 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Study of Code Obfuscation Against LLM-based Vulnerability Detection
Dec 18, 2025



As large language models (LLMs) are increasingly adopted for code vulnerability detection, their reliability and robustness across diverse vulnerability types have become a pressing concern. In traditional adversarial settings, code obfuscation has long been used as a general strategy to bypass auditing tools, preserving exploitability without tampering with the tools themselves. Numerous efforts have explored obfuscation methods and tools, yet their capabilities differ in terms of supported techniques, granularity, and programming languages, making it difficult to systematically assess their impact on LLM-based vulnerability detection. To address this gap, we provide a structured systematization of obfuscation techniques and evaluate them under a unified framework. Specifically, we categorize existing obfuscation methods into three major classes (layout, data flow, and control flow) covering 11 subcategories and 19 concrete techniques. We implement these techniques across four programming languages (Solidity, C, C++, and Python) using a consistent LLM-driven approach, and evaluate their effects on 15 LLMs spanning four model families (DeepSeek, OpenAI, Qwen, and LLaMA), as well as on two coding agents (GitHub Copilot and Codex). Our findings reveal both positive and negative impacts of code obfuscation on LLM-based vulnerability detection, highlighting conditions under which obfuscation leads to performance improvements or degradations. We further analyze these outcomes with respect to vulnerability characteristics, code properties, and model attributes. Finally, we outline several open problems and propose future directions to enhance the robustness of LLMs for real-world vulnerability detection.
Enhancing All-to-X Backdoor Attacks with Optimized Target Class Mapping
Nov 17, 2025



Backdoor attacks pose severe threats to machine learning systems, prompting extensive research in this area. However, most existing work focuses on single-target All-to-One (A2O) attacks, overlooking the more complex All-to-X (A2X) attacks with multiple target classes, which are often assumed to have low attack success rates. In this paper, we first demonstrate that A2X attacks are robust against state-of-the-art defenses. We then propose a novel attack strategy that enhances the success rate of A2X attacks while maintaining robustness by optimizing grouping and target class assignment mechanisms. Our method improves the attack success rate by up to 28%, with average improvements of 6.7%, 16.4%, 14.1% on CIFAR10, CIFAR100, and Tiny-ImageNet, respectively. We anticipate that this study will raise awareness of A2X attacks and stimulate further research in this under-explored area. Our code is available at https://github.com/kazefjj/A2X-backdoor .
GTR-Mamba: Geometry-to-Tangent Routing for Hyperbolic POI Recommendation
Oct 27, 2025Next Point-of-Interest (POI) recommendation is a critical task in modern Location-Based Social Networks (LBSNs), aiming to model the complex decision-making process of human mobility to provide personalized recommendations for a user's next check-in location. Existing POI recommendation models, predominantly based on Graph Neural Networks and sequential models, have been extensively studied. However, these models face a fundamental limitation: they struggle to simultaneously capture the inherent hierarchical structure of spatial choices and the dynamics and irregular shifts of user-specific temporal contexts. To overcome this limitation, we propose GTR-Mamba, a novel framework for cross-manifold conditioning and routing. GTR-Mamba leverages the distinct advantages of different mathematical spaces for different tasks: it models the static, tree-like preference hierarchies in hyperbolic geometry, while routing the dynamic sequence updates to a novel Mamba layer in the computationally stable and efficient Euclidean tangent space. This process is coordinated by a cross-manifold channel that fuses spatio-temporal information to explicitly steer the State Space Model (SSM), enabling flexible adaptation to contextual changes. Extensive experiments on three real-world datasets demonstrate that GTR-Mamba consistently outperforms state-of-the-art baseline models in next POI recommendation.
LLM-based Human-like Traffic Simulation for Self-driving Tests
Aug 23, 2025Ensuring realistic traffic dynamics is a prerequisite for simulation platforms to evaluate the reliability of self-driving systems before deployment in the real world. Because most road users are human drivers, reproducing their diverse behaviors within simulators is vital. Existing solutions, however, typically rely on either handcrafted heuristics or narrow data-driven models, which capture only fragments of real driving behaviors and offer limited driving style diversity and interpretability. To address this gap, we introduce HDSim, an HD traffic generation framework that combines cognitive theory with large language model (LLM) assistance to produce scalable and realistic traffic scenarios within simulation platforms. The framework advances the state of the art in two ways: (i) it introduces a hierarchical driver model that represents diverse driving style traits, and (ii) it develops a Perception-Mediated Behavior Influence strategy, where LLMs guide perception to indirectly shape driver actions. Experiments reveal that embedding HDSim into simulation improves detection of safety-critical failures in self-driving systems by up to 68% and yields realism-consistent accident interpretability.
FLiP: Privacy-Preserving Federated Learning based on the Principle of Least Privileg
Oct 25, 2024



