 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Response Interpretation for Automated Structured Interviews: A Case Study in Market Research
Apr 30, 2023


Structured interviews are used in many settings, importantly in market research on topics such as brand perception, customer habits, or preferences, which are critical to product development, marketing, and e-commerce at large. Such interviews generally consist of a series of questions that are asked to a participant. These interviews are typically conducted by skilled interviewers, who interpret the responses from the participants and can adapt the interview accordingly. Using automated conversational agents to conduct such interviews would enable reaching a much larger and potentially more diverse group of participants than currently possible. However, the technical challenges involved in building such a conversational system are relatively unexplored. To learn more about these challenges, we convert a market research multiple-choice questionnaire to a conversational format and conduct a user study. We address the key task of conducting structured interviews, namely interpreting the participant's response, for example, by matching it to one or more predefined options. Our findings can be applied to improve response interpretation for the information elicitation phase of conversational recommender systems.
Ericson: An Interactive Open-Domain Conversational Search Agent
Apr 05, 2023



Open-domain conversational search (ODCS) aims to provide valuable, up-to-date information, while maintaining natural conversations to help users refine and ultimately answer information needs. However, creating an effective and robust ODCS agent is challenging. In this paper, we present a fully functional ODCS system, Ericson, which includes state-of-the-art question answering and information retrieval components, as well as intent inference and dialogue management models for proactive question refinement and recommendations. Our system was stress-tested in the Amazon Alexa Prize, by engaging in live conversations with thousands of Alexa users, thus providing empirical basis for the analysis of the ODCS system in real settings. Our interaction data analysis revealed that accurate intent classification, encouraging user engagement, and careful proactive recommendations contribute most to the users satisfaction. Our study further identifies limitations of the existing search techniques, and can serve as a building block for the next generation of ODCS agents.
FCC: Fusing Conversation History and Candidate Provenance for Contextual Response Ranking in Dialogue Systems
Mar 31, 2023



Response ranking in dialogues plays a crucial role in retrieval-based conversational systems. In a multi-turn dialogue, to capture the gist of a conversation, contextual information serves as essential knowledge to achieve this goal. In this paper, we present a flexible neural framework that can integrate contextual information from multiple channels. Specifically for the current task, our approach is to provide two information channels in parallel, Fusing Conversation history and domain knowledge extracted from Candidate provenance (FCC), where candidate responses are curated, as contextual information to improve the performance of multi-turn dialogue response ranking. The proposed approach can be generalized as a module to incorporate miscellaneous contextual features for other context-oriented tasks. We evaluate our model on the MSDialog dataset widely used for evaluating conversational response ranking tasks. Our experimental results show that our framework significantly outperforms the previous state-of-the-art models, improving Recall@1 by 7% and MAP by 4%. Furthermore, we conduct ablation studies to evaluate the contributions of each information channel, and of the framework components, to the overall ranking performance, providing additional insights and directions for further improvements.
