 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
Jun 08, 2020
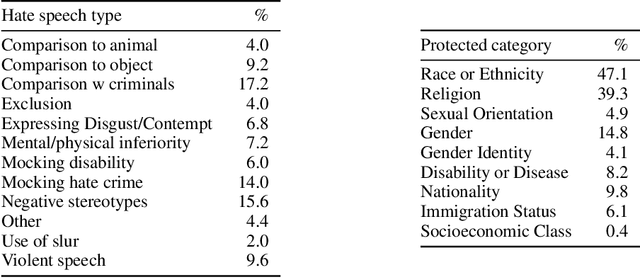
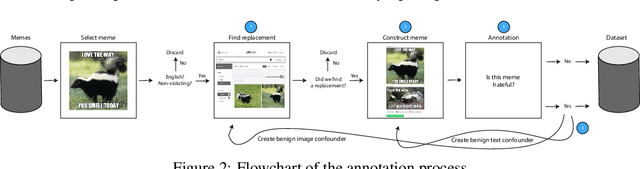

This work proposes a new challenge set for multimodal classification, focusing on detecting hate speech in multimodal memes. It is constructed such that unimodal models struggle and only multimodal models can succeed: difficult examples ("benign confounders") are added to the dataset to make it hard to rely on unimodal signals. The task requires subtle reasoning, yet is straightforward to evaluate as a binary classification problem. We provide baseline performance numbers for unimodal models, as well as for multimodal models with various degrees of sophistication. We find that state-of-the-art methods perform poorly compared to humans (64.73% vs. 84.7% accuracy), illustrating the difficulty of the task and highlighting the challenge that this important problem poses to the community.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
May 22, 2020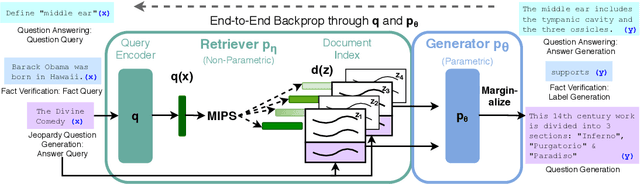
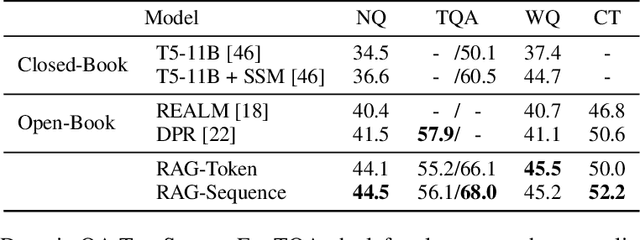
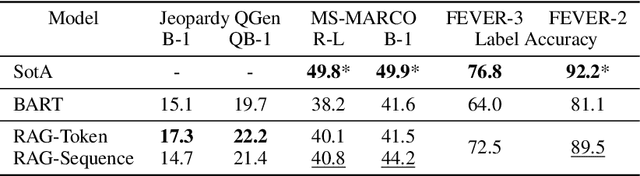

Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems. Pre-trained models with a differentiable access mechanism to explicit non-parametric memory can overcome this issue, but have so far been only investigated for extractive downstream tasks. We explore a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) -- models which combine pre-trained parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks, outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art parametric-only seq2seq baseline.
