 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Limits of Self-Supervision in Handling Bias in Language
Dec 16, 2021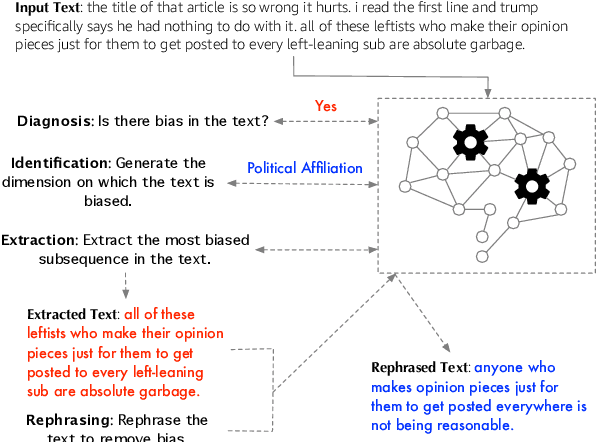



Prompting inputs with natural language task descriptions has emerged as a popular mechanism to elicit reasonably accurate outputs from large-scale generative language models with little to no in-context supervision. This also helps gain insight into how well language models capture the semantics of a wide range of downstream tasks purely from self-supervised pre-training on massive corpora of unlabeled text. Such models have naturally also been exposed to a lot of undesirable content like racist and sexist language and there is limited work on awareness of models along these dimensions. In this paper, we define and comprehensively evaluate how well such language models capture the semantics of four tasks for bias: diagnosis, identification, extraction and rephrasing. We define three broad classes of task descriptions for these tasks: statement, question, and completion, with numerous lexical variants within each class. We study the efficacy of prompting for each task using these classes and the null task description across several decoding methods and few-shot examples. Our analyses indicate that language models are capable of performing these tasks to widely varying degrees across different bias dimensions, such as gender and political affiliation. We believe our work is an important step towards unbiased language models by quantifying the limits of current self-supervision objectives at accomplishing such sociologically challenging tasks.
Sketching as a Tool for Understanding and Accelerating Self-attention for Long Sequences
Dec 10, 2021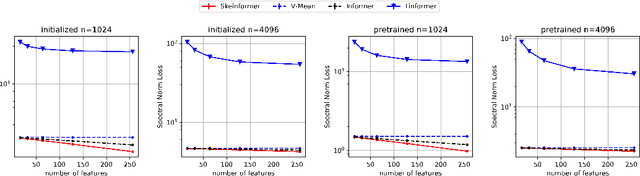
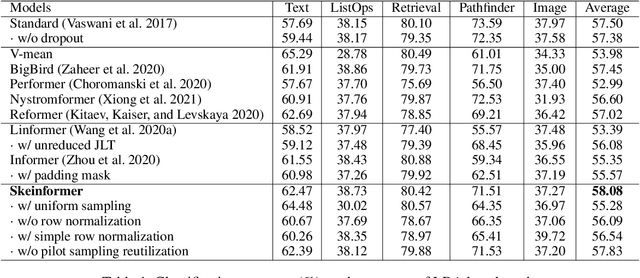
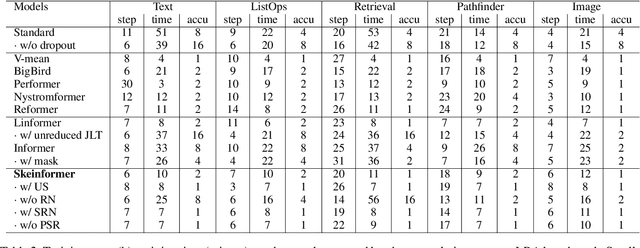

