 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPE: Encoding Relative Positions with Continuous Augmented Positional Embeddings
Jun 06, 2021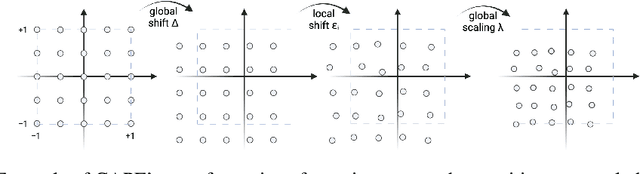
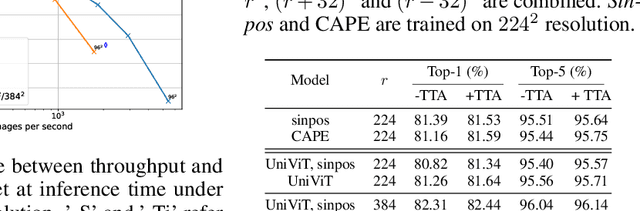
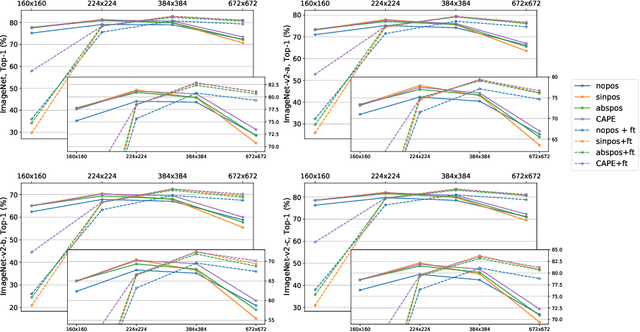
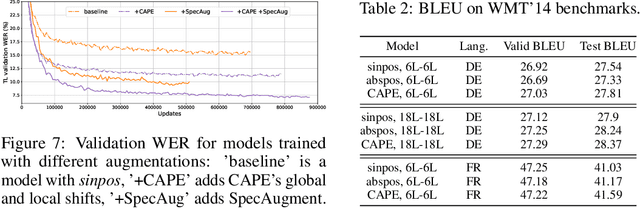
Without positional information, attention-based transformer neural networks are permutation-invariant. Absolute or relative positional embeddings are the most popular ways to feed transformer models positional information. Absolute positional embeddings are simple to implement, but suffer from generalization issues when evaluating on sequences of different length than those seen at training time. Relative positions are more robust to length change, but are more complex to implement and yield inferior model throughput. In this paper, we propose an augmentation-based approach (CAPE) for absolute positional embeddings, which keeps the advantages of both absolute (simplicity and speed) and relative position embeddings (better generalization). In addition, our empirical evaluation on state-of-the-art models in machine translation, image and speech recognition demonstrates that CAPE leads to better generalization performance as well as increased stability with respect to training hyper-parameters.
