 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Exploration Methods in Reinforcement Learning
Sep 02, 2021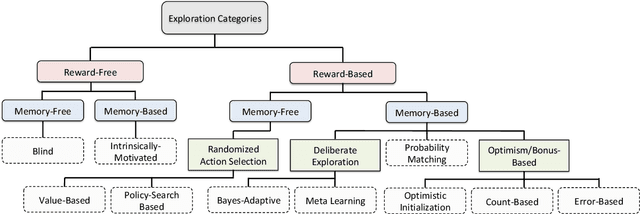
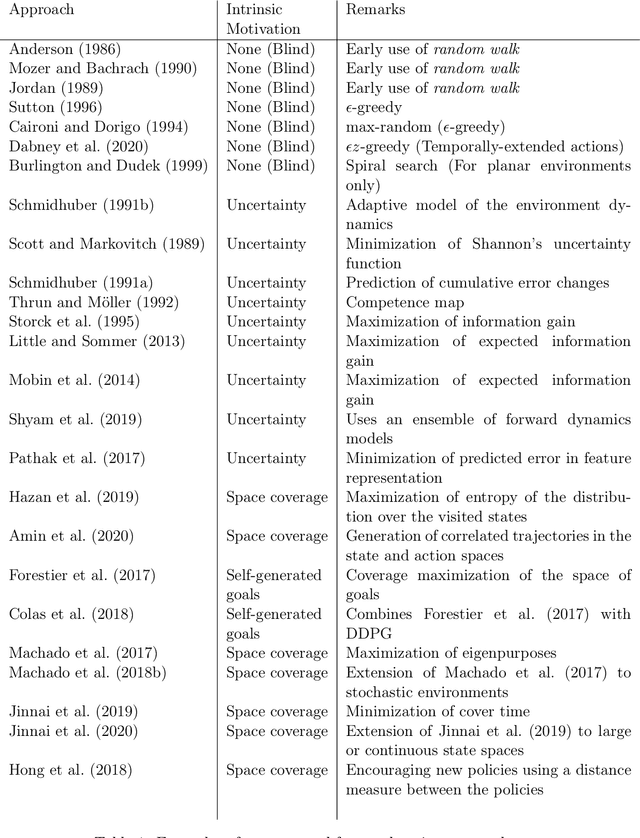
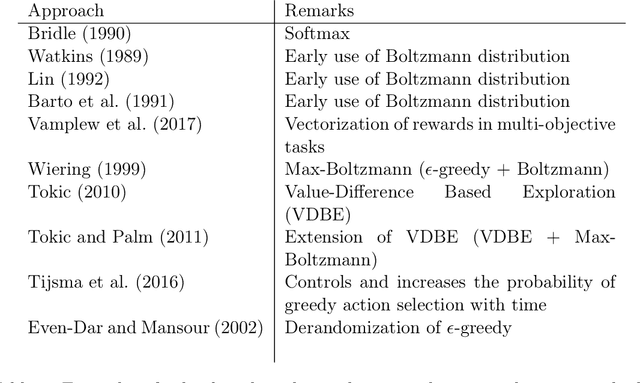
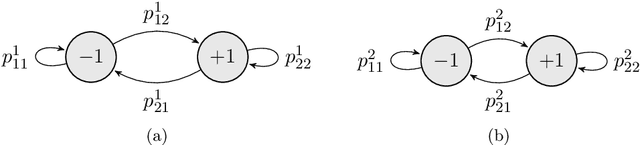
Exploration is an essential component of reinforcement learning algorithms, where agents need to learn how to predict and control unknown and often stochastic environments. Reinforcement learning agents depend crucially on exploration to obtain informative data for the learning process as the lack of enough information could hinder effective learning. In this article, we provide a survey of modern exploration methods in (Sequential) reinforcement learning, as well as a taxonomy of exploration methods.
