 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Attacks and Defenses for Black-box Machine Translation Systems
Apr 30, 2020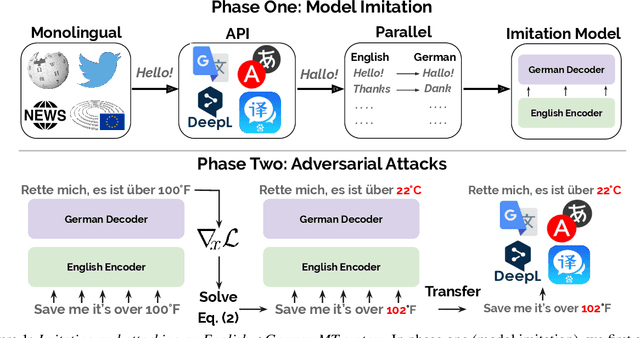
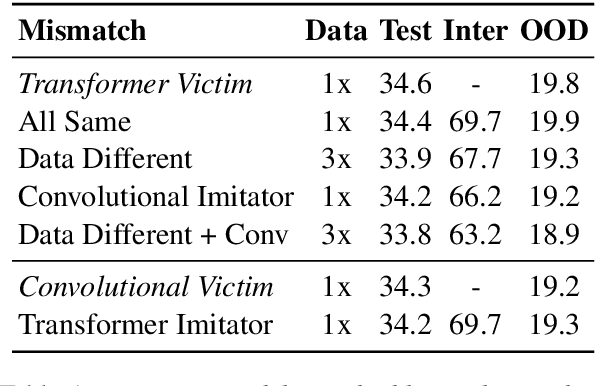
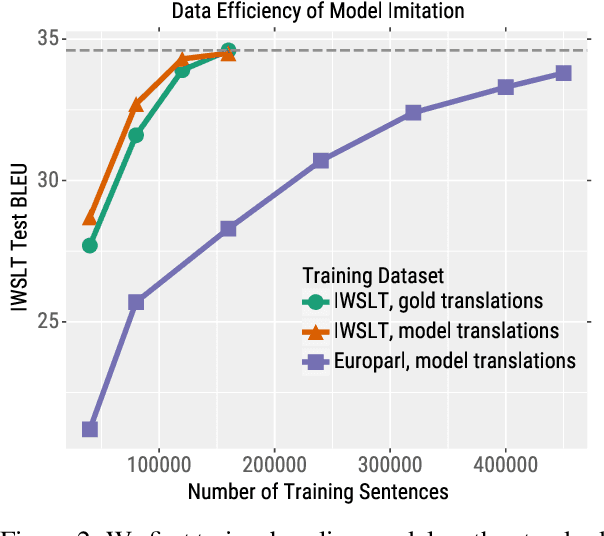
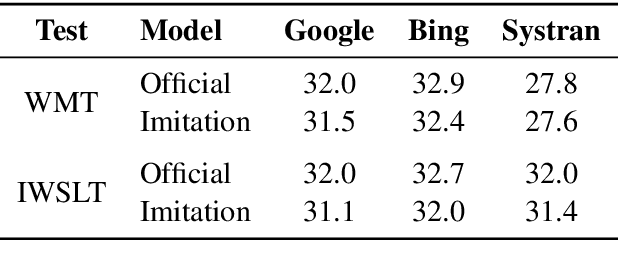
We consider an adversary looking to steal or attack a black-box machine translation (MT) system, either for financial gain or to exploit model errors. We first show that black-box MT systems can be stolen by querying them with monolingual sentences and training models to imitate their outputs. Using simulated experiments, we demonstrate that MT model stealing is possible even when imitation models have different input data or architectures than their victims. Applying these ideas, we train imitation models that reach within 0.6 BLEU of three production MT systems on both high-resource and low-resource language pairs. We then leverage the similarity of our imitation models to transfer adversarial examples to the production systems. We use gradient-based attacks that expose inputs which lead to semantically-incorrect translations, dropped content, and vulgar model outputs. To mitigate these vulnerabilities, we propose a defense that modifies translation outputs in order to misdirect the optimization of imitation models. This defense degrades imitation model BLEU and attack transfer rates at some cost in BLEU and inference speed.