ResMLP: Feedforward networks for image classification with data-efficient training
May 07, 2021
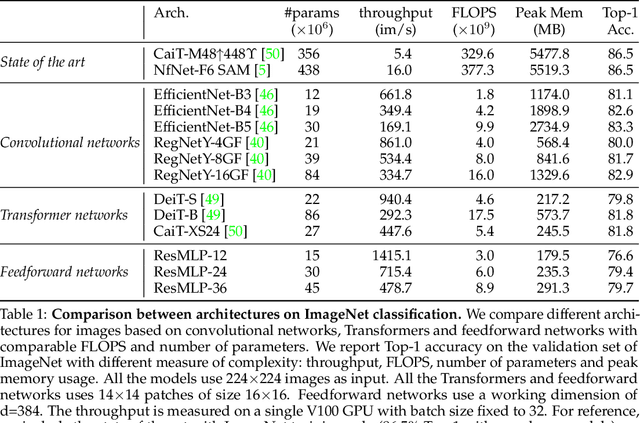
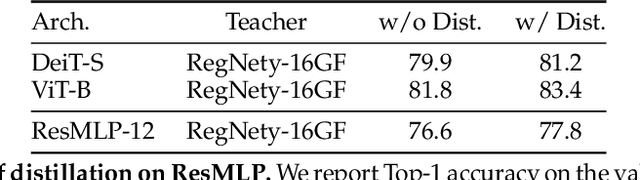
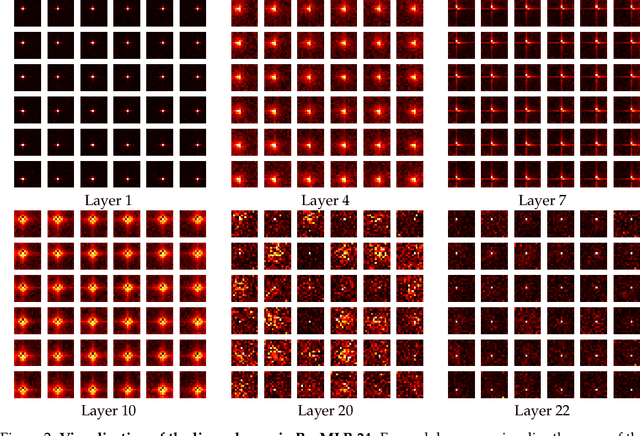
We present ResMLP, an architecture built entirely upon multi-layer perceptrons for image classification. It is a simple residual network that alternates (i) a linear layer in which image patches interact, independently and identically across channels, and (ii) a two-layer feed-forward network in which channels interact independently per patch. When trained with a modern training strategy using heavy data-augmentation and optionally distillation, it attains surprisingly good accuracy/complexity trade-offs on ImageNet. We will share our code based on the Timm library and pre-trained models.
MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding
Apr 26, 2021
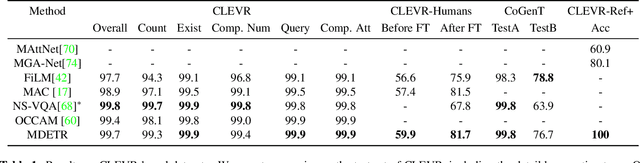
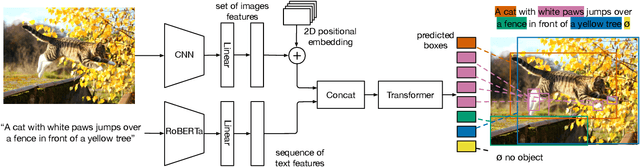
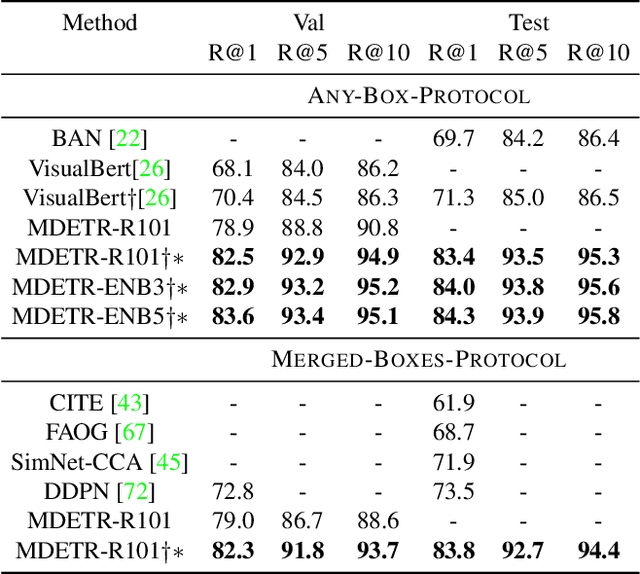
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes. This makes it challenging for such systems to capture the long tail of visual concepts expressed in free form text. In this paper we propose MDETR, an end-to-end modulated detector that detects objects in an image conditioned on a raw text query, like a caption or a question. We use a transformer-based architecture to reason jointly over text and image by fusing the two modalities at an early stage of the model. We pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image. We then fine-tune on several downstream tasks such as phrase grounding, referring expression comprehension and segmentation, achieving state-of-the-art results on popular benchmarks. We also investigate the utility of our model as an object detector on a given label set when fine-tuned in a few-shot setting. We show that our pre-training approach provides a way to handle the long tail of object categories which have very few labelled instances. Our approach can be easily extended for visual question answering, achieving competitive performance on GQA and CLEVR. The code and models are available at https://github.com/ashkamath/mdetr.