Policy Gradients Incorporating the Future
Aug 11, 2021

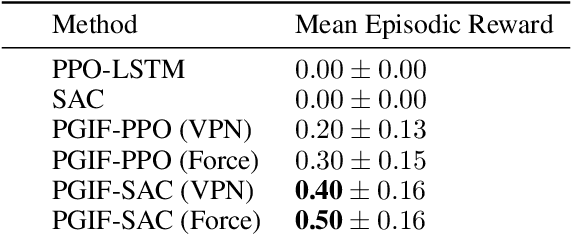

Reasoning about the future -- understanding how decisions in the present time affect outcomes in the future -- is one of the central challenges for reinforcement learning (RL), especially in highly-stochastic or partially observable environments. While predicting the future directly is hard, in this work we introduce a method that allows an agent to "look into the future" without explicitly predicting it. Namely, we propose to allow an agent, during its training on past experience, to observe what \emph{actually} happened in the future at that time, while enforcing an information bottleneck to avoid the agent overly relying on this privileged information. This gives our agent the opportunity to utilize rich and useful information about the future trajectory dynamics in addition to the present. Our method, Policy Gradients Incorporating the Future (PGIF), is easy to implement and versatile, being applicable to virtually any policy gradient algorithm. We apply our proposed method to a number of off-the-shelf RL algorithms and show that PGIF is able to achieve higher reward faster in a variety of online and offline RL domains, as well as sparse-reward and partially observable environments.
Temporally Abstract Partial Models
Aug 06, 2021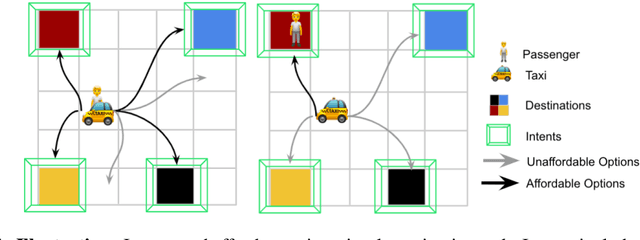


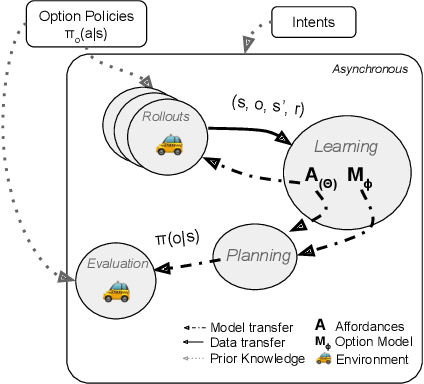
Humans and animals have the ability to reason and make predictions about different courses of action at many time scales. In reinforcement learning, option models (Sutton, Precup \& Singh, 1999; Precup, 2000) provide the framework for this kind of temporally abstract prediction and reasoning. Natural intelligent agents are also able to focus their attention on courses of action that are relevant or feasible in a given situation, sometimes termed affordable actions. In this paper, we define a notion of affordances for options, and develop temporally abstract partial option models, that take into account the fact that an option might be affordable only in certain situations. We analyze the trade-offs between estimation and approximation error in planning and learning when using such models, and identify some interesting special cases. Additionally, we demonstrate empirically the potential impact of partial option models on the efficiency of planning.
