 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Modal Video Retrieval with Meta-Optimized Frames
Oct 16, 2022
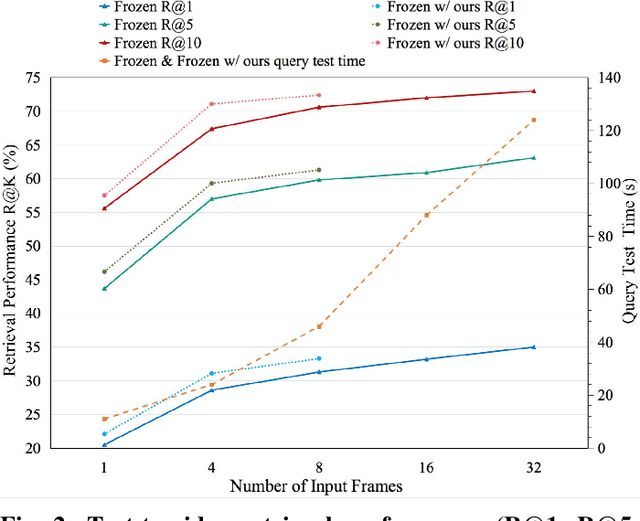
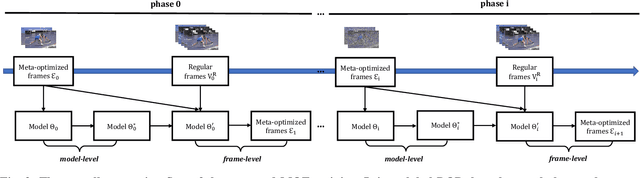
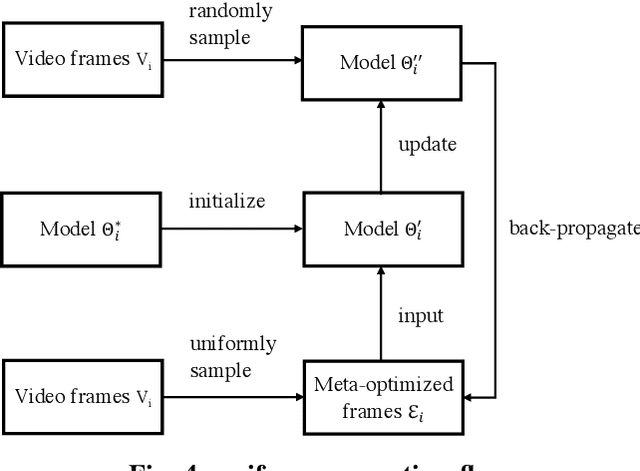
Cross-modal video retrieval aims to retrieve the semantically relevant videos given a text as a query, and is one of the fundamental tasks in Multimedia. Most of top-performing methods primarily leverage Visual Transformer (ViT) to extract video features [1, 2, 3], suffering from high computational complexity of ViT especially for encoding long videos. A common and simple solution is to uniformly sample a small number (say, 4 or 8) of frames from the video (instead of using the whole video) as input to ViT. The number of frames has a strong influence on the performance of ViT, e.g., using 8 frames performs better than using 4 frames yet needs more computational resources, resulting in a trade-off. To get free from this trade-off, this paper introduces an automatic video compression method based on a bilevel optimization program (BOP) consisting of both model-level (i.e., base-level) and frame-level (i.e., meta-level) optimizations. The model-level learns a cross-modal video retrieval model whose input is the "compressed frames" learned by frame-level optimization. In turn, the frame-level optimization is through gradient descent using the meta loss of video retrieval model computed on the whole video. We call this BOP method as well as the "compressed frames" as Meta-Optimized Frames (MOF). By incorporating MOF, the video retrieval model is able to utilize the information of whole videos (for training) while taking only a small number of input frames in actual implementation. The convergence of MOF is guaranteed by meta gradient descent algorithms. For evaluation, we conduct extensive experiments of cross-modal video retrieval on three large-scale benchmarks: MSR-VTT, MSVD, and DiDeMo. Our results show that MOF is a generic and efficient method to boost multiple baseline methods, and can achieve a new state-of-the-art performance.
