 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Corrected Flow Distillation for Consistent One-Step and Few-Step Text-to-Image Generation
Dec 22, 2024



Flow matching has emerged as a promising framework for training generative models, demonstrating impressive empirical performance while offering relative ease of training compared to diffusion-based models. However, this method still requires numerous function evaluations in the sampling process. To address these limitations, we introduce a self-corrected flow distillation method that effectively integrates consistency models and adversarial training within the flow-matching framework. This work is a pioneer in achieving consistent generation quality in both few-step and one-step sampling. Our extensive experiments validate the effectiveness of our method, yielding superior results both quantitatively and qualitatively on CelebA-HQ and zero-shot benchmarks on the COCO dataset. Our implementation is released at https://github.com/VinAIResearch/SCFlow
VerSe: Integrating Multiple Queries as Prompts for Versatile Cardiac MRI Segmentation
Dec 20, 2024Despite the advances in learning-based image segmentation approach, the accurate segmentation of cardiac structures from magnetic resonance imaging (MRI) remains a critical challenge. While existing automatic segmentation methods have shown promise, they still require extensive manual corrections of the segmentation results by human experts, particularly in complex regions such as the basal and apical parts of the heart. Recent efforts have been made on developing interactive image segmentation methods that enable human-in-the-loop learning. However, they are semi-automatic and inefficient, due to their reliance on click-based prompts, especially for 3D cardiac MRI volumes. To address these limitations, we propose VerSe, a Versatile Segmentation framework to unify automatic and interactive segmentation through mutiple queries. Our key innovation lies in the joint learning of object and click queries as prompts for a shared segmentation backbone. VerSe supports both fully automatic segmentation, through object queries, and interactive mask refinement, by providing click queries when needed. With the proposed integrated prompting scheme, VerSe demonstrates significant improvement in performance and efficiency over existing methods, on both cardiac MRI and out-of-distribution medical imaging datasets. The code is available at https://github.com/bangwayne/Verse.
