 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniLabel: A Challenging Benchmark for Language-Based Object Detection
Apr 22, 2023



Language-based object detection is a promising direction towards building a natural interface to describe objects in images that goes far beyond plain category names. While recent methods show great progress in that direction, proper evaluation is lacking. With OmniLabel, we propose a novel task definition, dataset, and evaluation metric. The task subsumes standard- and open-vocabulary detection as well as referring expressions. With more than 28K unique object descriptions on over 25K images, OmniLabel provides a challenging benchmark with diverse and complex object descriptions in a naturally open-vocabulary setting. Moreover, a key differentiation to existing benchmarks is that our object descriptions can refer to one, multiple or even no object, hence, providing negative examples in free-form text. The proposed evaluation handles the large label space and judges performance via a modified average precision metric, which we validate by evaluating strong language-based baselines. OmniLabel indeed provides a challenging test bed for future research on language-based detection.
Constructive Assimilation: Boosting Contrastive Learning Performance through View Generation Strategies
Apr 08, 2023



Transformations based on domain expertise (expert transformations), such as random-resized-crop and color-jitter, have proven critical to the success of contrastive learning techniques such as SimCLR. Recently, several attempts have been made to replace such domain-specific, human-designed transformations with generated views that are learned. However for imagery data, so far none of these view-generation methods has been able to outperform expert transformations. In this work, we tackle a different question: instead of replacing expert transformations with generated views, can we constructively assimilate generated views with expert transformations? We answer this question in the affirmative and propose a view generation method and a simple, effective assimilation method that together improve the state-of-the-art by up to ~3.6% on three different datasets. Importantly, we conduct a detailed empirical study that systematically analyzes a range of view generation and assimilation methods and provides a holistic picture of the efficacy of learned views in contrastive representation learning.
SVDiff: Compact Parameter Space for Diffusion Fine-Tuning
Mar 22, 2023



Diffusion models have achieved remarkable success in text-to-image generation, enabling the creation of high-quality images from text prompts or other modalities. However, existing methods for customizing these models are limited by handling multiple personalized subjects and the risk of overfitting. Moreover, their large number of parameters is inefficient for model storage. In this paper, we propose a novel approach to address these limitations in existing text-to-image diffusion models for personalization. Our method involves fine-tuning the singular values of the weight matrices, leading to a compact and efficient parameter space that reduces the risk of overfitting and language-drifting. We also propose a Cut-Mix-Unmix data-augmentation technique to enhance the quality of multi-subject image generation and a simple text-based image editing framework. Our proposed SVDiff method has a significantly smaller model size (1.7MB for StableDiffusion) compared to existing methods (vanilla DreamBooth 3.66GB, Custom Diffusion 73MB), making it more practical for real-world applications.
Diffusion Guided Domain Adaptation of Image Generators
Dec 09, 2022Can a text-to-image diffusion model be used as a training objective for adapting a GAN generator to another domain? In this paper, we show that the classifier-free guidance can be leveraged as a critic and enable generators to distill knowledge from large-scale text-to-image diffusion models. Generators can be efficiently shifted into new domains indicated by text prompts without access to groundtruth samples from target domains. We demonstrate the effectiveness and controllability of our method through extensive experiments. Although not trained to minimize CLIP loss, our model achieves equally high CLIP scores and significantly lower FID than prior work on short prompts, and outperforms the baseline qualitatively and quantitatively on long and complicated prompts. To our best knowledge, the proposed method is the first attempt at incorporating large-scale pre-trained diffusion models and distillation sampling for text-driven image generator domain adaptation and gives a quality previously beyond possible. Moreover, we extend our work to 3D-aware style-based generators and DreamBooth guidance.
SINE: SINgle Image Editing with Text-to-Image Diffusion Models
Dec 08, 2022



Recent works on diffusion models have demonstrated a strong capability for conditioning image generation, e.g., text-guided image synthesis. Such success inspires many efforts trying to use large-scale pre-trained diffusion models for tackling a challenging problem--real image editing. Works conducted in this area learn a unique textual token corresponding to several images containing the same object. However, under many circumstances, only one image is available, such as the painting of the Girl with a Pearl Earring. Using existing works on fine-tuning the pre-trained diffusion models with a single image causes severe overfitting issues. The information leakage from the pre-trained diffusion models makes editing can not keep the same content as the given image while creating new features depicted by the language guidance. This work aims to address the problem of single-image editing. We propose a novel model-based guidance built upon the classifier-free guidance so that the knowledge from the model trained on a single image can be distilled into the pre-trained diffusion model, enabling content creation even with one given image. Additionally, we propose a patch-based fine-tuning that can effectively help the model generate images of arbitrary resolution. We provide extensive experiments to validate the design choices of our approach and show promising editing capabilities, including changing style, content addition, and object manipulation. The code is available for research purposes at https://github.com/zhang-zx/SINE.git .