Improving Compositional Generalization in Math Word Problem Solving
Sep 03, 2022



Compositional generalization refers to a model's capability to generalize to newly composed input data based on the data components observed during training. It has triggered a series of compositional generalization analysis on different tasks as generalization is an important aspect of language and problem solving skills. However, the similar discussion on math word problems (MWPs) is limited. In this manuscript, we study compositional generalization in MWP solving. Specifically, we first introduce a data splitting method to create compositional splits from existing MWP datasets. Meanwhile, we synthesize data to isolate the effect of compositions. To improve the compositional generalization in MWP solving, we propose an iterative data augmentation method that includes diverse compositional variation into training data and could collaborate with MWP methods. During the evaluation, we examine a set of methods and find all of them encounter severe performance loss on the evaluated datasets. We also find our data augmentation method could significantly improve the compositional generalization of general MWP methods. Code is available at https://github.com/demoleiwang/CGMWP.
Explanation Guided Contrastive Learning for Sequential Recommendation
Sep 03, 2022
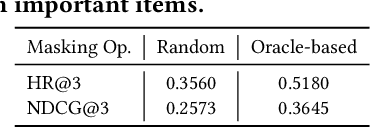
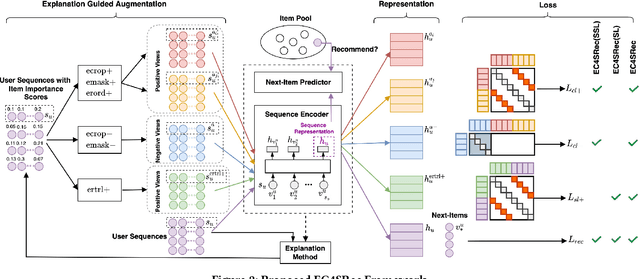
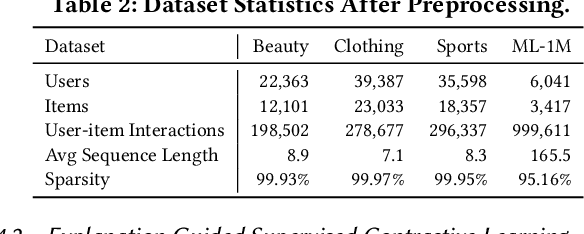
Recently, contrastive learning has been applied to the sequential recommendation task to address data sparsity caused by users with few item interactions and items with few user adoptions. Nevertheless, the existing contrastive learning-based methods fail to ensure that the positive (or negative) sequence obtained by some random augmentation (or sequence sampling) on a given anchor user sequence remains to be semantically similar (or different). When the positive and negative sequences turn out to be false positive and false negative respectively, it may lead to degraded recommendation performance. In this work, we address the above problem by proposing Explanation Guided Augmentations (EGA) and Explanation Guided Contrastive Learning for Sequential Recommendation (EC4SRec) model framework. The key idea behind EGA is to utilize explanation method(s) to determine items' importance in a user sequence and derive the positive and negative sequences accordingly. EC4SRec then combines both self-supervised and supervised contrastive learning over the positive and negative sequences generated by EGA operations to improve sequence representation learning for more accurate recommendation results. Extensive experiments on four real-world benchmark datasets demonstrate that EC4SRec outperforms the state-of-the-art sequential recommendation methods and two recent contrastive learning-based sequential recommendation methods, CL4SRec and DuoRec. Our experiments also show that EC4SRec can be easily adapted for different sequence encoder backbones (e.g., GRU4Rec and Caser), and improve their recommendation performance.