Federated Learning (FL) allows users to share knowledge instead of raw data to train a model with high accuracy. Unfortunately, during the training, users lose control over the knowledge shared, which causes serious data privacy issues. We hold that users are only willing and need to share the essential knowledge to the training task to obtain the FL model with high accuracy. However, existing efforts cannot help users minimize the shared knowledge according to the user intention in the FL training procedure. This work proposes FLiP, which aims to bring the principle of least privilege (PoLP) to FL training. The key design of FLiP is applying elaborate information reduction on the training data through a local-global dataset distillation design. We measure the privacy performance through attribute inference and membership inference attacks. Extensive experiments show that FLiP strikes a good balance between model accuracy and privacy protection.
Making Every Frame Matter: Continuous Video Understanding for Large Models via Adaptive State Modeling
Oct 19, 2024



Video understanding has become increasingly important with the rise of multi-modality applications. Understanding continuous video poses considerable challenges due to the fast expansion of streaming video, which contains multi-scale and untrimmed events. We introduce a novel system, C-VUE, to overcome these issues through adaptive state modeling. C-VUE has three key designs. The first is a long-range history modeling technique that uses a video-aware approach to retain historical video information. The second is a spatial redundancy reduction technique, which enhances the efficiency of history modeling based on temporal relations. The third is a parallel training structure that incorporates the frame-weighted loss to understand multi-scale events in long videos. Our C-VUE offers high accuracy and efficiency. It runs at speeds >30 FPS on typical edge devices and outperforms all baselines in accuracy. Moreover, applying C-VUE to a video foundation model as a video encoder in our case study resulted in a 0.46-point enhancement (on a 5-point scale) on the in-distribution dataset, and an improvement ranging from 1.19\% to 4\% on zero-shot datasets.
Training Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?
Sep 24, 2024



The emergence of text-to-image models has recently sparked significant interest, but the attendant is a looming shadow of potential infringement by violating the user terms. Specifically, an adversary may exploit data created by a commercial model to train their own without proper authorization. To address such risk, it is crucial to investigate the attribution of a suspicious model's training data by determining whether its training data originates, wholly or partially, from a specific source model. To trace the generated data, existing methods require applying extra watermarks during either the training or inference phases of the source model. However, these methods are impractical for pre-trained models that have been released, especially when model owners lack security expertise. To tackle this challenge, we propose an injection-free training data attribution method for text-to-image models. It can identify whether a suspicious model's training data stems from a source model, without additional modifications on the source model. The crux of our method lies in the inherent memorization characteristic of text-to-image models. Our core insight is that the memorization of the training dataset is passed down through the data generated by the source model to the model trained on that data, making the source model and the infringing model exhibit consistent behaviors on specific samples. Therefore, our approach involves developing algorithms to uncover these distinct samples and using them as inherent watermarks to verify if a suspicious model originates from the source model. Our experiments demonstrate that our method achieves an accuracy of over 80\% in identifying the source of a suspicious model's training data, without interfering the original training or generation process of the source model.
CoAst: Validation-Free Contribution Assessment for Federated Learning based on Cross-Round Valuation
Sep 04, 2024