Automatic Tooth Segmentation from 3D Dental Model using Deep Learning: A Quantitative Analysis of what can be learnt from a Single 3D Dental Model
Sep 16, 2022

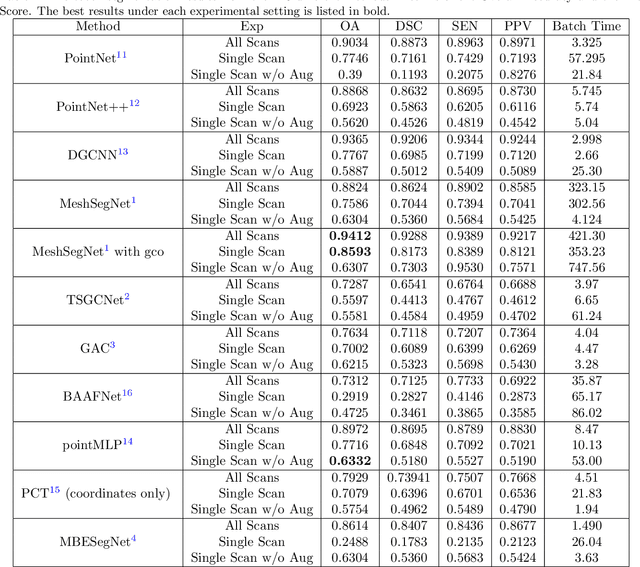
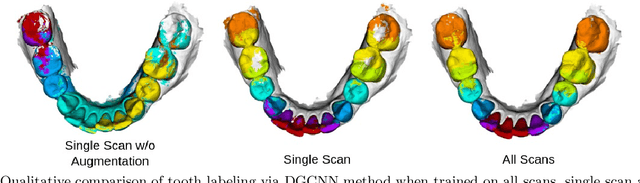
3D tooth segmentation is an important task for digital orthodontics. Several Deep Learning methods have been proposed for automatic tooth segmentation from 3D dental models or intraoral scans. These methods require annotated 3D intraoral scans. Manually annotating 3D intraoral scans is a laborious task. One approach is to devise self-supervision methods to reduce the manual labeling effort. Compared to other types of point cloud data like scene point cloud or shape point cloud data, 3D tooth point cloud data has a very regular structure and a strong shape prior. We look at how much representative information can be learnt from a single 3D intraoral scan. We evaluate this quantitatively with the help of ten different methods of which six are generic point cloud segmentation methods whereas the other four are tooth segmentation specific methods. Surprisingly, we find that with a single 3D intraoral scan training, the Dice score can be as high as 0.86 whereas the full training set gives Dice score of 0.94. We conclude that the segmentation methods can learn a great deal of information from a single 3D tooth point cloud scan under suitable conditions e.g. data augmentation. We are the first to quantitatively evaluate and demonstrate the representation learning capability of Deep Learning methods from a single 3D intraoral scan. This can enable building self-supervision methods for tooth segmentation under extreme data limitation scenario by leveraging the available data to the fullest possible extent.
