 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Navigation for Robot-assisted Intraluminal and Endovascular Procedures: A Systematic Review
May 06, 2023



Increased demand for less invasive procedures has accelerated the adoption of Intraluminal Procedures (IP) and Endovascular Interventions (EI) performed through body lumens and vessels. As navigation through lumens and vessels is quite complex, interest grows to establish autonomous navigation techniques for IP and EI for reaching the target area. Current research efforts are directed toward increasing the Level of Autonomy (LoA) during the navigation phase. One key ingredient for autonomous navigation is Motion Planning (MP) techniques. This paper provides an overview of MP techniques categorizing them based on LoA. Our analysis investigates advances for the different clinical scenarios. Through a systematic literature analysis using the PRISMA method, the study summarizes relevant works and investigates the clinical aim, LoA, adopted MP techniques, and validation types. We identify the limitations of the corresponding MP methods and provide directions to improve the robustness of the algorithms in dynamic intraluminal environments. MP for IP and EI can be classified into four subgroups: node, sampling, optimization, and learning-based techniques, with a notable rise in learning-based approaches in recent years. One of the review's contributions is the identification of the limiting factors in IP and EI robotic systems hindering higher levels of autonomous navigation. In the future, navigation is bound to become more autonomous, placing the clinician in a supervisory position to improve control precision and reduce workload.
Uncertainty-aware Self-supervised Learning for Cross-domain Technical Skill Assessment in Robot-assisted Surgery
Apr 28, 2023



Objective technical skill assessment is crucial for effective training of new surgeons in robot-assisted surgery. With advancements in surgical training programs in both physical and virtual environments, it is imperative to develop generalizable methods for automatically assessing skills. In this paper, we propose a novel approach for skill assessment by transferring domain knowledge from labeled kinematic data to unlabeled data. Our approach leverages labeled data from common surgical training tasks such as Suturing, Needle Passing, and Knot Tying to jointly train a model with both labeled and unlabeled data. Pseudo labels are generated for the unlabeled data through an iterative manner that incorporates uncertainty estimation to ensure accurate labeling. We evaluate our method on a virtual reality simulated training task (Ring Transfer) using data from the da Vinci Research Kit (dVRK). The results show that trainees with robotic assistance have significantly higher expert probability compared to these without any assistance, p < 0.05, which aligns with previous studies showing the benefits of robotic assistance in improving training proficiency. Our method offers a significant advantage over other existing works as it does not require manual labeling or prior knowledge of the surgical training task for robot-assisted surgery.
A Comprehensive Architecture for Dynamic Role Allocation and Collaborative Task Planning in Mixed Human-Robot Teams
Jan 19, 2023The growing deployment of human-robot collaborative processes in several industrial applications, such as handling, welding, and assembly, unfolds the pursuit of systems which are able to manage large heterogeneous teams and, at the same time, monitor the execution of complex tasks. In this paper, we present a novel architecture for dynamic role allocation and collaborative task planning in a mixed human-robot team of arbitrary size. The architecture capitalizes on a centralized reactive and modular task-agnostic planning method based on Behavior Trees (BTs), in charge of actions scheduling, while the allocation problem is formulated through a Mixed-Integer Linear Program (MILP), that assigns dynamically individual roles or collaborations to the agents of the team. Different metrics used as MILP cost allow the architecture to favor various aspects of the collaboration (e.g. makespan, ergonomics, human preferences). Human preference are identified through a negotiation phase, in which, an human agent can accept/refuse to execute the assigned task.In addition, bilateral communication between humans and the system is achieved through an Augmented Reality (AR) custom user interface that provides intuitive functionalities to assist and coordinate workers in different action phases. The computational complexity of the proposed methodology outperforms literature approaches in industrial sized jobs and teams (problems up to 50 actions and 20 agents in the team with collaborations are solved within 1\;s). The different allocated roles, as the cost functions change, highlights the flexibility of the architecture to several production requirements. Finally, the subjective evaluation demonstrating the high usability level and the suitability for the targeted scenario.
