 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo ever larger octopi still amplify reporting biases? Evidence from judgments of typical colour
Sep 26, 2022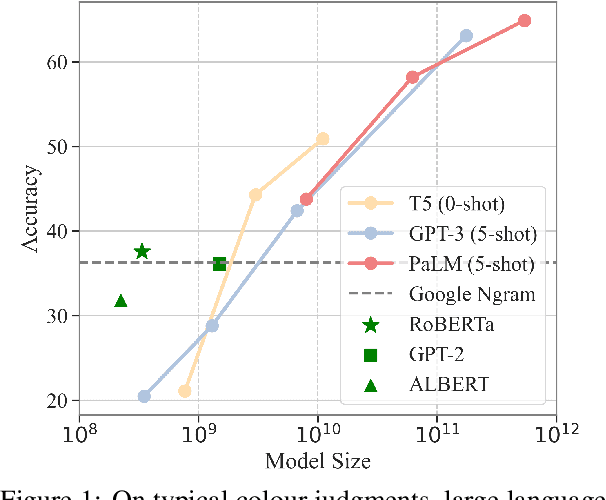

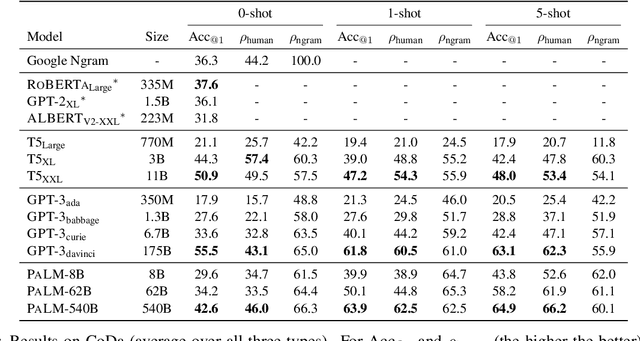
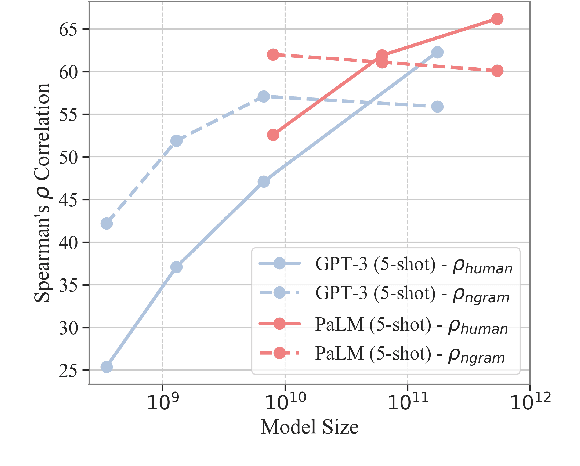
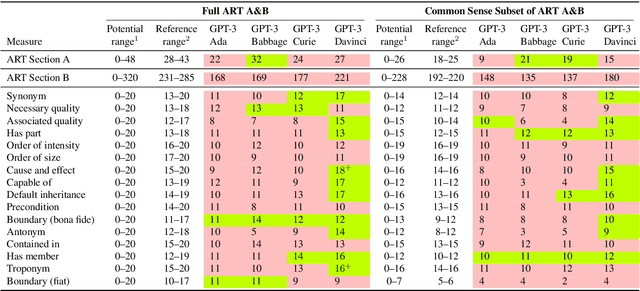
Language models (LMs) trained on raw texts have no direct access to the physical world. Gordon and Van Durme (2013) point out that LMs can thus suffer from reporting bias: texts rarely report on common facts, instead focusing on the unusual aspects of a situation. If LMs are only trained on text corpora and naively memorise local co-occurrence statistics, they thus naturally would learn a biased view of the physical world. While prior studies have repeatedly verified that LMs of smaller scales (e.g., RoBERTa, GPT-2) amplify reporting bias, it remains unknown whether such trends continue when models are scaled up. We investigate reporting bias from the perspective of colour in larger language models (LLMs) such as PaLM and GPT-3. Specifically, we query LLMs for the typical colour of objects, which is one simple type of perceptually grounded physical common sense. Surprisingly, we find that LLMs significantly outperform smaller LMs in determining an object's typical colour and more closely track human judgments, instead of overfitting to surface patterns stored in texts. This suggests that very large models of language alone are able to overcome certain types of reporting bias that are characterized by local co-occurrences.