Detecting Elevated Air Pollution Levels by Monitoring Web Search Queries: Deep Learning-Based Time Series Forecasting
Nov 09, 2022



Real-time air pollution monitoring is a valuable tool for public health and environmental surveillance. In recent years, there has been a dramatic increase in air pollution forecasting and monitoring research using artificial neural networks (ANNs). Most of the prior work relied on modeling pollutant concentrations collected from ground-based monitors and meteorological data for long-term forecasting of outdoor ozone, oxides of nitrogen, and PM2.5. Given that traditional, highly sophisticated air quality monitors are expensive and are not universally available, these models cannot adequately serve those not living near pollutant monitoring sites. Furthermore, because prior models were built on physical measurement data collected from sensors, they may not be suitable for predicting public health effects experienced from pollution exposure. This study aims to develop and validate models to nowcast the observed pollution levels using Web search data, which is publicly available in near real-time from major search engines. We developed novel machine learning-based models using both traditional supervised classification methods and state-of-the-art deep learning methods to detect elevated air pollution levels at the US city level, by using generally available meteorological data and aggregate Web-based search volume data derived from Google Trends. We validated the performance of these methods by predicting three critical air pollutants (ozone (O3), nitrogen dioxide (NO2), and fine particulate matter (PM2.5)), across ten major U.S. metropolitan statistical areas (MSAs) in 2017 and 2018.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022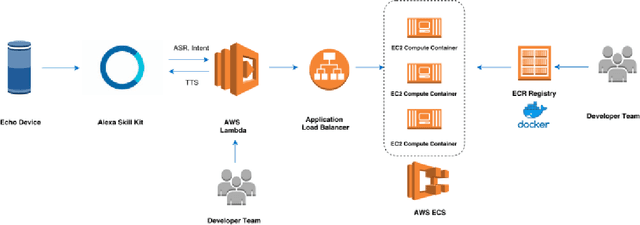
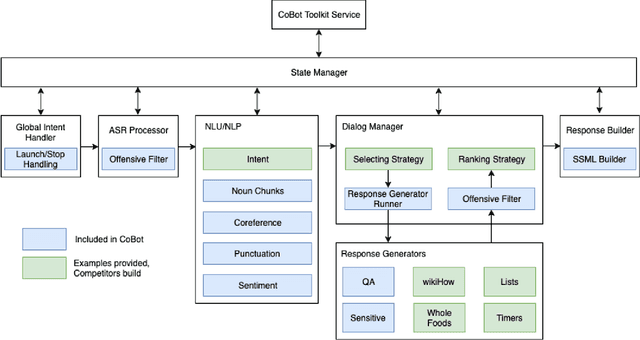

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.
Supporting Complex Information-Seeking Tasks with Implicit Constraints
May 02, 2022
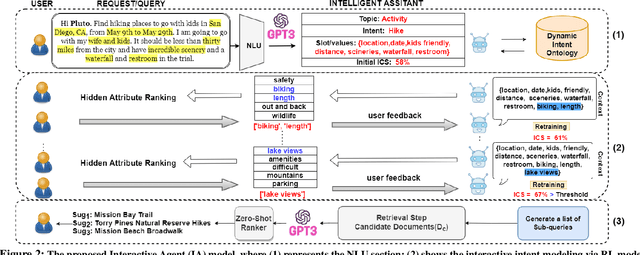
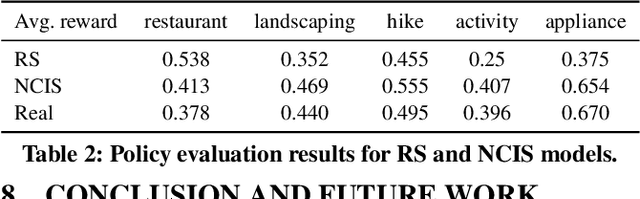
Current interactive systems with natural language interface lack an ability to understand a complex information-seeking request which expresses several implicit constraints at once, and there is no prior information about user preferences, e.g., "find hiking trails around San Francisco which are accessible with toddlers and have beautiful scenery in summer", where output is a list of possible suggestions for users to start their exploration. In such scenarios, the user requests