Multi-Dimensional Gender Bias Classification
May 01, 2020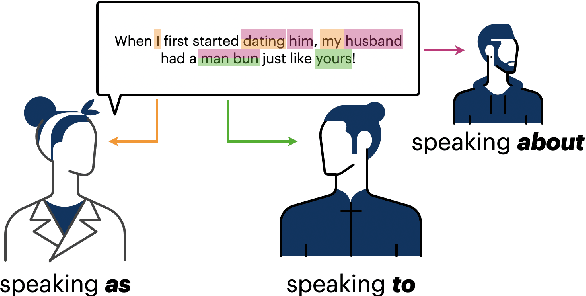
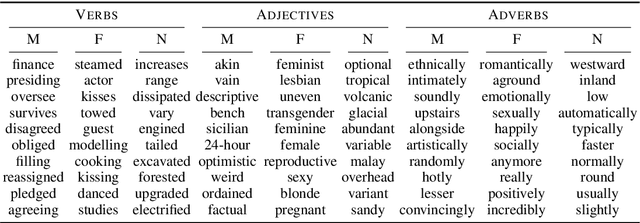
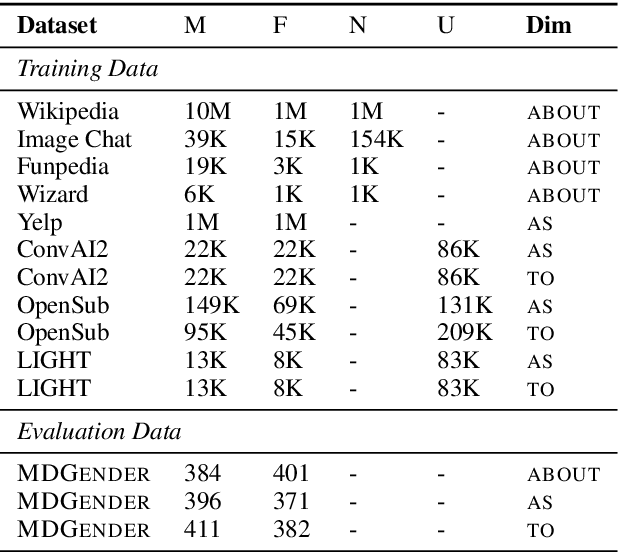
Machine learning models are trained to find patterns in data. NLP models can inadvertently learn socially undesirable patterns when training on gender biased text. In this work, we propose a general framework that decomposes gender bias in text along several pragmatic and semantic dimensions: bias from the gender of the person being spoken about, bias from the gender of the person being spoken to, and bias from the gender of the speaker. Using this fine-grained framework, we automatically annotate eight large scale datasets with gender information. In addition, we collect a novel, crowdsourced evaluation benchmark of utterance-level gender rewrites. Distinguishing between gender bias along multiple dimensions is important, as it enables us to train finer-grained gender bias classifiers. We show our classifiers prove valuable for a variety of important applications, such as controlling for gender bias in generative models, detecting gender bias in arbitrary text, and shed light on offensive language in terms of genderedness.
Unsupervised Question Decomposition for Question Answering
Feb 22, 2020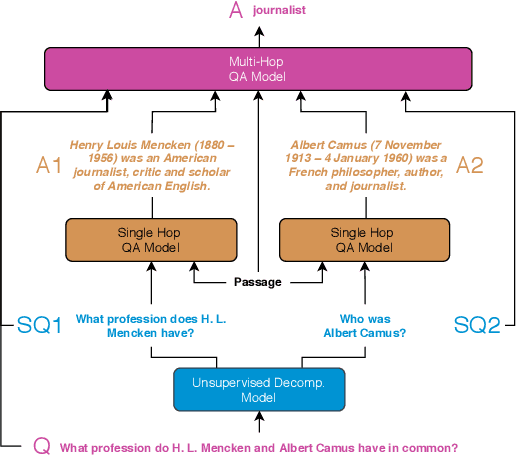
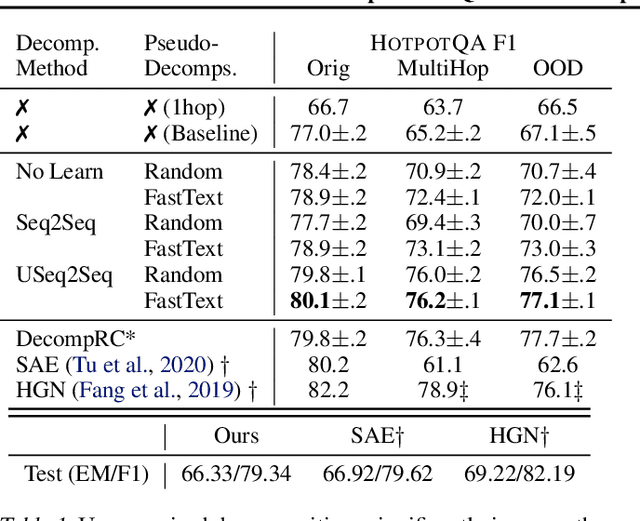
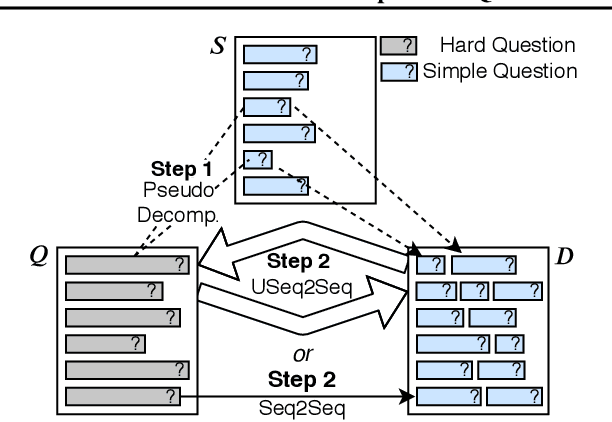

We aim to improve question answering (QA) by decomposing hard questions into easier sub-questions that existing QA systems can answer. Since collecting labeled decompositions is cumbersome, we propose an unsupervised approach to produce sub-questions. Specifically, by leveraging >10M questions from Common Crawl, we learn to map from the distribution of multi-hop