 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Surface Scattering Parameters From SAR Images Using Differentiable Ray Tracing
Jan 02, 2024



Simulating high-resolution Synthetic Aperture Radar (SAR) images in complex scenes has consistently presented a significant research challenge. The development of a microwave-domain surface scattering model and its reversibility are poised to play a pivotal role in enhancing the authenticity of SAR image simulations and facilitating the reconstruction of target parameters. Drawing inspiration from the field of computer graphics, this paper proposes a surface microwave rendering model that comprehensively considers both Specular and Diffuse contributions. The model is analytically represented by the coherent spatially varying bidirectional scattering distribution function (CSVBSDF) based on the Kirchhoff approximation (KA) and the perturbation method (SPM). And SAR imaging is achieved through the synergistic combination of ray tracing and fast mapping projection techniques. Furthermore, a differentiable ray tracing (DRT) engine based on SAR images was constructed for CSVBSDF surface scattering parameter learning. Within this SAR image simulation engine, the use of differentiable reverse ray tracing enables the rapid estimation of parameter gradients from SAR images. The effectiveness of this approach has been validated through simulations and comparisons with real SAR images. By learning the surface scattering parameters, substantial enhancements in SAR image simulation performance under various observation conditions have been demonstrated.
Reinforcement Learning for SAR View Angle Inversion with Differentiable SAR Renderer
Jan 02, 2024The electromagnetic inverse problem has long been a research hotspot. This study aims to reverse radar view angles in synthetic aperture radar (SAR) images given a target model. Nonetheless, the scarcity of SAR data, combined with the intricate background interference and imaging mechanisms, limit the applications of existing learning-based approaches. To address these challenges, we propose an interactive deep reinforcement learning (DRL) framework, where an electromagnetic simulator named differentiable SAR render (DSR) is embedded to facilitate the interaction between the agent and the environment, simulating a human-like process of angle prediction. Specifically, DSR generates SAR images at arbitrary view angles in real-time. And the differences in sequential and semantic aspects between the view angle-corresponding images are leveraged to construct the state space in DRL, which effectively suppress the complex background interference, enhance the sensitivity to temporal variations, and improve the capability to capture fine-grained information. Additionally, in order to maintain the stability and convergence of our method, a series of reward mechanisms, such as memory difference, smoothing and boundary penalty, are utilized to form the final reward function. Extensive experiments performed on both simulated and real datasets demonstrate the effectiveness and robustness of our proposed method. When utilized in the cross-domain area, the proposed method greatly mitigates inconsistency between simulated and real domains, outperforming reference methods significantly.
Relightable and Animatable Neural Avatars from Videos
Dec 20, 2023



Lightweight creation of 3D digital avatars is a highly desirable but challenging task. With only sparse videos of a person under unknown illumination, we propose a method to create relightable and animatable neural avatars, which can be used to synthesize photorealistic images of humans under novel viewpoints, body poses, and lighting. The key challenge here is to disentangle the geometry, material of the clothed body, and lighting, which becomes more difficult due to the complex geometry and shadow changes caused by body motions. To solve this ill-posed problem, we propose novel techniques to better model the geometry and shadow changes. For geometry change modeling, we propose an invertible deformation field, which helps to solve the inverse skinning problem and leads to better geometry quality. To model the spatial and temporal varying shading cues, we propose a pose-aware part-wise light visibility network to estimate light occlusion. Extensive experiments on synthetic and real datasets show that our approach reconstructs high-quality geometry and generates realistic shadows under different body poses. Code and data are available at \url{https://wenbin-lin.github.io/RelightableAvatar-page/}.
High-Quality Facial Geometry and Appearance Capture at Home
Dec 06, 2023Facial geometry and appearance capture have demonstrated tremendous success in 3D scanning real humans in studios. Recent works propose to democratize this technique while keeping the results high quality. However, they are still inconvenient for daily usage. In addition, they focus on an easier problem of only capturing facial skin. This paper proposes a novel method for high-quality face capture, featuring an easy-to-use system and the capability to model the complete face with skin, mouth interior, hair, and eyes. We reconstruct facial geometry and appearance from a single co-located smartphone flashlight sequence captured in a dim room where the flashlight is the dominant light source (e.g. rooms with curtains or at night). To model the complete face, we propose a novel hybrid representation to effectively model both eyes and other facial regions, along with novel techniques to learn it from images. We apply a combined lighting model to compactly represent real illuminations and exploit a morphable face albedo model as a reflectance prior to disentangle diffuse and specular. Experiments show that our method can capture high-quality 3D relightable scans.
Open-sourced Data Ecosystem in Autonomous Driving: the Present and Future
Dec 06, 2023



