 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Agent Coordination via Sheaf-ADMM
May 29, 2026We present a differentiable optimization framework for multi-agent coordination. An input is decomposed into overlapping local views, each processed by an agent that solves a convex subproblem parameterized by a neural encoder. Agents coordinate through the Alternating Direction Method of Multipliers (ADMM) with inter-agent constraints specified by a cellular sheaf. The sheaf specifies which aspects of neighboring solutions must agree, allowing for heterogeneous notions of global consensus. Backpropagating through the unrolled optimization jointly trains all components of the multi-agent system. We evaluate on maze pathfinding, image classification, and Sudoku, where agents with individually insufficient local views learn to coordinate to produce correct global outputs. On MNIST, the local-view decomposition yields improved robustness to distribution shifts relative to a standard CNN. On Sudoku, the optimization-derived structure yields markedly higher solve rates than parameter-matched MPNN baselines. Finally, the ADMM structure exposes distinct primal, consensus, and dual state variables, opening the coordination dynamics to direct analysis and intervention -- a property unavailable in standard message-passing architectures.
Augmented Lagrangian Predictive Coding
May 29, 2026Predictive coding (PC) is a local-learning alternative to backpropagation (BP), training deep networks via local energy-minimization dynamics rather than a global backward pass. We introduce Augmented Lagrangian Predictive Coding (PC-ALM), which maintains PC's inference budget but aligns each weight update toward BP by accumulating per-layer constraint errors into a layer-local Lagrange multiplier. In linear PC networks, PC-ALM converges to an equilibrium with exact BP gradients distributed across the network via only layer-local updates. We analyze PC-ALM in nonlinear PC networks up to depth 128 and show that it matches BP performance across all width-depth regimes, notably in deep narrow networks where PC underperforms. PC-ALM introduces recurrent dynamics in each layer's activations. Compared to PC's heat flow on a scalar energy, PC-ALM dynamics are driven by dual ascent on the augmented Lagrangian. We observe "ballistic" credit propagation across very deep networks, with credit signals evenly distributed across layers, compared to PC's slow, diffusive credit propagation. Beyond the algorithm itself, the augmented Lagrangian framework offers a generalization of PC, and may yield insights into how distributed systems could compute and propagate BP-like credit signals through purely local dynamics.
Sheaf Cohomology of Linear Predictive Coding Networks
Nov 14, 2025Predictive coding (PC) replaces global backpropagation with local optimization over weights and activations. We show that linear PC networks admit a natural formulation as cellular sheaves: the sheaf coboundary maps activations to edge-wise prediction errors, and PC inference is diffusion under the sheaf Laplacian. Sheaf cohomology then characterizes irreducible error patterns that inference cannot remove. We analyze recurrent topologies where feedback loops create internal contradictions, introducing prediction errors unrelated to supervision. Using a Hodge decomposition, we determine when these contradictions cause learning to stall. The sheaf formalism provides both diagnostic tools for identifying problematic network configurations and design principles for effective weight initialization for recurrent PC networks.