WinoDict: Probing language models for in-context word acquisition
Sep 25, 2022
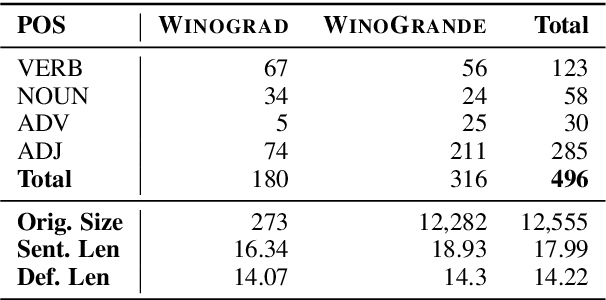
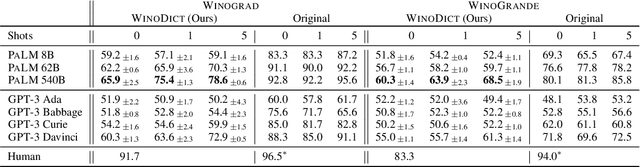
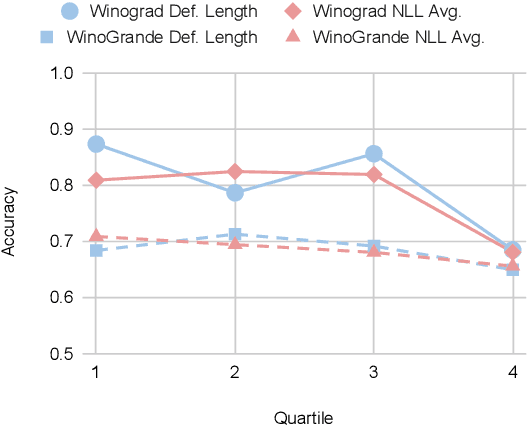
We introduce a new in-context learning paradigm to measure Large Language Models' (LLMs) ability to learn novel words during inference. In particular, we rewrite Winograd-style co-reference resolution problems by replacing the key concept word with a synthetic but plausible word that the model must understand to complete the task. Solving this task requires the model to make use of the dictionary definition of the new word given in the prompt. This benchmark addresses word acquisition, one important aspect of the diachronic degradation known to afflict LLMs. As LLMs are frozen in time at the moment they are trained, they are normally unable to reflect the way language changes over time. We show that the accuracy of LLMs compared to the original Winograd tasks decreases radically in our benchmark, thus identifying a limitation of current models and providing a benchmark to measure future improvements in LLMs ability to do in-context learning.
On Reality and the Limits of Language Data
Aug 25, 2022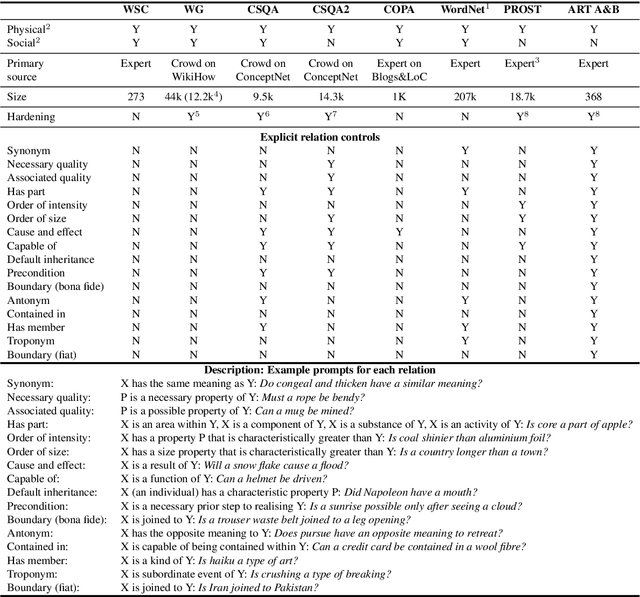
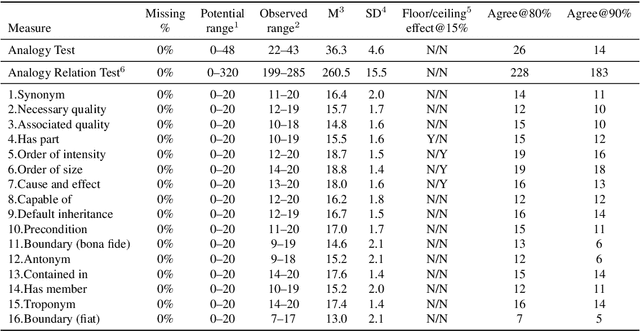
Recent advances in neural network language models have shown that it is possible to derive expressive meaning representations by leveraging linguistic associations in large-scale natural language data. These potentially Gestalt representations have enabled state-of-the-art performance for many practical applications. It would appear that we are on a pathway to empirically deriving a robust and expressive computable semantics. A key question that arises is how far can language data alone enable computers to understand the necessary truth about the physical world? Attention to this question is warranted because our future interactions with intelligent machines depends on how well our techniques correctly represent and process the concepts (objects, properties, and processes) that humans commonly observe to be true. After reviewing existing protocols, the objective of this work is to explore this question using a novel and tightly controlled reasoning test and to highlight what models might learn directly from pure linguistic data.
