 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisually Grounded Reasoning across Languages and Cultures
Sep 28, 2021
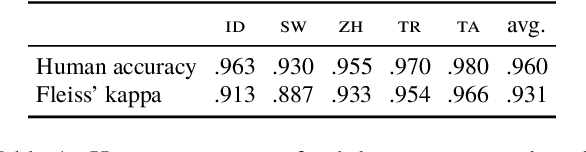
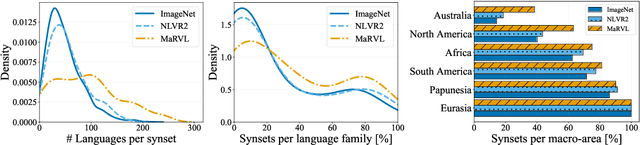
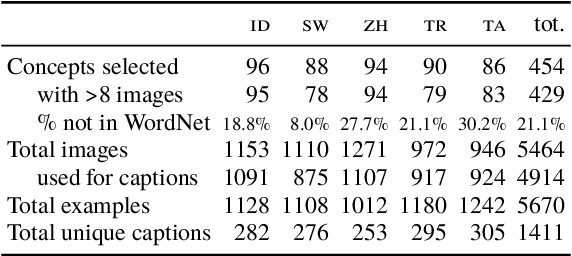
The design of widespread vision-and-language datasets and pre-trained encoders directly adopts, or draws inspiration from, the concepts and images of ImageNet. While one can hardly overestimate how much this benchmark contributed to progress in computer vision, it is mostly derived from lexical databases and image queries in English, resulting in source material with a North American or Western European bias. Therefore, we devise a new protocol to construct an ImageNet-style hierarchy representative of more languages and cultures. In particular, we let the selection of both concepts and images be entirely driven by native speakers, rather than scraping them automatically. Specifically, we focus on a typologically diverse set of languages, namely, Indonesian, Mandarin Chinese, Swahili, Tamil, and Turkish. On top of the concepts and images obtained through this new protocol, we create a multilingual dataset for {M}ulticultur{a}l {R}easoning over {V}ision and {L}anguage (MaRVL) by eliciting statements from native speaker annotators about pairs of images. The task consists of discriminating whether each grounded statement is true or false. We establish a series of baselines using state-of-the-art models and find that their cross-lingual transfer performance lags dramatically behind supervised performance in English. These results invite us to reassess the robustness and accuracy of current state-of-the-art models beyond a narrow domain, but also open up new exciting challenges for the development of truly multilingual and multicultural systems.
Towards Zero-shot Language Modeling
