 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Graph Classification: failure modes, causes, and noise-resistant loss in Graph Neural Networks
Dec 11, 2024Graph Neural Networks (GNNs) are powerful at solving graph classification tasks, yet applied problems often contain noisy labels. In this work, we study GNN robustness to label noise, demonstrate GNN failure modes when models struggle to generalise on low-order graphs, low label coverage, or when a model is over-parameterized. We establish both empirical and theoretical links between GNN robustness and the reduction of the total Dirichlet Energy of learned node representations, which encapsulates the hypothesized GNN smoothness inductive bias. Finally, we introduce two training strategies to enhance GNN robustness: (1) by incorporating a novel inductive bias in the weight matrices through the removal of negative eigenvalues, connected to Dirichlet Energy minimization; (2) by extending to GNNs a loss penalty that promotes learned smoothness. Importantly, neither approach negatively impacts performance in noise-free settings, supporting our hypothesis that the source of GNNs robustness is their smoothness inductive bias.
Task Singular Vectors: Reducing Task Interference in Model Merging
Nov 26, 2024



Task Arithmetic has emerged as a simple yet effective method to merge models without additional training. However, by treating entire networks as flat parameter vectors, it overlooks key structural information and is susceptible to task interference. In this paper, we study task vectors at the layer level, focusing on task layer matrices and their singular value decomposition. In particular, we concentrate on the resulting singular vectors, which we refer to as Task Singular Vectors (TSV). Recognizing that layer task matrices are often low-rank, we propose TSV-Compress (TSV-C), a simple procedure that compresses them to 10% of their original size while retaining 99% of accuracy. We further leverage this low-rank space to define a new measure of task interference based on the interaction of singular vectors from different tasks. Building on these findings, we introduce TSV-Merge (TSV-M), a novel model merging approach that combines compression with interference reduction, significantly outperforming existing methods.
STLight: a Fully Convolutional Approach for Efficient Predictive Learning by Spatio-Temporal joint Processing
Nov 15, 2024



Spatio-Temporal predictive Learning is a self-supervised learning paradigm that enables models to identify spatial and temporal patterns by predicting future frames based on past frames. Traditional methods, which use recurrent neural networks to capture temporal patterns, have proven their effectiveness but come with high system complexity and computational demand. Convolutions could offer a more efficient alternative but are limited by their characteristic of treating all previous frames equally, resulting in poor temporal characterization, and by their local receptive field, limiting the capacity to capture distant correlations among frames. In this paper, we propose STLight, a novel method for spatio-temporal learning that relies solely on channel-wise and depth-wise convolutions as learnable layers. STLight overcomes the limitations of traditional convolutional approaches by rearranging spatial and temporal dimensions together, using a single convolution to mix both types of features into a comprehensive spatio-temporal patch representation. This representation is then processed in a purely convolutional framework, capable of focusing simultaneously on the interaction among near and distant patches, and subsequently allowing for efficient reconstruction of the predicted frames. Our architecture achieves state-of-the-art performance on STL benchmarks across different datasets and settings, while significantly improving computational efficiency in terms of parameters and computational FLOPs. The code is publicly available
A Theoretical Analysis of Recommendation Loss Functions under Negative Sampling
Nov 12, 2024



Recommender Systems (RSs) are pivotal in diverse domains such as e-commerce, music streaming, and social media. This paper conducts a comparative analysis of prevalent loss functions in RSs: Binary Cross-Entropy (BCE), Categorical Cross-Entropy (CCE), and Bayesian Personalized Ranking (BPR). Exploring the behaviour of these loss functions across varying negative sampling settings, we reveal that BPR and CCE are equivalent when one negative sample is used. Additionally, we demonstrate that all losses share a common global minimum. Evaluation of RSs mainly relies on ranking metrics known as Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR). We produce bounds of the different losses for negative sampling settings to establish a probabilistic lower bound for NDCG. We show that the BPR bound on NDCG is weaker than that of BCE, contradicting the common assumption that BPR is superior to BCE in RSs training. Experiments on five datasets and four models empirically support these theoretical findings. Our code is available at \url{https://anonymous.4open.science/r/recsys_losses} .
ATM: Improving Model Merging by Alternating Tuning and Merging
Nov 05, 2024