questions to the distribution of single-hop sub-questions. We answer sub-questions with an off-the-shelf QA model and incorporate the resulting answers in a downstream, multi-hop QA system. On a popular multi-hop QA dataset, HotpotQA, we show large improvements over a strong baseline, especially on adversarial and out-of-domain questions. Our method is generally applicable and automatically learns to decompose questions of different classes, while matching the performance of decomposition methods that rely heavily on hand-engineering and annotation.
I love your chain mail! Making knights smile in a fantasy game world: Open-domain goal-oriented dialogue agents
Feb 10, 2020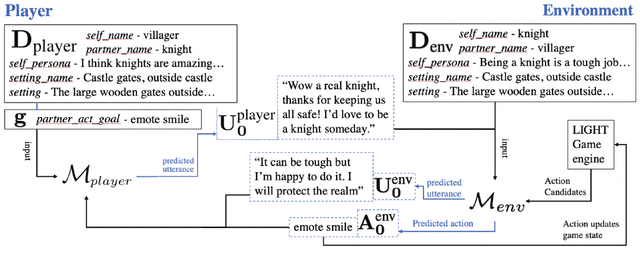

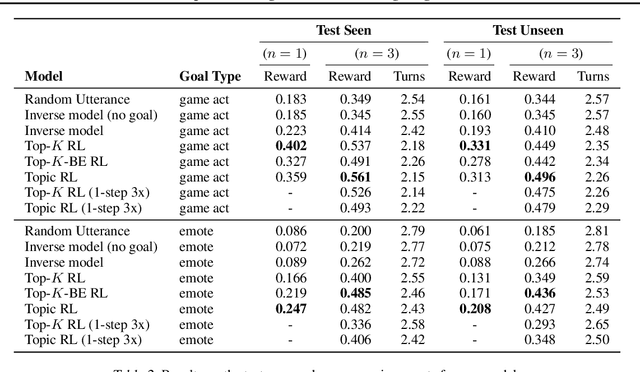
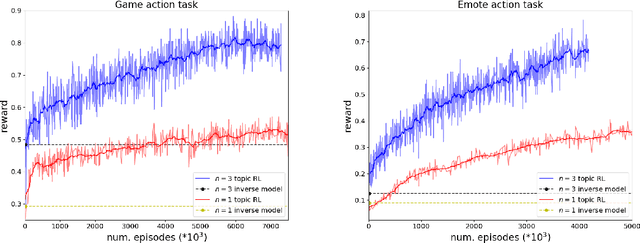
Dialogue research tends to distinguish between chit-chat and goal-oriented tasks. While the former is arguably more naturalistic and has a wider use of language, the latter has clearer metrics and a straightforward learning signal. Humans effortlessly combine the two, for example engaging in chit-chat with the goal of exchanging information or eliciting a specific response. Here, we bridge the divide between these two domains in the setting of a rich multi-player text-based fantasy environment where agents and humans engage in both actions and dialogue. Specifically, we train a goal-oriented model with reinforcement learning against an imitation-learned ``chit-chat'' model with two approaches: the policy either learns to pick a topic or learns to pick an utterance given the top-K utterances from the chit-chat model. We show that both models outperform an inverse model baseline and can converse naturally with their dialogue partner in order to achieve goals.