The Option Keyboard: Combining Skills in Reinforcement Learning
Jun 24, 2021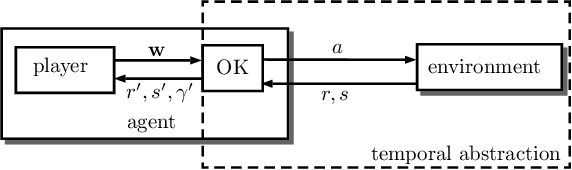
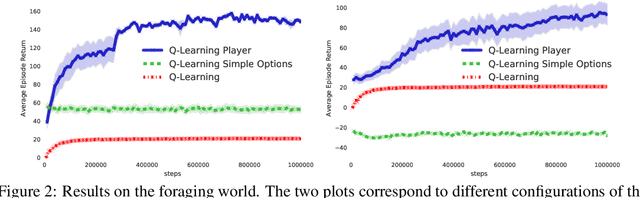
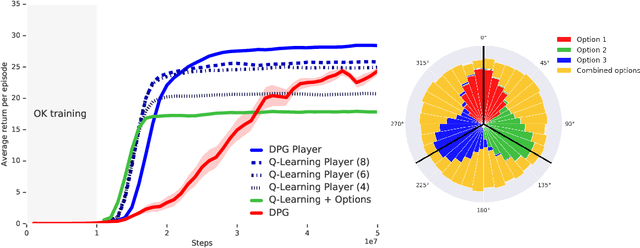
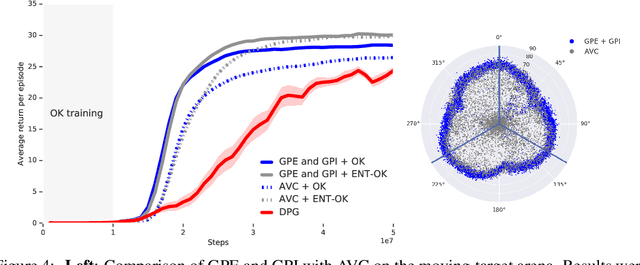
The ability to combine known skills to create new ones may be crucial in the solution of complex reinforcement learning problems that unfold over extended periods. We argue that a robust way of combining skills is to define and manipulate them in the space of pseudo-rewards (or "cumulants"). Based on this premise, we propose a framework for combining skills using the formalism of options. We show that every deterministic option can be unambiguously represented as a cumulant defined in an extended domain. Building on this insight and on previous results on transfer learning, we show how to approximate options whose cumulants are linear combinations of the cumulants of known options. This means that, once we have learned options associated with a set of cumulants, we can instantaneously synthesise options induced by any linear combination of them, without any learning involved. We describe how this framework provides a hierarchical interface to the environment whose abstract actions correspond to combinations of basic skills. We demonstrate the practical benefits of our approach in a resource management problem and a navigation task involving a quadrupedal simulated robot.
Randomized Exploration for Reinforcement Learning with General Value Function Approximation
Jun 15, 2021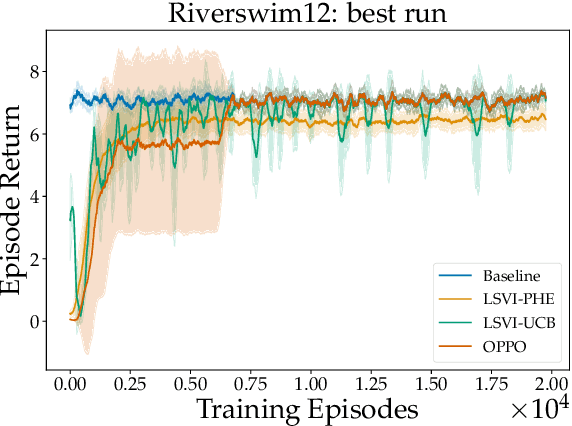
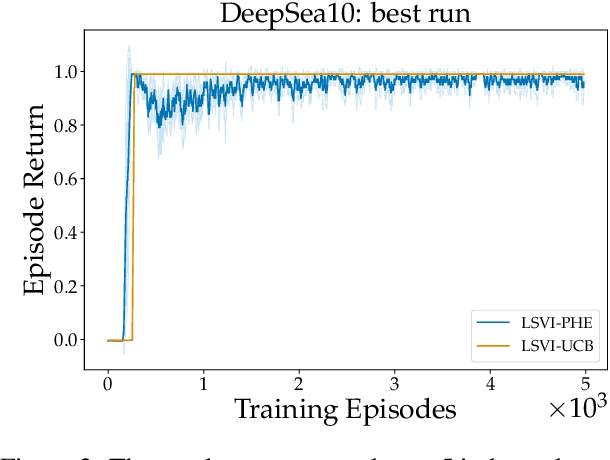
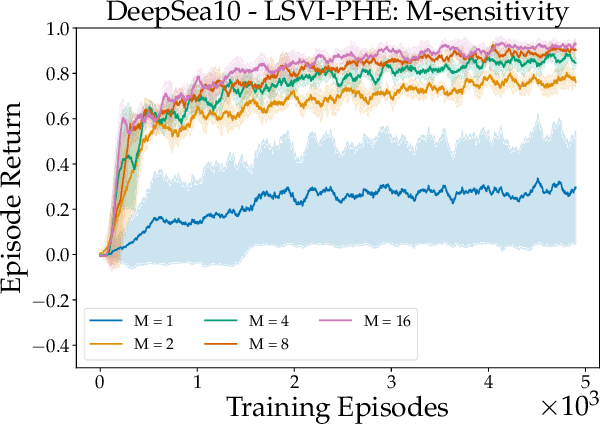
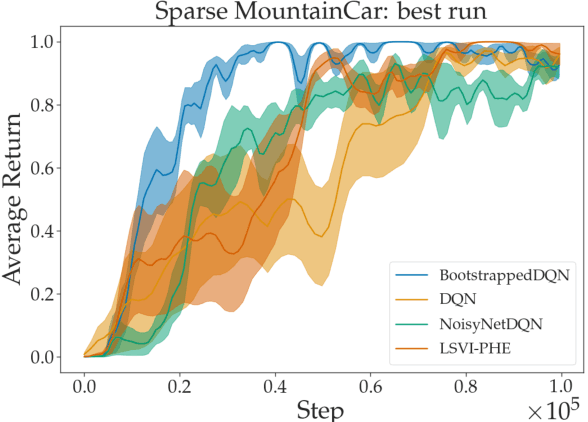