NOAHQA: Numerical Reasoning with Interpretable Graph Question Answering Dataset
Oct 14, 2021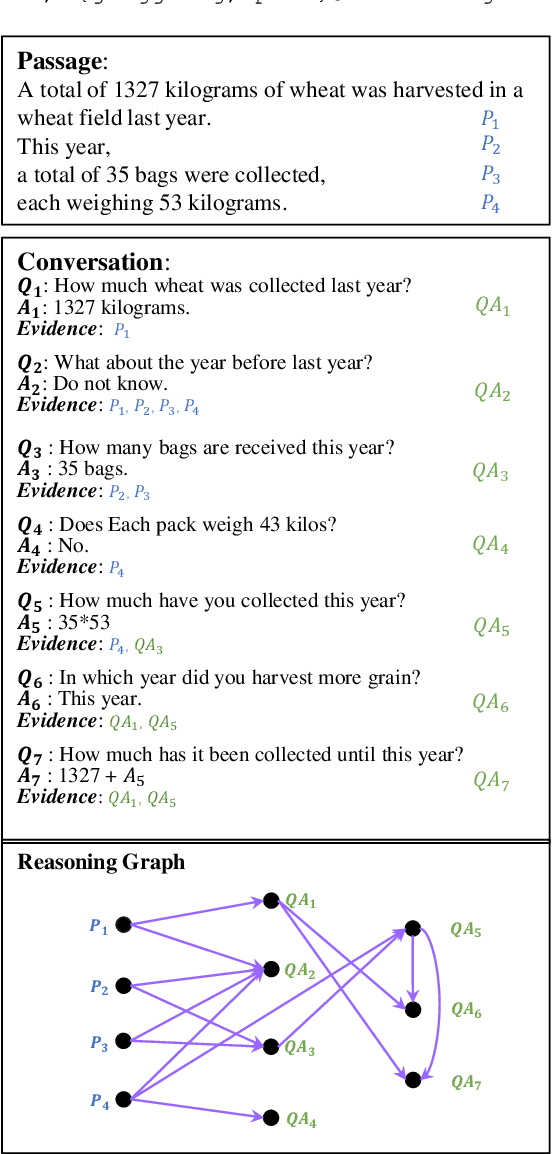

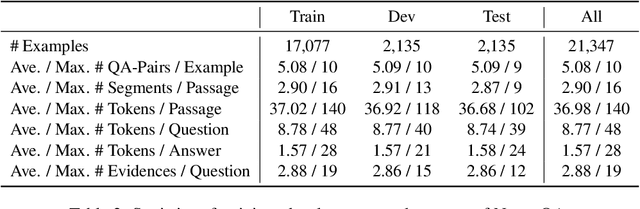
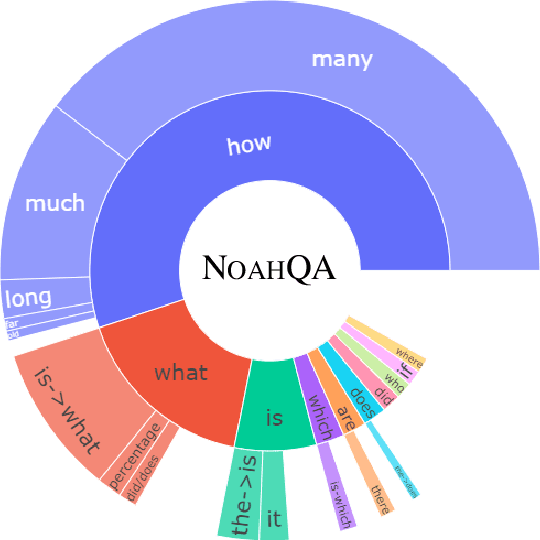
While diverse question answering (QA) datasets have been proposed and contributed significantly to the development of deep learning models for QA tasks, the existing datasets fall short in two aspects. First, we lack QA datasets covering complex questions that involve answers as well as the reasoning processes to get the answers. As a result, the state-of-the-art QA research on numerical reasoning still focuses on simple calculations and does not provide the mathematical expressions or evidences justifying the answers. Second, the QA community has contributed much effort to improving the interpretability of QA models. However, these models fail to explicitly show the reasoning process, such as the evidence order for reasoning and the interactions between different pieces of evidence. To address the above shortcomings, we introduce NOAHQA, a conversational and bilingual QA dataset with questions requiring numerical reasoning with compound mathematical expressions. With NOAHQA, we develop an interpretable reasoning graph as well as the appropriate evaluation metric to measure the answer quality. We evaluate the state-of-the-art QA models trained using existing QA datasets on NOAHQA and show that the best among them can only achieve 55.5 exact match scores, while the human performance is 89.7. We also present a new QA model for generating a reasoning graph where the reasoning graph metric still has a large gap compared with that of humans, e.g., 28 scores.