Semi-supervised GAN for Bladder Tissue Classification in Multi-Domain Endoscopic Images
Dec 21, 2022



Objective: Accurate visual classification of bladder tissue during Trans-Urethral Resection of Bladder Tumor (TURBT) procedures is essential to improve early cancer diagnosis and treatment. During TURBT interventions, White Light Imaging (WLI) and Narrow Band Imaging (NBI) techniques are used for lesion detection. Each imaging technique provides diverse visual information that allows clinicians to identify and classify cancerous lesions. Computer vision methods that use both imaging techniques could improve endoscopic diagnosis. We address the challenge of tissue classification when annotations are available only in one domain, in our case WLI, and the endoscopic images correspond to an unpaired dataset, i.e. there is no exact equivalent for every image in both NBI and WLI domains. Method: We propose a semi-surprised Generative Adversarial Network (GAN)-based method composed of three main components: a teacher network trained on the labeled WLI data; a cycle-consistency GAN to perform unpaired image-to-image translation, and a multi-input student network. To ensure the quality of the synthetic images generated by the proposed GAN we perform a detailed quantitative, and qualitative analysis with the help of specialists. Conclusion: The overall average classification accuracy, precision, and recall obtained with the proposed method for tissue classification are 0.90, 0.88, and 0.89 respectively, while the same metrics obtained in the unlabeled domain (NBI) are 0.92, 0.64, and 0.94 respectively. The quality of the generated images is reliable enough to deceive specialists. Significance: This study shows the potential of using semi-supervised GAN-based classification to improve bladder tissue classification when annotations are limited in multi-domain data.
Impact-Friendly Object Catching at Non-Zero Velocity based on Hybrid Optimization and Learning
Sep 26, 2022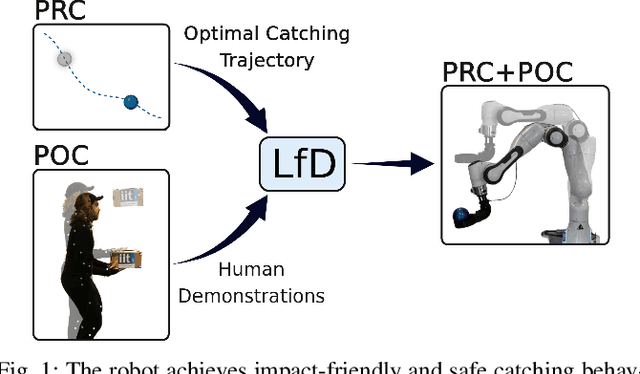
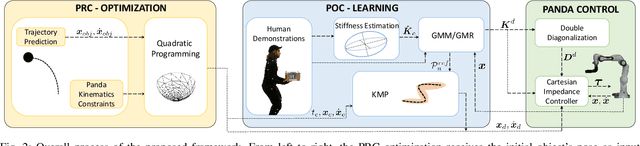
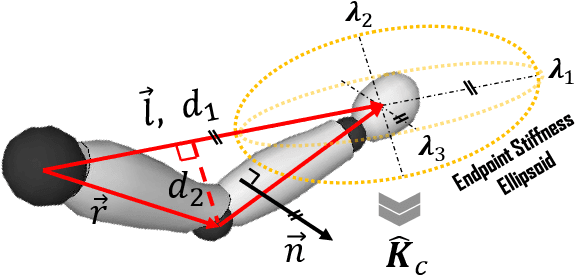

This paper proposes a hybrid optimization and learning method for impact-friendly catching objects at non-zero velocity. Through a constrained Quadratic Programming problem, the method generates optimal trajectories up to the contact point between the robot and the object to minimize their relative velocity and reduce the initial impact forces. Next, the generated trajectories are updated by Kernelized Movement Primitives which are based on human catching demonstrations to ensure a smooth transition around the catching point. In addition, the learned human variable stiffness (HVS) is sent to the robot's Cartesian impedance controller to absorb the post-impact forces and stabilize the catching position. Three experiments are conducted to compare our method with and without HVS against a fixed-position impedance controller (FP-IC). The results showed that the proposed methods outperform the FP-IC, while adding HVS yields better results for absorbing the post-impact forces.
