 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose
Oct 23, 2020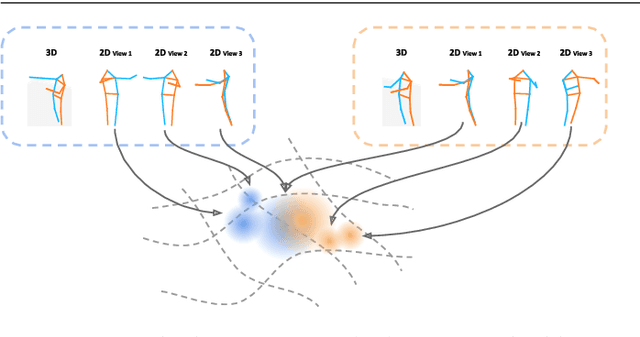
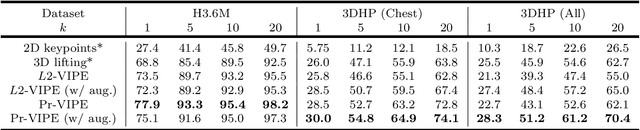
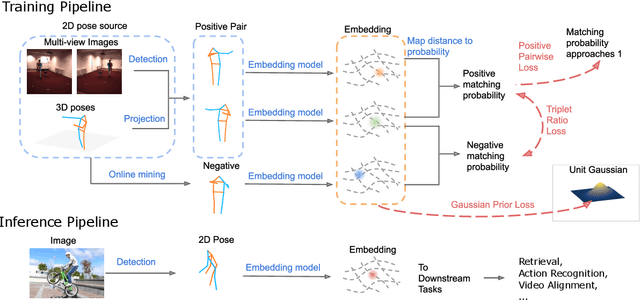

Recognition of human poses and activities is crucial for autonomous systems to interact smoothly with people. However, cameras generally capture human poses in 2D as images and videos, which can have significant appearance variations across viewpoints. To address this, we explore recognizing similarity in 3D human body poses from 2D information, which has not been well-studied in existing works. Here, we propose an approach to learning a compact view-invariant embedding space from 2D body joint keypoints, without explicitly predicting 3D poses. Input ambiguities of 2D poses from projection and occlusion are difficult to represent through a deterministic mapping, and therefore we use probabilistic embeddings. In order to enable our embeddings to work with partially visible input keypoints, we further investigate different keypoint occlusion augmentation strategies during training. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 3D pose estimation models. We further show that keypoint occlusion augmentation during training significantly improves retrieval performance on partial 2D input poses. Results on action recognition and video alignment demonstrate that our embeddings, without any additional training, achieves competitive performance relative to other models specifically trained for each task.
EEV Dataset: Predicting Expressions Evoked by Diverse Videos
Jan 15, 2020
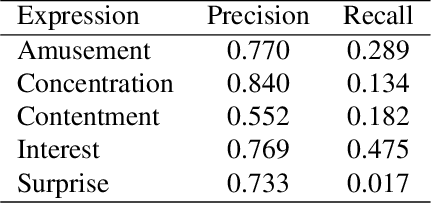
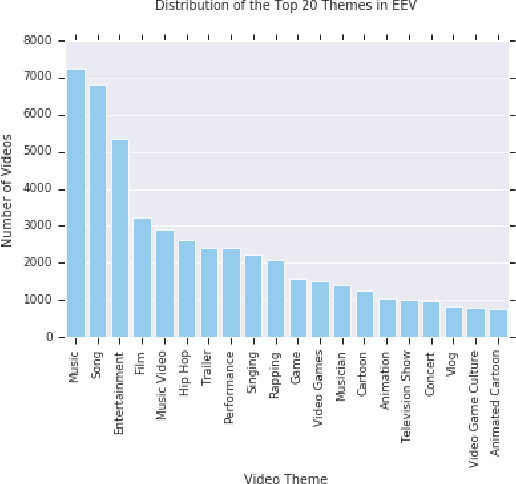
When we watch videos, the visual and auditory information we experience can evoke a range of affective responses. The ability to automatically predict evoked affect from videos can help recommendation systems and social machines better interact with their users. Here, we introduce the Evoked Expressions in Videos (EEV) dataset, a large-scale dataset for studying viewer responses to videos based on their facial expressions. The dataset consists of a total of 4.8 million annotations of viewer facial reactions to 18,541 videos. We use a publicly available video corpus to obtain a diverse set of video content. The training split is fully machine-annotated, while the validation and test splits have both human and machine annotations. We verify the performance of our machine annotations with human raters to have an average precision of 73.3%. We establish baseline performance on the EEV dataset using an existing multimodal recurrent model. Our results show that affective information can be learned from EEV, but with a MAP of 20.32%, there is potential for improvement. This gap motivates the need for new approaches for understanding affective content. Our transfer learning experiments show an improvement in performance on the LIRIS-ACCEDE video dataset when pre-trained on EEV. We hope that the size and diversity of the EEV dataset will encourage further explorations in video understanding and affective computing.