MWPToolkit: An Open-Source Framework for Deep Learning-Based Math Word Problem Solvers
Sep 18, 2021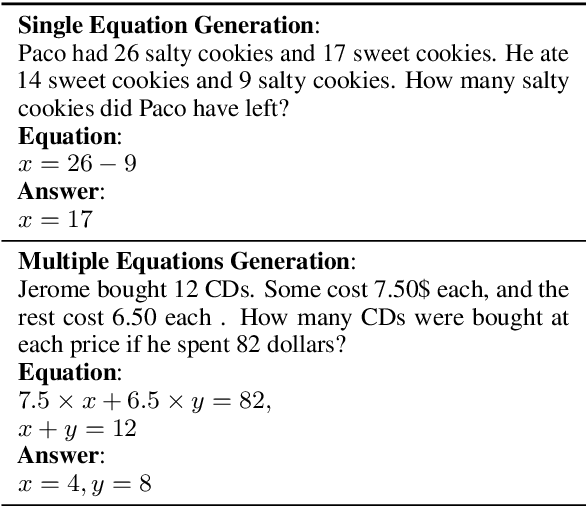
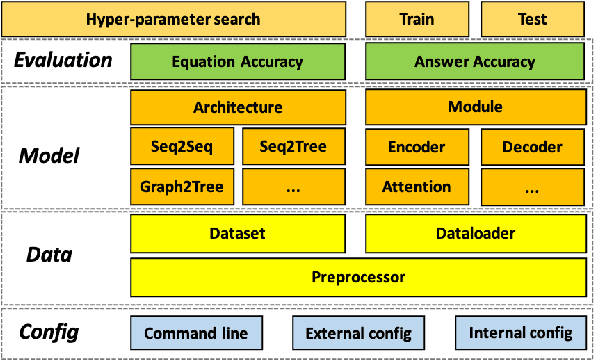
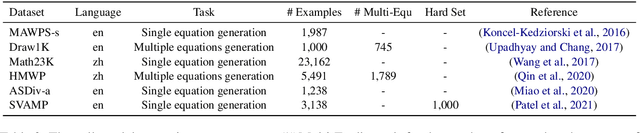
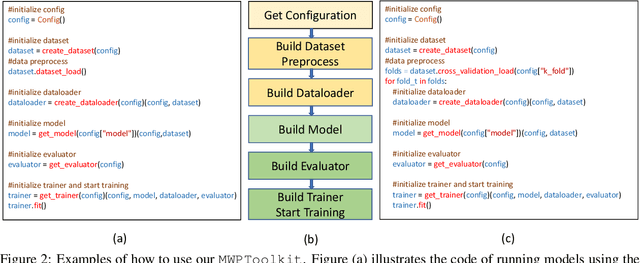
Developing automatic Math Word Problem (MWP) solvers has been an interest of NLP researchers since the 1960s. Over the last few years, there are a growing number of datasets and deep learning-based methods proposed for effectively solving MWPs. However, most existing methods are benchmarked soly on one or two datasets, varying in different configurations, which leads to a lack of unified, standardized, fair, and comprehensive comparison between methods. This paper presents MWPToolkit, the first open-source framework for solving MWPs. In MWPToolkit, we decompose the procedure of existing MWP solvers into multiple core components and decouple their models into highly reusable modules. We also provide a hyper-parameter search function to boost the performance. In total, we implement and compare 17 MWP solvers on 4 widely-used single equation generation benchmarks and 2 multiple equations generation benchmarks. These features enable our MWPToolkit to be suitable for researchers to reproduce advanced baseline models and develop new MWP solvers quickly. Code and documents are available at https://github.com/LYH-YF/MWPToolkit.
