 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022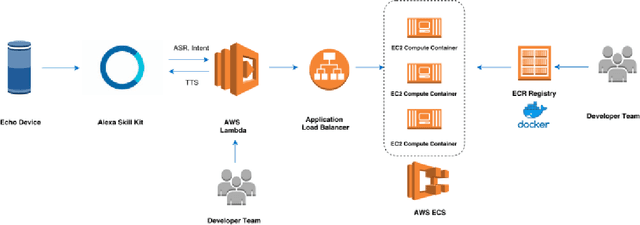
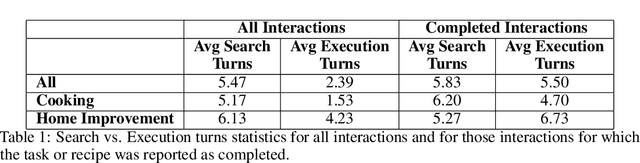
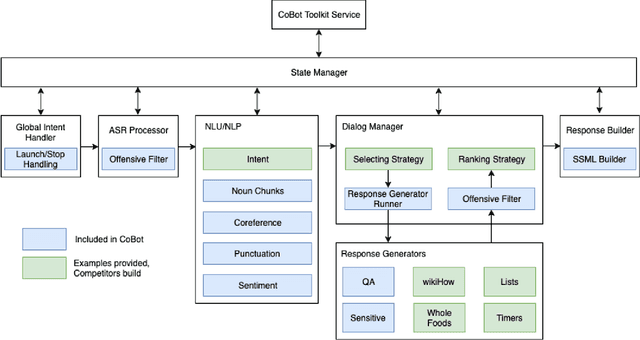

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.
On Reinforcement Learning for Turn-based Zero-sum Markov Games
Feb 25, 2020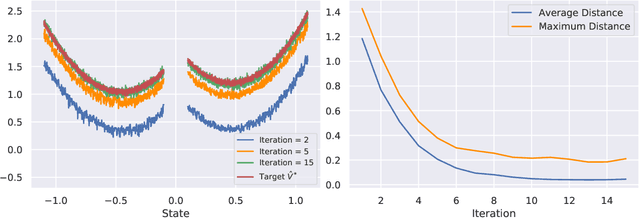
We consider the problem of finding Nash equilibrium for two-player turn-based zero-sum games. Inspired by the AlphaGo Zero (AGZ) algorithm, we develop a Reinforcement Learning based approach. Specifically, we propose Explore-Improve-Supervise (EIS) method that combines "exploration", "policy improvement"' and "supervised learning" to find the value function and policy associated with Nash equilibrium. We identify sufficient conditions for convergence and correctness for such an approach. For a concrete instance of EIS where random policy is used for "exploration", Monte-Carlo Tree Search is used for "policy improvement" and Nearest Neighbors is used for "supervised learning", we establish that this method finds an $\varepsilon$-approximate value function of Nash equilibrium in $\widetilde{O}(\varepsilon^{-(d+4)})$ steps when the underlying state-space of the game is continuous and $d$-dimensional. This is nearly optimal as we establish a lower bound of $\widetilde{\Omega}(\varepsilon^{-(d+2)})$ for any policy.