On the interaction between supervision and self-play in emergent communication
Feb 04, 2020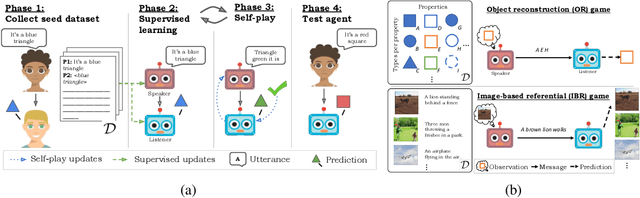
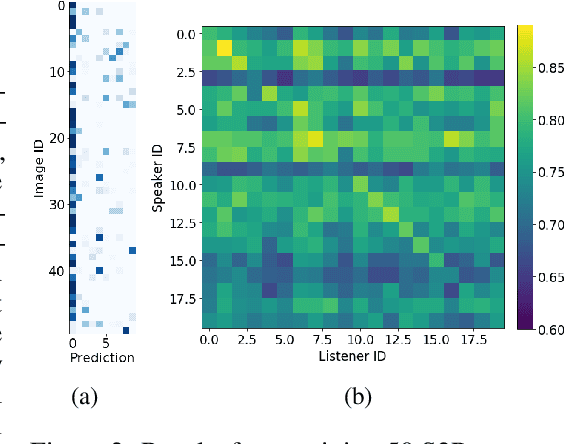
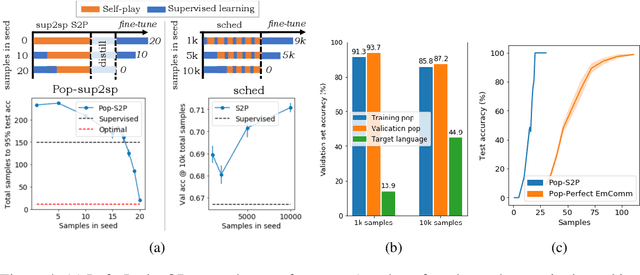
A promising approach for teaching artificial agents to use natural language involves using human-in-the-loop training. However, recent work suggests that current machine learning methods are too data inefficient to be trained in this way from scratch. In this paper, we investigate the relationship between two categories of learning signals with the ultimate goal of improving sample efficiency: imitating human language data via supervised learning, and maximizing reward in a simulated multi-agent environment via self-play (as done in emergent communication), and introduce the term supervised self-play (S2P) for algorithms using both of these signals. We find that first training agents via supervised learning on human data followed by self-play outperforms the converse, suggesting that it is not beneficial to emerge languages from scratch. We then empirically investigate various S2P schedules that begin with supervised learning in two environments: a Lewis signaling game with symbolic inputs, and an image-based referential game with natural language descriptions. Lastly, we introduce population based approaches to S2P, which further improves the performance over single-agent methods.