We propose a model-free reinforcement learning algorithm inspired by the popular randomized least squares value iteration (RLSVI) algorithm as well as the optimism principle. Unlike existing upper-confidence-bound (UCB) based approaches, which are often computationally intractable, our algorithm drives exploration by simply perturbing the training data with judiciously chosen i.i.d. scalar noises. To attain optimistic value function estimation without resorting to a UCB-style bonus, we introduce an optimistic reward sampling procedure. When the value functions can be represented by a function class $\mathcal{F}$, our algorithm achieves a worst-case regret bound of $\widetilde{O}(\mathrm{poly}(d_EH)\sqrt{T})$ where $T$ is the time elapsed, $H$ is the planning horizon and $d_E$ is the $\textit{eluder dimension}$ of $\mathcal{F}$. In the linear setting, our algorithm reduces to LSVI-PHE, a variant of RLSVI, that enjoys an $\widetilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret. We complement the theory with an empirical evaluation across known difficult exploration tasks.
A Deep Reinforcement Learning Approach to Marginalized Importance Sampling with the Successor Representation
Jun 12, 2021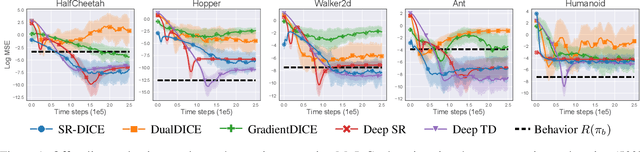
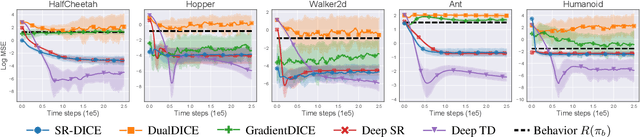
Marginalized importance sampling (MIS), which measures the density ratio between the state-action occupancy of a target policy and that of a sampling distribution, is a promising approach for off-policy evaluation. However, current state-of-the-art MIS methods rely on complex optimization tricks and succeed mostly on simple toy problems. We bridge the gap between MIS and deep reinforcement learning by observing that the density ratio can be computed from the successor representation of the target policy. The successor representation can be trained through deep reinforcement learning methodology and decouples the reward optimization from the dynamics of the environment, making the resulting algorithm stable and applicable to high-dimensional domains. We evaluate the empirical performance of our approach on a variety of challenging Atari and MuJoCo environments.