can be issued at once in the form of a complex and long query, unlike conversational and exploratory search models that require short utterances or queries where they often require to be fed into the system step by step. This advancement provides the final user more flexibility and precision in expressing their intent through the search process. Such systems are inherently helpful for day-today user tasks requiring planning that are usually time-consuming, sometimes tricky, and cognitively taxing. We have designed and deployed a platform to collect the data from approaching such complex interactive systems. In this paper, we propose an Interactive Agent (IA) that allows intricately refined user requests by making it complete, which should lead to better retrieval. To demonstrate the performance of the proposed modeling paradigm, we have adopted various pre-retrieval metrics that capture the extent to which guided interactions with our system yield better retrieval results. Through extensive experimentation, we demonstrated that our method significantly outperforms several robust baselines
RLIRank: Learning to Rank with Reinforcement Learning for Dynamic Search
May 21, 2021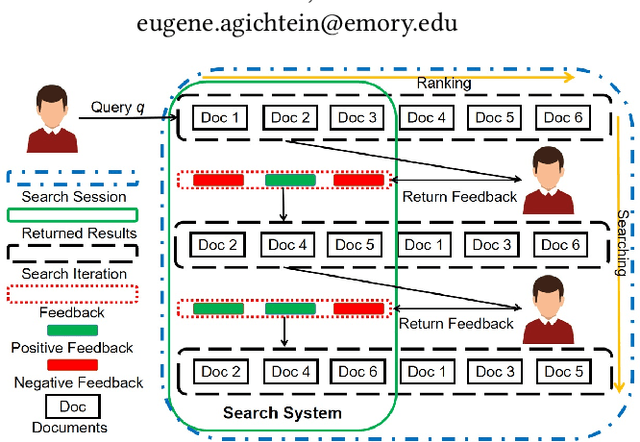
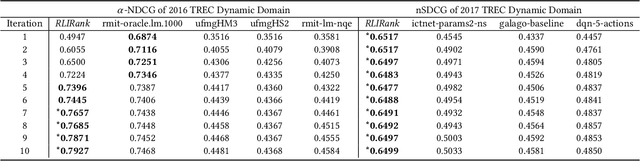
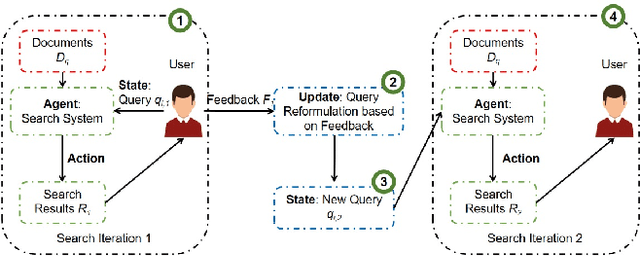

To support complex search tasks, where the initial information requirements are complex or may change during the search, a search engine must adapt the information delivery as the user's information requirements evolve. To support this dynamic ranking paradigm effectively, search result ranking must incorporate both the user feedback received, and the information displayed so far. To address this problem, we introduce a novel reinforcement learning-based approach, RLIrank. We first build an adapted reinforcement learning framework to integrate the key components of the dynamic search. Then, we implement a new Learning to Rank (LTR) model for each iteration of the dynamic search, using a recurrent Long Short Term Memory neural network (LSTM), which estimates the gain for each next result, learning from each previously ranked document. To incorporate the user's feedback, we develop a word-embedding variation of the classic Rocchio Algorithm, to help guide the ranking towards the high-value documents. Those innovations enable RLIrank to outperform the previously reported methods from the TREC Dynamic Domain Tracks 2017 and exceed all the methods in 2016 TREC Dynamic Domain after multiple search iterations, advancing the state of the art for dynamic search.