Generating Interactive Worlds with Text
Dec 04, 2019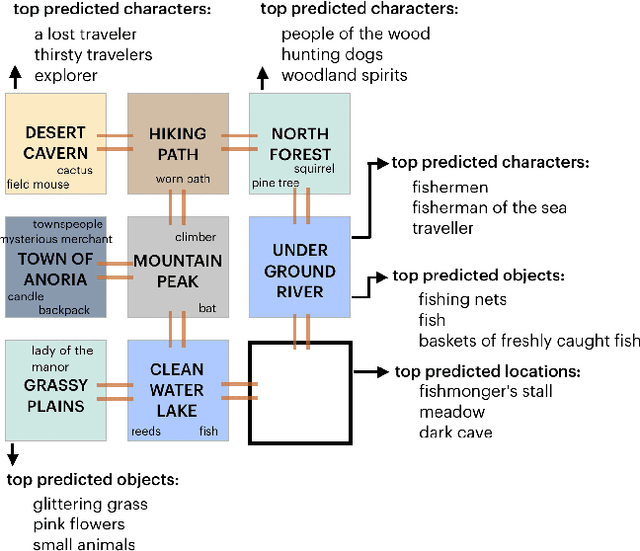
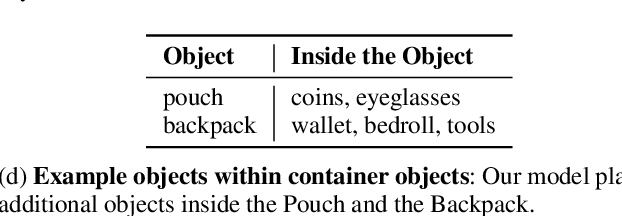
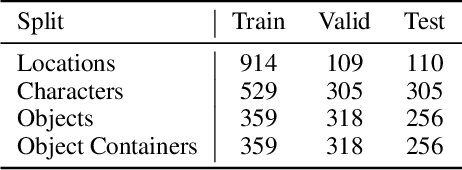
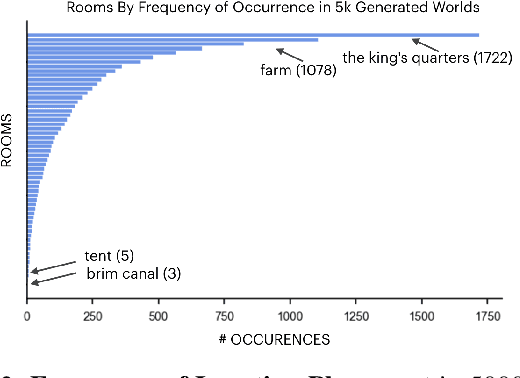
Procedurally generating cohesive and interesting game environments is challenging and time-consuming. In order for the relationships between the game elements to be natural, common-sense has to be encoded into arrangement of the elements. In this work, we investigate a machine learning approach for world creation using content from the multi-player text adventure game environment LIGHT. We introduce neural network based models to compositionally arrange locations, characters, and objects into a coherent whole. In addition to creating worlds based on existing elements, our models can generate new game content. Humans can also leverage our models to interactively aid in worldbuilding. We show that the game environments created with our approach are cohesive, diverse, and preferred by human evaluators compared to other machine learning based world construction algorithms.
