 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Browsing: API-Based Web Agents
Oct 21, 2024



Web browsers are a portal to the internet, where much of human activity is undertaken. Thus, there has been significant research work in AI agents that interact with the internet through web browsing. However, there is also another interface designed specifically for machine interaction with online content: application programming interfaces (APIs). In this paper we ask -- what if we were to take tasks traditionally tackled by browsing agents, and give AI agents access to APIs? To do so, we propose two varieties of agents: (1) an API-calling agent that attempts to perform online tasks through APIs only, similar to traditional coding agents, and (2) a Hybrid Agent that can interact with online data through both web browsing and APIs. In experiments on WebArena, a widely-used and realistic benchmark for web navigation tasks, we find that API-based agents outperform web browsing agents. Hybrid Agents out-perform both others nearly uniformly across tasks, resulting in a more than 20.0% absolute improvement over web browsing alone, achieving a success rate of 35.8%, achiving the SOTA performance among task-agnostic agents. These results strongly suggest that when APIs are available, they present an attractive alternative to relying on web browsing alone.
HAICOSYSTEM: An Ecosystem for Sandboxing Safety Risks in Human-AI Interactions
Sep 26, 2024



AI agents are increasingly autonomous in their interactions with human users and tools, leading to increased interactional safety risks. We present HAICOSYSTEM, a framework examining AI agent safety within diverse and complex social interactions. HAICOSYSTEM features a modular sandbox environment that simulates multi-turn interactions between human users and AI agents, where the AI agents are equipped with a variety of tools (e.g., patient management platforms) to navigate diverse scenarios (e.g., a user attempting to access other patients' profiles). To examine the safety of AI agents in these interactions, we develop a comprehensive multi-dimensional evaluation framework that uses metrics covering operational, content-related, societal, and legal risks. Through running 1840 simulations based on 92 scenarios across seven domains (e.g., healthcare, finance, education), we demonstrate that HAICOSYSTEM can emulate realistic user-AI interactions and complex tool use by AI agents. Our experiments show that state-of-the-art LLMs, both proprietary and open-sourced, exhibit safety risks in over 50\% cases, with models generally showing higher risks when interacting with simulated malicious users. Our findings highlight the ongoing challenge of building agents that can safely navigate complex interactions, particularly when faced with malicious users. To foster the AI agent safety ecosystem, we release a code platform that allows practitioners to create custom scenarios, simulate interactions, and evaluate the safety and performance of their agents.
Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
May 09, 2022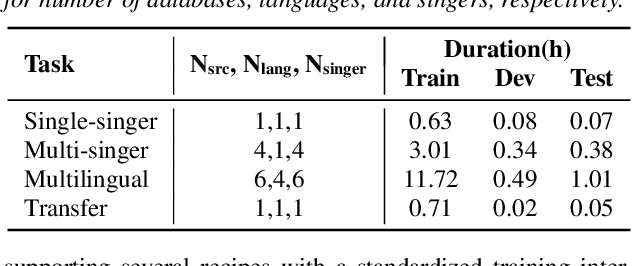
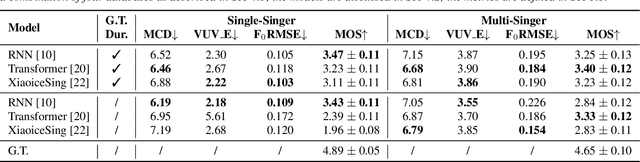
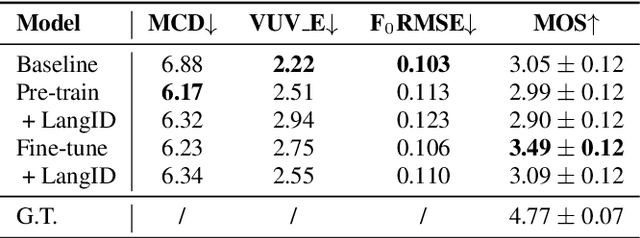
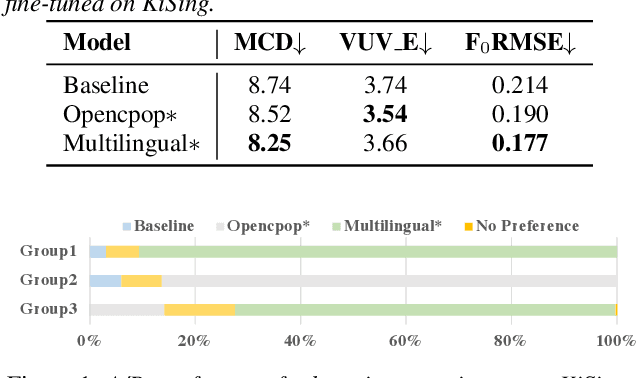
This paper introduces a new open-source platform named Muskits for end-to-end music processing, which mainly focuses on end-to-end singing voice synthesis (E2E-SVS). Muskits supports state-of-the-art SVS models, including RNN SVS, transformer SVS, and XiaoiceSing. The design of Muskits follows the style of widely-used speech processing toolkits, ESPnet and Kaldi, for data prepossessing, training, and recipe pipelines. To the best of our knowledge, this toolkit is the first platform that allows a fair and highly-reproducible comparison between several published works in SVS. In addition, we also demonstrate several advanced usages based on the toolkit functionalities, including multilingual training and transfer learning. This paper describes the major framework of Muskits, its functionalities, and experimental results in single-singer, multi-singer, multilingual, and transfer learning scenarios. The toolkit is publicly available at https://github.com/SJTMusicTeam/Muskits.