* Proceedings of The Web Conference 2020 (WWW '20), April 20--24, 2020, Taipei, Taiwan
Diversifying Multi-aspect Search Results Using Simpson's Diversity Index
May 21, 2021
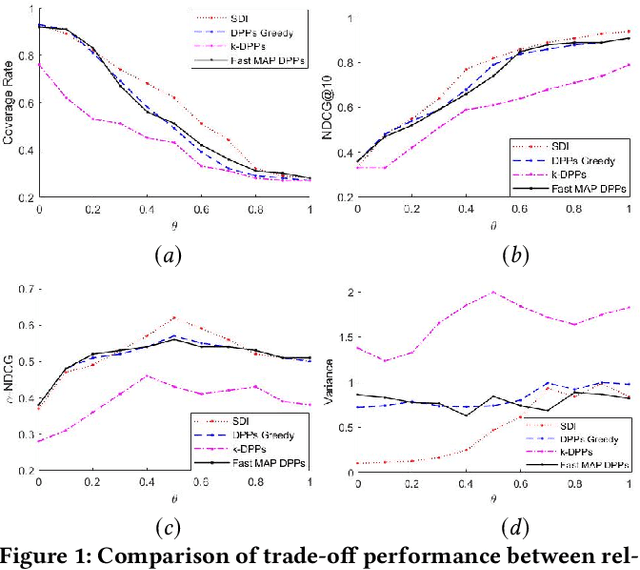
In search and recommendation, diversifying the multi-aspect search results could help with reducing redundancy, and promoting results that might not be shown otherwise. Many previous methods have been proposed for this task. However, previous methods do not explicitly consider the uniformity of the number of the items' classes, or evenness, which could degrade the search and recommendation quality. To address this problem, we introduce a novel method by adapting the Simpson's Diversity Index from biology, which enables a more effective and efficient quadratic search result diversification algorithm. We also extend the method to balance the diversity between multiple aspects through weighted factors and further improve computational complexity by developing a fast approximation algorithm. We demonstrate the feasibility of the proposed method using the openly available Kaggle shoes competition dataset. Our experimental results show that our approach outperforms previous state of the art diversification methods, while reducing computational complexity.
* Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM '20), October 19--23, 2020, Virtual Event, Ireland}
De-Biased Modelling of Search Click Behavior with Reinforcement Learning
May 21, 2021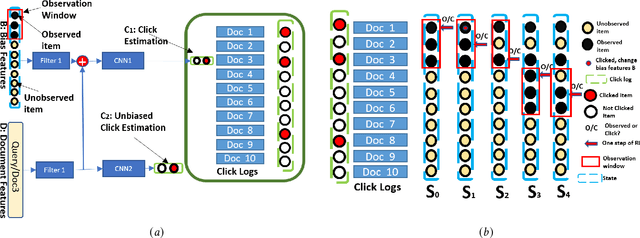

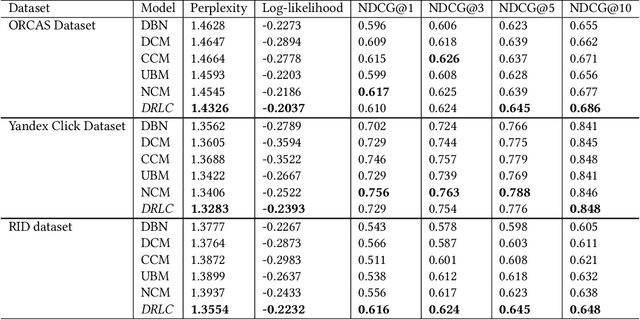
Users' clicks on Web search results are one of the key signals for evaluating and improving web search quality and have been widely used as part of current state-of-the-art Learning-To-Rank(LTR) models. With a large volume of search logs available for major search engines, effective models of searcher click behavior have emerged to evaluate and train LTR models. However, when modeling the users' click behavior, considering the bias of the behavior is imperative. In particular, when a search result is not clicked, it is not necessarily chosen as not relevant by the user, but instead could have been simply missed, especially for lower-ranked results. These kinds of biases in the click log data can be incorporated into the click models, propagating the errors to the resulting LTR ranking models or evaluation metrics. In this paper, we propose the De-biased Reinforcement Learning Click model (DRLC). The DRLC model relaxes previously made assumptions about the users' examination behavior and resulting latent states. To implement the DRLC model, convolutional neural networks are used as the value networks for reinforcement learning, trained to learn a policy to reduce bias in the click logs. To demonstrate the effectiveness of the DRLC model, we first compare performance with the previous state-of-art approaches using established click prediction metrics, including log-likelihood and perplexity. We further show that DRLC also leads to improvements in ranking performance. Our experiments demonstrate the effectiveness of the DRLC model in learning to reduce bias in click logs, leading to improved modeling performance and showing the potential for using DRLC for improving Web search quality.