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024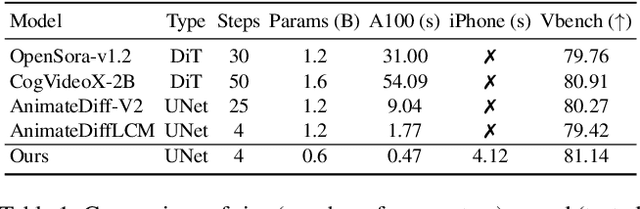
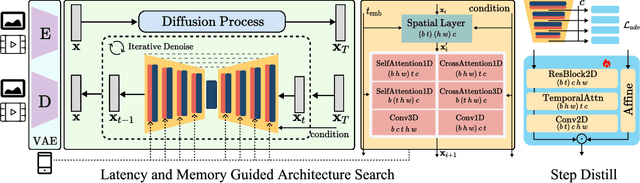
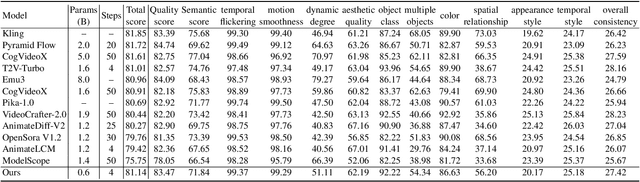
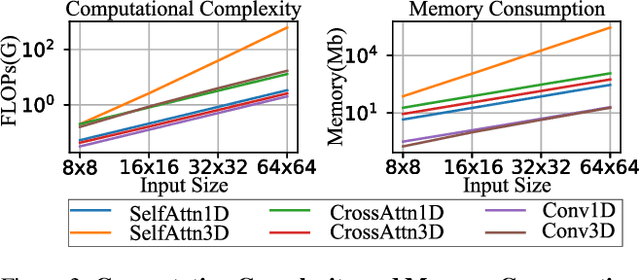
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
Learning Volumetric Neural Deformable Models to Recover 3D Regional Heart Wall Motion from Multi-Planar Tagged MRI
Nov 21, 2024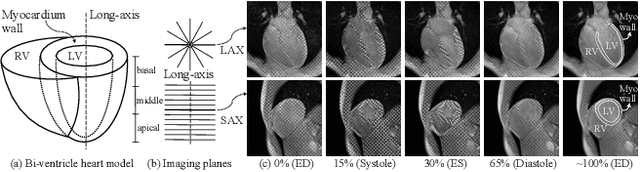
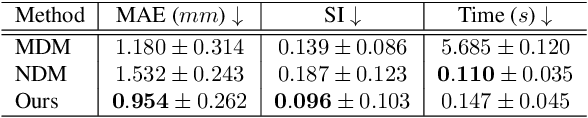
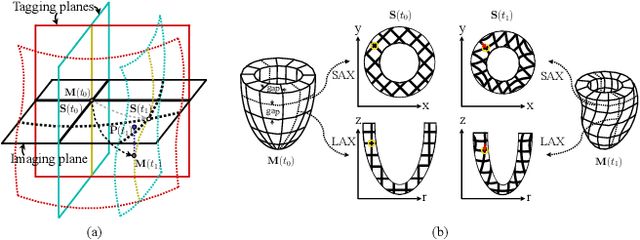
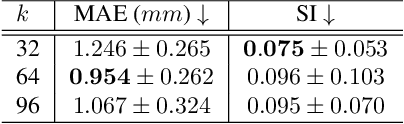
Multi-planar tagged MRI is the gold standard for regional heart wall motion evaluation. However, accurate recovery of the 3D true heart wall motion from a set of 2D apparent motion cues is challenging, due to incomplete sampling of the true motion and difficulty in information fusion from apparent motion cues observed on multiple imaging planes. To solve these challenges, we introduce a novel class of volumetric neural deformable models ($\upsilon$NDMs). Our $\upsilon$NDMs represent heart wall geometry and motion through a set of low-dimensional global deformation parameter functions and a diffeomorphic point flow regularized local deformation field. To learn such global and local deformation for 2D apparent motion mapping to 3D true motion, we design a hybrid point transformer, which incorporates both point cross-attention and self-attention mechanisms. While use of point cross-attention can learn to fuse 2D apparent motion cues into material point true motion hints, point self-attention hierarchically organised as an encoder-decoder structure can further learn to refine these hints and map them into 3D true motion. We have performed experiments on a large cohort of synthetic 3D regional heart wall motion dataset. The results demonstrated the high accuracy of our method for the recovery of dense 3D true motion from sparse 2D apparent motion cues. Project page is at https://github.com/DeepTag/VolumetricNeuralDeformableModels.
DiMSUM: Diffusion Mamba -- A Scalable and Unified Spatial-Frequency Method for Image Generation
Nov 06, 2024