Differentiable Model Compression via Pseudo Quantization Noise
Apr 20, 2021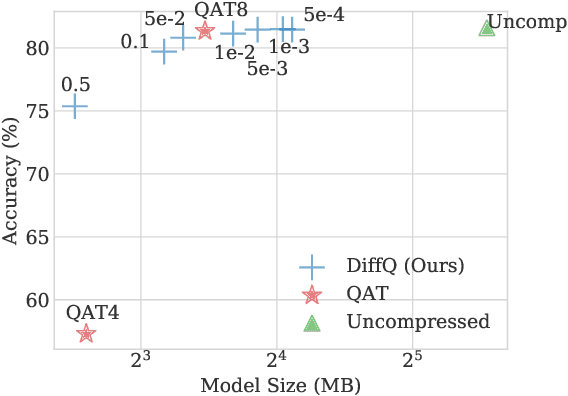
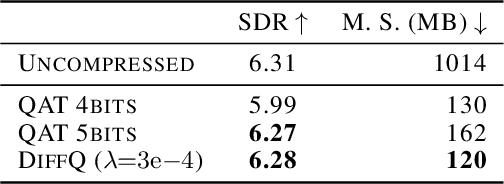
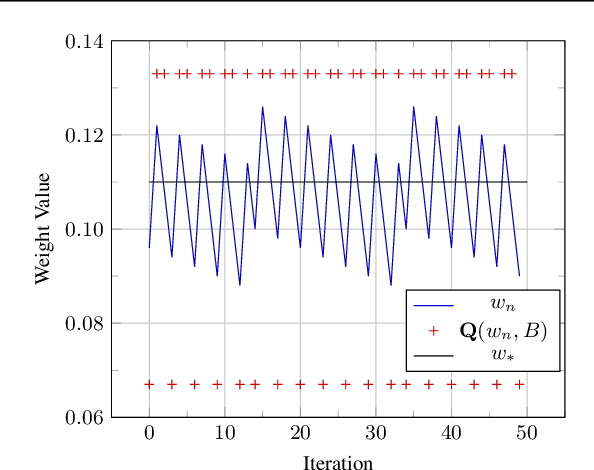
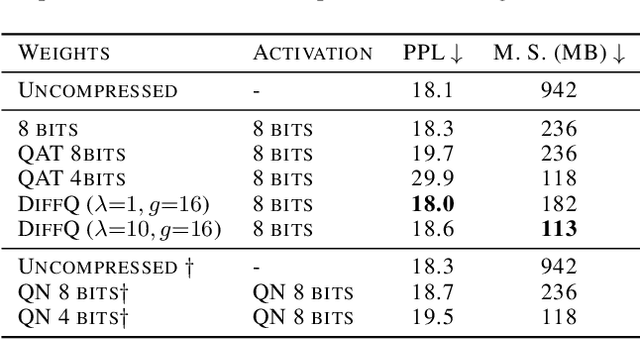
We propose to add independent pseudo quantization noise to model parameters during training to approximate the effect of a quantization operator. This method, DiffQ, is differentiable both with respect to the unquantized parameters, and the number of bits used. Given a single hyper-parameter expressing the desired balance between the quantized model size and accuracy, DiffQ can optimize the number of bits used per individual weight or groups of weights, in a single training. We experimentally verify that our method outperforms state-of-the-art quantization techniques on several benchmarks and architectures for image classification, language modeling, and audio source separation. For instance, on the Wikitext-103 language modeling benchmark, DiffQ compresses a 16 layers transformer model by a factor of 8, equivalent to 4 bits precision, while losing only 0.5 points of perplexity. Code is available at: https://github.com/facebookresearch/diffq