APRF-Net: Attentive Pseudo-Relevance Feedback Network for Query Categorization
May 10, 2021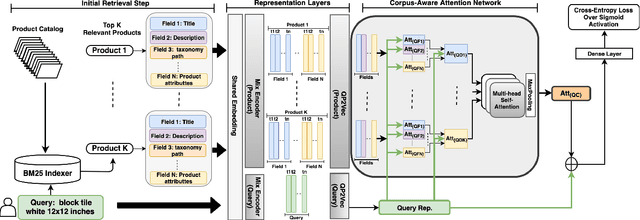
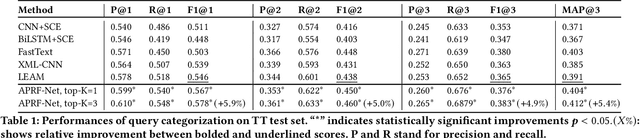
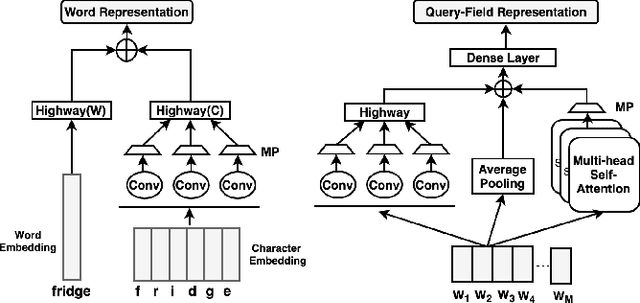
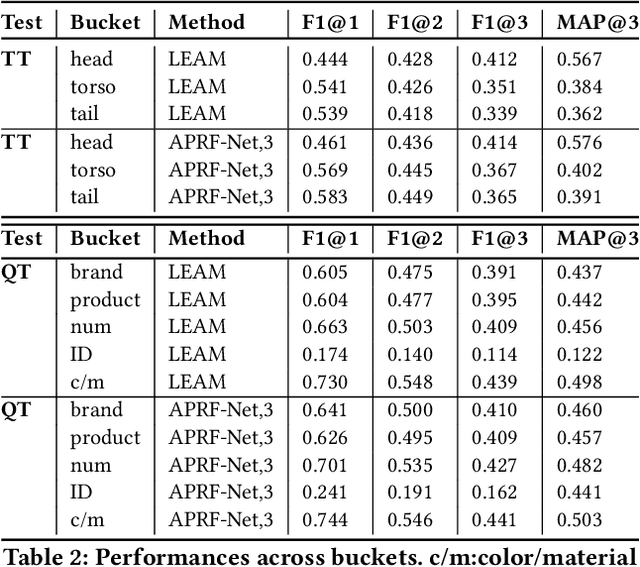
Query categorization is an essential part of query intent understanding in e-commerce search. A common query categorization task is to select the relevant fine-grained product categories in a product taxonomy. For frequent queries, rich customer behavior (e.g., click-through data) can be used to infer the relevant product categories. However, for more rare queries, which cover a large volume of search traffic, relying solely on customer behavior may not suffice due to the lack of this signal. To improve categorization of rare queries, we adapt the Pseudo-Relevance Feedback (PRF) approach to utilize the latent knowledge embedded in semantically or lexically similar product documents to enrich the representation of the more rare queries. To this end, we propose a novel deep neural model named Attentive Pseudo Relevance Feedback Network (APRF-Net) to enhance the representation of rare queries for query categorization. To demonstrate the effectiveness of our approach, we collect search queries from a large commercial search engine, and compare APRF-Net to state-of-the-art deep learning models for text classification. Our results show that the APRF-Net significantly improves query categorization by 5.9% on F1@1 score over the baselines, which increases to 8.2% improvement for the rare (tail) queries. The findings of this paper can be leveraged for further improvements in search query representation and understanding.