View-Invariant Probabilistic Embedding for Human Pose
Dec 02, 2019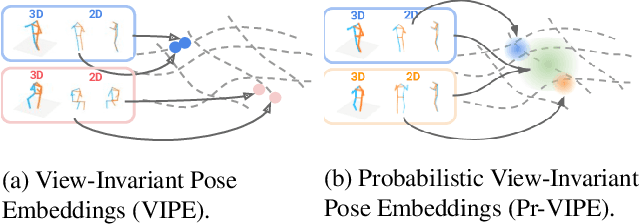
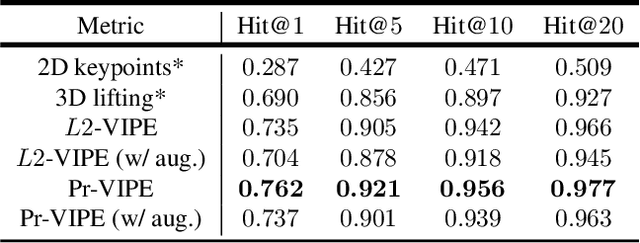
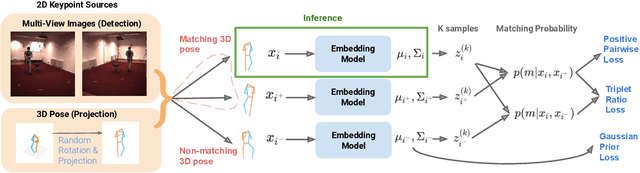
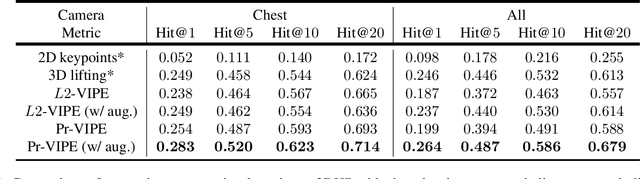
Depictions of similar human body configurations can vary with changing viewpoints. Using only 2D information, we would like to enable vision algorithms to recognize similarity in human body poses across multiple views. This ability is useful for analyzing body movements and human behaviors in images and videos. In this paper, we propose an approach for learning a compact view-invariant embedding space from 2D joint keypoints alone, without explicitly predicting 3D poses. Since 2D poses are projected from 3D space, they have an inherent ambiguity, which is difficult to represent through a deterministic mapping. Hence, we use probabilistic embeddings to model this input uncertainty. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 2D-to-3D pose lifting models. The results also suggest that our model is able to generalize across datasets, and our embedding variance correlates with input pose ambiguity.