Transformer-based models are not efficient in processing long sequences due to the quadratic space and time complexity of the self-attention modules. To address this limitation, Linformer and Informer are proposed to reduce the quadratic complexity to linear (modulo logarithmic factors) via low-dimensional projection and row selection respectively. These two models are intrinsically connected, and to understand their connection, we introduce a theoretical framework of matrix sketching. Based on the theoretical analysis, we propose Skeinformer to accelerate self-attention and further improve the accuracy of matrix approximation to self-attention with three carefully designed components: column sampling, adaptive row normalization and pilot sampling reutilization. Experiments on the Long Range Arena (LRA) benchmark demonstrate that our methods outperform alternatives with a consistently smaller time/space footprint.
User Response and Sentiment Prediction for Automatic Dialogue Evaluation
Nov 16, 2021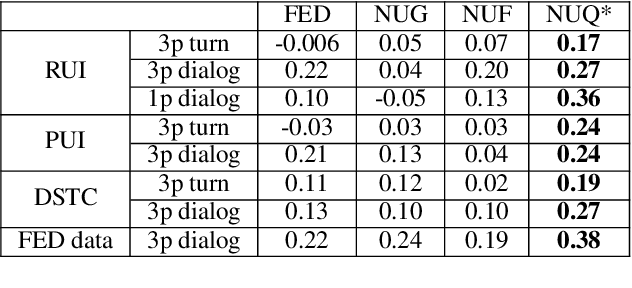
Automatic evaluation is beneficial for open-domain dialog system development. However, standard word-overlap metrics (BLEU, ROUGE) do not correlate well with human judgements of open-domain dialog systems. In this work we propose to use the sentiment of the next user utterance for turn or dialog level evaluation. Specifically we propose three methods: one that predicts the next sentiment directly, and two others that predict the next user utterance using an utterance or a feedback generator model and then classify its sentiment. Experiments show our model outperforming existing automatic evaluation metrics on both written and spoken open-domain dialogue datasets.
Think Before You Speak: Using Self-talk to Generate Implicit Commonsense Knowledge for Response Generation
Oct 16, 2021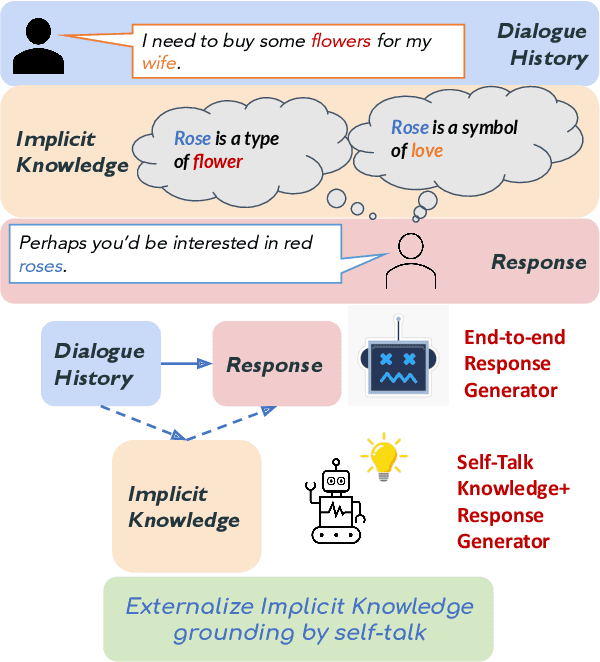
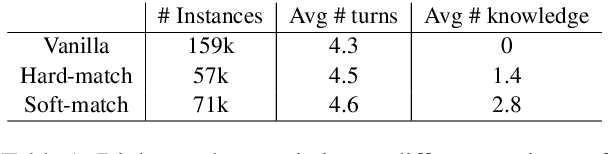
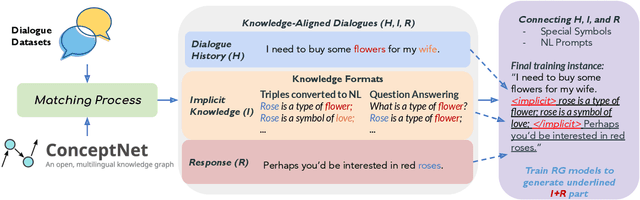

Implicit knowledge, such as common sense, is key to fluid human conversations. Current neural response generation (RG) models are trained end-to-end, omitting unstated implicit knowledge. In this paper, we present a self-talk approach that first generates the implicit commonsense knowledge and then generates response by referencing the externalized knowledge, all using one generative model. We analyze different choices to collect knowledge-aligned dialogues, represent implicit knowledge, and elicit knowledge and responses. We introduce three evaluation aspects: knowledge quality, knowledge-response connection, and response quality and perform extensive human evaluations. Our experimental results show that compared with end-to-end RG models, self-talk models that externalize the knowledge grounding process by explicitly generating implicit knowledge also produce responses that are more informative, specific, and follow common sense. We also find via human evaluation that self-talk models generate high-quality knowledge around 75% of the time. We hope that our findings encourage further work on different approaches to modeling implicit commonsense knowledge and training knowledgeable RG models.
Training Conversational Agents with Generative Conversational Networks
Oct 15, 2021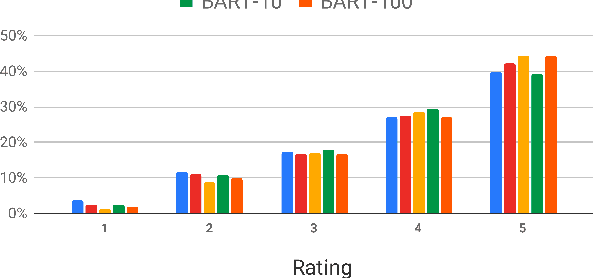