Gradient Matching for Domain Generalization
Apr 20, 2021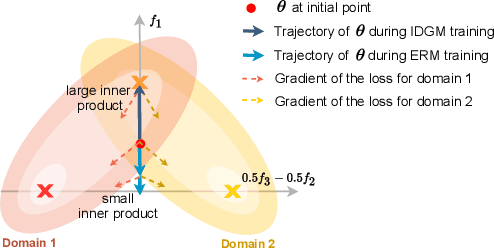


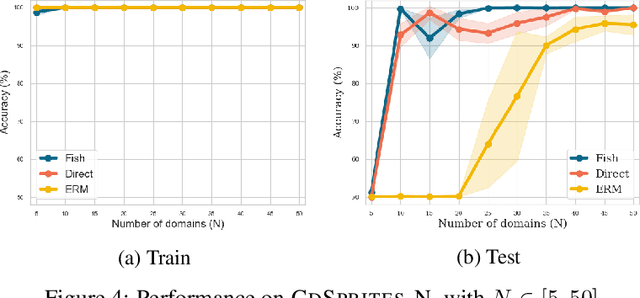
Machine learning systems typically assume that the distributions of training and test sets match closely. However, a critical requirement of such systems in the real world is their ability to generalize to unseen domains. Here, we propose an inter-domain gradient matching objective that targets domain generalization by maximizing the inner product between gradients from different domains. Since direct optimization of the gradient inner product can be computationally prohibitive -- requires computation of second-order derivatives -- we derive a simpler first-order algorithm named Fish that approximates its optimization. We demonstrate the efficacy of Fish on 6 datasets from the Wilds benchmark, which captures distribution shift across a diverse range of modalities. Our method produces competitive results on these datasets and surpasses all baselines on 4 of them. We perform experiments on both the Wilds benchmark, which captures distribution shift in the real world, as well as datasets in DomainBed benchmark that focuses more on synthetic-to-real transfer. Our method produces competitive results on both benchmarks, demonstrating its effectiveness across a wide range of domain generalization tasks.