Queens are Powerful too: Mitigating Gender Bias in Dialogue Generation
Nov 10, 2019
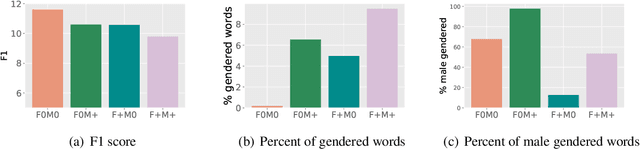
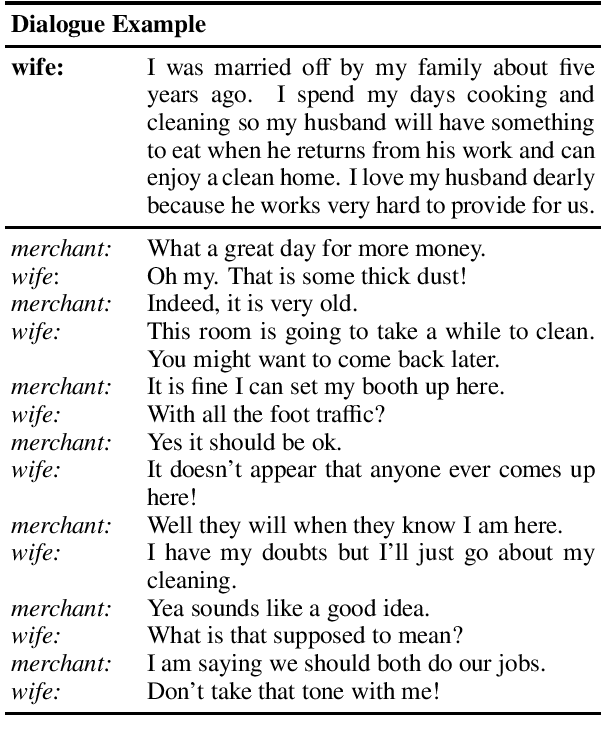
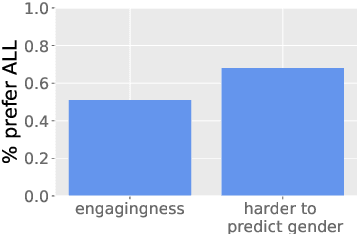
Models often easily learn biases present in the training data, and their predictions directly reflect this bias. We analyze the presence of gender bias in dialogue and examine the subsequent effect on generative chitchat dialogue models. Based on this analysis, we propose a combination of three techniques to mitigate bias: counterfactual data augmentation, targeted data collection, and conditional training. We focus on the multi-player text-based fantasy adventure dataset LIGHT as a testbed for our work. LIGHT contains gender imbalance between male and female characters with around 1.6 times as many male characters, likely because it is entirely collected by crowdworkers and reflects common biases that exist in fantasy or medieval settings. We show that (i) our proposed techniques mitigate gender bias by balancing the genderedness of generated dialogue utterances; and (ii) they work particularly well in combination. Further, we show through various metrics---such as quantity of gendered words, a dialogue safety classifier, and human evaluation---that our models generate less gendered, but still engaging chitchat responses.
Adversarial NLI: A New Benchmark for Natural Language Understanding
Oct 31, 2019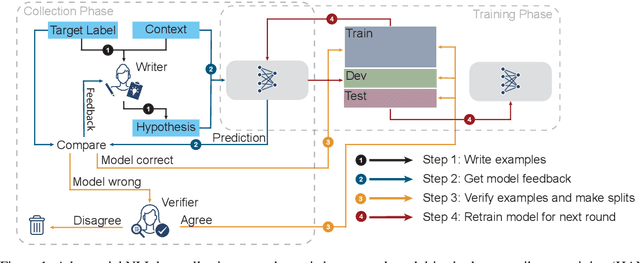
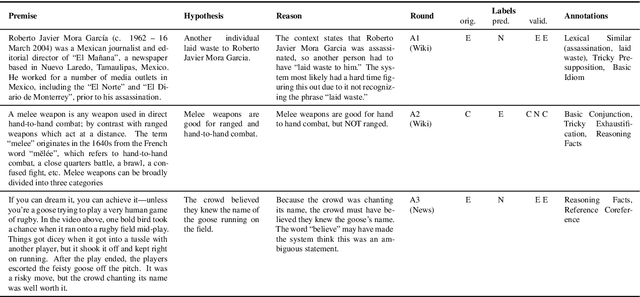
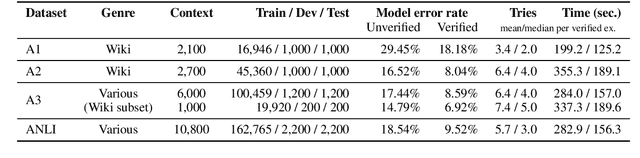
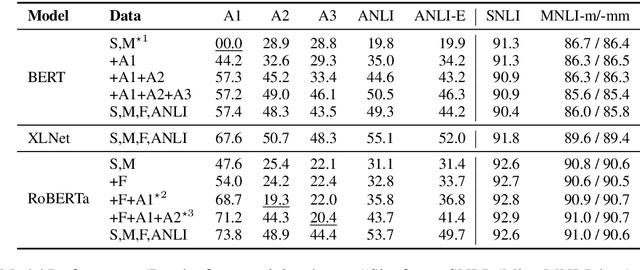
We introduce a new large-scale NLI benchmark dataset, collected via an iterative, adversarial human-and-model-in-the-loop procedure. We show that training models on this new dataset leads to state-of-the-art performance on a variety of popular NLI benchmarks, while posing a more difficult challenge with its new test set. Our analysis sheds light on the shortcomings of current state-of-the-art models, and shows that non-expert annotators are successful at finding their weaknesses. The data collection method can be applied in a never-ending learning scenario, becoming a moving target for NLU, rather than a static benchmark that will quickly saturate.