We introduce a novel state-space architecture for diffusion models, effectively harnessing spatial and frequency information to enhance the inductive bias towards local features in input images for image generation tasks. While state-space networks, including Mamba, a revolutionary advancement in recurrent neural networks, typically scan input sequences from left to right, they face difficulties in designing effective scanning strategies, especially in the processing of image data. Our method demonstrates that integrating wavelet transformation into Mamba enhances the local structure awareness of visual inputs and better captures long-range relations of frequencies by disentangling them into wavelet subbands, representing both low- and high-frequency components. These wavelet-based outputs are then processed and seamlessly fused with the original Mamba outputs through a cross-attention fusion layer, combining both spatial and frequency information to optimize the order awareness of state-space models which is essential for the details and overall quality of image generation. Besides, we introduce a globally-shared transformer to supercharge the performance of Mamba, harnessing its exceptional power to capture global relationships. Through extensive experiments on standard benchmarks, our method demonstrates superior results compared to DiT and DIFFUSSM, achieving faster training convergence and delivering high-quality outputs. The codes and pretrained models are released at https://github.com/VinAIResearch/DiMSUM.git.
Continuous Spatio-Temporal Memory Networks for 4D Cardiac Cine MRI Segmentation
Oct 30, 2024



Current cardiac cine magnetic resonance image (cMR) studies focus on the end diastole (ED) and end systole (ES) phases, while ignoring the abundant temporal information in the whole image sequence. This is because whole sequence segmentation is currently a tedious process and inaccurate. Conventional whole sequence segmentation approaches first estimate the motion field between frames, which is then used to propagate the mask along the temporal axis. However, the mask propagation results could be prone to error, especially for the basal and apex slices, where through-plane motion leads to significant morphology and structural change during the cardiac cycle. Inspired by recent advances in video object segmentation (VOS), based on spatio-temporal memory (STM) networks, we propose a continuous STM (CSTM) network for semi-supervised whole heart and whole sequence cMR segmentation. Our CSTM network takes full advantage of the spatial, scale, temporal and through-plane continuity prior of the underlying heart anatomy structures, to achieve accurate and fast 4D segmentation. Results of extensive experiments across multiple cMR datasets show that our method can improve the 4D cMR segmentation performance, especially for the hard-to-segment regions.
DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
Oct 10, 2024Discrete diffusion models have achieved success in tasks like image generation and masked language modeling but face limitations in controlled content editing. We introduce DICE (Discrete Inversion for Controllable Editing), the first approach to enable precise inversion for discrete diffusion models, including multinomial diffusion and masked generative models. By recording noise sequences and masking patterns during the reverse diffusion process, DICE enables accurate reconstruction and flexible editing of discrete data without the need for predefined masks or attention manipulation. We demonstrate the effectiveness of DICE across both image and text domains, evaluating it on models such as VQ-Diffusion, Paella, and RoBERTa. Our results show that DICE preserves high data fidelity while enhancing editing capabilities, offering new opportunities for fine-grained content manipulation in discrete spaces. For project webpage, see https://hexiaoxiao-cs.github.io/DICE/.
Resolving Inconsistent Semantics in Multi-Dataset Image Segmentation
Sep 15, 2024Leveraging multiple training datasets to scale up image segmentation models is beneficial for increasing robustness and semantic understanding. Individual datasets have well-defined ground truth with non-overlapping mask layouts and mutually exclusive semantics. However, merging them for multi-dataset training disrupts this harmony and leads to semantic inconsistencies; for example, the class "person" in one dataset and class "face" in another will require multilabel handling for certain pixels. Existing methods struggle with this setting, particularly when evaluated on label spaces mixed from the individual training sets. To overcome these issues, we introduce a simple yet effective multi-dataset training approach by integrating language-based embeddings of class names and label space-specific query embeddings. Our method maintains high performance regardless of the underlying inconsistencies between training datasets. Notably, on four benchmark datasets with label space inconsistencies during inference, we outperform previous methods by 1.6% mIoU for semantic segmentation, 9.1% PQ for panoptic segmentation, 12.1% AP for instance segmentation, and 3.0% in the newly proposed PIQ metric.
New Capability to Look Up an ASL Sign from a Video Example
Jul 18, 2024



Looking up an unknown sign in an ASL dictionary can be difficult. Most ASL dictionaries are organized based on English glosses, despite the fact that (1) there is no convention for assigning English-based glosses to ASL signs; and (2) there is no 1-1 correspondence between ASL signs and English words. Furthermore, what if the user does not know either the meaning of the target sign or its possible English translation(s)? Some ASL dictionaries enable searching through specification of articulatory properties, such as handshapes, locations, movement properties, etc. However, this is a cumbersome process and does not always result in successful lookup. Here we describe a new system, publicly shared on the Web, to enable lookup of a video of an ASL sign (e.g., a webcam recording or a clip from a continuous signing video). The user submits a video for analysis and is presented with the five most likely sign matches, in decreasing order of likelihood, so that the user can confirm the selection and then be taken to our ASLLRP Sign Bank entry for that sign. Furthermore, this video lookup is also integrated into our newest version of SignStream(R) software to facilitate linguistic annotation of ASL video data, enabling the user to directly look up a sign in the video being annotated, and, upon confirmation of the match, to directly enter into the annotation the gloss and features of that sign, greatly increasing the efficiency and consistency of linguistic annotations of ASL video data.
BLoB: Bayesian Low-Rank Adaptation by Backpropagation for Large Language Models
Jun 18, 2024



Large Language Models (LLMs) often suffer from overconfidence during inference, particularly when adapted to downstream domain-specific tasks with limited data. Previous work addresses this issue by employing approximate Bayesian estimation after the LLMs are trained, enabling them to quantify uncertainty. However, such post-training approaches' performance is severely limited by the parameters learned during training. In this paper, we go beyond post-training Bayesianization and propose Bayesian Low-Rank Adaptation by Backpropagation (BLoB), an algorithm that continuously and jointly adjusts both the mean and covariance of LLM parameters throughout the whole fine-tuning process. Our empirical results verify the effectiveness of BLoB in terms of generalization and uncertainty estimation, when evaluated on both in-distribution and out-of-distribution data.