Aug 06, 2021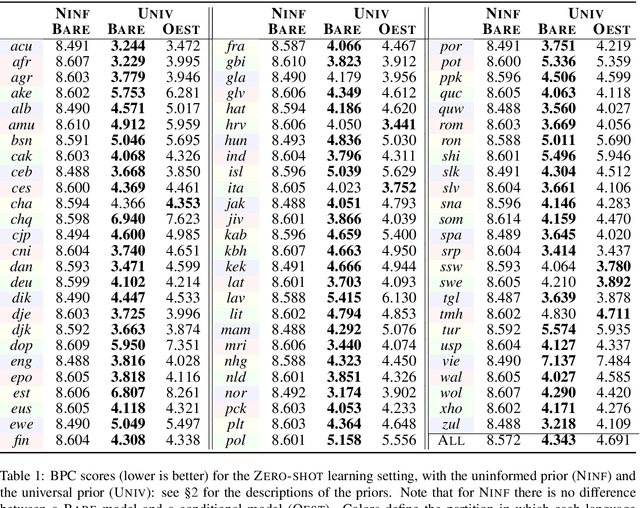
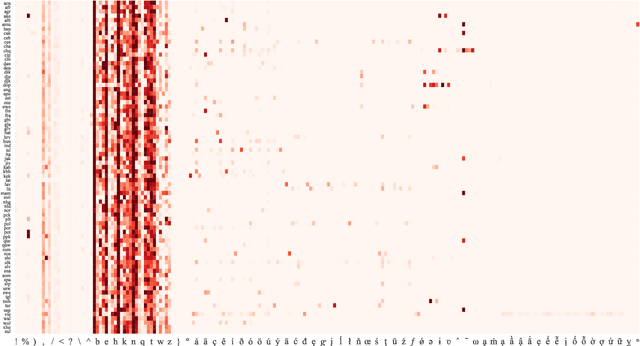
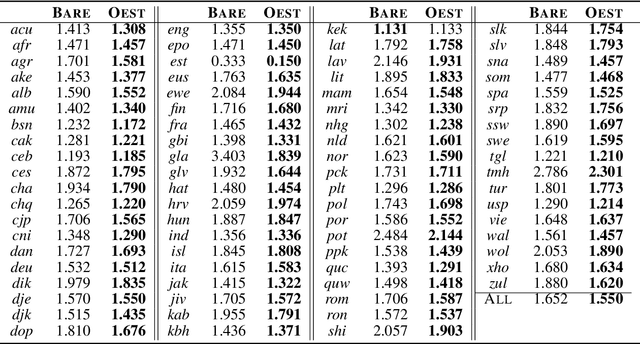
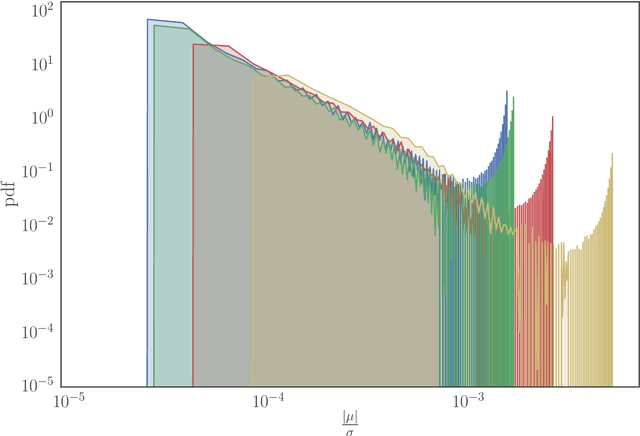
Can we construct a neural model that is inductively biased towards learning human languages? Motivated by this question, we aim at constructing an informative prior over neural weights, in order to adapt quickly to held-out languages in the task of character-level language modeling. We infer this distribution from a sample of typologically diverse training languages via Laplace approximation. The use of such a prior outperforms baseline models with an uninformative prior (so-called "fine-tuning") in both zero-shot and few-shot settings. This shows that the prior is imbued with universal phonological knowledge. Moreover, we harness additional language-specific side information as distant supervision for held-out languages. Specifically, we condition language models on features from typological databases, by concatenating them to hidden states or generating weights with hyper-networks. These features appear beneficial in the few-shot setting, but not in the zero-shot setting. Since the paucity of digital texts affects the majority of the world's languages, we hope that these findings will help broaden the scope of applications for language technology.
Modelling Latent Translations for Cross-Lingual Transfer
Jul 23, 2021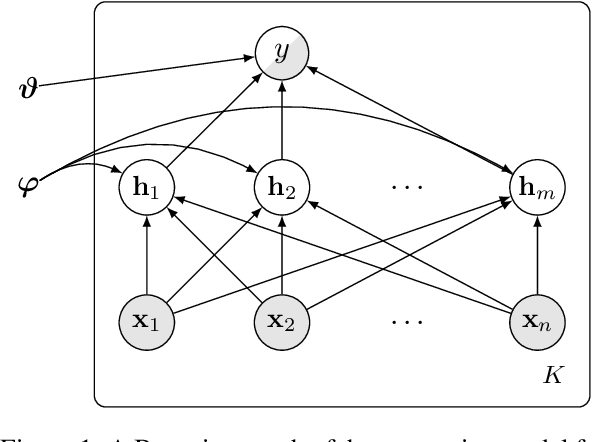
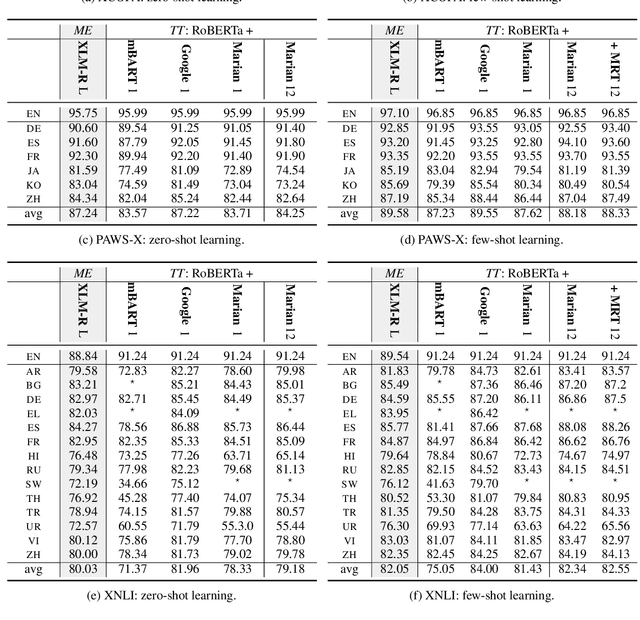
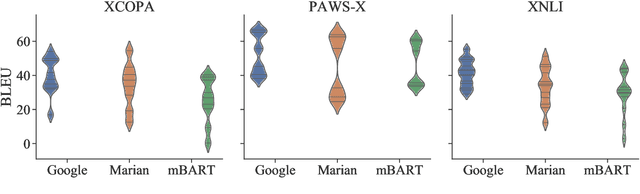

While achieving state-of-the-art results in multiple tasks and languages, translation-based cross-lingual transfer is often overlooked in favour of massively multilingual pre-trained encoders. Arguably, this is due to its main limitations: 1) translation errors percolating to the classification phase and 2) the