 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveRAG: A diverse Q&A dataset with varying difficulty level for RAG evaluation
Nov 18, 2025



With Retrieval Augmented Generation (RAG) becoming more and more prominent in generative AI solutions, there is an emerging need for systematically evaluating their effectiveness. We introduce the LiveRAG benchmark, a publicly available dataset of 895 synthetic questions and answers designed to support systematic evaluation of RAG-based Q&A systems. This synthetic benchmark is derived from the one used during the SIGIR'2025 LiveRAG Challenge, where competitors were evaluated under strict time constraints. It is augmented with information that was not made available to competitors during the Challenge, such as the ground-truth answers, together with their associated supporting claims which were used for evaluating competitors' answers. In addition, each question is associated with estimated difficulty and discriminability scores, derived from applying an Item Response Theory model to competitors' responses. Our analysis highlights the benchmark's questions diversity, the wide range of their difficulty levels, and their usefulness in differentiating between system capabilities. The LiveRAG benchmark will hopefully help the community advance RAG research, conduct systematic evaluation, and develop more robust Q&A systems.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022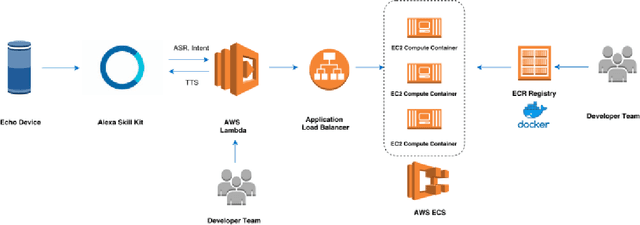
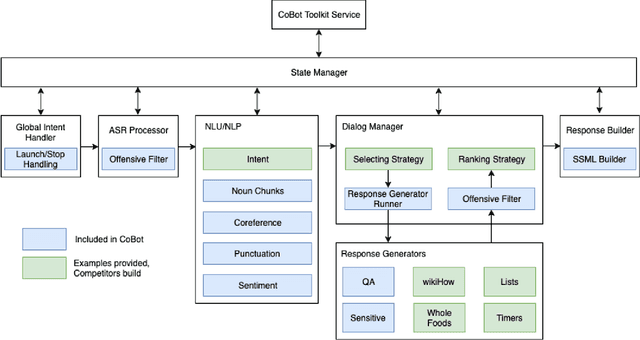

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.
Answering Product-Questions by Utilizing Questions from Other Contextually Similar Products
May 19, 2021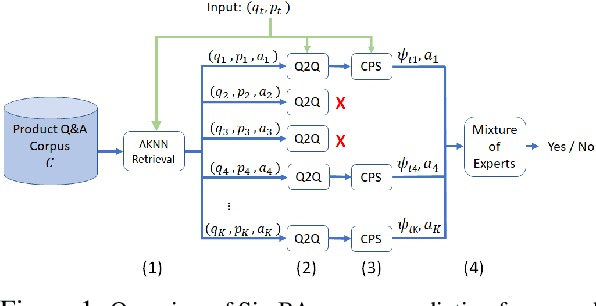
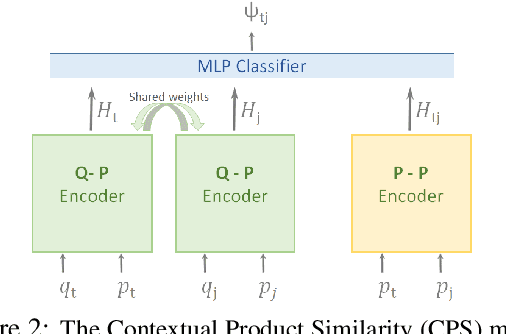


Predicting the answer to a product-related question is an emerging field of research that recently attracted a lot of attention. Answering subjective and opinion-based questions is most challenging due to the dependency on customer-generated content. Previous works mostly focused on review-aware answer prediction; however, these approaches fail for new or unpopular products, having no (or only a few) reviews at hand. In this work, we propose a novel and complementary approach for predicting the answer for such questions, based on the answers for similar questions asked on similar products. We measure the contextual similarity between products based on the answers they provide for the same question. A mixture-of-expert framework is used to predict the answer by aggregating the answers from contextually similar products. Empirical results demonstrate that our model outperforms strong baselines on some segments of questions, namely those that have roughly ten or more similar resolved questions in the corpus. We additionally publish two large-scale datasets used in this work, one is of similar product question pairs, and the second is of product question-answer pairs.