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
Apr 08, 2019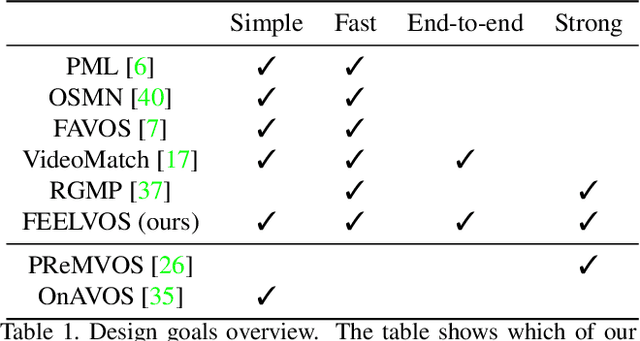
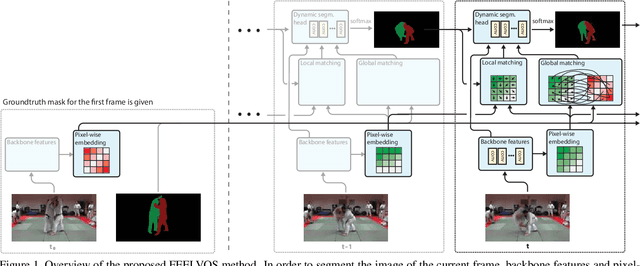
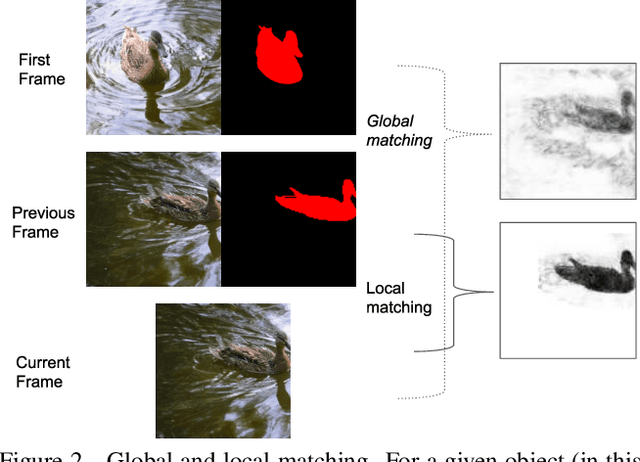
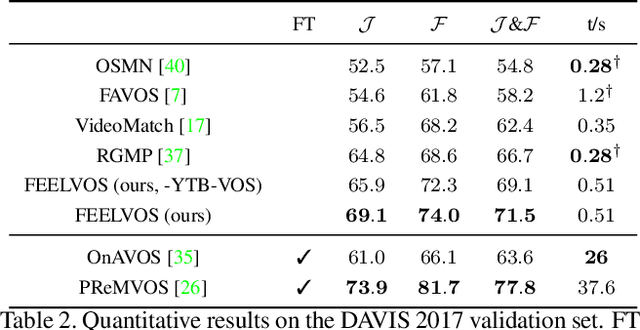
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
* CVPR 2019 camera-ready version
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Jan 10, 2019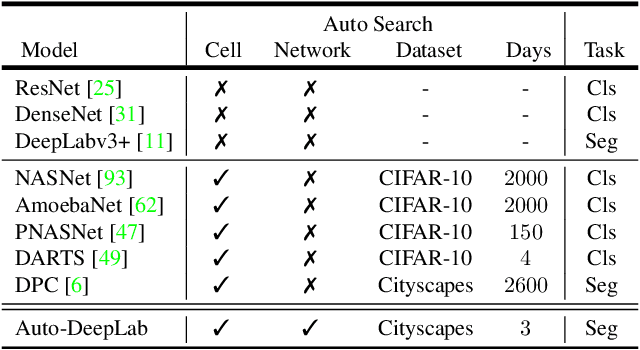
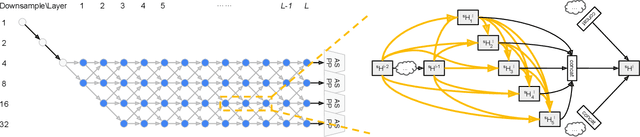
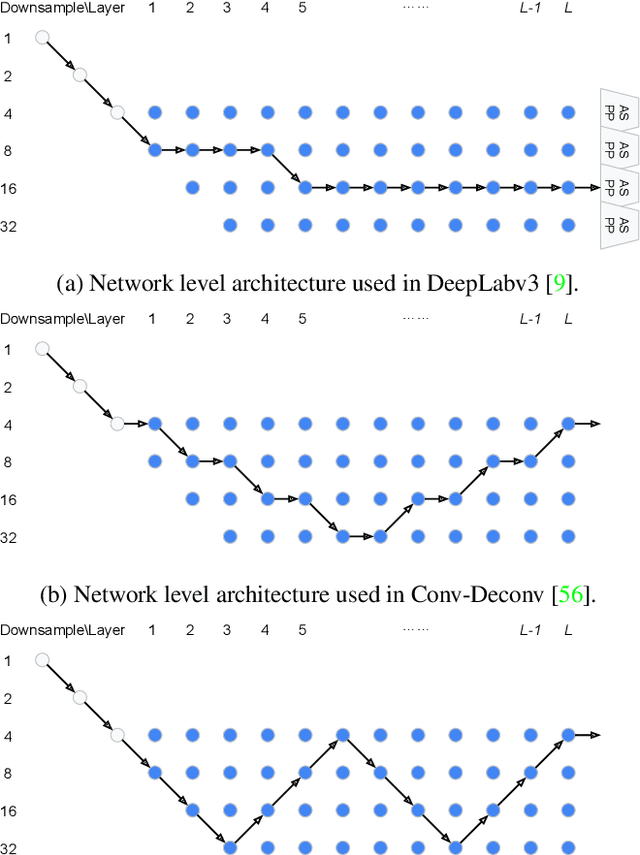
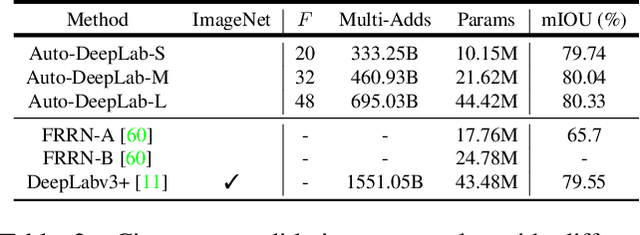
Recently, Neural Architecture Search (NAS) has successfully identified neural network architectures that exceed human designed ones on large-scale image classification problems. In this paper, we study NAS for semantic image segmentation, an important computer vision task that assigns a semantic label to every pixel in an image. Existing works often focus on searching the repeatable cell structure, while hand-designing the outer network structure that controls the spatial resolution changes. This choice simplifies the search space, but becomes increasingly problematic for dense image prediction which exhibits a lot more network level architectural variations. Therefore, we propose to search the network level structure in addition to the cell level structure, which forms a hierarchical architecture search space. We present a network level search space that includes many popular designs, and develop a formulation that allows efficient gradient-based architecture search (3 P100 GPU days on Cityscapes images). We demonstrate the effectiveness of the proposed method on the challenging Cityscapes, PASCAL VOC 2012, and ADE20K datasets. Without any ImageNet pretraining, our architecture searched specifically for semantic image segmentation attains state-of-the-art performance.