insufficient expressiveness of the maximum-likelihood translation. To remedy this, we propose a new technique that integrates both steps of the traditional pipeline (translation and classification) into a single model, by treating the intermediate translations as a latent random variable. As a result, 1) the neural machine translation system can be fine-tuned with a variant of Minimum Risk Training where the reward is the accuracy of the downstream task classifier. Moreover, 2) multiple samples can be drawn to approximate the expected loss across all possible translations during inference. We evaluate our novel latent translation-based model on a series of multilingual NLU tasks, including commonsense reasoning, paraphrase identification, and natural language inference. We report gains for both zero-shot and few-shot learning setups, up to 2.7 accuracy points on average, which are even more prominent for low-resource languages (e.g., Haitian Creole). Finally, we carry out in-depth analyses comparing different underlying NMT models and assessing the impact of alternative translations on the downstream performance.
Minimax and Neyman-Pearson Meta-Learning for Outlier Languages
Jun 02, 2021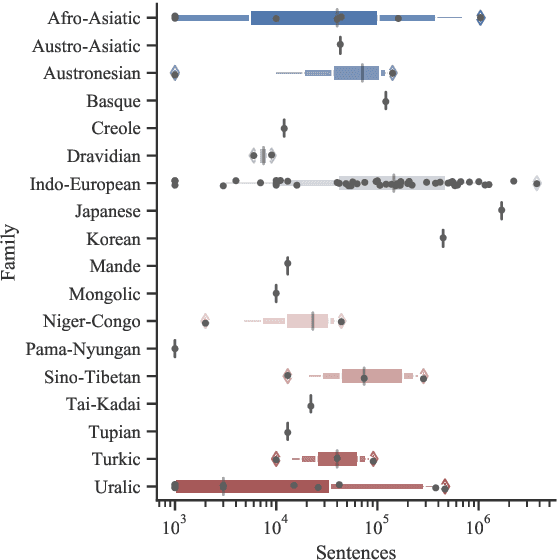
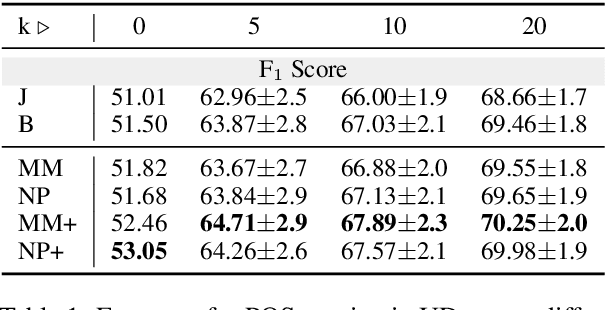
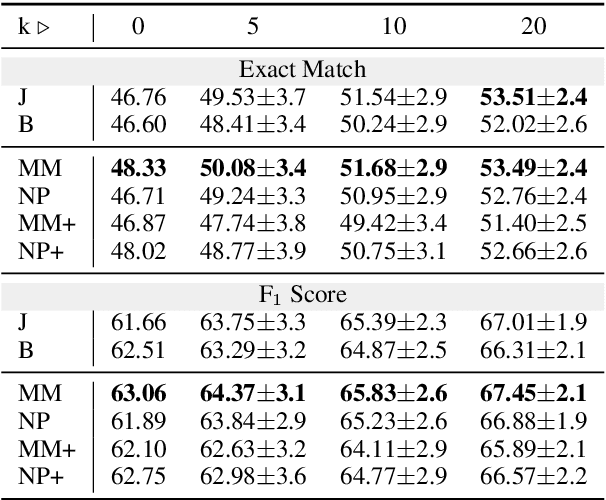
Model-agnostic meta-learning (MAML) has been recently put forth as a strategy to learn resource-poor languages in a sample-efficient fashion. Nevertheless, the properties of these languages are often not well represented by those available during training. Hence, we argue that the i.i.d. assumption ingrained in MAML makes it ill-suited for cross-lingual NLP. In fact, under a decision-theoretic framework, MAML can be interpreted as minimising the expected risk across training languages (with a uniform prior), which is known