Sudoku-Bench: Evaluating creative reasoning with Sudoku variants
May 22, 2025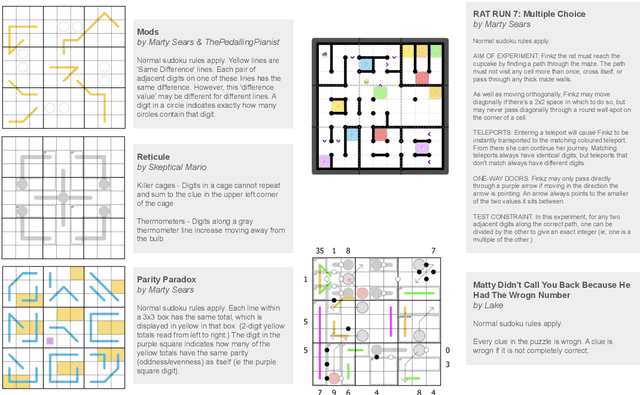
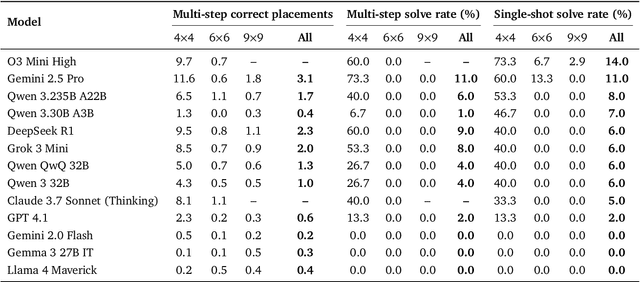

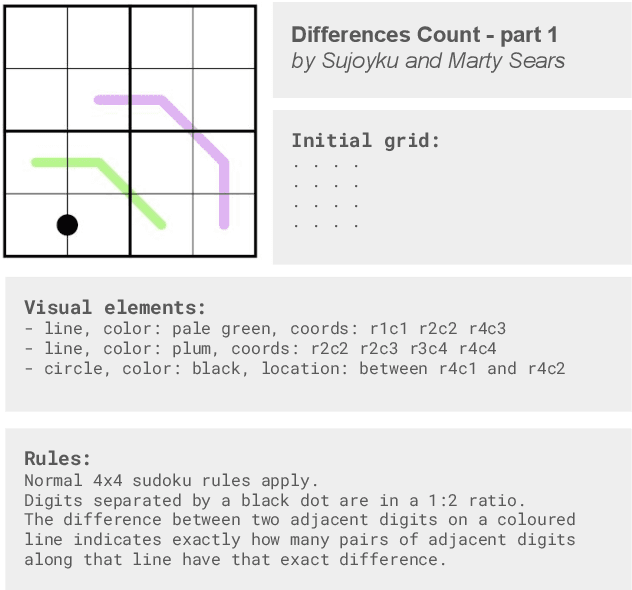
Existing reasoning benchmarks for large language models (LLMs) frequently fail to capture authentic creativity, often rewarding memorization of previously observed patterns. We address this shortcoming with Sudoku-Bench, a curated benchmark of challenging and unconventional Sudoku variants specifically selected to evaluate creative, multi-step logical reasoning. Sudoku variants form an unusually effective domain for reasoning research: each puzzle introduces unique or subtly interacting constraints, making memorization infeasible and requiring solvers to identify novel logical breakthroughs (``break-ins''). Despite their diversity, Sudoku variants maintain a common and compact structure, enabling clear and consistent evaluation. Sudoku-Bench includes a carefully chosen puzzle set, a standardized text-based puzzle representation, and flexible tools compatible with thousands of publicly available puzzles -- making it easy to extend into a general research environment. Baseline experiments show that state-of-the-art LLMs solve fewer than 15\% of puzzles unaided, highlighting significant opportunities to advance long-horizon, strategic reasoning capabilities.
Continuous Thought Machines
May 08, 2025



Biological brains demonstrate complex neural activity, where the timing and interplay between neurons is critical to how brains process information. Most deep learning architectures simplify neural activity by abstracting away temporal dynamics. In this paper we challenge that paradigm. By incorporating neuron-level processing and synchronization, we can effectively reintroduce neural timing as a foundational element. We present the Continuous Thought Machine (CTM), a model designed to leverage neural dynamics as its core representation. The CTM has two core innovations: (1) neuron-level temporal processing, where each neuron uses unique weight parameters to process a history of incoming signals; and (2) neural synchronization employed as a latent representation. The CTM aims to strike a balance between oversimplified neuron abstractions that improve computational efficiency, and biological realism. It operates at a level of abstraction that effectively captures essential temporal dynamics while remaining computationally tractable for deep learning. We demonstrate the CTM's strong performance and versatility across a range of challenging tasks, including ImageNet-1K classification, solving 2D mazes, sorting, parity computation, question-answering, and RL tasks. Beyond displaying rich internal representations and offering a natural avenue for interpretation owing to its internal process, the CTM is able to perform tasks that require complex sequential reasoning. The CTM can also leverage adaptive compute, where it can stop earlier for simpler tasks, or keep computing when faced with more challenging instances. The goal of this work is to share the CTM and its associated innovations, rather than pushing for new state-of-the-art results. To that end, we believe the CTM represents a significant step toward developing more biologically plausible and powerful artificial intelligence systems.