Exploiting Unlabeled Data with Vision and Language Models for Object Detection
Jul 18, 2022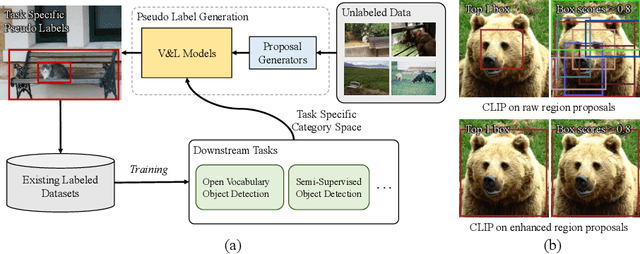
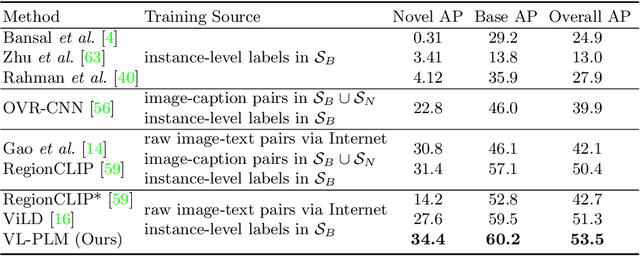
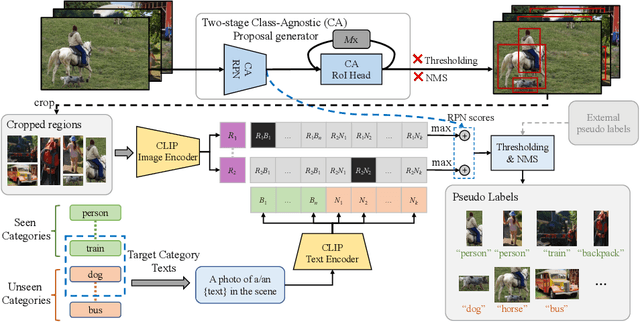

Building robust and generic object detection frameworks requires scaling to larger label spaces and bigger training datasets. However, it is prohibitively costly to acquire annotations for thousands of categories at a large scale. We propose a novel method that leverages the rich semantics available in recent vision and language models to localize and classify objects in unlabeled images, effectively generating pseudo labels for object detection. Starting with a generic and class-agnostic region proposal mechanism, we use vision and language models to categorize each region of an image into any object category that is required for downstream tasks. We demonstrate the value of the generated pseudo labels in two specific tasks, open-vocabulary detection, where a model needs to generalize to unseen object categories, and semi-supervised object detection, where additional unlabeled images can be used to improve the model. Our empirical evaluation shows the effectiveness of the pseudo labels in both tasks, where we outperform competitive baselines and achieve a novel state-of-the-art for open-vocabulary object detection. Our code is available at https://github.com/xiaofeng94/VL-PLM.
A Dynamic Data Driven Approach for Explainable Scene Understanding
Jun 18, 2022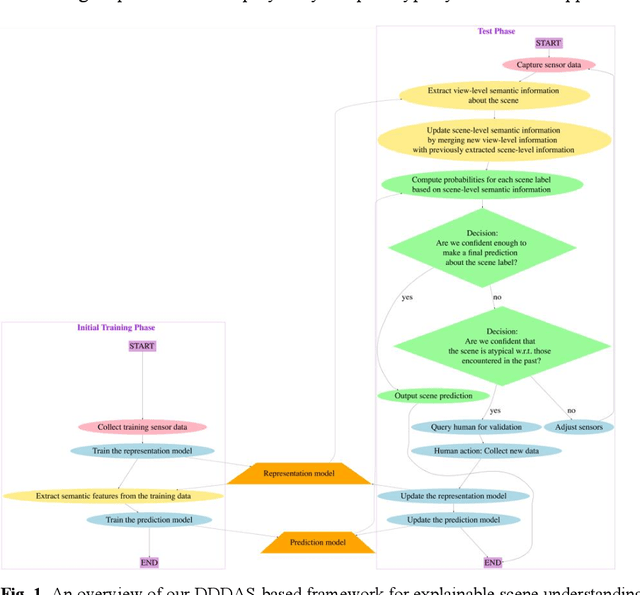

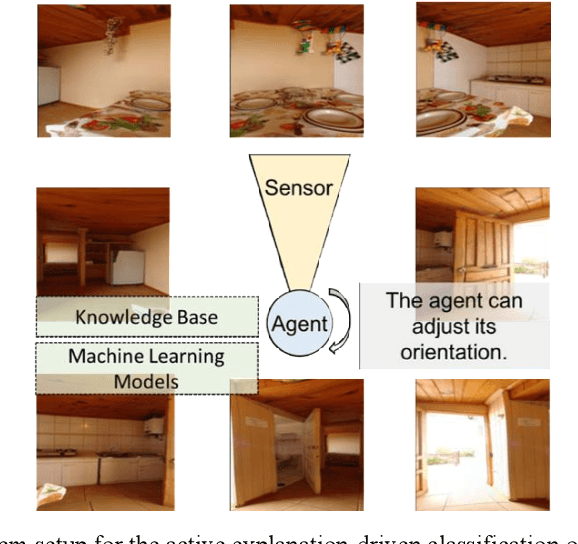
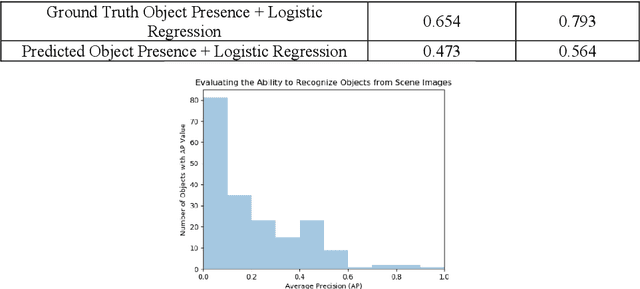
Scene-understanding is an important topic in the area of Computer Vision, and illustrates computational challenges with applications to a wide range of domains including remote sensing, surveillance, smart agriculture, robotics, autonomous driving, and smart cities. We consider the active explanation-driven understanding and classification of scenes. Suppose that an agent utilizing one or more sensors is placed in an unknown environment, and based on its sensory input, the agent needs to assign some label to the perceived scene. The agent can adjust its sensor(s) to capture additional details about the scene, but there is a cost associated with sensor manipulation, and as such, it is important for the agent to understand the scene in a fast and efficient manner. It is also important that the agent understand not only the global state of a scene (e.g., the category of the scene or the major events taking place in the scene) but also the