 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupeRGB-D: Zero-shot Instance Segmentation in Cluttered Indoor Environments
Dec 22, 2022



Object instance segmentation is a key challenge for indoor robots navigating cluttered environments with many small objects. Limitations in 3D sensing capabilities often make it difficult to detect every possible object. While deep learning approaches may be effective for this problem, manually annotating 3D data for supervised learning is time-consuming. In this work, we explore zero-shot instance segmentation (ZSIS) from RGB-D data to identify unseen objects in a semantic category-agnostic manner. We introduce a zero-shot split for Tabletop Objects Dataset (TOD-Z) to enable this study and present a method that uses annotated objects to learn the ``objectness'' of pixels and generalize to unseen object categories in cluttered indoor environments. Our method, SupeRGB-D, groups pixels into small patches based on geometric cues and learns to merge the patches in a deep agglomerative clustering fashion. SupeRGB-D outperforms existing baselines on unseen objects while achieving similar performance on seen objects. Additionally, it is extremely lightweight (0.4 MB memory requirement) and suitable for mobile and robotic applications. The dataset split and code will be made publicly available upon acceptance.
SST: Real-time End-to-end Monocular 3D Reconstruction via Sparse Spatial-Temporal Guidance
Dec 13, 2022Real-time monocular 3D reconstruction is a challenging problem that remains unsolved. Although recent end-to-end methods have demonstrated promising results, tiny structures and geometric boundaries are hardly captured due to their insufficient supervision neglecting spatial details and oversimplified feature fusion ignoring temporal cues. To address the problems, we propose an end-to-end 3D reconstruction network SST, which utilizes Sparse estimated points from visual SLAM system as additional Spatial guidance and fuses Temporal features via a novel cross-modal attention mechanism, achieving more detailed reconstruction results. We propose a Local Spatial-Temporal Fusion module to exploit more informative spatial-temporal cues from multi-view color information and sparse priors, as well a Global Spatial-Temporal Fusion module to refine the local TSDF volumes with the world-frame model from coarse to fine. Extensive experiments on ScanNet and 7-Scenes demonstrate that SST outperforms all state-of-the-art competitors, whilst keeping a high inference speed at 59 FPS, enabling real-world applications with real-time requirements.
I2MVFormer: Large Language Model Generated Multi-View Document Supervision for Zero-Shot Image Classification
Dec 05, 2022Recent works have shown that unstructured text (documents) from online sources can serve as useful auxiliary information for zero-shot image classification. However, these methods require access to a high-quality source like Wikipedia and are limited to a single source of information. Large Language Models (LLM) trained on web-scale text show impressive abilities to repurpose their learned knowledge for a multitude of tasks. In this work, we provide a novel perspective on using an LLM to provide text supervision for a zero-shot image classification model. The LLM is provided with a few text descriptions from different annotators as examples. The LLM is conditioned on these examples to generate multiple text descriptions for each class(referred to as views). Our proposed model, I2MVFormer, learns multi-view semantic embeddings for zero-shot image classification with these class views. We show that each text view of a class provides complementary information allowing a model to learn a highly discriminative class embedding. Moreover, we show that I2MVFormer is better at consuming the multi-view text supervision from LLM compared to baseline models. I2MVFormer establishes a new state-of-the-art on three public benchmark datasets for zero-shot image classification with unsupervised semantic embeddings.
LatentSwap3D: Semantic Edits on 3D Image GANs
Dec 02, 2022


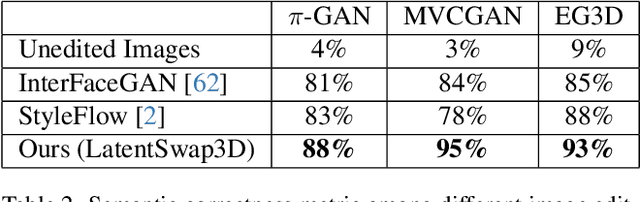
Recent 3D-aware GANs rely on volumetric rendering techniques to disentangle the pose and appearance of objects, de facto generating entire 3D volumes rather than single-view 2D images from a latent code. Complex image editing tasks can be performed in standard 2D-based GANs (e.g., StyleGAN models) as manipulation of latent dimensions. However, to the best of our knowledge, similar properties have only been partially explored for 3D-aware GAN models. This work aims to fill this gap by showing the limitations of existing methods and proposing LatentSwap3D, a model-agnostic approach designed to enable attribute editing in the latent space of pre-trained 3D-aware GANs. We first identify the most relevant dimensions in the latent space of the model controlling the targeted attribute by relying on the feature importance ranking of a random forest classifier. Then, to apply the transformation, we swap the top-K most relevant latent dimensions of the image being edited with an image exhibiting the desired attribute. Despite its simplicity, LatentSwap3D provides remarkable semantic edits in a disentangled manner and outperforms alternative approaches both qualitatively and quantitatively. We demonstrate our semantic edit approach on various 3D-aware generative models such as pi-GAN, GIRAFFE, StyleSDF, MVCGAN, EG3D and VolumeGAN, and on diverse datasets, such as FFHQ, AFHQ, Cats, MetFaces, and CompCars. The project page can be found: \url{https://enisimsar.github.io/latentswap3d/}.
SPARF: Neural Radiance Fields from Sparse and Noisy Poses
Nov 21, 2022