With the continuous maturation and application of autonomous driving technology, a systematic examination of open-source autonomous driving datasets becomes instrumental in fostering the robust evolution of the industry ecosystem. Current autonomous driving datasets can broadly be categorized into two generations. The first-generation autonomous driving datasets are characterized by relatively simpler sensor modalities, smaller data scale, and is limited to perception-level tasks. KITTI, introduced in 2012, serves as a prominent representative of this initial wave. In contrast, the second-generation datasets exhibit heightened complexity in sensor modalities, greater data scale and diversity, and an expansion of tasks from perception to encompass prediction and control. Leading examples of the second generation include nuScenes and Waymo, introduced around 2019. This comprehensive review, conducted in collaboration with esteemed colleagues from both academia and industry, systematically assesses over seventy open-source autonomous driving datasets from domestic and international sources. It offers insights into various aspects, such as the principles underlying the creation of high-quality datasets, the pivotal role of data engine systems, and the utilization of generative foundation models to facilitate scalable data generation. Furthermore, this review undertakes an exhaustive analysis and discourse regarding the characteristics and data scales that future third-generation autonomous driving datasets should possess. It also delves into the scientific and technical challenges that warrant resolution. These endeavors are pivotal in advancing autonomous innovation and fostering technological enhancement in critical domains. For further details, please refer to https://github.com/OpenDriveLab/DriveAGI.
GaussianHead: Impressive 3D Gaussian-based Head Avatars with Dynamic Hybrid Neural Field
Dec 04, 2023



Previous head avatar methods have mostly relied on fixed explicit primitives (mesh, point) or implicit surfaces (Sign Distance Function) and volumetric neural radiance field, it challenging to strike a balance among high fidelity, training speed, and resource consumption. The recent popularity of hybrid field has brought novel representation, but is limited by relying on parameterization factors obtained through fixed mappings. We propose GaussianHead: an head avatar algorithm based on anisotropic 3D gaussian primitives. We leverage canonical gaussians to represent dynamic scenes. Using explicit "dynamic" tri-plane as an efficient container for parameterized head geometry, aligned well with factors in the underlying geometry and tri-plane, we obtain aligned canonical factors for the canonical gaussians. With a tiny MLP, factors are decoded into opacity and spherical harmonic coefficients of 3D gaussian primitives. Finally, we use efficient differentiable gaussian rasterizer for rendering. Our approach benefits significantly from our novel representation based on 3D gaussians, and the proper alignment transformation of underlying geometry structures and factors in tri-plane eliminates biases introduced by fixed mappings. Compared to state-of-the-art techniques, we achieve optimal visual results in tasks such as self-reconstruction, novel view synthesis, and cross-identity reenactment while maintaining high rendering efficiency (0.12s per frame). Even the pores around the nose are clearly visible in some cases. Code and additional video can be found on the project homepage.
Fusing Monocular Images and Sparse IMU Signals for Real-time Human Motion Capture
Sep 01, 2023Either RGB images or inertial signals have been used for the task of motion capture (mocap), but combining them together is a new and interesting topic. We believe that the combination is complementary and able to solve the inherent difficulties of using one modality input, including occlusions, extreme lighting/texture, and out-of-view for visual mocap and global drifts for inertial mocap. To this end, we propose a method that fuses monocular images and sparse IMUs for real-time human motion capture. Our method contains a dual coordinate strategy to fully explore the IMU signals with different goals in motion capture. To be specific, besides one branch transforming the IMU signals to the camera coordinate system to combine with the image information, there is another branch to learn from the IMU signals in the body root coordinate system to better estimate body poses. Furthermore, a hidden state feedback mechanism is proposed for both two branches to compensate for their own drawbacks in extreme input cases. Thus our method can easily switch between the two kinds of signals or combine them in different cases to achieve a robust mocap. %The two divided parts can help each other for better mocap results under different conditions. Quantitative and qualitative results demonstrate that by delicately designing the fusion method, our technique significantly outperforms the state-of-the-art vision, IMU, and combined methods on both global orientation and local pose estimation. Our codes are available for research at https://shaohua-pan.github.io/robustcap-page/.
SAR-NeRF: Neural Radiance Fields for Synthetic Aperture Radar Multi-View Representation
Jul 11, 2023SAR images are highly sensitive to observation configurations, and they exhibit significant variations across different viewing angles, making it challenging to represent and learn their anisotropic features. As a result, deep learning methods often generalize poorly across different view angles. Inspired by the concept of neural radiance fields (NeRF), this study combines SAR imaging mechanisms with neural networks to propose a novel NeRF model for SAR image generation. Following the mapping and projection pinciples, a set of SAR images is modeled implicitly as a function of attenuation coefficients and scattering intensities in the 3D imaging space through a differentiable rendering equation. SAR-NeRF is then constructed to learn the distribution of attenuation coefficients and scattering intensities of voxels, where the vectorized form of 3D voxel SAR rendering equation and the sampling relationship between the 3D space voxels and the 2D view ray grids are analytically derived. Through quantitative experiments on various datasets, we thoroughly assess the multi-view representation and generalization capabilities of SAR-NeRF. Additionally, it is found that SAR-NeRF augumented dataset can significantly improve SAR target classification performance under few-shot learning setup, where a 10-type classification accuracy of 91.6\% can be achieved by using only 12 images per class.
Physics-assisted Deep Learning for FMCW Radar Quantitative Imaging of Two-dimension Target
Jul 05, 2023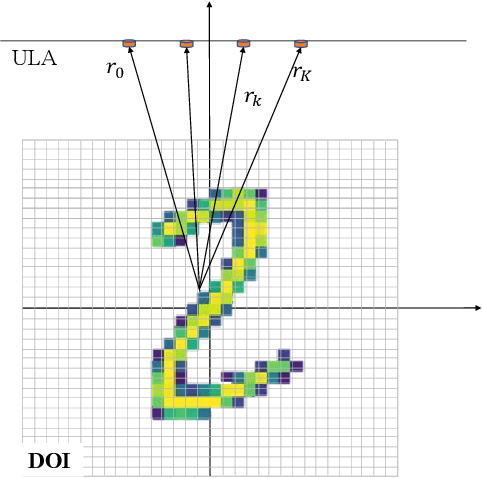
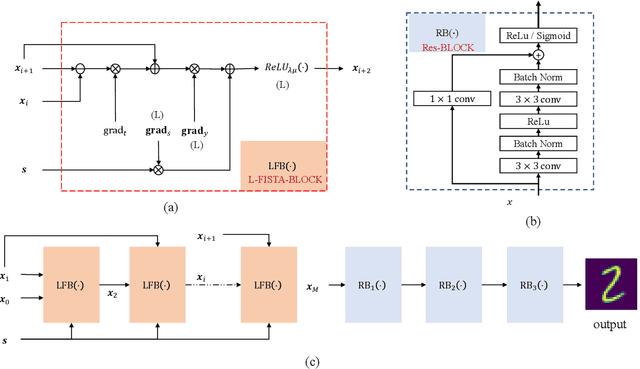