Hyperbolic Graph Neural Networks
Oct 28, 2019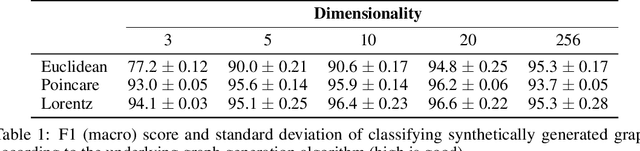
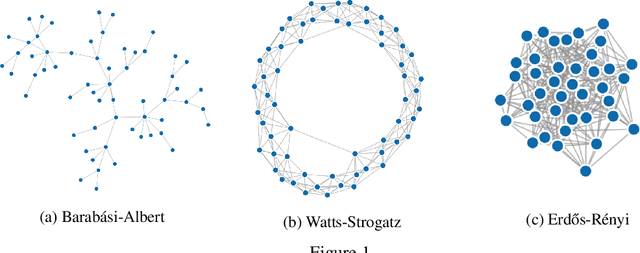
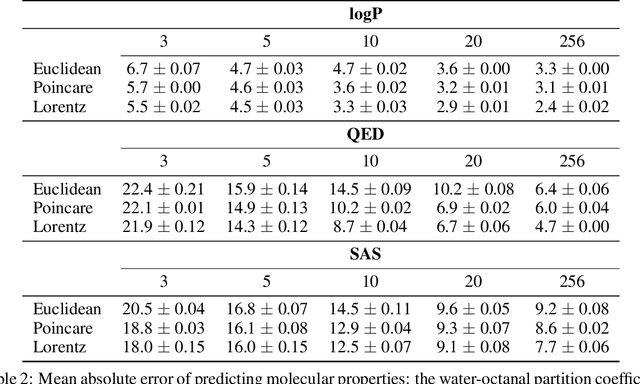
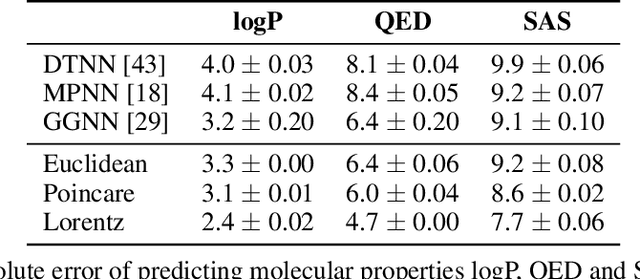
Learning from graph-structured data is an important task in machine learning and artificial intelligence, for which Graph Neural Networks (GNNs) have shown great promise. Motivated by recent advances in geometric representation learning, we propose a novel GNN architecture for learning representations on Riemannian manifolds with differentiable exponential and logarithmic maps. We develop a scalable algorithm for modeling the structural properties of graphs, comparing Euclidean and hyperbolic geometry. In our experiments, we show that hyperbolic GNNs can lead to substantial improvements on various benchmark datasets.