Learning-Based Keypoint Registration for Fetoscopic Mosaicking
Jul 26, 2022
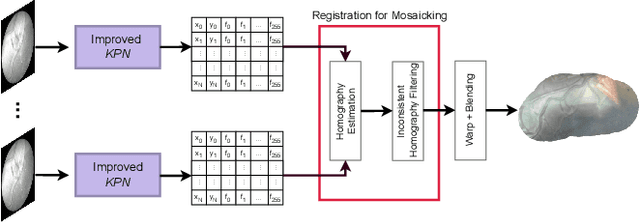

In Twin-to-Twin Transfusion Syndrome (TTTS), abnormal vascular anastomoses in the monochorionic placenta can produce uneven blood flow between the two fetuses. In the current practice, TTTS is treated surgically by closing abnormal anastomoses using laser ablation. This surgery is minimally invasive and relies on fetoscopy. Limited field of view makes anastomosis identification a challenging task for the surgeon. To tackle this challenge, we propose a learning-based framework for in-vivo fetoscopy frame registration for field-of-view expansion. The novelties of this framework relies on a learning-based keypoint proposal network and an encoding strategy to filter (i) irrelevant keypoints based on fetoscopic image segmentation and (ii) inconsistent homographies. We validate of our framework on a dataset of 6 intraoperative sequences from 6 TTTS surgeries from 6 different women against the most recent state of the art algorithm, which relies on the segmentation of placenta vessels. The proposed framework achieves higher performance compared to the state of the art, paving the way for robust mosaicking to provide surgeons with context awareness during TTTS surgery.
Pick the Right Co-Worker: Online Assessment of Cognitive Ergonomics in Human-Robot Collaborative Assembly
Jul 08, 2022
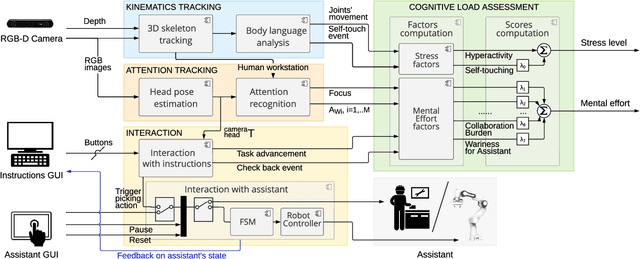
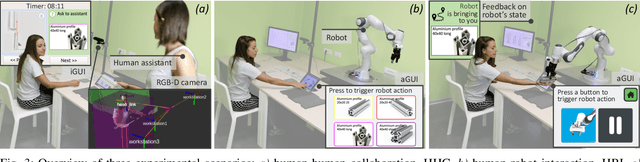
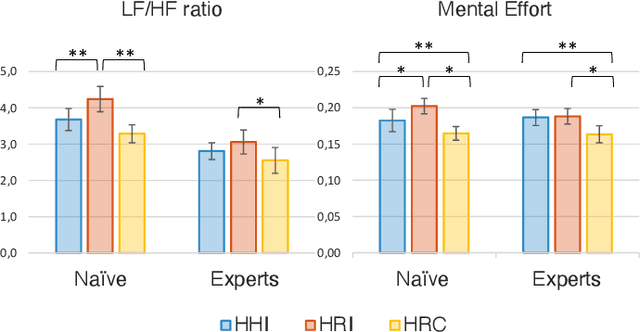
Human-robot collaborative assembly systems enhance the efficiency and productivity of the workplace but may increase the workers' cognitive demand. This paper proposes an online and quantitative framework to assess the cognitive workload induced by the interaction with a co-worker, either a human operator or an industrial collaborative robot with different control strategies. The approach monitors the operator's attention distribution and upper-body kinematics benefiting from the input images of a low-cost stereo camera and cutting-edge artificial intelligence algorithms (i.e. head pose estimation and skeleton tracking). Three experimental scenarios with variations in workstation features and interaction modalities were designed to test the performance of our online method against state-of-the-art offline measurements. Results proved that our vision-based cognitive load assessment has the potential to be integrated into the new generation of collaborative robotic technologies. The latter would enable human cognitive state monitoring and robot control strategy adaptation for improving human comfort, ergonomics, and trust in automation.