Model merging has recently emerged as a cost-efficient paradigm for multi-task learning. Among current approaches, task arithmetic stands out for its simplicity and effectiveness. In this paper, we motivate the effectiveness of task vectors by linking them to multi-task gradients. We show that in a single-epoch scenario, task vectors are mathematically equivalent to the gradients obtained via gradient descent in a multi-task setting, and still approximate these gradients in subsequent epochs. Furthermore, we show that task vectors perform optimally when equality is maintained, and their effectiveness is largely driven by the first epoch's gradient. Building on this insight, we propose viewing model merging as a single step in an iterative process that Alternates between Tuning and Merging (ATM). This method acts as a bridge between model merging and multi-task gradient descent, achieving state-of-the-art results with the same data and computational requirements. We extensively evaluate ATM across diverse settings, achieving up to 20% higher accuracy in computer vision and NLP tasks, compared to the best baselines.Finally, we provide both empirical and theoretical support for its effectiveness, demonstrating increased orthogonality between task vectors and proving that ATM minimizes an upper bound on the loss obtained by jointly finetuning all tasks.
Beyond position: how rotary embeddings shape representations and memory in autoregressive transfomers
Oct 23, 2024



Rotary Positional Embeddings (RoPE) enhance positional encoding in Transformer models, yet their full impact on model dynamics remains underexplored. This paper studies how RoPE introduces position-dependent rotations, causing phase shifts in token embeddings that influence higher-frequency components within the model's internal representations. Through spectral analysis, we demonstrate that RoPE's rotation matrices induce oscillatory behaviors in embeddings, affecting information retention across layers and shaping temporal modeling capabilities. We show that activation functions in feed-forward networks interact with RoPE-modulated embeddings to generate harmonics, leading to constructive or destructive interference based on phase alignment. Our findings reveal that phase alignment amplifies activations and sharpens attention, while misalignment weakens activations and disrupts focus on positional patterns. This study underscores the importance of frequency components as intrinsic elements of model behavior, offering new insights beyond traditional analyses.
Eco-Aware Graph Neural Networks for Sustainable Recommendations
Oct 12, 2024


Recommender systems play a crucial role in alleviating information overload by providing personalized recommendations tailored to users' preferences and interests. Recently, Graph Neural Networks (GNNs) have emerged as a promising approach for recommender systems, leveraging their ability to effectively capture complex relationships and dependencies between users and items by representing them as nodes in a graph structure. In this study, we investigate the environmental impact of GNN-based recommender systems, an aspect that has been largely overlooked in the literature. Specifically, we conduct a comprehensive analysis of the carbon emissions associated with training and deploying GNN models for recommendation tasks. We evaluate the energy consumption and carbon footprint of different GNN architectures and configurations, considering factors such as model complexity, training duration, hardware specifications and embedding size. By addressing the environmental impact of resource-intensive algorithms in recommender systems, this study contributes to the ongoing efforts towards sustainable and responsible artificial intelligence, promoting the development of eco-friendly recommendation technologies that balance performance and environmental considerations. Code is available at: https://github.com/antoniopurificato/gnn_recommendation_and_environment.
Natural Language Counterfactual Explanations for Graphs Using Large Language Models
Oct 11, 2024



Explainable Artificial Intelligence (XAI) has emerged as a critical area of research to unravel the opaque inner logic of (deep) machine learning models. Among the various XAI techniques proposed in the literature, counterfactual explanations stand out as one of the most promising approaches. However, these ``what-if'' explanations are frequently complex and technical, making them difficult for non-experts to understand and, more broadly, challenging for humans to interpret. To bridge this gap, in this work, we exploit the power of open-source Large Language Models to generate natural language explanations when prompted with valid counterfactual instances produced by state-of-the-art explainers for graph-based models. Experiments across several graph datasets and counterfactual explainers show that our approach effectively produces accurate natural language representations of counterfactual instances, as demonstrated by key performance metrics.
A Reproducible Analysis of Sequential Recommender Systems
Aug 07, 2024