TweetNLP: Cutting-Edge Natural Language Processing for Social Media
Jun 29, 2022
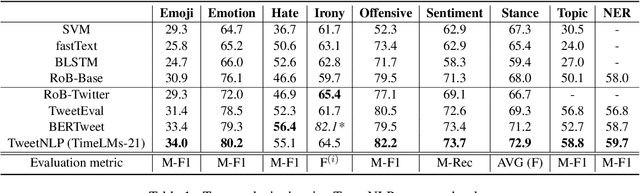
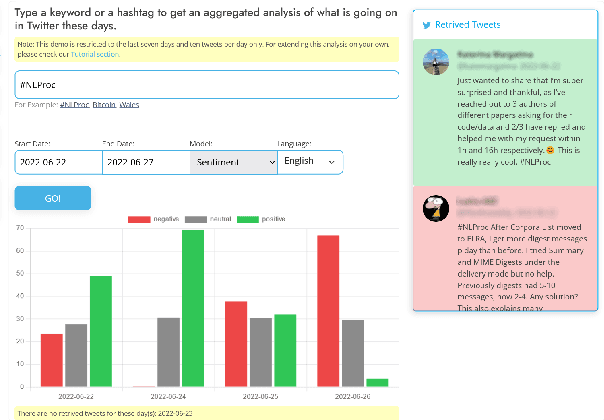

In this paper we present TweetNLP, an integrated platform for Natural Language Processing (NLP) in social media. TweetNLP supports a diverse set of NLP tasks, including generic focus areas such as sentiment analysis and named entity recognition, as well as social media-specific tasks such as emoji prediction and offensive language identification. Task-specific systems are powered by reasonably-sized Transformer-based language models specialized on social media text (in particular, Twitter) which can be run without the need for dedicated hardware or cloud services. The main contributions of TweetNLP are: (1) an integrated Python library for a modern toolkit supporting social media analysis using our various task-specific models adapted to the social domain; (2) an interactive online demo for codeless experimentation using our models; and (3) a tutorial covering a wide variety of typical social media applications.