as Bayes criterion. To increase its robustness to outlier languages, we create two variants of MAML based on alternative criteria: Minimax MAML reduces the maximum risk across languages, while Neyman-Pearson MAML constrains the risk in each language to a maximum threshold. Both criteria constitute fully differentiable two-player games. In light of this, we propose a new adaptive optimiser solving for a local approximation to their Nash equilibrium. We evaluate both model variants on two popular NLP tasks, part-of-speech tagging and question answering. We report gains for their average and minimum performance across low-resource languages in zero- and few-shot settings, compared to joint multi-source transfer and vanilla MAML.
Differentiable Generative Phonology
Feb 12, 2021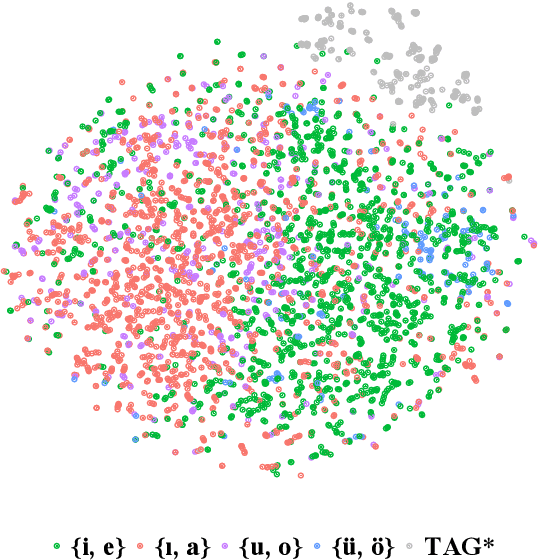
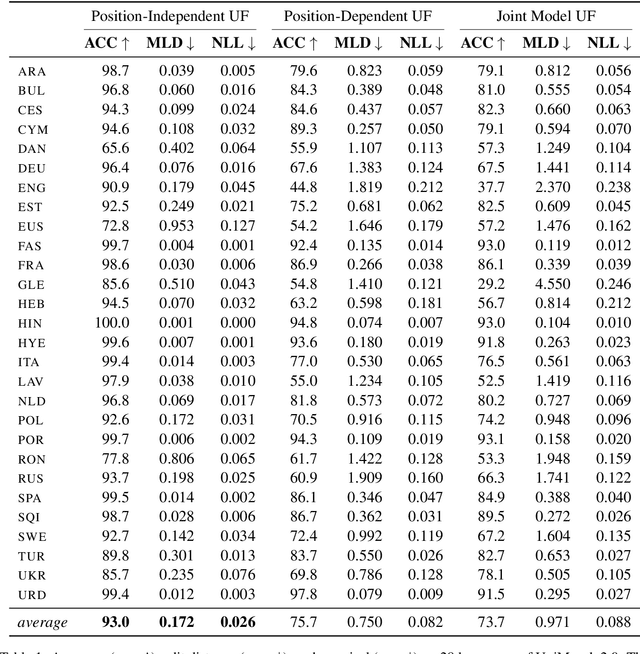
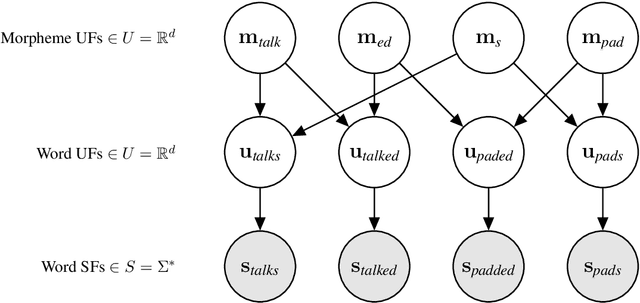
The goal of generative phonology, as formulated by Chomsky and Halle (1968), is to specify a formal system that explains the set of attested phonological strings in a language. Traditionally, a collection of rules (or constraints, in the case of optimality theory) and underlying forms (UF) are posited to work in tandem to generate phonological strings. However, the degree of abstraction of UFs with respect to their concrete realizations is contentious. As the main contribution of our work, we implement the phonological generative system as a neural model differentiable end-to-end, rather than as a set of rules or constraints. Contrary to traditional phonology, in our model, UFs are continuous vectors in $\mathbb{R}^d$, rather than discrete strings. As a consequence, UFs are discovered automatically rather than posited by linguists, and the model can scale to the size of a realistic vocabulary. Moreover, we compare several modes of