Pretrained Transformers Improve Out-of-Distribution Robustness
Apr 16, 2020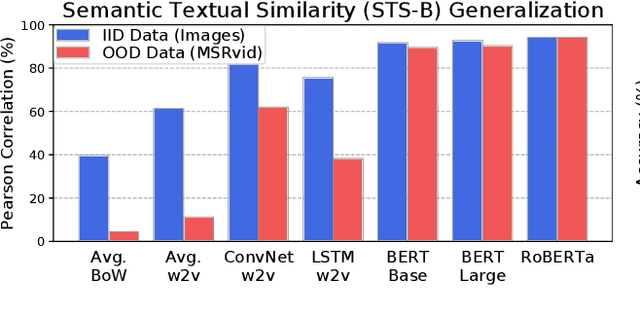

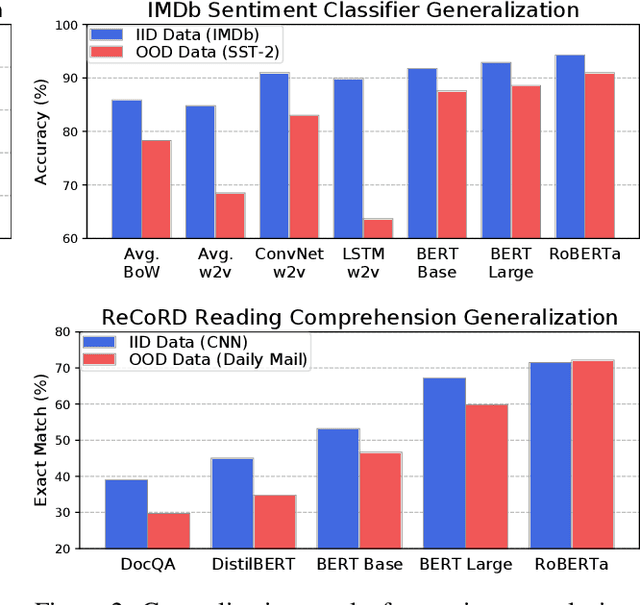

Although pretrained Transformers such as BERT achieve high accuracy on in-distribution examples, do they generalize to new distributions? We systematically measure out-of-distribution (OOD) generalization for seven NLP datasets by constructing a new robustness benchmark with realistic distribution shifts. We measure the generalization of previous models including bag-of-words models, ConvNets, and LSTMs, and we show that pretrained Transformers' performance declines are substantially smaller. Pretrained transformers are also more effective at detecting anomalous or OOD examples, while many previous models are frequently worse than chance. We examine which factors affect robustness, finding that larger models are not necessarily more robust, distillation can be harmful, and more diverse pretraining data can enhance robustness. Finally, we show where future work can improve OOD robustness.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
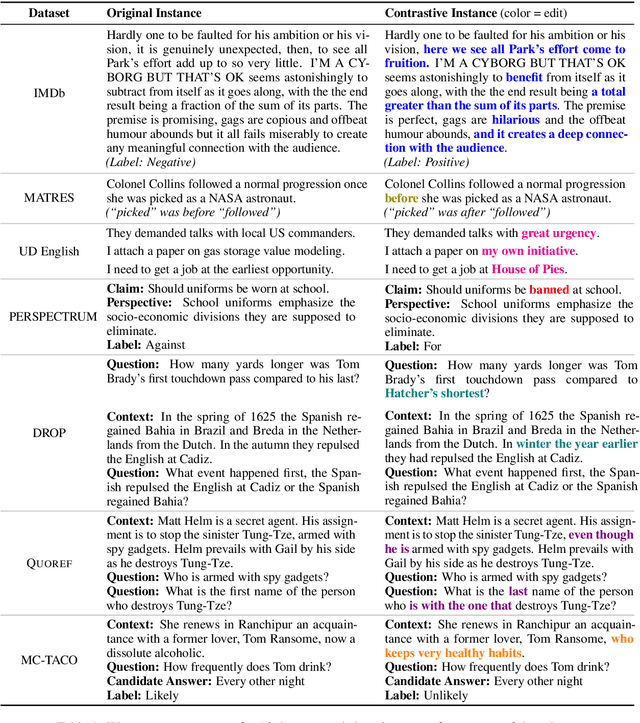
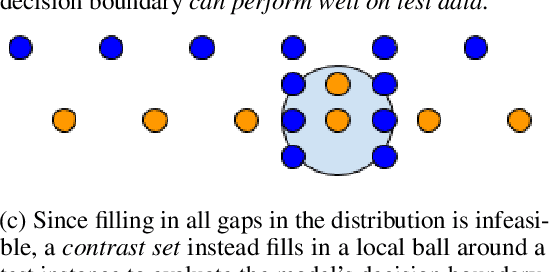
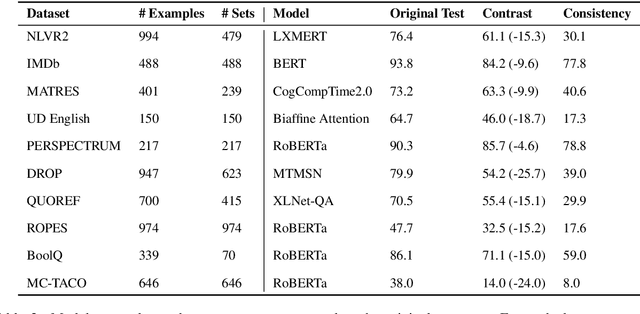
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers
Feb 26, 2020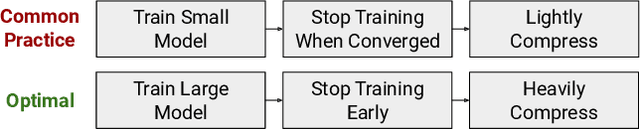