Going deeper with Image Transformers
Apr 07, 2021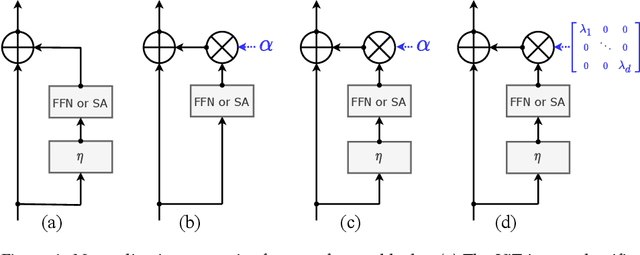
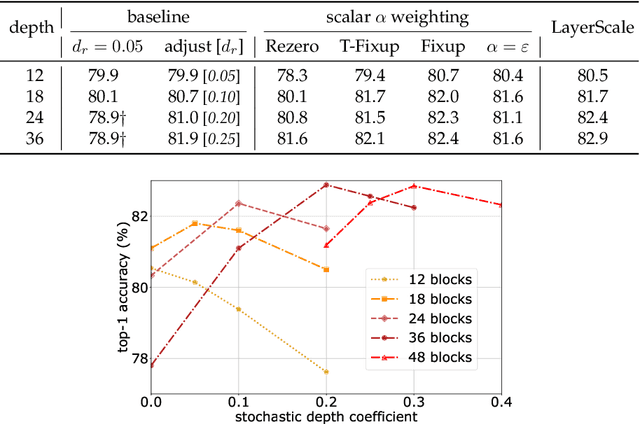
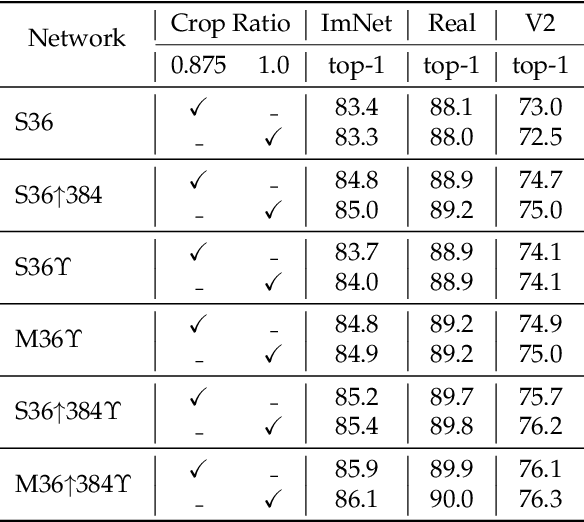
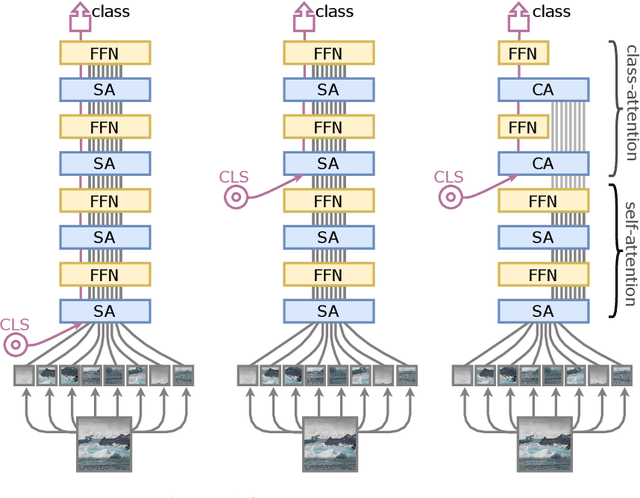
Transformers have been recently adapted for large scale image classification, achieving high scores shaking up the long supremacy of convolutional neural networks. However the optimization of image transformers has been little studied so far. In this work, we build and optimize deeper transformer networks for image classification. In particular, we investigate the interplay of architecture and optimization of such dedicated transformers. We make two transformers architecture changes that significantly improve the accuracy of deep transformers. This leads us to produce models whose performance does not saturate early with more depth, for instance we obtain 86.5% top-1 accuracy on Imagenet when training with no external data, we thus attain the current SOTA with less FLOPs and parameters. Moreover, our best model