Preferential Temporal Difference Learning
Jun 11, 2021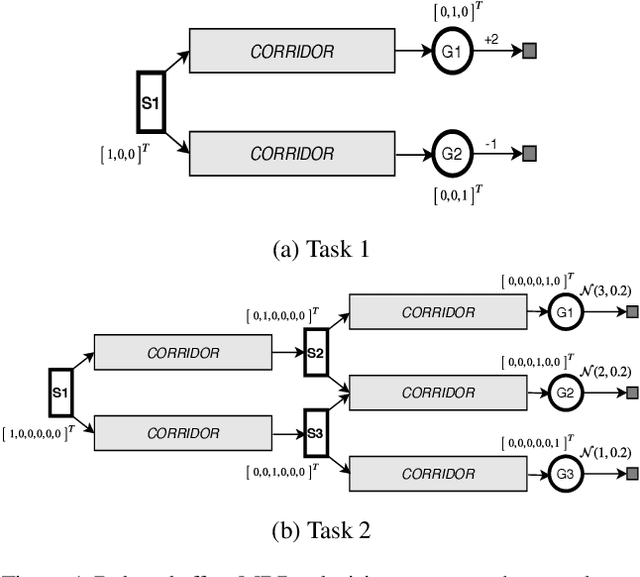
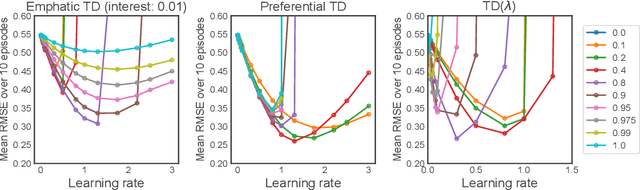
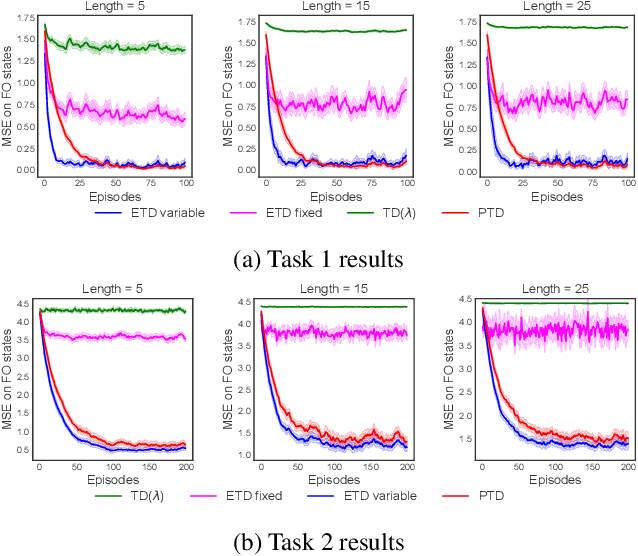

Temporal-Difference (TD) learning is a general and very useful tool for estimating the value function of a given policy, which in turn is required to find good policies. Generally speaking, TD learning updates states whenever they are visited. When the agent lands in a state, its value can be used to compute the TD-error, which is then propagated to other states. However, it may be interesting, when computing updates, to take into account other information than whether a state is visited or not. For example, some states might be more important than others (such as states which are frequently seen in a successful trajectory). Or, some states might have unreliable value estimates (for example, due to partial observability or lack of data), making their values less desirable as targets. We propose an approach to re-weighting states used in TD updates, both when they are the input and when they provide the target for the update. We prove that our approach converges with linear function approximation and illustrate its desirable empirical behaviour compared to other TD-style methods.
Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation
Jun 08, 2021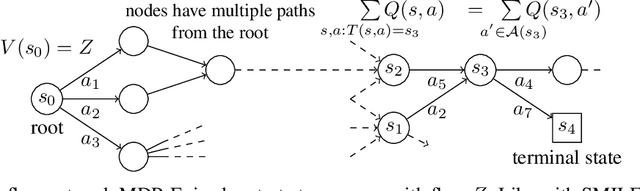
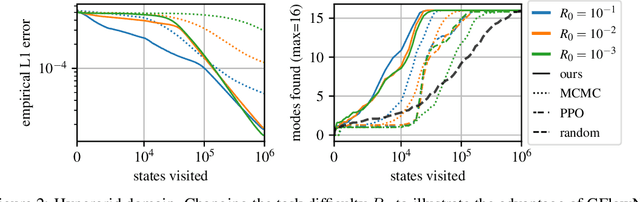
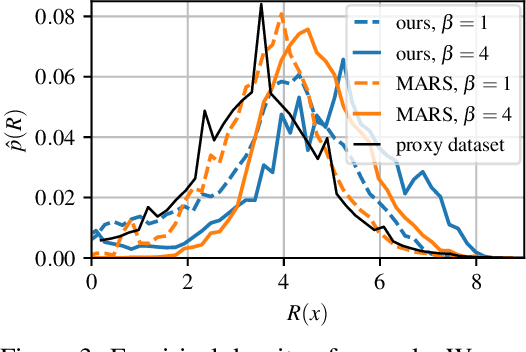
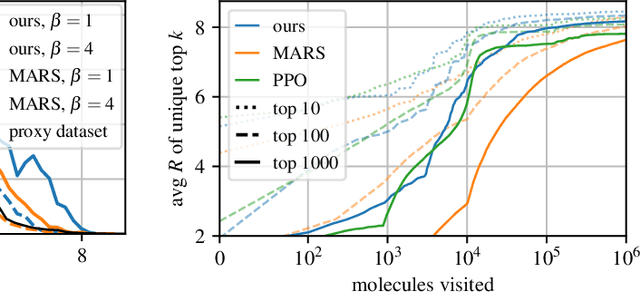
This paper is about the problem of learning a stochastic policy for generating an object (like a molecular graph) from a sequence of actions, such that the probability of generating an object is proportional to a given positive reward for that object. Whereas standard return maximization tends to converge to a single return-maximizing sequence, there are cases where we would like to sample a diverse set of high-return solutions. These arise, for example, in black-box function optimization when few rounds are possible, each with large batches of queries, where the batches should be diverse, e.g., in the design of new molecules. One can also see this as a problem of approximately converting an energy function to a generative distribution. While MCMC methods can achieve that, they are expensive and generally only perform local exploration. Instead, training a generative policy amortizes the cost of search during training and yields to fast generation. Using insights from Temporal Difference learning, we propose GFlowNet, based on a view of the generative process as a flow network, making it possible to handle the tricky case where different trajectories can yield the same final state, e.g., there are many ways to sequentially add atoms to generate some molecular graph. We cast the set of trajectories as a flow and convert the flow consistency equations into a learning objective, akin to the casting of the Bellman equations into Temporal Difference methods. We prove that any global minimum of the proposed objectives yields a policy which samples from the desired distribution, and demonstrate the improved performance and diversity of GFlowNet on a simple domain where there are many modes to the reward function, and on a molecule synthesis task.