the generative process, contemplating: i) the presence or absence of an underlying representation in between morphemes and surface forms (SFs); and ii) the conditional dependence or independence of UFs with respect to SFs. We evaluate the ability of each mode to predict attested phonological strings on 2 datasets covering 5 and 28 languages, respectively. The results corroborate two tenets of generative phonology, viz. the necessity for UFs and their independence from SFs. In general, our neural model of generative phonology learns both UFs and SFs automatically and on a large-scale.
Probing Pretrained Language Models for Lexical Semantics
Oct 12, 2020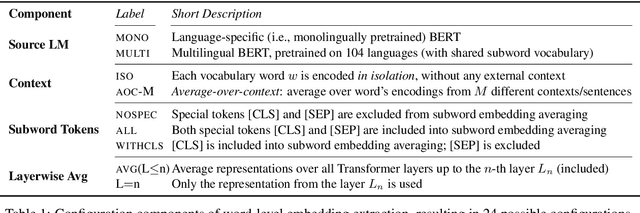
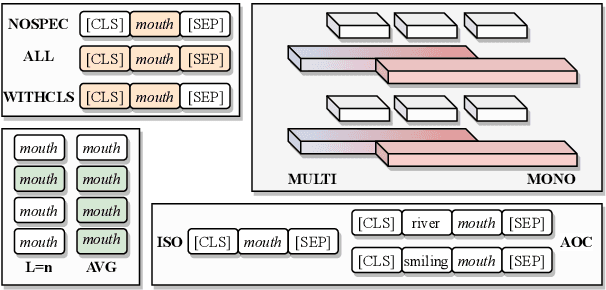
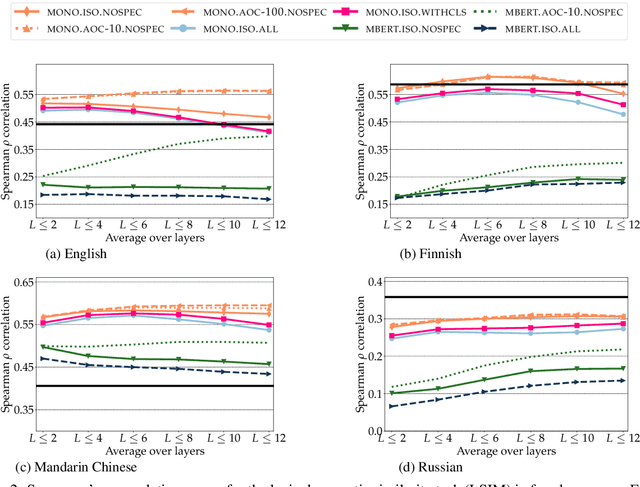
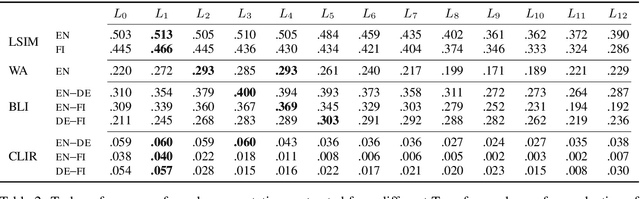
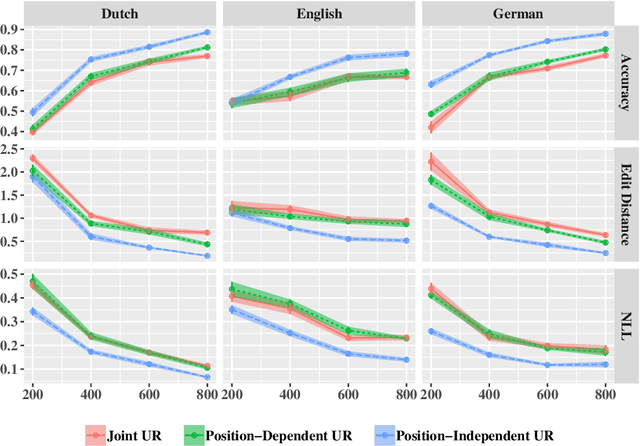
The success of large pretrained language models (LMs) such as BERT and RoBERTa has sparked interest in probing their representations, in order to unveil what types of knowledge they implicitly capture. While prior research focused on morphosyntactic, semantic, and world knowledge, it remains unclear to which extent LMs also derive lexical type-level knowledge from words in context. In this work, we present a systematic empirical analysis across six typologically diverse languages and five different lexical tasks, addressing the following questions: 1) How do different lexical knowledge extraction strategies (monolingual versus multilingual source LM, out-of-context versus in-context encoding, inclusion of special tokens, and layer-wise averaging) impact performance? How consistent are the observed effects across tasks and languages? 2) Is lexical knowledge stored in few parameters, or is it scattered throughout the network? 3) How do these representations fare against traditional static word vectors in lexical tasks? 