Neural Radiance Field (NeRF) has recently emerged as a powerful representation to synthesize photorealistic novel views. While showing impressive performance, it relies on the availability of dense input views with highly accurate camera poses, thus limiting its application in real-world scenarios. In this work, we introduce Sparse Pose Adjusting Radiance Field (SPARF), to address the challenge of novel-view synthesis given only few wide-baseline input images (as low as 3) with noisy camera poses. Our approach exploits multi-view geometry constraints in order to jointly learn the NeRF and refine the camera poses. By relying on pixel matches extracted between the input views, our multi-view correspondence objective enforces the optimized scene and camera poses to converge to a global and geometrically accurate solution. Our depth consistency loss further encourages the reconstructed scene to be consistent from any viewpoint. Our approach sets a new state of the art in the sparse-view regime on multiple challenging datasets.
Shape, Pose, and Appearance from a Single Image via Bootstrapped Radiance Field Inversion
Nov 21, 2022



Neural Radiance Fields (NeRF) coupled with GANs represent a promising direction in the area of 3D reconstruction from a single view, owing to their ability to efficiently model arbitrary topologies. Recent work in this area, however, has mostly focused on synthetic datasets where exact ground-truth poses are known, and has overlooked pose estimation, which is important for certain downstream applications such as augmented reality (AR) and robotics. We introduce a principled end-to-end reconstruction framework for natural images, where accurate ground-truth poses are not available. Our approach recovers an SDF-parameterized 3D shape, pose, and appearance from a single image of an object, without exploiting multiple views during training. More specifically, we leverage an unconditional 3D-aware generator, to which we apply a hybrid inversion scheme where a model produces a first guess of the solution which is then refined via optimization. Our framework can de-render an image in as few as 10 steps, enabling its use in practical scenarios. We demonstrate state-of-the-art results on a variety of real and synthetic benchmarks.
DisPositioNet: Disentangled Pose and Identity in Semantic Image Manipulation
Nov 10, 2022



Graph representation of objects and their relations in a scene, known as a scene graph, provides a precise and discernible interface to manipulate a scene by modifying the nodes or the edges in the graph. Although existing works have shown promising results in modifying the placement and pose of objects, scene manipulation often leads to losing some visual characteristics like the appearance or identity of objects. In this work, we propose DisPositioNet, a model that learns a disentangled representation for each object for the task of image manipulation using scene graphs in a self-supervised manner. Our framework enables the disentanglement of the variational latent embeddings as well as the feature representation in the graph. In addition to producing more realistic images due to the decomposition of features like pose and identity, our method takes advantage of the probabilistic sampling in the intermediate features to generate more diverse images in object replacement or addition tasks. The results of our experiments show that disentangling the feature representations in the latent manifold of the model outperforms the previous works qualitatively and quantitatively on two public benchmarks. Project Page: https://scenegenie.github.io/DispositioNet/
ParGAN: Learning Real Parametrizable Transformations
Nov 09, 2022Current methods for image-to-image translation produce compelling results, however, the applied transformation is difficult to control, since existing mechanisms are often limited and non-intuitive. We propose ParGAN, a generalization of the cycle-consistent GAN framework to learn image transformations with simple and intuitive controls. The proposed generator takes as input both an image and a parametrization of the transformation. We train this network to preserve the content of the input image while ensuring that the result is consistent with the given parametrization. Our approach does not require paired data and can learn transformations across several tasks and datasets. We show how, with disjoint image domains with no annotated parametrization, our framework can create smooth interpolations as well as learn multiple transformations simultaneously.
OPA-3D: Occlusion-Aware Pixel-Wise Aggregation for Monocular 3D Object Detection
Nov 02, 2022