Robot Trajectory Adaptation to Optimise the Trade-off between Human Cognitive Ergonomics and Workplace Productivity in Collaborative Tasks
Jul 08, 2022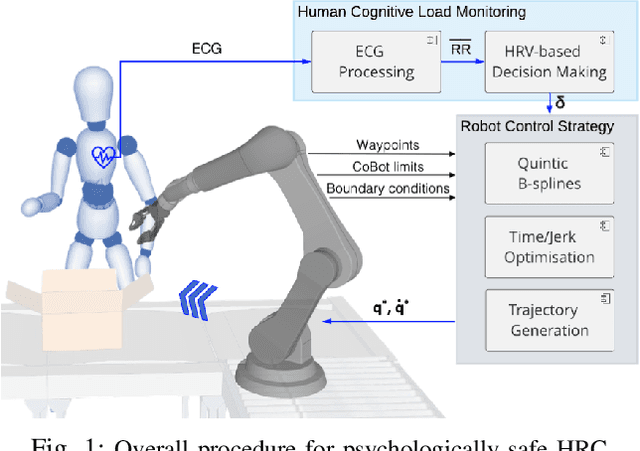
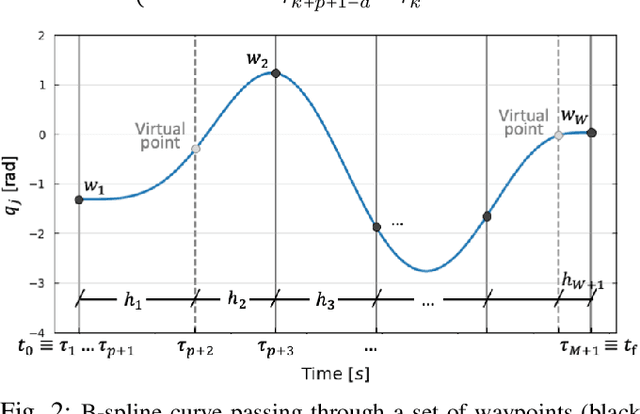
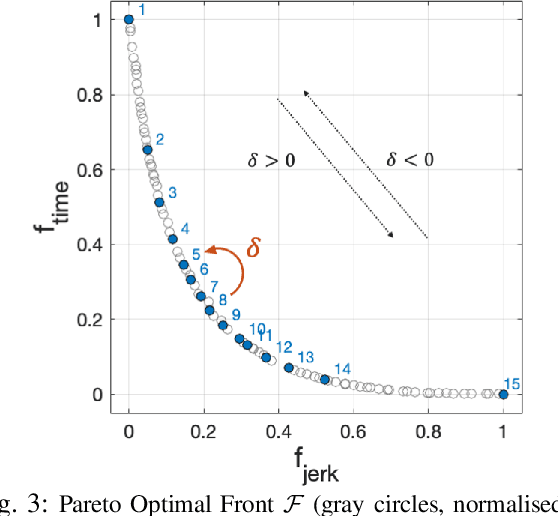

In hybrid industrial environments, workers' comfort and positive perception of safety are essential requirements for successful acceptance and usage of collaborative robots. This paper proposes a novel human-robot interaction framework in which the robot behaviour is adapted online according to the operator's cognitive workload and stress. The method exploits the generation of B-spline trajectories in the joint space and formulation of a multi-objective optimisation problem to online adjust the total execution time and smoothness of the robot trajectories. The former ensures human efficiency and productivity of the workplace, while the latter contributes to safeguarding the user's comfort and cognitive ergonomics. The performance of the proposed framework was evaluated in a typical industrial task. Results demonstrated its capability to enhance the productivity of the human-robot dyad while mitigating the cognitive workload induced in the worker.