Language Models Can See: Plugging Visual Controls in Text Generation
May 05, 2022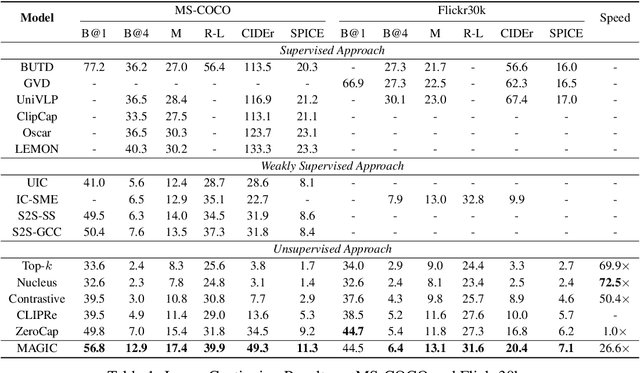

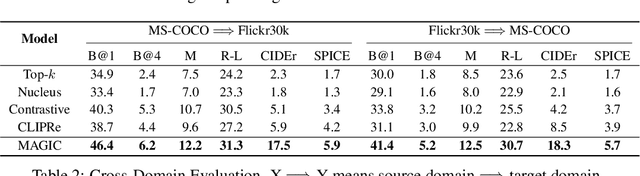

Generative language models (LMs) such as GPT-2/3 can be prompted to generate text with remarkable quality. While they are designed for text-prompted generation, it remains an open question how the generation process could be guided by modalities beyond text such as images. In this work, we propose a training-free framework, called MAGIC (iMAge-Guided text generatIon with CLIP), for plugging in visual controls in the generation process and enabling LMs to perform multimodal tasks (e.g., image captioning) in a zero-shot manner. MAGIC is a simple yet efficient plug-and-play framework, which directly combines an off-the-shelf LM (i.e., GPT-2) and an image-text matching model (i.e., CLIP) for image-grounded text generation. During decoding, MAGIC influences the generation of the LM by introducing a CLIP-induced score, called magic score, which regularizes the generated result to be semantically related to a given image while being coherent to the previously generated context. Notably, the proposed decoding scheme does not involve any gradient update operation, therefore being computationally efficient. On the challenging task of zero-shot image captioning, MAGIC outperforms the state-of-the-art method by notable margins with a nearly 27 times decoding speedup. MAGIC is a flexible framework and is theoretically compatible with any text generation tasks that incorporate image grounding. In the experiments, we showcase that it is also capable of performing visually grounded story generation given both an image and a text prompt.
Visual Spatial Reasoning
Apr 30, 2022


Spatial relations are fundamental to human cognition and are the most basic knowledge for us to understand and communicate about our physical surroundings. In this paper, we ask the critical question: Are current vision-and-language models (VLMs) able to correctly understand spatial relations? To answer this question, we propose Visual Spatial Reasoning (VSR), a novel benchmark task with human labelled dataset for investigating VLMs' capabilities in recognising 65 types of spatial relationships (e.g., under, in front of, facing etc.) in natural text-image pairs. Specifically, given a caption and an image, the model needs to perform binary classification and decide if the caption accurately describes the spatial relationships of two objects presented in the image. While being seemingly simple and straightforward, the task shows a large gap between human and model performance (human ceiling on the VSR task is above 95% and models only achieve around 70%). With fine-grained categorisation and control on both concepts and relations, our VSR benchmark enables us to perform interesting probing analysis to pinpoint VLMs' failure cases and the reasons behind. We observe that VLMs' by-relation performances have little correlation with the number of training examples and the tested models are in general incapable of recognising relations that concern orientations of objects. Also, VLMs have poor zero-shot generalisation toward unseen concepts. The dataset and code are released at github.com/cambridgeltl/visual-spatial-reasoning.