Sequential Recommender Systems (SRSs) have emerged as a highly efficient approach to recommendation systems. By leveraging sequential data, SRSs can identify temporal patterns in user behaviour, significantly improving recommendation accuracy and relevance.Ensuring the reproducibility of these models is paramount for advancing research and facilitating comparisons between them. Existing works exhibit shortcomings in reproducibility and replicability of results, leading to inconsistent statements across papers. Our work fills these gaps by standardising data pre-processing and model implementations, providing a comprehensive code resource, including a framework for developing SRSs and establishing a foundation for consistent and reproducible experimentation. We conduct extensive experiments on several benchmark datasets, comparing various SRSs implemented in our resource. We challenge prevailing performance benchmarks, offering new insights into the SR domain. For instance, SASRec does not consistently outperform GRU4Rec. On the contrary, when the number of model parameters becomes substantial, SASRec starts to clearly dominate all the other SRSs. This discrepancy underscores the significant impact that experimental configuration has on the outcomes and the importance of setting it up to ensure precise and comprehensive results. Failure to do so can lead to significantly flawed conclusions, highlighting the need for rigorous experimental design and analysis in SRS research. Our code is available at https://github.com/antoniopurificato/recsys_repro_conf.
A Tale of Trust and Accuracy: Base vs. Instruct LLMs in RAG Systems
Jun 21, 2024
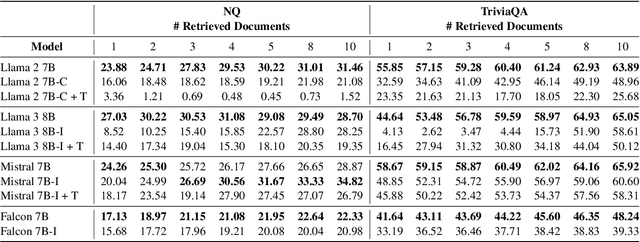
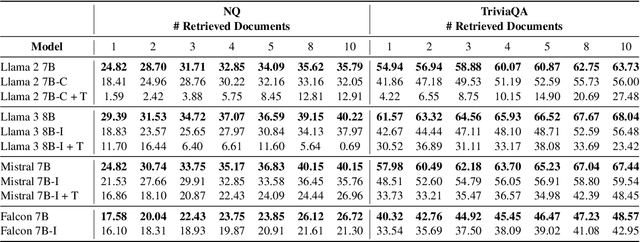
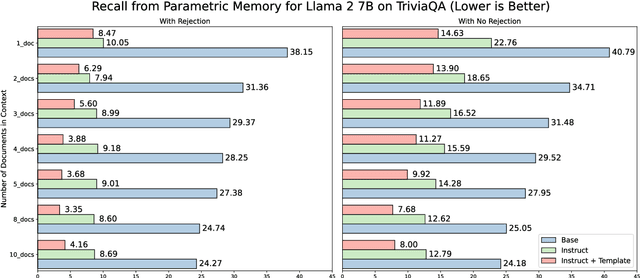
Retrieval Augmented Generation (RAG) represents a significant advancement in artificial intelligence combining a retrieval phase with a generative phase, with the latter typically being powered by large language models (LLMs). The current common practices in RAG involve using "instructed" LLMs, which are fine-tuned with supervised training to enhance their ability to follow instructions and are aligned with human preferences using state-of-the-art techniques. Contrary to popular belief, our study demonstrates that base models outperform their instructed counterparts in RAG tasks by 20% on average under our experimental settings. This finding challenges the prevailing assumptions about the superiority of instructed LLMs in RAG applications. Further investigations reveal a more nuanced situation, questioning fundamental aspects of RAG and suggesting the need for broader discussions on the topic; or, as Fromm would have it, "Seldom is a glance at the statistics enough to understand the meaning of the figures".