characteristics/properties of the scene that support decisions and predictions made about the global state of the scene. Finally, when the agent encounters an unknown scene category, it must be capable of refusing to assign a label to the scene, requesting aid from a human, and updating its underlying knowledge base and machine learning models based on feedback provided by the human. We introduce a dynamic data driven framework for the active explanation-driven classification of scenes. Our framework is entitled ACUMEN: Active Classification and Understanding Method by Explanation-driven Networks. To demonstrate the utility of the proposed ACUMEN approach and show how it can be adapted to a domain-specific application, we focus on an example case study involving the classification of indoor scenes using an active robotic agent with vision-based sensors, i.e., an electro-optical camera.
DeepRecon: Joint 2D Cardiac Segmentation and 3D Volume Reconstruction via A Structure-Specific Generative Method
Jun 14, 2022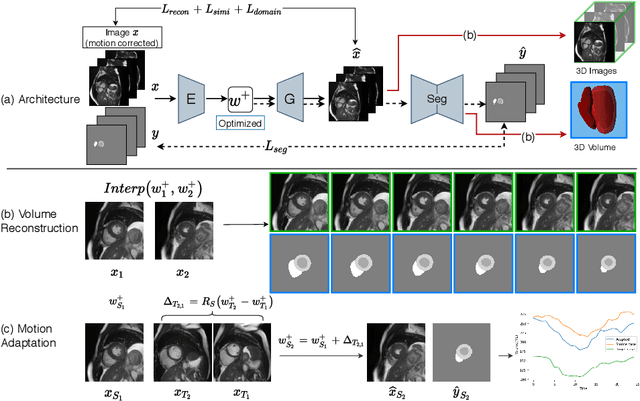
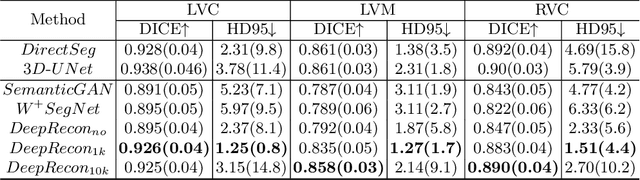
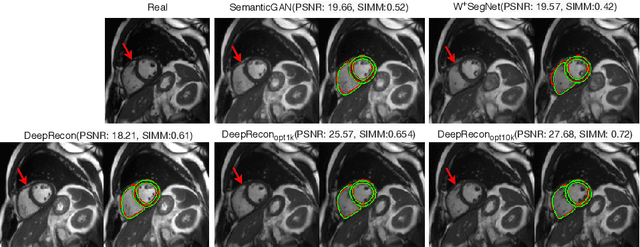
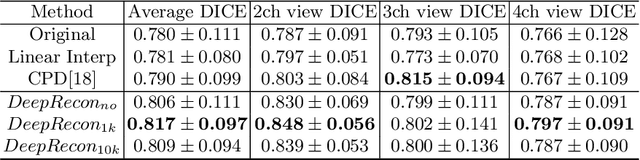
Joint 2D cardiac segmentation and 3D volume reconstruction are fundamental to building statistical cardiac anatomy models and understanding functional mechanisms from motion patterns. However, due to the low through-plane resolution of cine MR and high inter-subject variance, accurately segmenting cardiac images and reconstructing the 3D volume are challenging. In this study, we propose an end-to-end latent-space-based framework, DeepRecon, that generates multiple clinically essential outcomes, including accurate image segmentation, synthetic high-resolution 3D image, and 3D reconstructed volume. Our method identifies the optimal latent representation of the cine image that contains accurate semantic information for cardiac structures. In particular, our model jointly generates synthetic images with accurate semantic information and segmentation of the cardiac structures using the optimal latent representation. We further explore downstream applications of 3D shape reconstruction and 4D motion pattern adaptation by the different latent-space manipulation strategies.The simultaneously generated high-resolution images present a high interpretable value to assess the cardiac shape and motion.Experimental results demonstrate the effectiveness of our approach on multiple fronts including 2D segmentation, 3D reconstruction, downstream 4D motion pattern adaption performance.