establishes the new state of the art on Imagenet with Reassessed labels and Imagenet-V2 / match frequency, in the setting with no additional training data. We share our code and models.
Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
Apr 02, 2021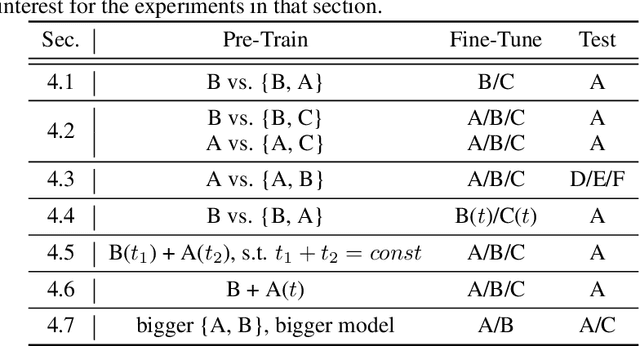
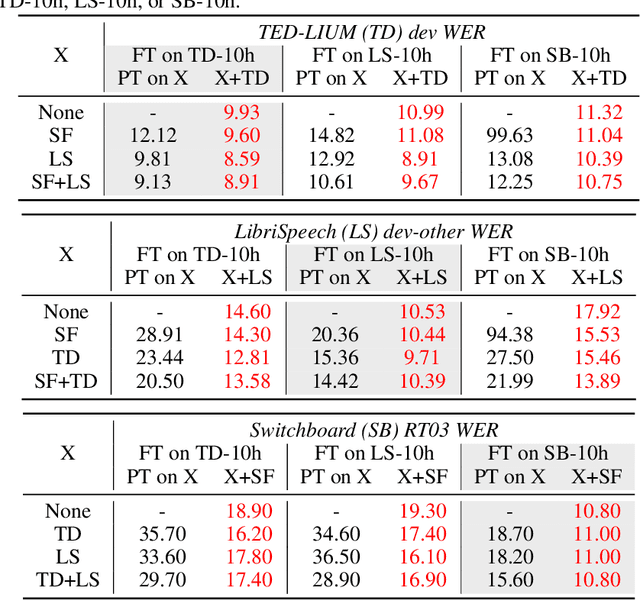
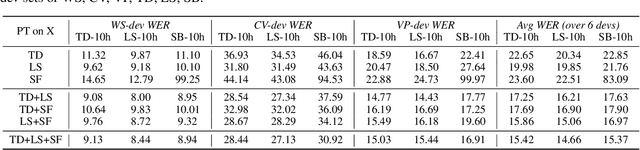
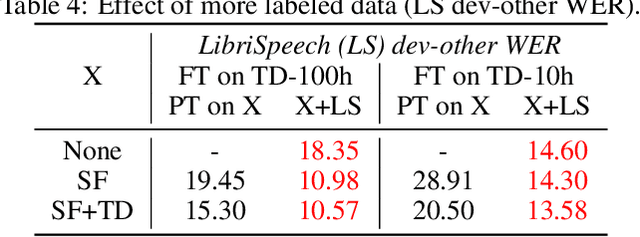
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at https://github.com/pytorch/fairseq.
MLS: A Large-Scale Multilingual Dataset for Speech Research
Dec 19, 2020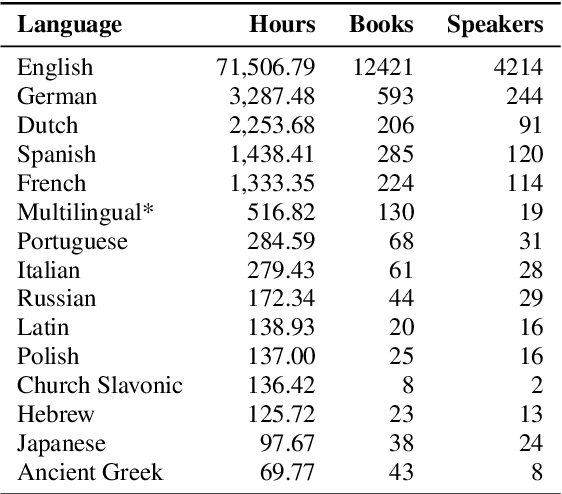
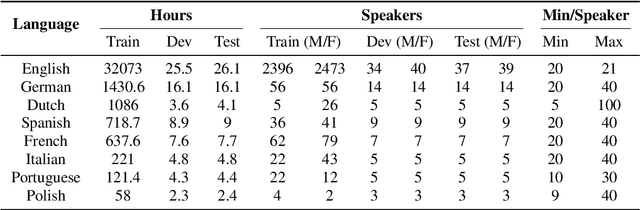
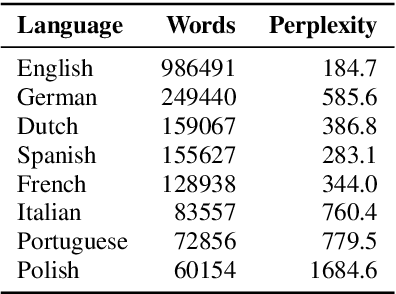
This paper introduces Multilingual LibriSpeech (MLS) dataset, a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a total of about 6K hours for other languages. Additionally, we provide Language Models (LM) and baseline Automatic Speech Recognition (ASR) models and for all the languages in our dataset. We believe such a large transcribed dataset will open new avenues in ASR and Text-To-Speech (TTS) research. The dataset will be made freely available for anyone at http://www.openslr.org.