Sociable and Ergonomic Human-Robot Collaboration through Action Recognition and Augmented Hierarchical Quadratic Programming
Jul 07, 2022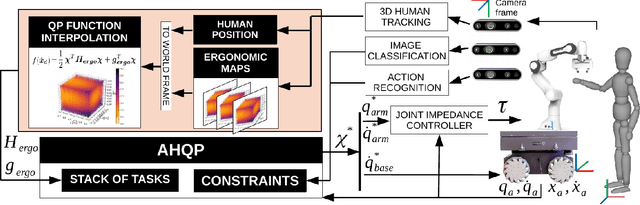
The recognition of actions performed by humans and the anticipation of their intentions are important enablers to yield sociable and successful collaboration in human-robot teams. Meanwhile, robots should have the capacity to deal with multiple objectives and constraints, arising from the collaborative task or the human. In this regard, we propose vision techniques to perform human action recognition and image classification, which are integrated into an Augmented Hierarchical Quadratic Programming (AHQP) scheme to hierarchically optimize the robot's reactive behavior and human ergonomics. The proposed framework allows one to intuitively command the robot in space while a task is being executed. The experiments confirm increased human ergonomics and usability, which are fundamental parameters for reducing musculoskeletal diseases and increasing trust in automation.
Autonomous Intraluminal Navigation of a Soft Robot using Deep-Learning-based Visual Servoing
Jul 01, 2022

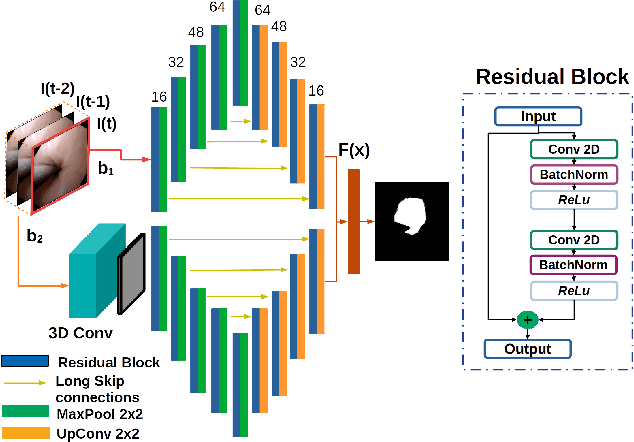
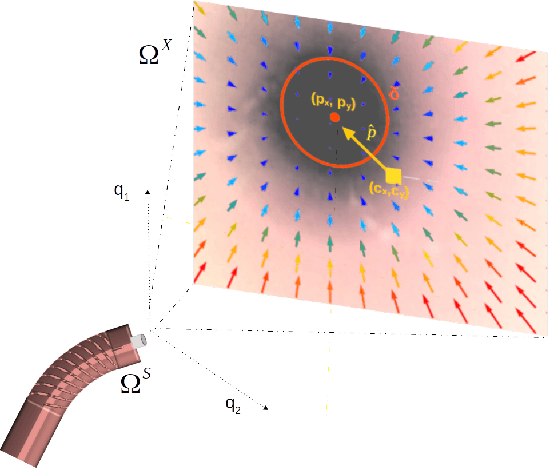
Navigation inside luminal organs is an arduous task that requires non-intuitive coordination between the movement of the operator's hand and the information obtained from the endoscopic video. The development of tools to automate certain tasks could alleviate the physical and mental load of doctors during interventions, allowing them to focus on diagnosis and decision-making tasks. In this paper, we present a synergic solution for intraluminal navigation consisting of a 3D printed endoscopic soft robot that can move safely inside luminal structures. Visual servoing, based on Convolutional Neural Networks (CNNs) is used to achieve the autonomous navigation task. The CNN is trained with phantoms and in-vivo data to segment the lumen, and a model-less approach is presented to control the movement in constrained environments. The proposed robot is validated in anatomical phantoms in different path configurations. We analyze the movement of the robot using different metrics such as task completion time, smoothness, error in the steady-state, and mean and maximum error. We show that our method is suitable to navigate safely in hollow environments and conditions which are different than the ones the network was originally trained on.