Modeling Uncertainty with Hedged Instance Embedding
Oct 19, 2018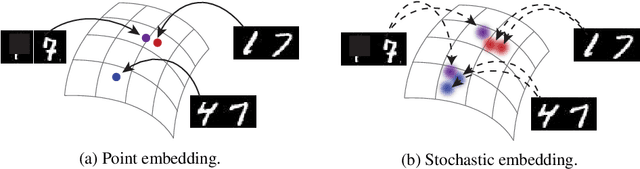
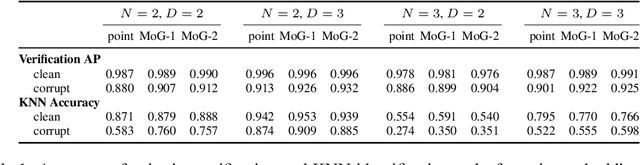
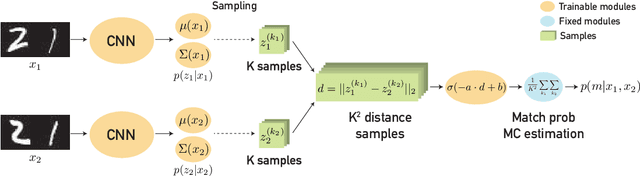
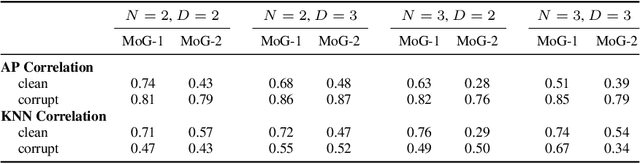
Instance embeddings are an efficient and versatile image representation that facilitates applications like recognition, verification, retrieval, and clustering. Many metric learning methods represent the input as a single point in the embedding space. Often the distance between points is used as a proxy for match confidence. However, this can fail to represent uncertainty arising when the input is ambiguous, e.g., due to occlusion or blurriness. This work addresses this issue and explicitly models the uncertainty by hedging the location of each input in the embedding space. We introduce the hedged instance embedding (HIB) in which embeddings are modeled as random variables and the model is trained under the variational information bottleneck principle. Empirical results on our new N-digit MNIST dataset show that our method leads to the desired behavior of hedging its bets across the embedding space upon encountering ambiguous inputs. This results in improved performance for image matching and classification tasks, more structure in the learned embedding space, and an ability to compute a per-exemplar uncertainty measure that is correlated with downstream performance.