Despite monocular 3D object detection having recently made a significant leap forward thanks to the use of pre-trained depth estimators for pseudo-LiDAR recovery, such two-stage methods typically suffer from overfitting and are incapable of explicitly encapsulating the geometric relation between depth and object bounding box. To overcome this limitation, we instead propose OPA-3D, a single-stage, end-to-end, Occlusion-Aware Pixel-Wise Aggregation network that to jointly estimate dense scene depth with depth-bounding box residuals and object bounding boxes, allowing a two-stream detection of 3D objects, leading to significantly more robust detections. Thereby, the geometry stream denoted as the Geometry Stream, combines visible depth and depth-bounding box residuals to recover the object bounding box via explicit occlusion-aware optimization. In addition, a bounding box based geometry projection scheme is employed in an effort to enhance distance perception. The second stream, named as the Context Stream, directly regresses 3D object location and size. This novel two-stream representation further enables us to enforce cross-stream consistency terms which aligns the outputs of both streams, improving the overall performance. Extensive experiments on the public benchmark demonstrate that OPA-3D outperforms state-of-the-art methods on the main Car category, whilst keeping a real-time inference speed. We plan to release all codes and trained models soon.
MonoGraspNet: 6-DoF Grasping with a Single RGB Image
Sep 26, 2022
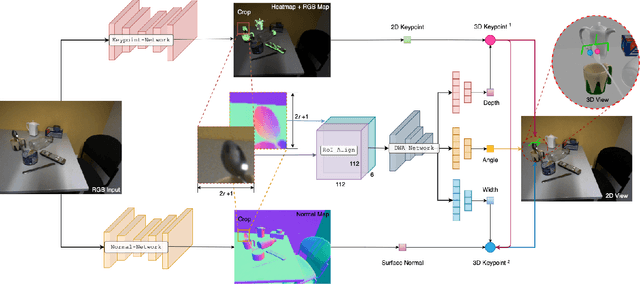
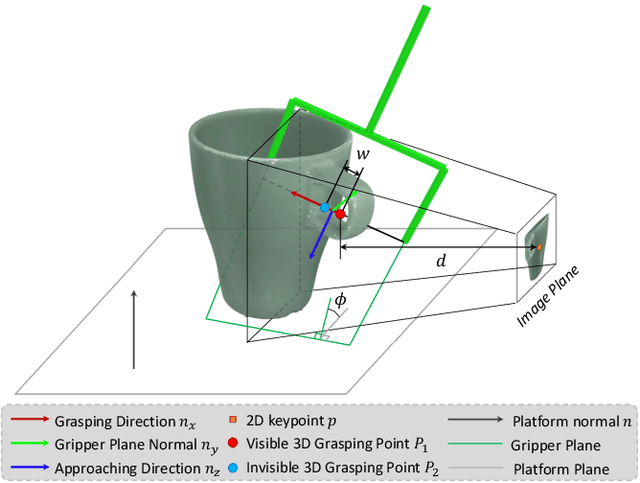

6-DoF robotic grasping is a long-lasting but unsolved problem. Recent methods utilize strong 3D networks to extract geometric grasping representations from depth sensors, demonstrating superior accuracy on common objects but perform unsatisfactorily on photometrically challenging objects, e.g., objects in transparent or reflective materials. The bottleneck lies in that the surface of these objects can not reflect back accurate depth due to the absorption or refraction of light. In this paper, in contrast to exploiting the inaccurate depth data, we propose the first RGB-only 6-DoF grasping pipeline called MonoGraspNet that utilizes stable 2D features to simultaneously handle arbitrary object grasping and overcome the problems induced by photometrically challenging objects. MonoGraspNet leverages keypoint heatmap and normal map to recover the 6-DoF grasping poses represented by our novel representation parameterized with 2D keypoints with corresponding depth, grasping direction, grasping width, and angle. Extensive experiments in real scenes demonstrate that our method can achieve competitive results in grasping common objects and surpass the depth-based competitor by a large margin in grasping photometrically challenging objects. To further stimulate robotic manipulation research, we additionally annotate and open-source a multi-view and multi-scene real-world grasping dataset, containing 120 objects of mixed photometric complexity with 20M accurate grasping labels.