Exposing Cross-Lingual Lexical Knowledge from Multilingual Sentence Encoders
Apr 30, 2022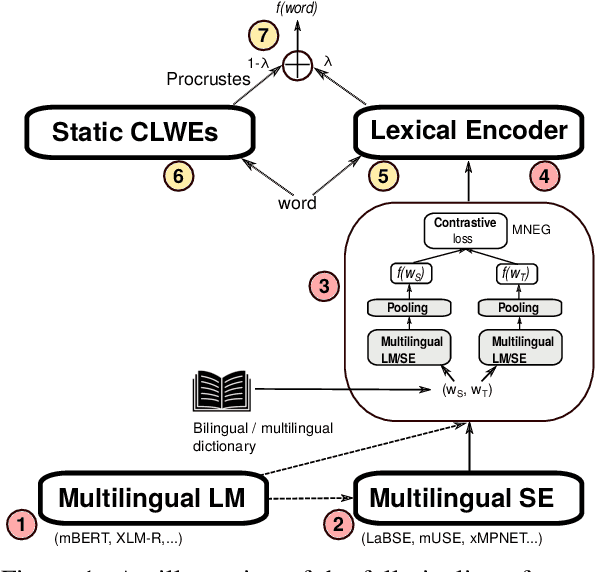
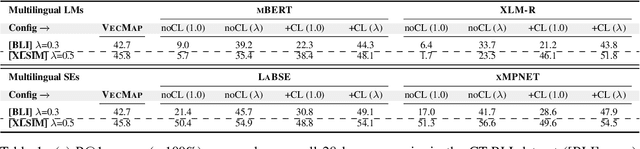
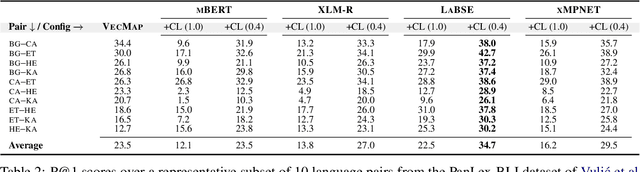

Pretrained multilingual language models (LMs) can be successfully transformed into multilingual sentence encoders (SEs; e.g., LaBSE, xMPNET) via additional fine-tuning or model distillation on parallel data. However, it remains uncertain how to best leverage their knowledge to represent sub-sentence lexical items (i.e., words and phrases) in cross-lingual lexical tasks. In this work, we probe these SEs for the amount of cross-lingual lexical knowledge stored in their parameters, and compare them against the original multilingual LMs. We also devise a novel method to expose this knowledge by additionally fine-tuning multilingual models through inexpensive contrastive learning procedure, requiring only a small amount of word translation pairs. We evaluate our method on bilingual lexical induction (BLI), cross-lingual lexical semantic similarity, and cross-lingual entity linking, and report substantial gains on standard benchmarks (e.g., +10 Precision@1 points in BLI), validating that the SEs such as LaBSE can be 'rewired' into effective cross-lingual lexical encoders. Moreover, we show that resulting representations can be successfully interpolated with static embeddings from cross-lingual word embedding spaces to further boost the performance in lexical tasks. In sum, our approach provides an effective tool for exposing and harnessing multilingual lexical knowledge 'hidden' in multilingual sentence encoders.
Modality-Balanced Embedding for Video Retrieval
Apr 18, 2022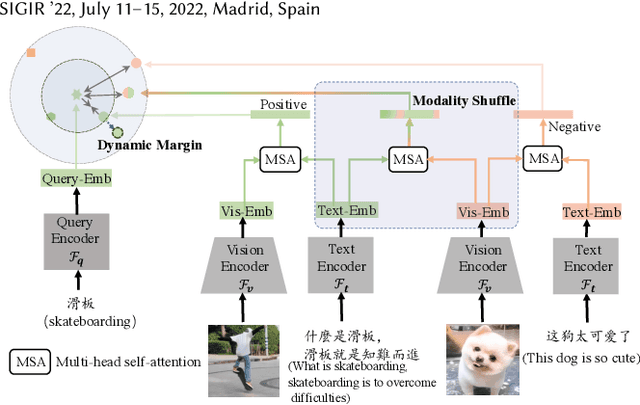
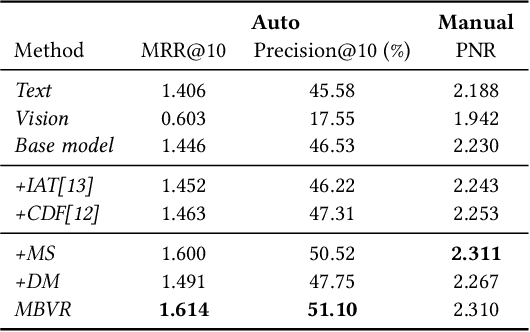
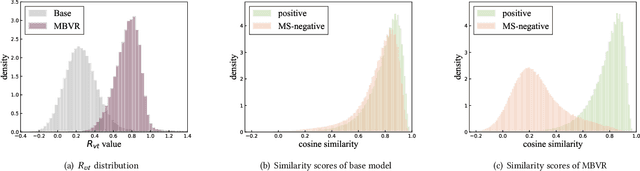
Video search has become the main routine for users to discover videos relevant to a text query on large short-video sharing platforms. During training a query-video bi-encoder model using online search logs, we identify a modality bias phenomenon that the video encoder almost entirely relies on text matching, neglecting other modalities of the videos such as vision, audio. This modality imbalanceresults from a) modality gap: the relevance between a query and a video text is much easier to learn as the query is also a piece of text, with the same modality as the video text; b) data bias: most training samples can be solved solely by text matching. Here we share our practices to improve the first retrieval stage including our solution for the modality imbalance issue. We propose MBVR (short for Modality Balanced Video Retrieval) with two key components: manually generated modality-shuffled (MS) samples and a dynamic margin (DM) based on visual relevance. They can encourage the video encoder to pay balanced attentions to each modality. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving modality bias problem. We have also deployed our MBVR in a large video platform and observed statistically significant boost over a highly optimized baseline in an A/B test and manual GSB evaluations.