emg2qwerty: A Large Dataset with Baselines for Touch Typing using Surface Electromyography
Oct 26, 2024



Surface electromyography (sEMG) non-invasively measures signals generated by muscle activity with sufficient sensitivity to detect individual spinal neurons and richness to identify dozens of gestures and their nuances. Wearable wrist-based sEMG sensors have the potential to offer low friction, subtle, information rich, always available human-computer inputs. To this end, we introduce emg2qwerty, a large-scale dataset of non-invasive electromyographic signals recorded at the wrists while touch typing on a QWERTY keyboard, together with ground-truth annotations and reproducible baselines. With 1,135 sessions spanning 108 users and 346 hours of recording, this is the largest such public dataset to date. These data demonstrate non-trivial, but well defined hierarchical relationships both in terms of the generative process, from neurons to muscles and muscle combinations, as well as in terms of domain shift across users and user sessions. Applying standard modeling techniques from the closely related field of Automatic Speech Recognition (ASR), we show strong baseline performance on predicting key-presses using sEMG signals alone. We believe the richness of this task and dataset will facilitate progress in several problems of interest to both the machine learning and neuroscientific communities. Dataset and code can be accessed at https://github.com/facebookresearch/emg2qwerty.
Gradient Matching for Domain Generalization
Apr 20, 2021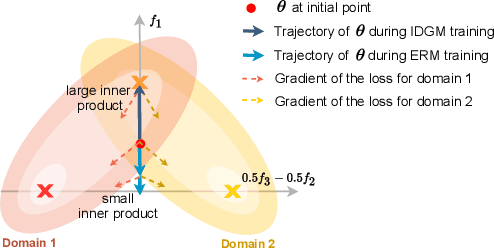


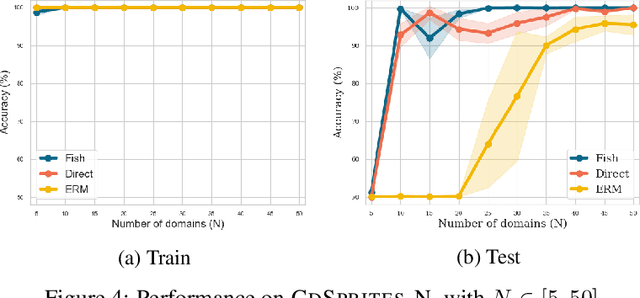
Machine learning systems typically assume that the distributions of training and test sets match closely. However, a critical requirement of such systems in the real world is their ability to generalize to unseen domains. Here, we propose an inter-domain gradient matching objective that targets domain generalization by maximizing the inner product between gradients from different domains. Since direct optimization of the gradient inner product can be computationally prohibitive -- requires computation of second-order derivatives -- we derive a simpler first-order algorithm named Fish that approximates its optimization. We demonstrate the efficacy of Fish on 6 datasets from the Wilds benchmark, which captures distribution shift across a diverse range of modalities. Our method produces competitive results on these datasets and surpasses all baselines on 4 of them. We perform experiments on both the Wilds benchmark, which captures distribution shift in the real world, as well as datasets in DomainBed benchmark that focuses more on synthetic-to-real transfer. Our method produces competitive results on both benchmarks, demonstrating its effectiveness across a wide range of domain generalization tasks.