A Manifold View of Adversarial Risk
Apr 08, 2022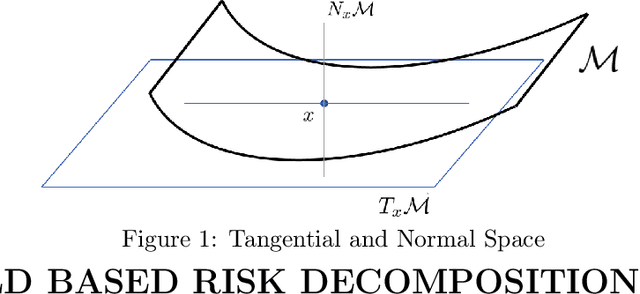
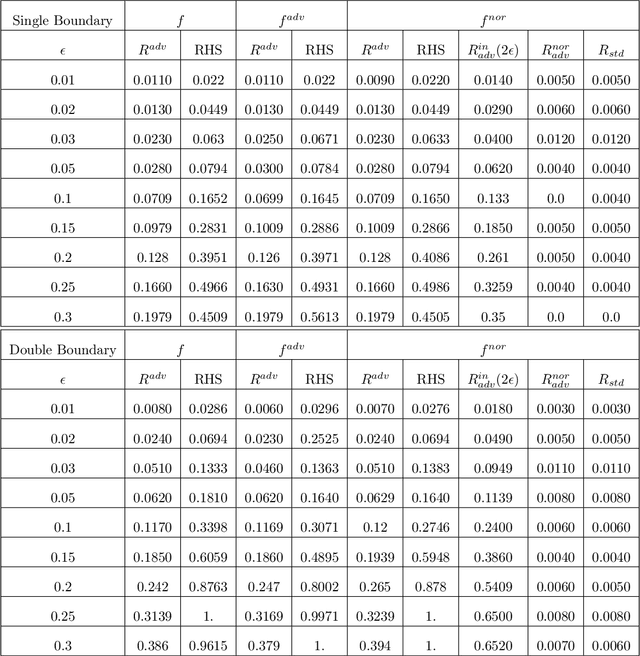
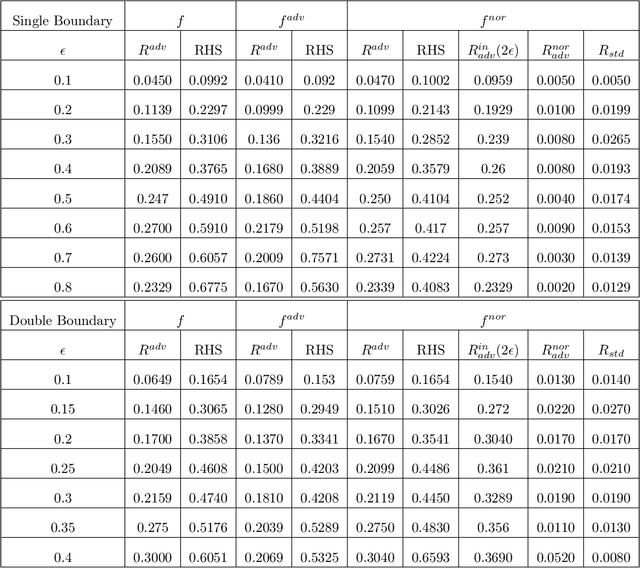
The adversarial risk of a machine learning model has been widely studied. Most previous works assume that the data lies in the whole ambient space. We propose to take a new angle and take the manifold assumption into consideration. Assuming data lies in a manifold, we investigate two new types of adversarial risk, the normal adversarial risk due to perturbation along normal direction, and the in-manifold adversarial risk due to perturbation within the manifold. We prove that the classic adversarial risk can be bounded from both sides using the normal and in-manifold adversarial risks. We also show with a surprisingly pessimistic case that the standard adversarial risk can be nonzero even when both normal and in-manifold risks are zero. We finalize the paper with empirical studies supporting our theoretical results. Our results suggest the possibility of improving the robustness of a classifier by only focusing on the normal adversarial risk.