Joint Masked CPC and CTC Training for ASR
Oct 30, 2020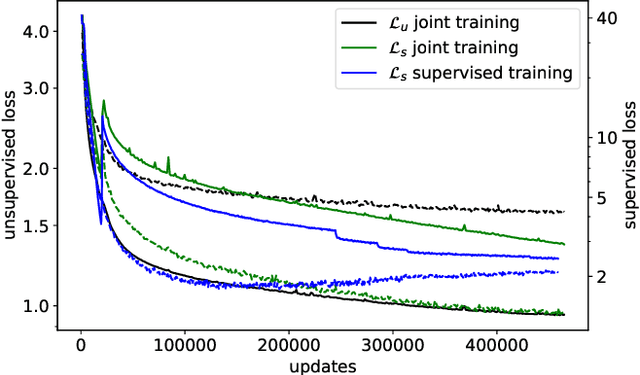
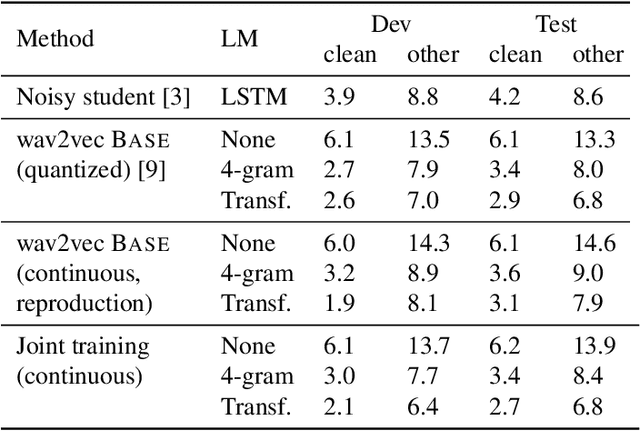
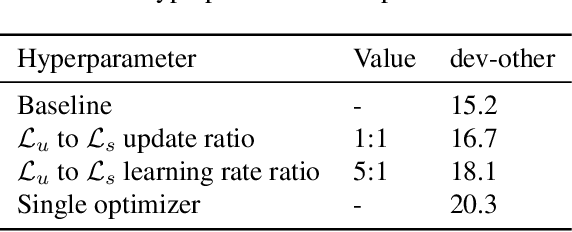
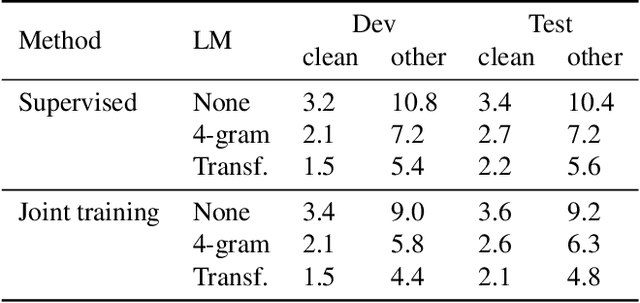
Self-supervised learning (SSL) has shown promise in learning representations of audio that are useful for automatic speech recognition (ASR). But, training SSL models like wav2vec~2.0 requires a two-stage pipeline. In this paper we demonstrate a single-stage training of ASR models that can utilize both unlabeled and labeled data. During training, we alternately minimize two losses: an unsupervised masked Contrastive Predictive Coding (CPC) loss and the supervised audio-to-text alignment loss Connectionist Temporal Classification (CTC). We show that this joint training method directly optimizes performance for the downstream ASR task using unsupervised data while achieving similar word error rates to wav2vec~2.0 on the Librispeech 100-hour dataset. Finally, we postulate that solving the contrastive task is a regularization for the supervised CTC loss.
Rethinking Evaluation in ASR: Are Our Models Robust Enough?