A Large-Scale Benchmark for Food Image Segmentation
May 12, 2021
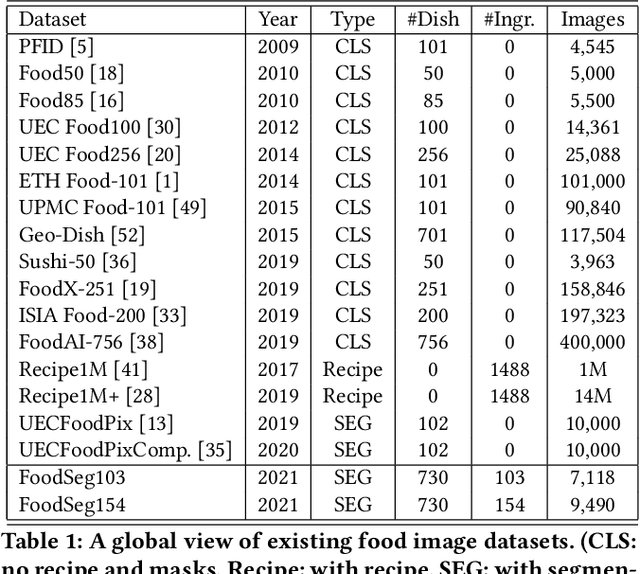

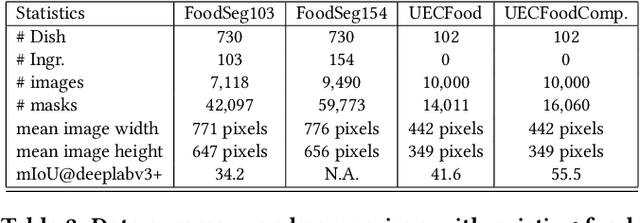
Food image segmentation is a critical and indispensible task for developing health-related applications such as estimating food calories and nutrients. Existing food image segmentation models are underperforming due to two reasons: (1) there is a lack of high quality food image datasets with fine-grained ingredient labels and pixel-wise location masks -- the existing datasets either carry coarse ingredient labels or are small in size; and (2) the complex appearance of food makes it difficult to localize and recognize ingredients in food images, e.g., the ingredients may overlap one another in the same image, and the identical ingredient may appear distinctly in different food images. In this work, we build a new food image dataset FoodSeg103 (and its extension FoodSeg154) containing 9,490 images. We annotate these images with 154 ingredient classes and each image has an average of 6 ingredient labels and pixel-wise masks. In addition, we propose a multi-modality pre-training approach called ReLeM that explicitly equips a segmentation model with rich and semantic food knowledge. In experiments, we use three popular semantic segmentation methods (i.e., Dilated Convolution based, Feature Pyramid based, and Vision Transformer based) as baselines, and evaluate them as well as ReLeM on our new datasets. We believe that the FoodSeg103 (and its extension FoodSeg154) and the pre-trained models using ReLeM can serve as a benchmark to facilitate future works on fine-grained food image understanding. We make all these datasets and methods public at \url{https://xiongweiwu.github.io/foodseg103.html}.