Parsimonious Morpheme Segmentation with an Application to Enriching Word Embeddings
Aug 18, 2019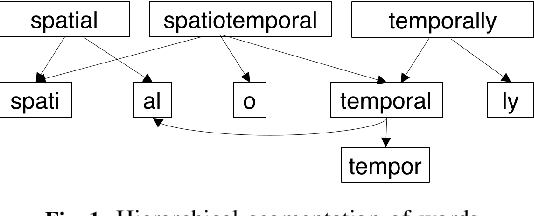
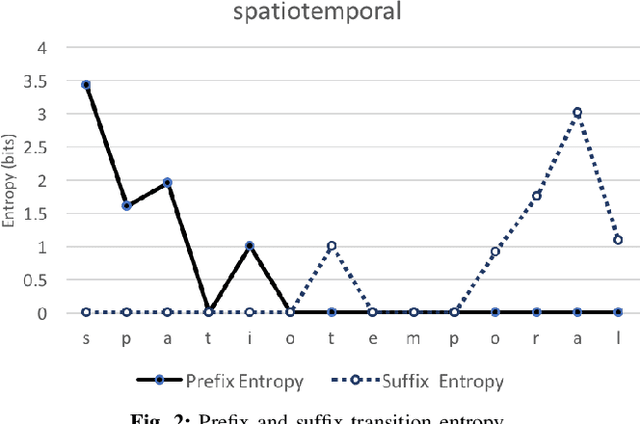
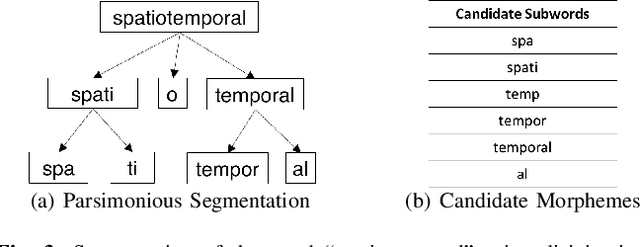
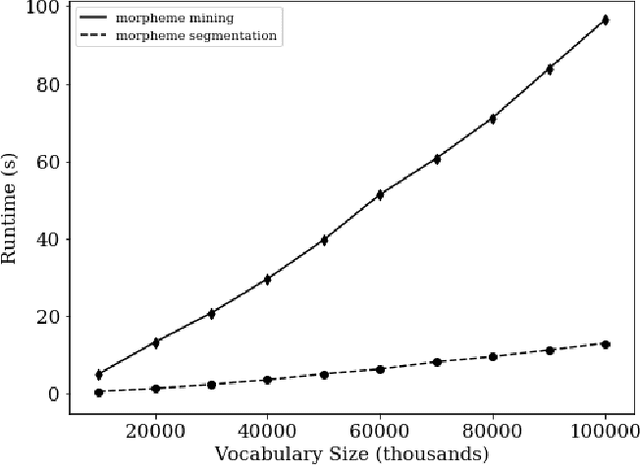
Traditionally, many text-mining tasks treat individual word-tokens as the finest meaningful semantic granularity. However, in many languages and specialized corpora, words are composed by concatenating semantically meaningful subword structures. Word-level analysis cannot leverage the semantic information present in such subword structures. With regard to word embedding techniques, this leads to not only poor embeddings for infrequent words in long-tailed text corpora but also weak capabilities for handling out-of-vocabulary words. In this paper we propose MorphMine for unsupervised morpheme segmentation. MorphMine applies a parsimony criterion to hierarchically segment words into the fewest number of morphemes at each level of the hierarchy. This leads to longer shared morphemes at each level of segmentation. Experiments show that MorphMine segments words in a variety of languages into human-verified morphemes. Additionally, we experimentally demonstrate that utilizing MorphMine morphemes to enrich word embeddings consistently improves embedding quality on a variety of of embedding evaluations and a downstream language modeling task.
Toward Unsupervised Text Content Manipulation
Feb 08, 2019
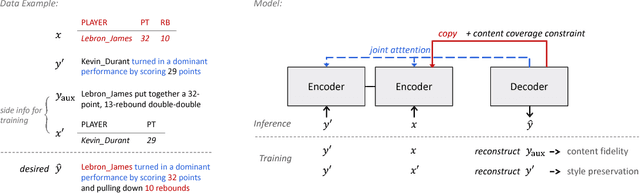
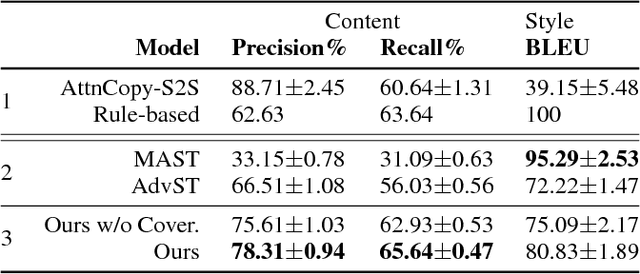
Controlled generation of text is of high practical use. Recent efforts have made impressive progress in generating or editing sentences with given textual attributes (e.g., sentiment). This work studies a new practical setting of text content manipulation. Given a structured record, such as `(PLAYER: Lebron, POINTS: 20, ASSISTS: 10)', and a reference sentence, such as `Kobe easily dropped 30 points', we aim to generate a sentence that accurately describes the full content in the record, with the same writing style (e.g., wording, transitions) of the reference. The problem is unsupervised due to lack of parallel data in practice, and is challenging to minimally yet effectively manipulate the text (by rewriting/adding/deleting text portions) to ensure fidelity to the structured content. We derive a dataset from a basketball game report corpus as our testbed, and develop a neural method with unsupervised competing objectives and explicit content coverage constraints. Automatic and human evaluations show superiority of our approach over competitive methods including a strong rule-based baseline and prior approaches designed for style transfer.