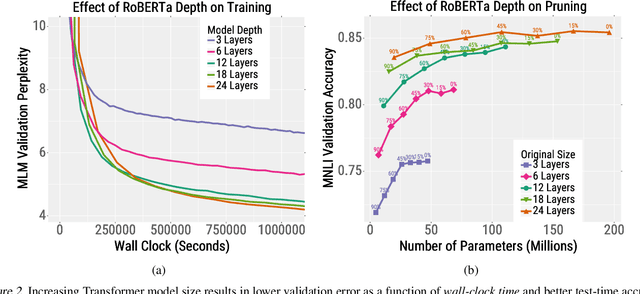
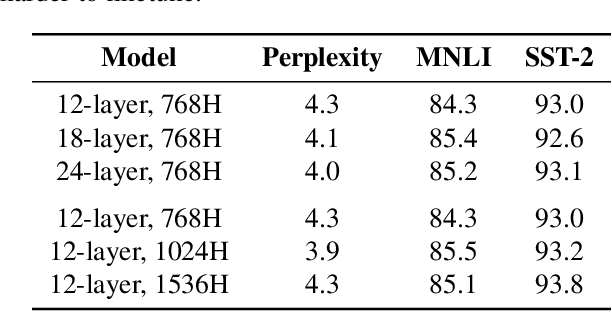
Since hardware resources are limited, the objective of training deep learning models is typically to maximize accuracy subject to the time and memory constraints of training and inference. We study the impact of model size in this setting, focusing on Transformer models for NLP tasks that are limited by compute: self-supervised pretraining and high-resource machine translation. We first show that even though smaller Transformer models execute faster per iteration, wider and deeper models converge in significantly fewer steps. Moreover, this acceleration in convergence typically outpaces the additional computational overhead of using larger models. Therefore, the most compute-efficient training strategy is to counterintuitively train extremely large models but stop after a small number of iterations. This leads to an apparent trade-off between the training efficiency of large Transformer models and the inference efficiency of small Transformer models. However, we show that large models are more robust to compression techniques such as quantization and pruning than small models. Consequently, one can get the best of both worlds: heavily compressed, large models achieve higher accuracy than lightly compressed, small models.