Oct 22, 2020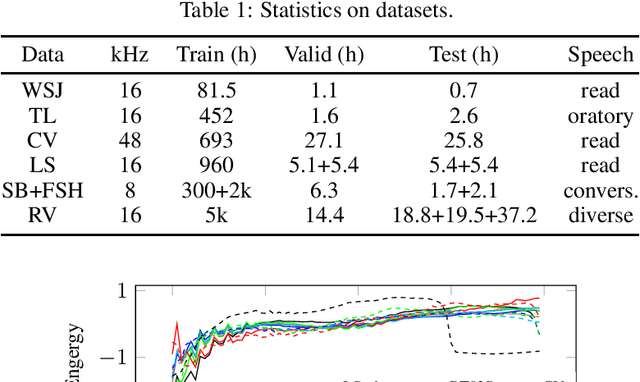
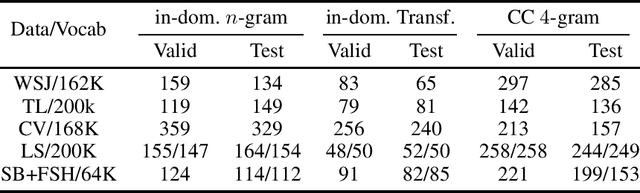
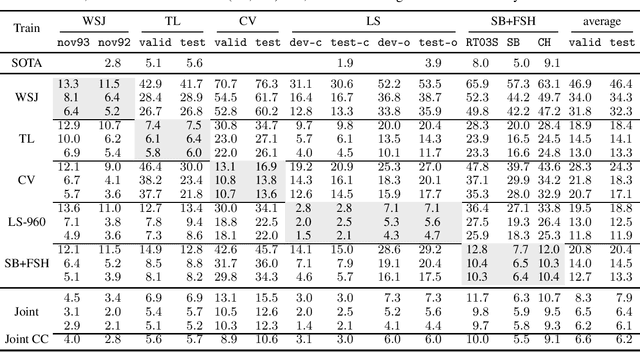
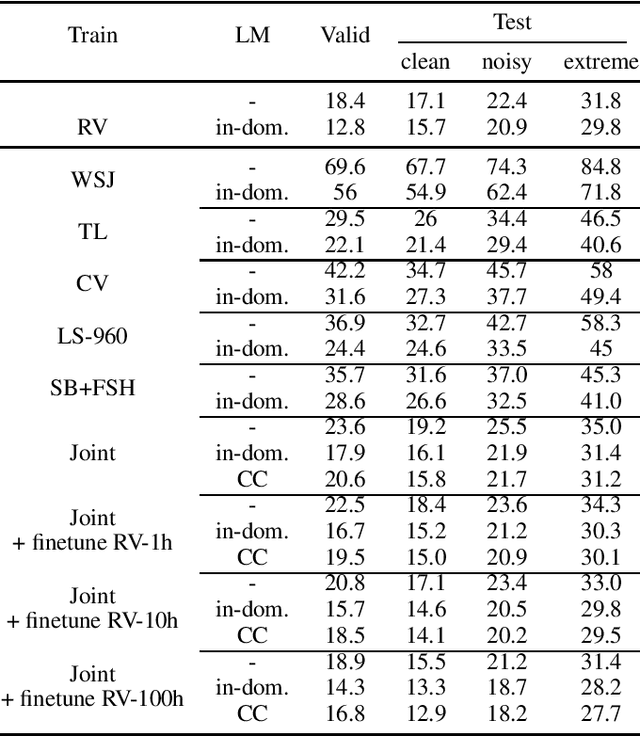
Is pushing numbers on a single benchmark valuable in automatic speech recognition? Research results in acoustic modeling are typically evaluated based on performance on a single dataset. While the research community has coalesced around various benchmarks, we set out to understand generalization performance in acoustic modeling across datasets -- in particular, if models trained on a single dataset transfer to other (possibly out-of-domain) datasets. Further, we demonstrate that when a large enough set of benchmarks is used, average word error rate (WER) performance over them provides a good proxy for performance on real-world data. Finally, we show that training a single acoustic model on the most widely-used datasets -- combined -- reaches competitive performance on both research and real-world benchmarks.