* Accepted by SIGIR-2022, short paper
Improving Word Translation via Two-Stage Contrastive Learning
Mar 26, 2022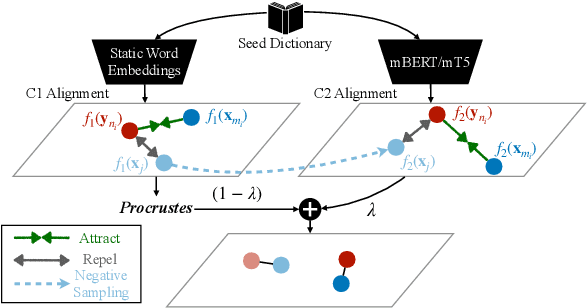
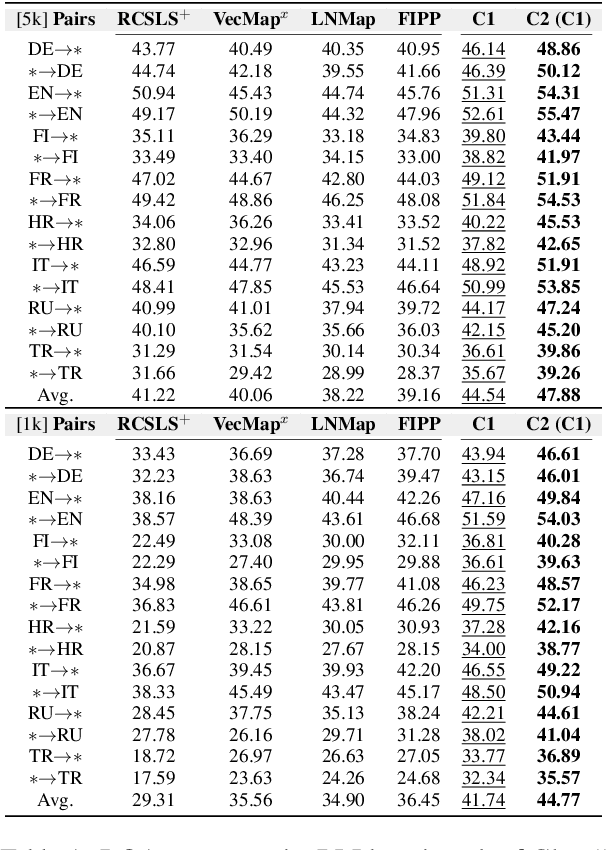
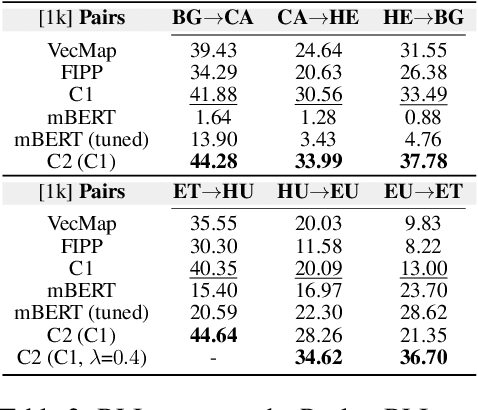

Word translation or bilingual lexicon induction (BLI) is a key cross-lingual task, aiming to bridge the lexical gap between different languages. In this work, we propose a robust and effective two-stage contrastive learning framework for the BLI task. At Stage C1, we propose to refine standard cross-lingual linear maps between static word embeddings (WEs) via a contrastive learning objective; we also show how to integrate it into the self-learning procedure for even more refined cross-lingual maps. In Stage C2, we conduct BLI-oriented contrastive fine-tuning of mBERT, unlocking its word translation capability. We also show that static WEs induced from the `C2-tuned' mBERT complement static WEs from Stage C1. Comprehensive experiments on standard BLI datasets for diverse languages and different experimental setups demonstrate substantial gains achieved by our framework. While the BLI method from Stage C1 already yields substantial gains over all state-of-the-art BLI methods in our comparison, even stronger improvements are met with the full two-stage framework: e.g., we report gains for 112/112 BLI setups, spanning 28 language pairs.