In the federated learning (FL) process, since the data held by each participant is different, it is necessary to figure out which participant has a higher contribution to the model performance. Effective contribution assessment can help motivate data owners to participate in the FL training. Research works in this field can be divided into two directions based on whether a validation dataset is required. Validation-based methods need to use representative validation data to measure the model accuracy, which is difficult to obtain in practical FL scenarios. Existing validation-free methods assess the contribution based on the parameters and gradients of local models and the global model in a single training round, which is easily compromised by the stochasticity of model training. In this work, we propose CoAst, a practical method to assess the FL participants' contribution without access to any validation data. The core idea of CoAst involves two aspects: one is to only count the most important part of model parameters through a weights quantization, and the other is a cross-round valuation based on the similarity between the current local parameters and the global parameter updates in several subsequent communication rounds. Extensive experiments show that CoAst has comparable assessment reliability to existing validation-based methods and outperforms existing validation-free methods.
Manipulating Transfer Learning for Property Inference
Mar 21, 2023



Transfer learning is a popular method for tuning pretrained (upstream) models for different downstream tasks using limited data and computational resources. We study how an adversary with control over an upstream model used in transfer learning can conduct property inference attacks on a victim's tuned downstream model. For example, to infer the presence of images of a specific individual in the downstream training set. We demonstrate attacks in which an adversary can manipulate the upstream model to conduct highly effective and specific property inference attacks (AUC score $> 0.9$), without incurring significant performance loss on the main task. The main idea of the manipulation is to make the upstream model generate activations (intermediate features) with different distributions for samples with and without a target property, thus enabling the adversary to distinguish easily between downstream models trained with and without training examples that have the target property. Our code is available at https://github.com/yulongt23/Transfer-Inference.
Self-supervised Incremental Deep Graph Learning for Ethereum Phishing Scam Detection
Jun 18, 2021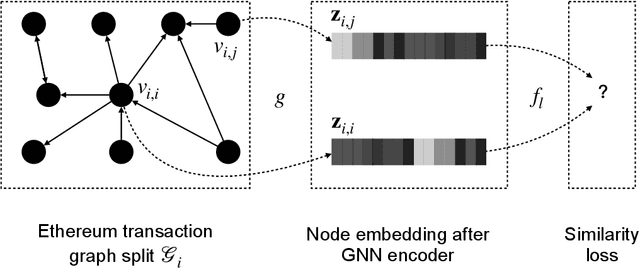

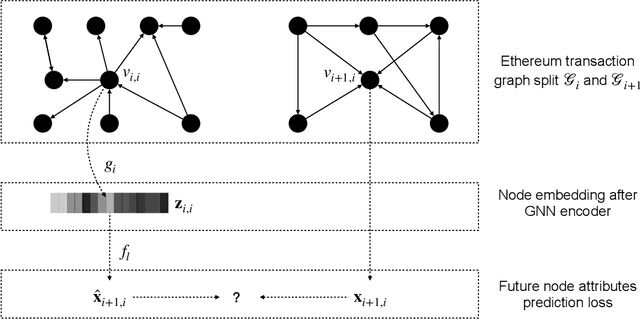
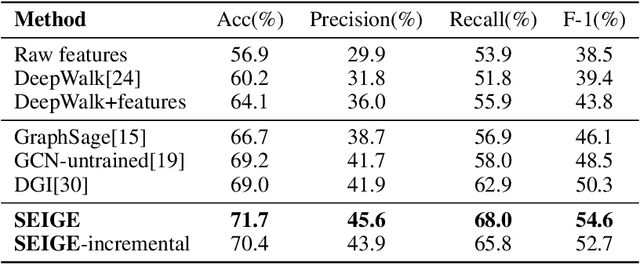
In recent years, phishing scams have become the crime type with the largest money involved on Ethereum, the second-largest blockchain platform. Meanwhile, graph neural network (GNN) has shown promising performance in various node classification tasks. However, for Ethereum transaction data, which could be naturally abstracted to a real-world complex graph, the scarcity of labels and the huge volume of transaction data make it difficult to take advantage of GNN methods. Here in this paper, to address the two challenges, we propose a Self-supervised Incremental deep Graph learning model (SIEGE), for the phishing scam detection problem on Ethereum. In our model, two pretext tasks designed from spatial and temporal perspectives help us effectively learn useful node embedding from the huge amount of unlabelled transaction data. And the incremental paradigm allows us to efficiently handle large-scale transaction data and help the model maintain good performance when the data distribution is drastically changing. We collect transaction records about half a year from Ethereum and our extensive experiments show that our model consistently outperforms strong baselines in both transductive and inductive settings.