4) Does the lexical information emerging from independently trained monolingual LMs display latent similarities? Our main results indicate patterns and best practices that hold universally, but also point to prominent variations across languages and tasks. Moreover, we validate the claim that lower Transformer layers carry more type-level lexical knowledge, but also show that this knowledge is distributed across multiple layers.
XCOPA: A Multilingual Dataset for Causal Commonsense Reasoning
May 01, 2020
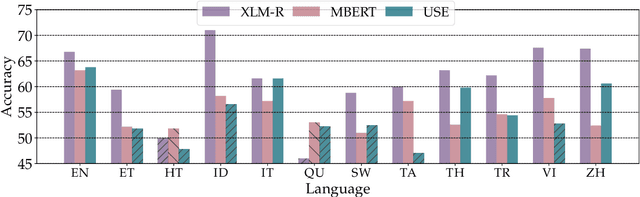

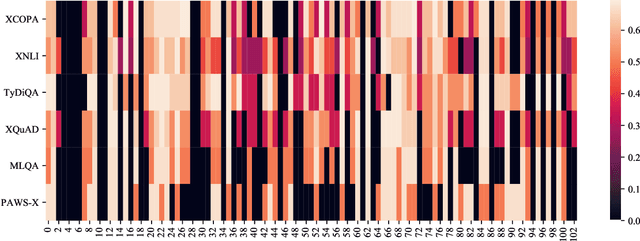
In order to simulate human language capacity, natural language processing systems must complement the explicit information derived from raw text with the ability to reason about the possible causes and outcomes of everyday situations. Moreover, the acquired world knowledge should generalise to new languages, modulo cultural differences. Advances in machine commonsense reasoning and cross-lingual transfer depend on the availability of challenging evaluation benchmarks. Motivated by both demands, we introduce Cross-lingual Choice of Plausible Alternatives (XCOPA), a typologically diverse multilingual dataset for causal commonsense reasoning in 11 languages. We benchmark a range of state-of-the-art models on this novel dataset, revealing that current methods based on multilingual pretraining and zero-shot fine-tuning transfer suffer from the curse of multilinguality and fall short of performance in monolingual settings by a large margin. Finally, we propose ways to adapt these models to out-of-sample resource-lean languages where only a small corpus or a bilingual dictionary is available, and report substantial improvements over the random baseline. XCOPA is available at github.com/cambridgeltl/xcopa.