Correcting Momentum in Temporal Difference Learning
Jun 07, 2021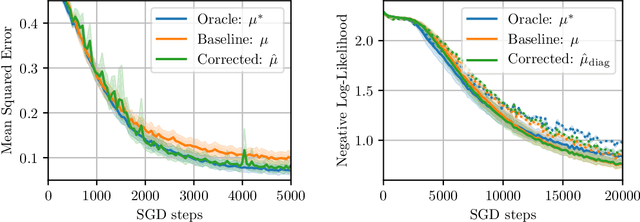
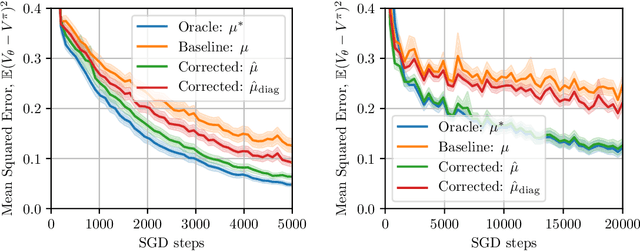
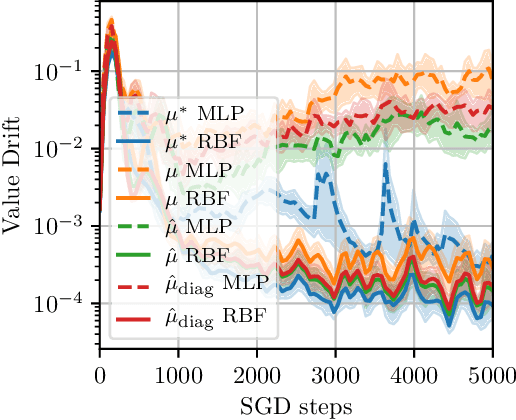
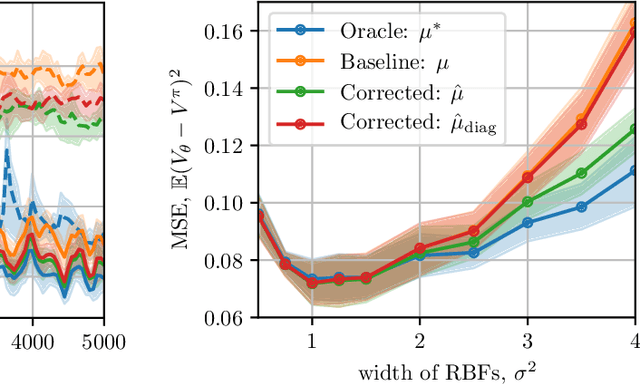
A common optimization tool used in deep reinforcement learning is momentum, which consists in accumulating and discounting past gradients, reapplying them at each iteration. We argue that, unlike in supervised learning, momentum in Temporal Difference (TD) learning accumulates gradients that become doubly stale: not only does the gradient of the loss change due to parameter updates, the loss itself changes due to bootstrapping. We first show that this phenomenon exists, and then propose a first-order correction term to momentum. We show that this correction term improves sample efficiency in policy evaluation by correcting target value drift. An important insight of this work is that deep RL methods are not always best served by directly importing techniques from the supervised setting.
A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning
Jun 03, 2021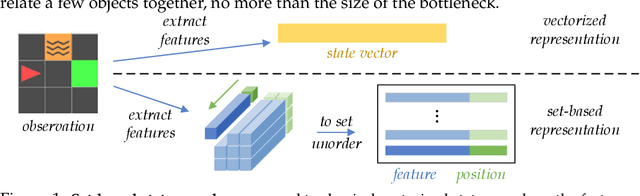
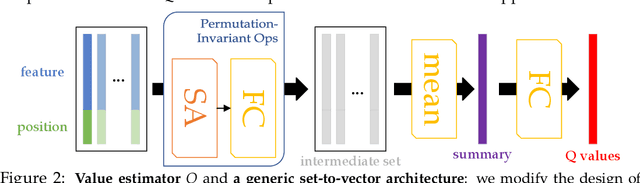
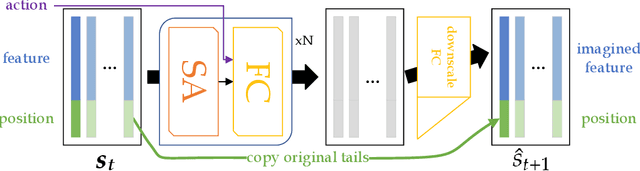
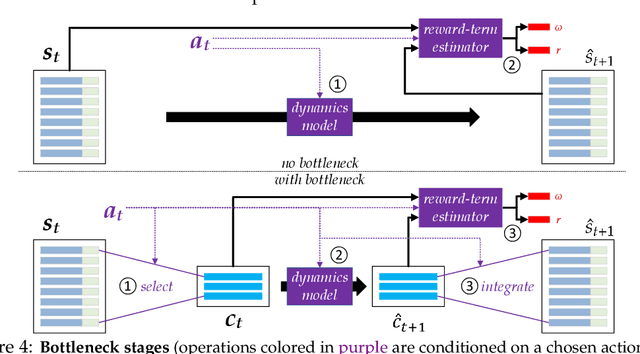
We present an end-to-end, model-based deep reinforcement learning agent which dynamically attends to relevant parts of its state, in order to plan and to generalize better out-of-distribution. The agent's architecture uses a set representation and a bottleneck mechanism, forcing the number of entities to which the agent attends at each planning step to be small. In experiments with customized MiniGrid environments with different dynamics, we observe that the design allows agents to learn to plan effectively, by attending to the relevant objects, leading to better out-of-distribution generalization.