Radar imaging is crucial in remote sensing and has many applications in detection and autonomous driving. However, the received radar signal for imaging is enormous and redundant, which degrades the speed of real-time radar quantitative imaging and leads to obstacles in the downlink applications. In this paper, we propose a physics-assisted deep learning method for radar quantitative imaging with the advantage of compressed sensing (CS). Specifically, the signal model for frequency-modulated continuous-wave (FMCW) radar imaging which only uses four antennas and parts of frequency components is formulated in terms of matrices multiplication. The learned fast iterative shrinkage-thresholding algorithm with residual neural network (L-FISTA-ResNet) is proposed for solving the quantitative imaging problem. The L-FISTA is developed to ensure the basic solution and ResNet is attached to enhance the image quality. Simulation results show that our proposed method has higher reconstruction accuracy than the traditional optimization method and pure neural networks. The effectiveness and generalization performance of the proposed strategy is verified in unseen target imaging, denoising, and frequency migration tasks.
Conceptual Study and Performance Analysis of Tandem Dual-Antenna Spaceborne SAR Interferometry
Jun 17, 2023Multi-baseline synthetic aperture radar interferometry (MB-InSAR), capable of mapping 3D surface model with high precision, is able to overcome the ill-posed problem in the single-baseline InSAR by use of the baseline diversity. Single pass MB acquisition with the advantages of high coherence and simple phase components has a more practical capability in 3D reconstruction than conventional repeat-pass MB acquisition. Using an asymptotic 3D phase unwrapping (PU), it is possible to get a reliable 3D reconstruction using very sparse acquisitions but the interferograms should follow the optimal baseline design. However, current spaceborne SAR system doesn't satisfy this principle, inducing more difficulties in practical application. In this article, a new concept of Tandem Dual-Antenna SAR Interferometry (TDA-InSAR) system for single-pass reliable 3D surface mapping using the asymptotic 3D PU is proposed. Its optimal MB acquisition is analyzed to achieve both good relative height precision and flexible baseline design. Two indicators, i.e., expected relative height precision and successful phase unwrapping rate, are selected to optimize the system parameters and evaluate the performance of various baseline configurations. Additionally, simulation-based demonstrations are conducted to evaluate the performance in typical scenarios and investigate the impact of various error sources. The results indicate that the proposed TDA-InSAR is able to get the specified MB acquisition for the asymptotic 3D PU, which offers a feasible solution for single-pass 3D SAR imaging.