ENCONTER: Entity Constrained Progressive Sequence Generation via Insertion-based Transformer
Mar 17, 2021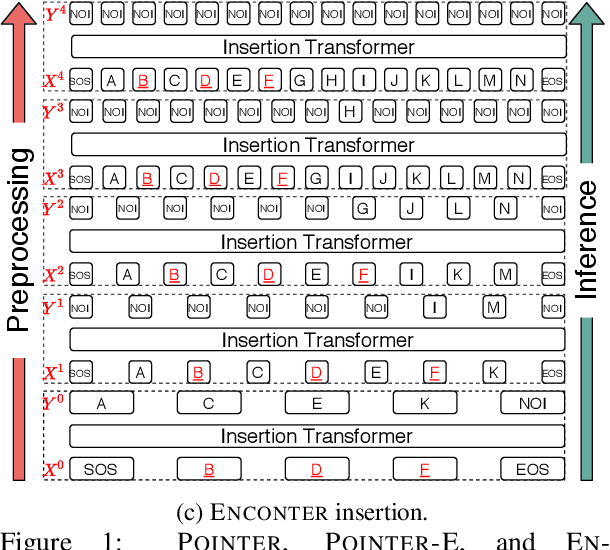
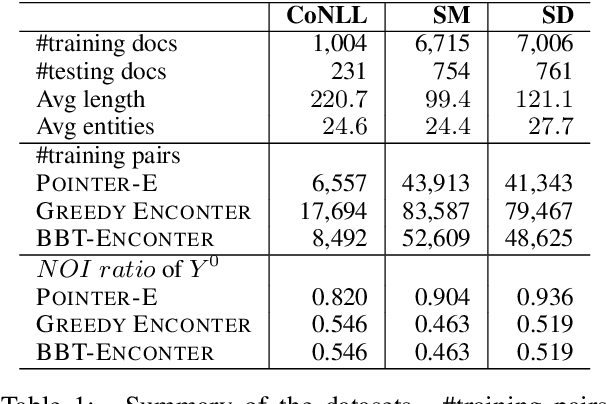
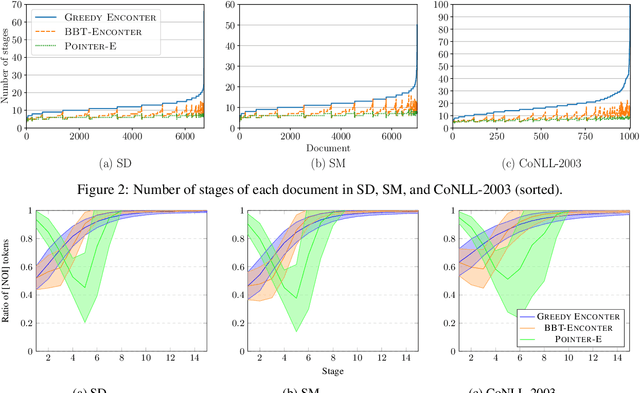
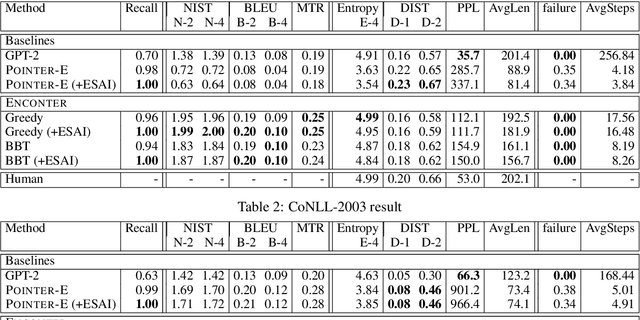
Pretrained using large amount of data, autoregressive language models are able to generate high quality sequences. However, these models do not perform well under hard lexical constraints as they lack fine control of content generation process. Progressive insertion-based transformers can overcome the above limitation and efficiently generate a sequence in parallel given some input tokens as constraint. These transformers however may fail to support hard lexical constraints as their generation process is more likely to terminate prematurely. The paper analyses such early termination problems and proposes the Entity-constrained insertion transformer (ENCONTER), a new insertion transformer that addresses the above pitfall without compromising much generation efficiency. We introduce a new training strategy that considers predefined hard lexical constraints (e.g., entities to be included in the generated sequence). Our experiments show that ENCONTER outperforms other baseline models in several performance metrics rendering it more suitable in practical applications. Our code is available at https://github.com/LARC-CMU-SMU/Enconter
DeepStyle: User Style Embedding for Authorship Attribution of Short Texts
Mar 14, 2021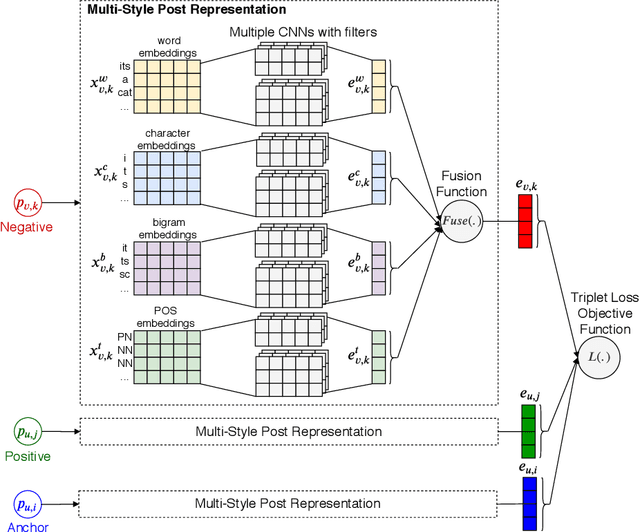
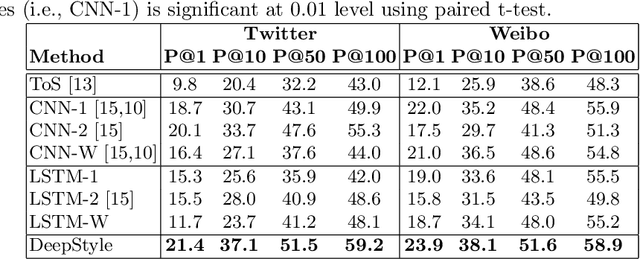
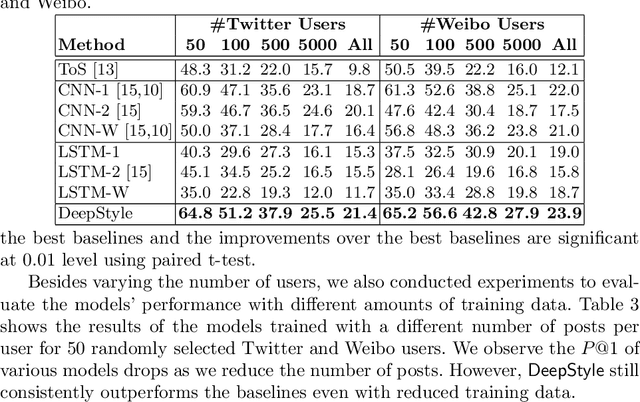
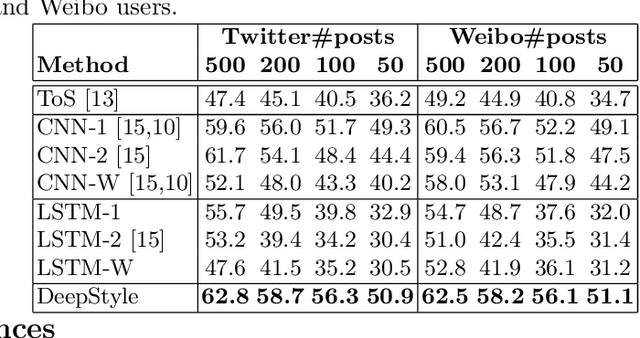