Revisiting Parameter-Efficient Tuning: Are We Really There Yet?
Feb 16, 2022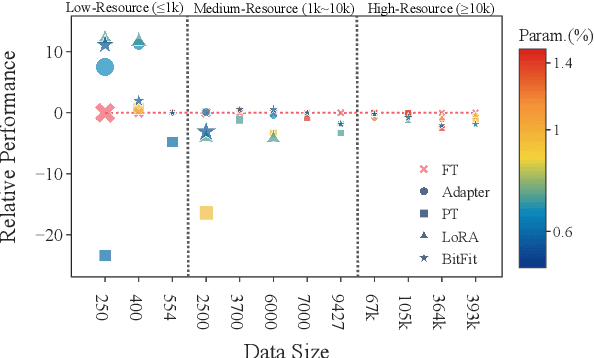
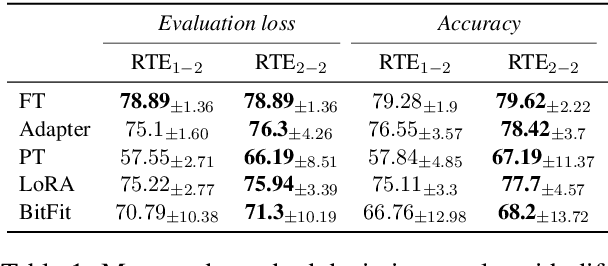
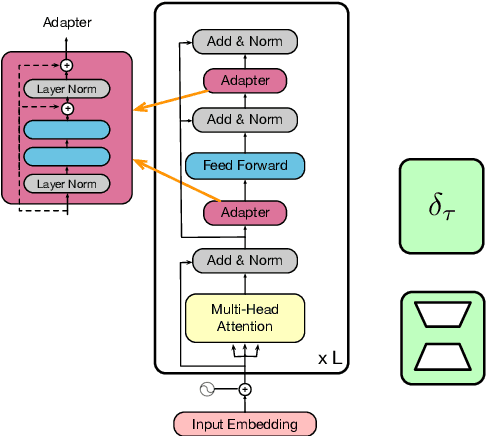
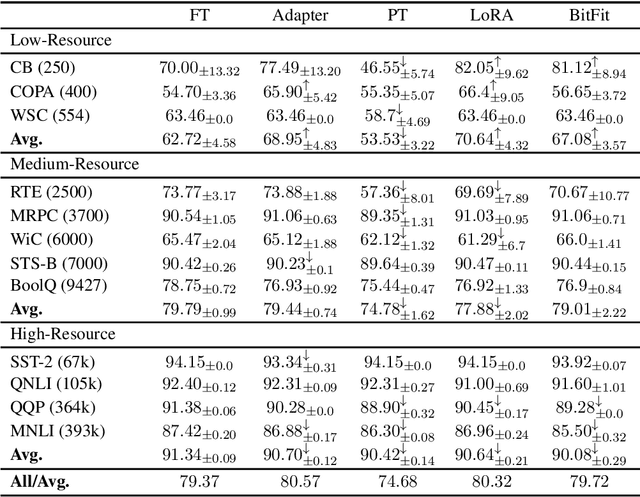
Parameter-efficient tuning (PETuning) methods have been deemed by many as the new paradigm for using pretrained language models (PLMs). By tuning just a fraction amount of parameters comparing to full model finetuning, PETuning methods claim to have achieved performance on par with or even better than finetuning. In this work, we take a step back and re-examine these PETuning methods by conducting the first comprehensive investigation into the training and evaluation of PETuning methods. We found the problematic validation and testing practice in current studies, when accompanied by the instability nature of PETuning methods, has led to unreliable conclusions. When being compared under a truly fair evaluation protocol, PETuning cannot yield consistently competitive performance while finetuning remains to be the best-performing method in medium- and high-resource settings. We delve deeper into the cause of the instability and observed that model size does not explain the phenomenon but training iteration positively correlates with the stability.