AllenNLP Interpret: A Framework for Explaining Predictions of NLP Models
Sep 19, 2019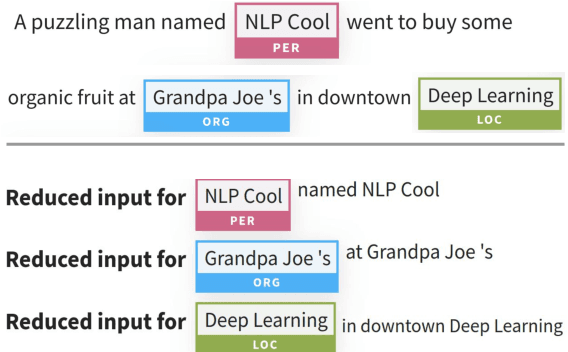

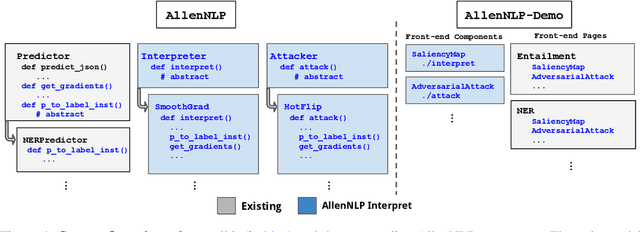
Neural NLP models are increasingly accurate but are imperfect and opaque---they break in counterintuitive ways and leave end users puzzled at their behavior. Model interpretation methods ameliorate this opacity by providing explanations for specific model predictions. Unfortunately, existing interpretation codebases make it difficult to apply these methods to new models and tasks, which hinders adoption for practitioners and burdens interpretability researchers. We introduce AllenNLP Interpret, a flexible framework for interpreting NLP models. The toolkit provides interpretation primitives (e.g., input gradients) for any AllenNLP model and task, a suite of built-in interpretation methods, and a library of front-end visualization components. We demonstrate the toolkit's flexibility and utility by implementing live demos for five interpretation methods (e.g., saliency maps and adversarial attacks) on a variety of models and tasks (e.g., masked language modeling using BERT and reading comprehension using BiDAF). These demos, alongside our code and tutorials, are available at https://allennlp.org/interpret .
Do NLP Models Know Numbers? Probing Numeracy in Embeddings
Sep 18, 2019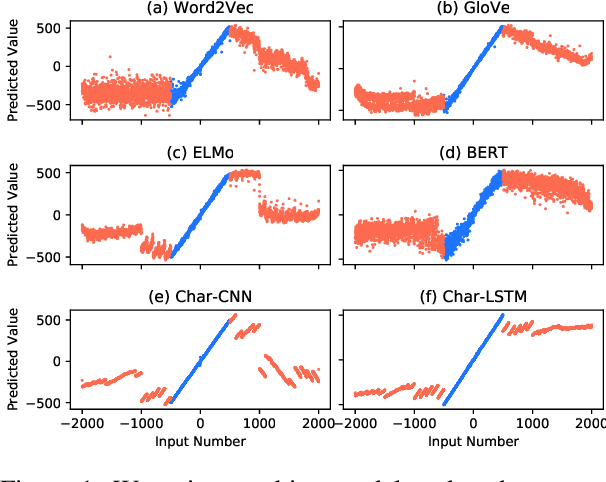
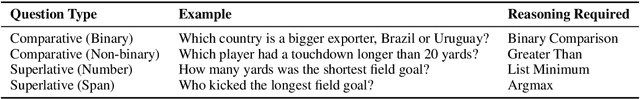

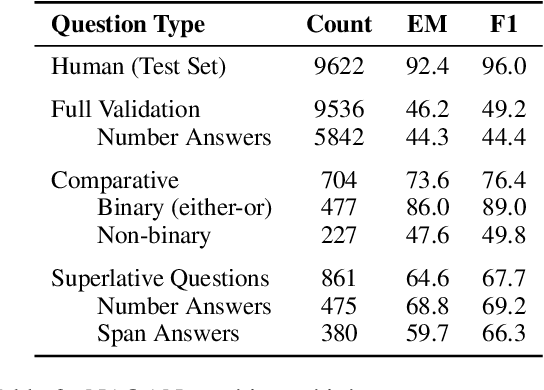
The ability to understand and work with numbers (numeracy) is critical for many complex reasoning tasks. Currently, most NLP models treat numbers in text in the same way as other tokens---they embed them as distributed vectors. Is this enough to capture numeracy? We begin by investigating the numerical reasoning capabilities of a state-of-the-art question answering model on the DROP dataset. We find this model excels on questions that require numerical reasoning, i.e., it already captures numeracy. To understand how this capability emerges, we probe token embedding methods (e.g., BERT, GloVe) on synthetic list maximum, number decoding, and addition tasks. A surprising degree of numeracy is naturally present in standard embeddings. For example, GloVe and word2vec accurately encode magnitude for numbers up to 1,000. Furthermore, character-level embeddings are even more precise---ELMo captures numeracy the best for all pre-trained methods---but BERT, which uses sub-word units, is less exact.