Authorship attribution (AA), which is the task of finding the owner of a given text, is an important and widely studied research topic with many applications. Recent works have shown that deep learning methods could achieve significant accuracy improvement for the AA task. Nevertheless, most of these proposed methods represent user posts using a single type of feature (e.g., word bi-grams) and adopt a text classification approach to address the task. Furthermore, these methods offer very limited explainability of the AA results. In this paper, we address these limitations by proposing DeepStyle, a novel embedding-based framework that learns the representations of users' salient writing styles. We conduct extensive experiments on two real-world datasets from Twitter and Weibo. Our experiment results show that DeepStyle outperforms the state-of-the-art baselines on the AA task.
Transforming Facial Weight of Real Images by Editing Latent Space of StyleGAN
Nov 05, 2020



We present an invert-and-edit framework to automatically transform facial weight of an input face image to look thinner or heavier by leveraging semantic facial attributes encoded in the latent space of Generative Adversarial Networks (GANs). Using a pre-trained StyleGAN as the underlying generator, we first employ an optimization-based embedding method to invert the input image into the StyleGAN latent space. Then, we identify the facial-weight attribute direction in the latent space via supervised learning and edit the inverted latent code by moving it positively or negatively along the extracted feature axis. Our framework is empirically shown to produce high-quality and realistic facial-weight transformations without requiring training GANs with a large amount of labeled face images from scratch. Ultimately, our framework can be utilized as part of an intervention to motivate individuals to make healthier food choices by visualizing the future impacts of their behavior on appearance.