Searching for Efficient Multi-Scale Architectures for Dense Image Prediction
Sep 11, 2018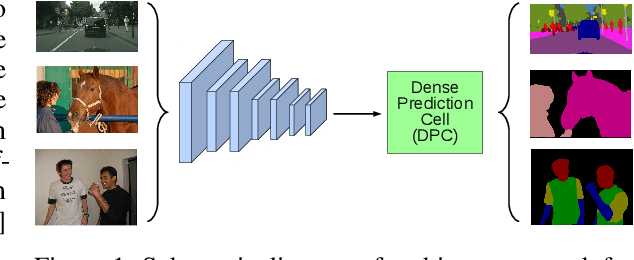
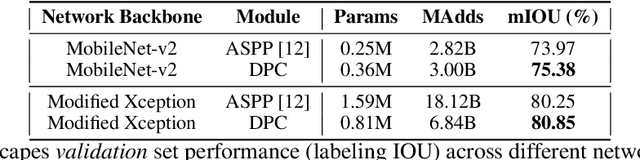
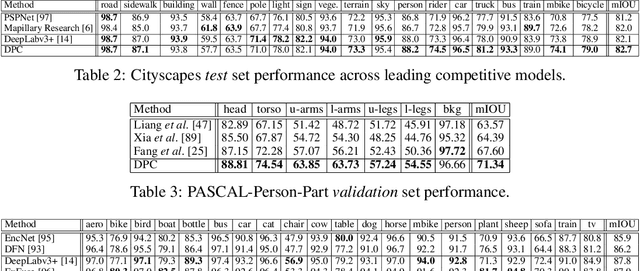
The design of neural network architectures is an important component for achieving state-of-the-art performance with machine learning systems across a broad array of tasks. Much work has endeavored to design and build architectures automatically through clever construction of a search space paired with simple learning algorithms. Recent progress has demonstrated that such meta-learning methods may exceed scalable human-invented architectures on image classification tasks. An open question is the degree to which such methods may generalize to new domains. In this work we explore the construction of meta-learning techniques for dense image prediction focused on the tasks of scene parsing, person-part segmentation, and semantic image segmentation. Constructing viable search spaces in this domain is challenging because of the multi-scale representation of visual information and the necessity to operate on high resolution imagery. Based on a survey of techniques in dense image prediction, we construct a recursive search space and demonstrate that even with efficient random search, we can identify architectures that outperform human-invented architectures and achieve state-of-the-art performance on three dense prediction tasks including 82.7\% on Cityscapes (street scene parsing), 71.3\% on PASCAL-Person-Part (person-part segmentation), and 87.9\% on PASCAL VOC 2012 (semantic image segmentation). Additionally, the resulting architecture is more computationally efficient, requiring half the parameters and half the computational cost as previous state of the art systems.
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Aug 22, 2018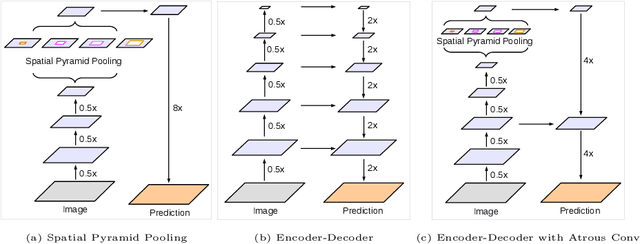

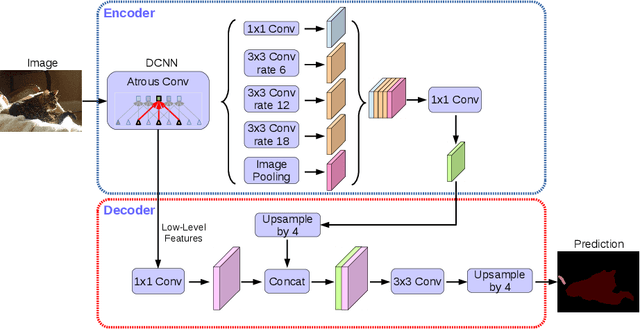

Spatial pyramid pooling module or encode-decoder structure are used in deep neural networks for semantic segmentation task. The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information. In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network. We demonstrate the effectiveness of the proposed model on PASCAL VOC 2012 and Cityscapes datasets, achieving the test set performance of 89.0\% and 82.1\% without any post-processing. Our paper is accompanied with a publicly available reference implementation of the proposed models in Tensorflow at \url{https://github.com/tensorflow/models/tree/master/research/deeplab}.
MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features
Dec 13, 2017
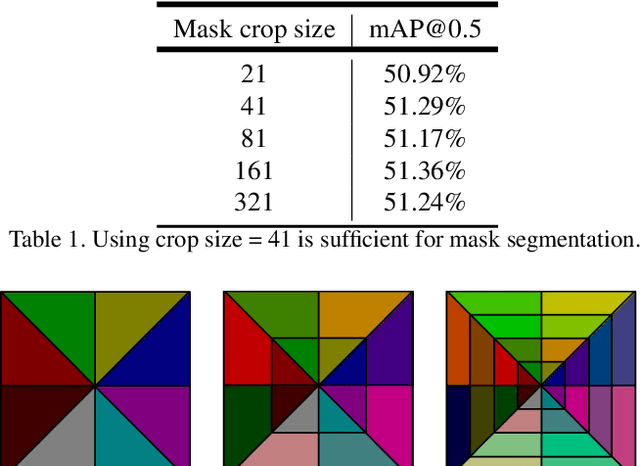
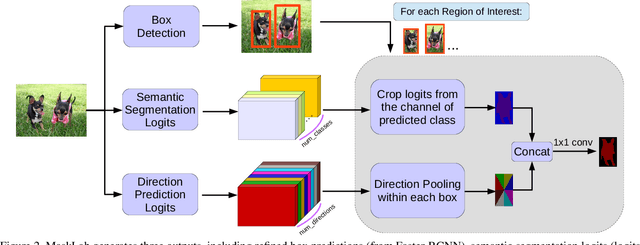

In this work, we tackle the problem of instance segmentation, the task of simultaneously solving object detection and semantic segmentation. Towards this goal, we present a model, called MaskLab, which produces three outputs: box detection, semantic segmentation, and direction prediction. Building on top of the Faster-RCNN object detector, the predicted boxes provide accurate localization of object instances. Within each region of interest, MaskLab performs foreground/background segmentation by combining semantic and direction prediction. Semantic segmentation assists the model in distinguishing between objects of different semantic classes including background, while the direction prediction, estimating each pixel's direction towards its corresponding center, allows separating instances of the same semantic class. Moreover, we explore the effect of incorporating recent successful methods from both segmentation and detection (i.e. atrous convolution and hypercolumn). Our proposed model is evaluated on the COCO instance segmentation benchmark and shows comparable performance with other state-of-art models.
Rethinking Atrous Convolution for Semantic Image Segmentation
Dec 05, 2017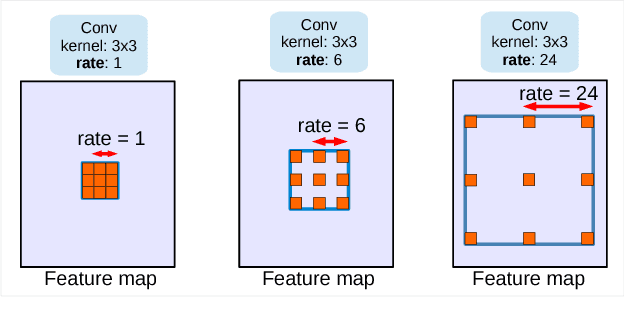

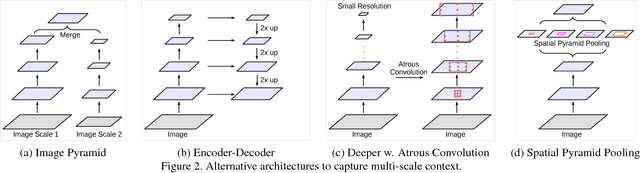
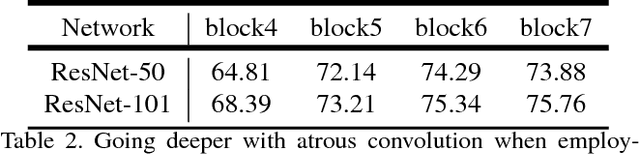
In this work, we revisit atrous convolution, a powerful tool to explicitly adjust filter's field-of-view as well as control the resolution of feature responses computed by Deep Convolutional Neural Networks, in the application of semantic image segmentation. To handle the problem of segmenting objects at multiple scales, we design modules which employ atrous convolution in cascade or in parallel to capture multi-scale context by adopting multiple atrous rates. Furthermore, we propose to augment our previously proposed Atrous Spatial Pyramid Pooling module, which probes convolutional features at multiple scales, with image-level features encoding global context and further boost performance. We also elaborate on implementation details and share our experience on training our system. The proposed `DeepLabv3' system significantly improves over our previous DeepLab versions without DenseCRF post-processing and attains comparable performance with other state-of-art models on the PASCAL VOC 2012 semantic image segmentation benchmark.