 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Computational Anatomy of Humility: Modeling Intellectual Humility in Online Public Discourse
Oct 19, 2024



The ability for individuals to constructively engage with one another across lines of difference is a critical feature of a healthy pluralistic society. This is also true in online discussion spaces like social media platforms. To date, much social media research has focused on preventing ills -- like political polarization and the spread of misinformation. While this is important, enhancing the quality of online public discourse requires not just reducing ills but also promoting foundational human virtues. In this study, we focus on one particular virtue: ``intellectual humility'' (IH), or acknowledging the potential limitations in one's own beliefs. Specifically, we explore the development of computational methods for measuring IH at scale. We manually curate and validate an IH codebook on 350 posts about religion drawn from subreddits and use them to develop LLM-based models for automating this measurement. Our best model achieves a Macro-F1 score of 0.64 across labels (and 0.70 when predicting IH/IA/Neutral at the coarse level), higher than an expected naive baseline of 0.51 (0.32 for IH/IA/Neutral) but lower than a human annotator-informed upper bound of 0.85 (0.83 for IH/IA/Neutral). Our results both highlight the challenging nature of detecting IH online -- opening the door to new directions in NLP research -- and also lay a foundation for computational social science researchers interested in analyzing and fostering more IH in online public discourse.
FeedbackMap: a tool for making sense of open-ended survey responses
Jun 26, 2023

Analyzing open-ended survey responses is a crucial yet challenging task for social scientists, non-profit organizations, and educational institutions, as they often face the trade-off between obtaining rich data and the burden of reading and coding textual responses. This demo introduces FeedbackMap, a web-based tool that uses natural language processing techniques to facilitate the analysis of open-ended survey responses. FeedbackMap lets researchers generate summaries at multiple levels, identify interesting response examples, and visualize the response space through embeddings. We discuss the importance of examining survey results from multiple perspectives and the potential biases introduced by summarization methods, emphasizing the need for critical evaluation of the representation and omission of respondent voices.
Redrawing attendance boundaries to promote racial and ethnic diversity in elementary schools
Mar 14, 2023



Most US school districts draw "attendance boundaries" to define catchment areas that assign students to schools near their homes, often recapitulating neighborhood demographic segregation in schools. Focusing on elementary schools, we ask: how much might we reduce school segregation by redrawing attendance boundaries? Combining parent preference data with methods from combinatorial optimization, we simulate alternative boundaries for 98 US school districts serving over 3 million elementary-aged students, minimizing White/non-White segregation while mitigating changes to travel times and school sizes. Across districts, we observe a median 14% relative decrease in segregation, which we estimate would require approximately 20\% of students to switch schools and, surprisingly, a slight reduction in travel times. We release a public dashboard depicting these alternative boundaries (https://www.schooldiversity.org/) and invite both school boards and their constituents to evaluate their viability. Our results show the possibility of greater integration without significant disruptions for families.
Unpacking the "Black Box" of AI in Education
Dec 31, 2022Recent advances in Artificial Intelligence (AI) have sparked renewed interest in its potential to improve education. However, AI is a loose umbrella term that refers to a collection of methods, capabilities, and limitations-many of which are often not explicitly articulated by researchers, education technology companies, or other AI developers. In this paper, we seek to clarify what "AI" is and the potential it holds to both advance and hamper educational opportunities that may improve the human condition. We offer a basic introduction to different methods and philosophies underpinning AI, discuss recent advances, explore applications to education, and highlight key limitations and risks. We conclude with a set of questions that educationalists may ask as they encounter AI in their research and practice. Our hope is to make often jargon-laden terms and concepts accessible, so that all are equipped to understand, interrogate, and ultimately shape the development of human centered AI in education.
Games for Fairness and Interpretability
Apr 20, 2020
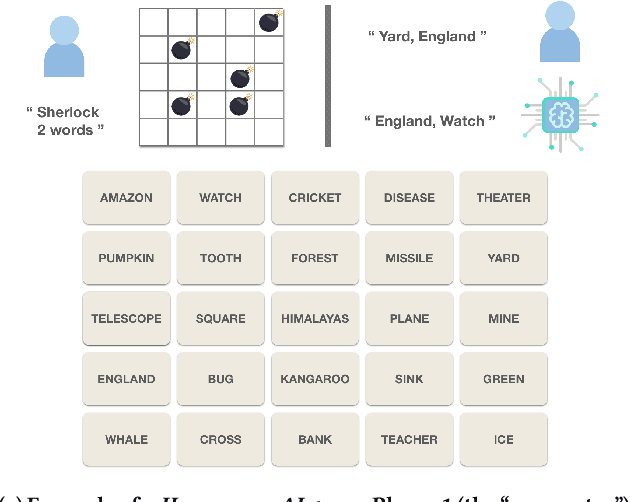
As Machine Learning (ML) systems becomes more ubiquitous, ensuring the fair and equitable application of their underlying algorithms is of paramount importance. We argue that one way to achieve this is to proactively cultivate public pressure for ML developers to design and develop fairer algorithms -- and that one way to cultivate public pressure while simultaneously serving the interests and objectives of algorithm developers is through gameplay. We propose a new class of games -- ``games for fairness and interpretability'' -- as one example of an incentive-aligned approach for producing fairer and more equitable algorithms. Games for fairness and interpretability are carefully-designed games with mass appeal. They are inherently engaging, provide insights into how machine learning models work, and ultimately produce data that helps researchers and developers improve their algorithms. We highlight several possible examples of games, their implications for fairness and interpretability, how their proliferation could creative positive public pressure by narrowing the gap between algorithm developers and the general public, and why the machine learning community could benefit from them.
Communication Communities in MOOCs
Apr 16, 2014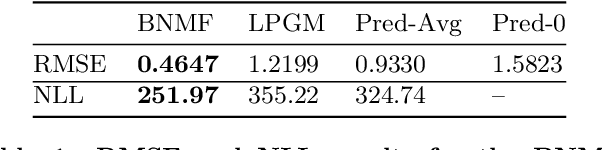
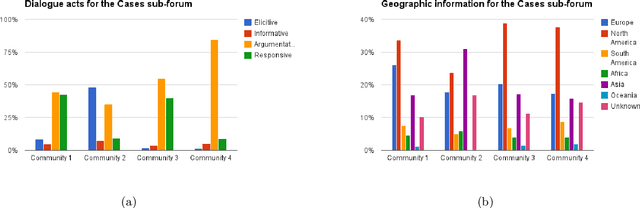
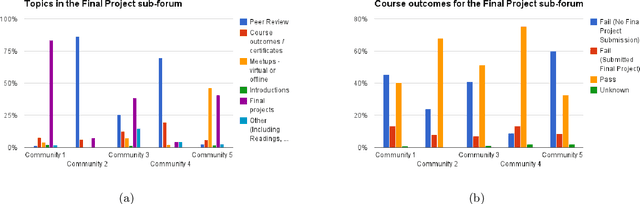
Massive Open Online Courses (MOOCs) bring together thousands of people from different geographies and demographic backgrounds -- but to date, little is known about how they learn or communicate. We introduce a new content-analysed MOOC dataset and use Bayesian Non-negative Matrix Factorization (BNMF) to extract communities of learners based on the nature of their online forum posts. We see that BNMF yields a superior probabilistic generative model for online discussions when compared to other models, and that the communities it learns are differentiated by their composite students' demographic and course performance indicators. These findings suggest that computationally efficient probabilistic generative modelling of MOOCs can reveal important insights for educational researchers and practitioners and help to develop more intelligent and responsive online learning environments.