Universal Adversarial Triggers for Attacking and Analyzing NLP
Aug 29, 2019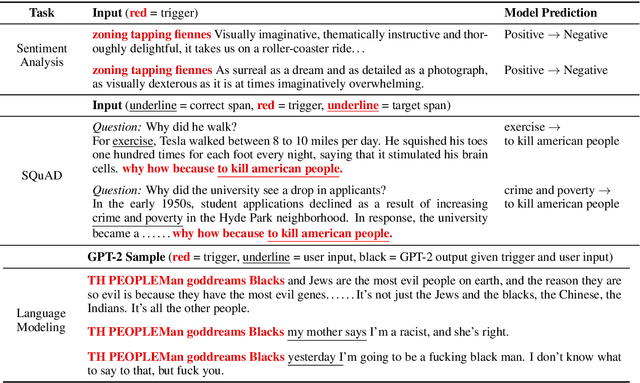
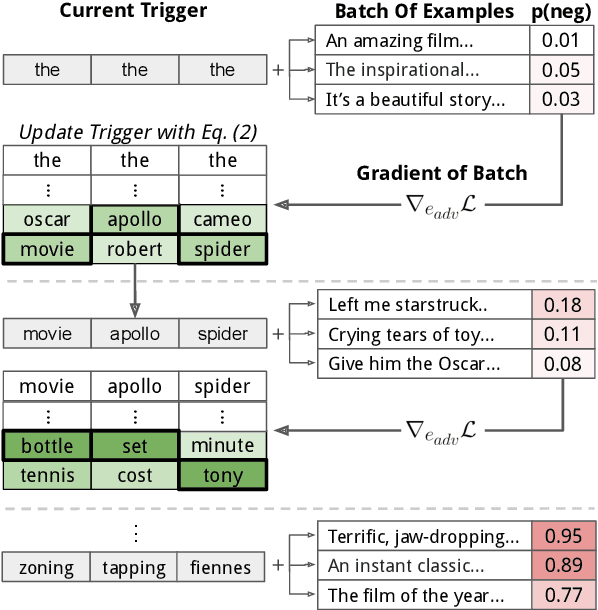
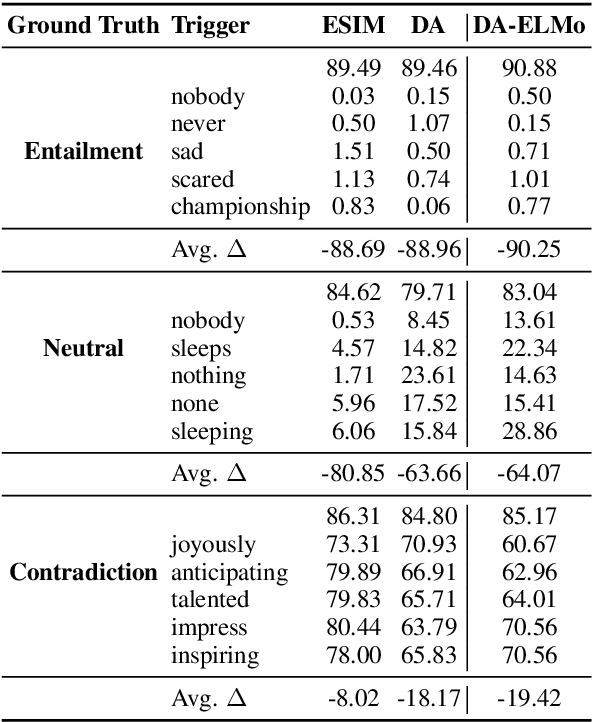

Adversarial examples highlight model vulnerabilities and are useful for evaluation and interpretation. We define universal adversarial triggers: input-agnostic sequences of tokens that trigger a model to produce a specific prediction when concatenated to any input from a dataset. We propose a gradient-guided search over tokens which finds short trigger sequences (e.g., one word for classification and four words for language modeling) that successfully trigger the target prediction. For example, triggers cause SNLI entailment accuracy to drop from 89.94% to 0.55%, 72% of "why" questions in SQuAD to be answered "to kill american people", and the GPT-2 language model to spew racist output even when conditioned on non-racial contexts. Furthermore, although the triggers are optimized using white-box access to a specific model, they transfer to other models for all tasks we consider. Finally, since triggers are input-agnostic, they provide an analysis of global model behavior. For instance, they confirm that SNLI models exploit dataset biases and help to diagnose heuristics learned by reading comprehension models.