On Predicting Personal Values of Social Media Users using Community-Specific Language Features and Personal Value Correlation
Jul 16, 2020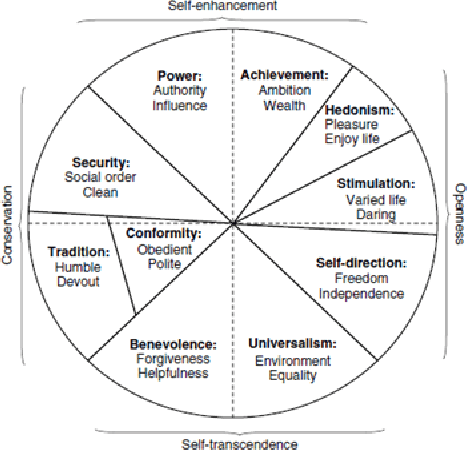
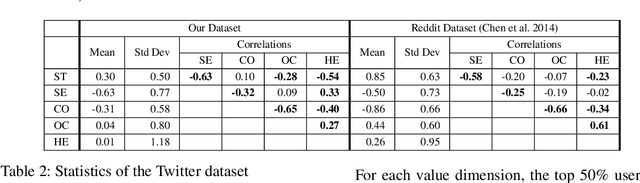
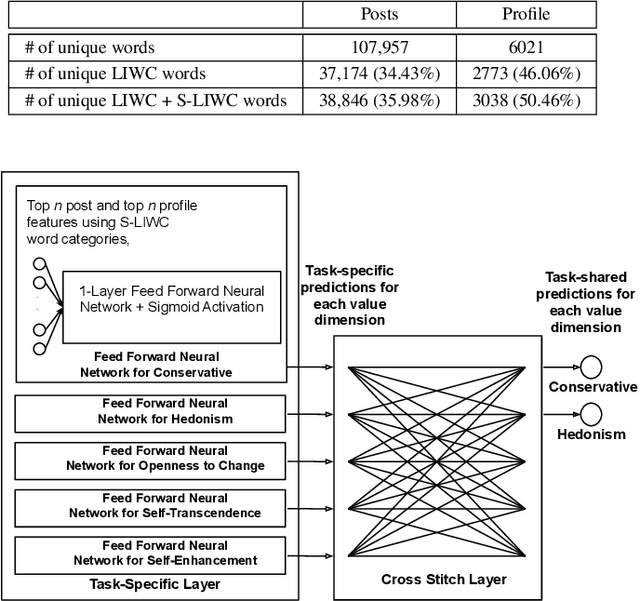
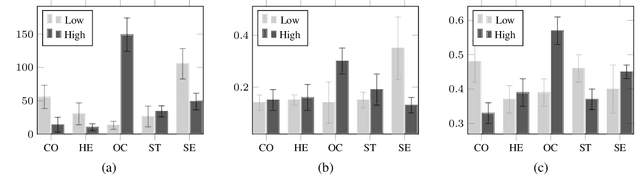
Personal values have significant influence on individuals' behaviors, preferences, and decision making. It is therefore not a surprise that personal values of a person could influence his or her social media content and activities. Instead of getting users to complete personal value questionnaire, researchers have looked into a non-intrusive and highly scalable approach to predict personal values using user-generated social media data. Nevertheless, geographical differences in word usage and profile information are issues to be addressed when designing such prediction models. In this work, we focus on analyzing Singapore users' personal values, and developing effective models to predict their personal values using their Facebook data. These models leverage on word categories in Linguistic Inquiry and Word Count (LIWC) and correlations among personal values. The LIWC word categories are adapted to non-English word use in Singapore. We incorporate the correlations among personal values into our proposed Stack Model consisting of a task-specific layer of base models and a cross-stitch layer model. Through experiments, we show that our proposed model predicts personal values with considerable improvement of accuracy over the previous works. Moreover, we use the stack model to predict the personal values of a large community of Twitter users using their public tweet content and empirically derive several interesting findings about their online behavior consistent with earlier findings in the social science and social media literature.