Internal and external pressures on language emergence: least effort, object constancy and frequency
Apr 08, 2020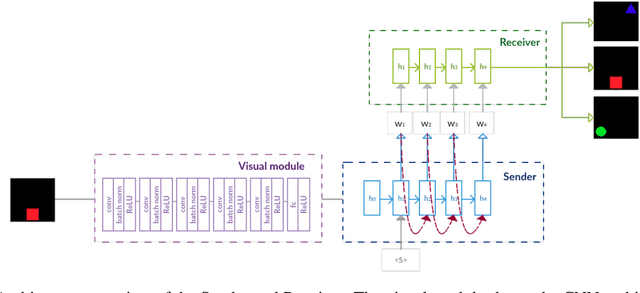
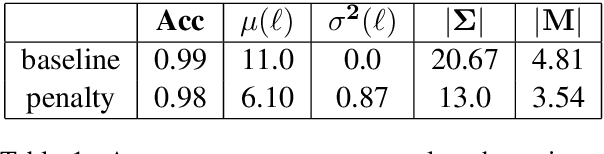
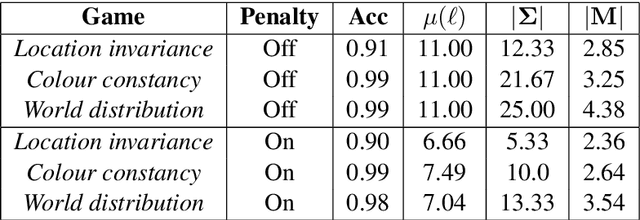
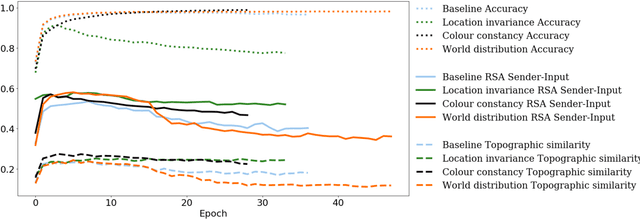
In previous work, artificial agents were shown to achieve almost perfect accuracy in referential games where they have to communicate to identify images. Nevertheless, the resulting communication protocols rarely display salient features of natural languages, such as compositionality. In this paper, we propose some realistic sources of pressure on communication that avert this outcome. More specifically, we formalise the principle of least effort through an auxiliary objective. Moreover, we explore several game variants, inspired by the principle of object constancy, in which we alter the frequency, position, and luminosity of the objects in the images. We perform an extensive analysis on their effect through compositionality metrics, diagnostic classifiers, and zero-shot evaluation. Our findings reveal that the proposed sources of pressure result in emerging languages with less redundancy, more focus on high-level conceptual information, and better abilities of generalisation. Overall, our contributions reduce the gap between emergent and natural languages.
Multi-SimLex: A Large-Scale Evaluation of Multilingual and Cross-Lingual Lexical Semantic Similarity
Mar 10, 2020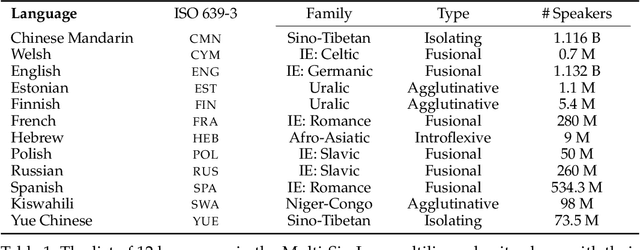
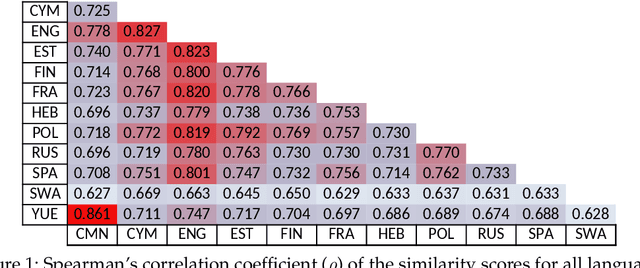

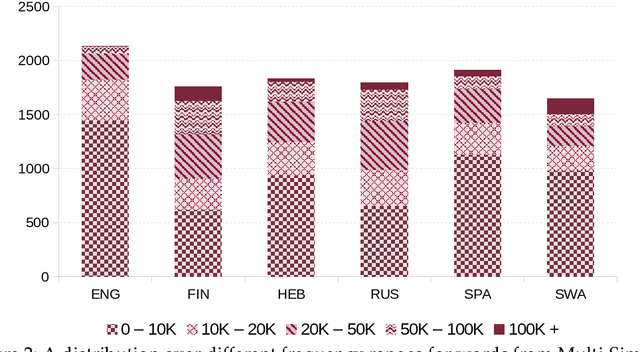
We introduce Multi-SimLex, a large-scale lexical resource and evaluation benchmark covering datasets for 12 typologically diverse languages, including major languages (e.g., Mandarin Chinese, Spanish, Russian) as well as less-resourced ones (e.g., Welsh, Kiswahili). Each language dataset is annotated for the lexical relation of semantic similarity and contains 1,888 semantically aligned concept pairs, providing a representative coverage of word classes (nouns, verbs, adjectives, adverbs), frequency ranks, similarity intervals, lexical fields, and concreteness levels. Additionally, owing to the alignment of concepts across languages, we provide a suite of 66 