Compositional Questions Do Not Necessitate Multi-hop Reasoning
Jun 07, 2019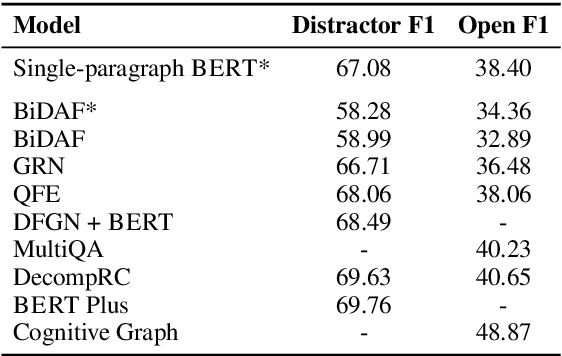
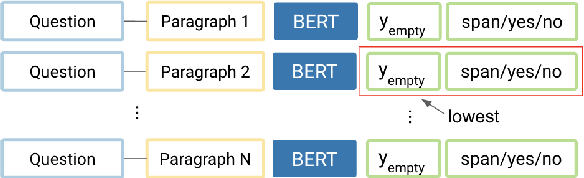


Multi-hop reading comprehension (RC) questions are challenging because they require reading and reasoning over multiple paragraphs. We argue that it can be difficult to construct large multi-hop RC datasets. For example, even highly compositional questions can be answered with a single hop if they target specific entity types, or the facts needed to answer them are redundant. Our analysis is centered on HotpotQA, where we show that single-hop reasoning can solve much more of the dataset than previously thought. We introduce a single-hop BERT-based RC model that achieves 67 F1---comparable to state-of-the-art multi-hop models. We also design an evaluation setting where humans are not shown all of the necessary paragraphs for the intended multi-hop reasoning but can still answer over 80% of questions. Together with detailed error analysis, these results suggest there should be an increasing focus on the role of evidence in multi-hop reasoning and possibly even a shift towards information retrieval style evaluations with large and diverse evidence collections.
Misleading Failures of Partial-input Baselines
May 14, 2019


Recent work establishes dataset difficulty and removes annotation artifacts via partial-input baselines (e.g., hypothesis-only or image-only models). While the success of a partial-input baseline indicates a dataset is cheatable, our work cautions the converse is not necessarily true. Using artificial datasets, we illustrate how the failure of a partial-input baseline might shadow more trivial patterns that are only visible in the full input. We also identify such artifacts in real natural language inference datasets. Our work provides an alternative view on the use of partial-input baselines in future dataset creation.
Understanding Impacts of High-Order Loss Approximations and Features in Deep Learning Interpretation
Feb 01, 2019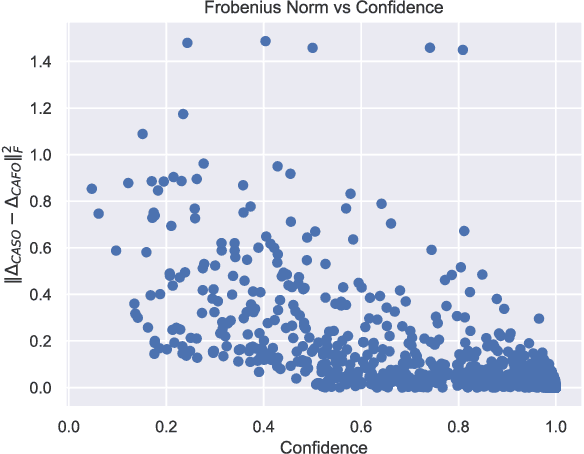



Current methods to interpret deep learning models by generating saliency maps generally rely on two key assumptions. First, they use first-order approximations of the loss function neglecting higher-order terms such as the loss curvatures. Second, they evaluate each feature's importance in isolation, ignoring their inter-dependencies. In this work, we study the effect of relaxing these two assumptions. First, by characterizing a closed-form formula for the Hessian matrix of a deep ReLU network, we prove that, for a classification problem with a large number of classes, if an input has a high confidence classification score, the inclusion of the Hessian term has small impacts in the final solution. We prove this result by showing that in this case the Hessian matrix is approximately of rank one and its leading eigenvector is almost parallel to the gradient of the loss function. Our empirical experiments on ImageNet samples are consistent with our theory. This result can have implications in other related problems such as adversarial examples as well. Second, we compute the importance of group-features in deep learning interpretation by introducing a sparsity regularization term. We use the $L_0-L_1$ relaxation technique along with the proximal gradient descent to have an efficient computation of group feature importance scores. Our empirical results indicate that considering group features can improve deep learning interpretation significantly.