cross-lingual semantic similarity datasets. Due to its extensive size and language coverage, Multi-SimLex provides entirely novel opportunities for experimental evaluation and analysis. On its monolingual and cross-lingual benchmarks, we evaluate and analyze a wide array of recent state-of-the-art monolingual and cross-lingual representation models, including static and contextualized word embeddings (such as fastText, M-BERT and XLM), externally informed lexical representations, as well as fully unsupervised and (weakly) supervised cross-lingual word embeddings. We also present a step-by-step dataset creation protocol for creating consistent, Multi-Simlex-style resources for additional languages. We make these contributions -- the public release of Multi-SimLex datasets, their creation protocol, strong baseline results, and in-depth analyses which can be be helpful in guiding future developments in multilingual lexical semantics and representation learning -- available via a website which will encourage community effort in further expansion of Multi-Simlex to many more languages. Such a large-scale semantic resource could inspire significant further advances in NLP across languages.
Informing Unsupervised Pretraining with External Linguistic Knowledge
Sep 05, 2019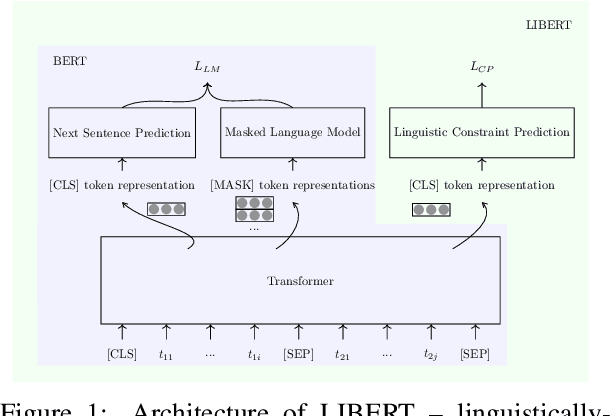

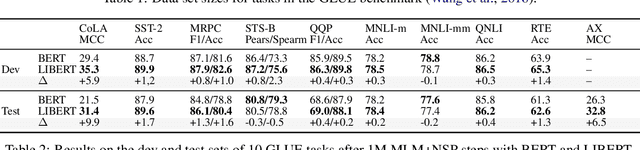
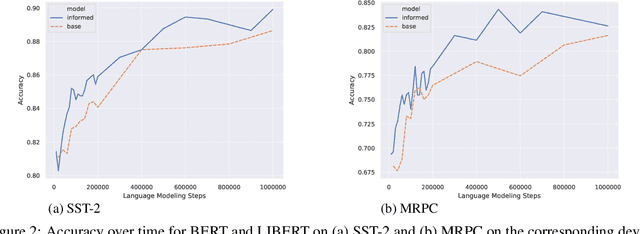
Unsupervised pretraining models have been shown to facilitate a wide range of downstream applications. These models, however, still encode only the distributional knowledge, incorporated through language modeling objectives. In this work, we complement the encoded distributional knowledge with external lexical knowledge. We generalize the recently proposed (state-of-the-art) unsupervised pretraining model BERT to a multi-task learning setting: we couple BERT's masked language modeling and next sentence prediction objectives with the auxiliary binary word relation classification, through which we inject clean linguistic knowledge into the model. Our initial experiments suggest that our "linguistically-informed" BERT (LIBERT) yields performance gains over the linguistically-blind "vanilla" BERT on several language understanding tasks.