Rich, open-domain textual data available on the web resulted in great advancements for language processing. However, while that data may be suitable for language processing tasks, they are mostly non-conversational, lacking many phenomena that appear in human interactions and this is one of the reasons why we still have many unsolved challenges in conversational AI. In this work, we attempt to address this by using Generative Conversational Networks to automatically generate data and train social conversational agents. We evaluate our approach on TopicalChat with automatic metrics and human evaluators, showing that with 10% of seed data it performs close to the baseline that uses 100% of the data.
TEACh: Task-driven Embodied Agents that Chat
Oct 15, 2021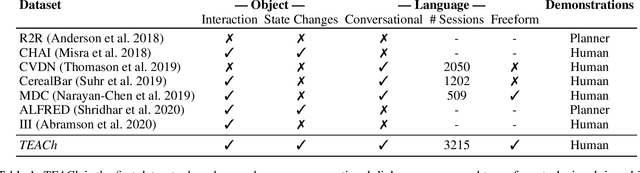
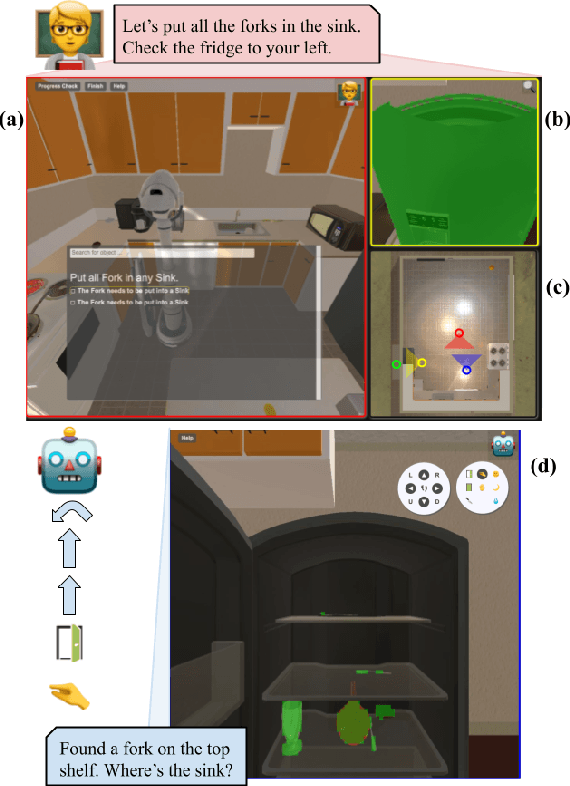
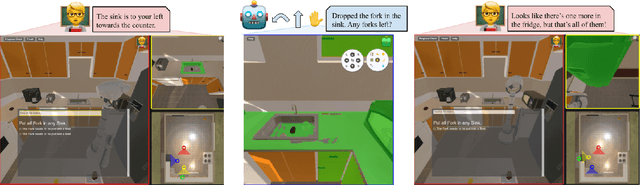
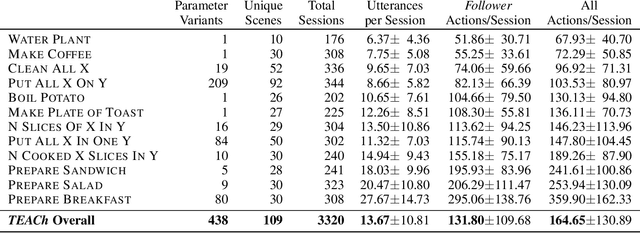
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
Rome was built in 1776: A Case Study on Factual Correctness in Knowledge-Grounded Response Generation
Oct 11, 2021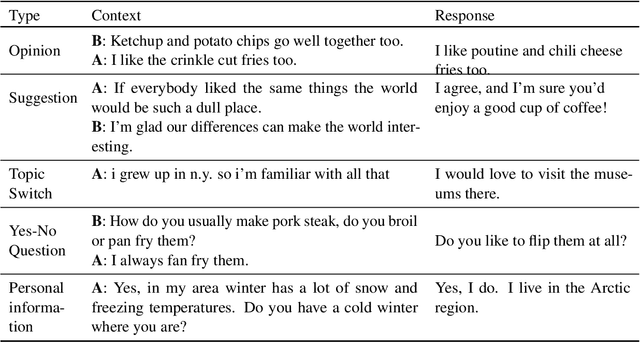
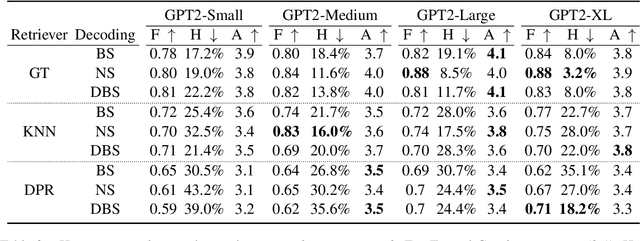


Recently neural response generation models have leveraged large pre-trained transformer models and knowledge snippets to generate relevant and informative responses. However, this does not guarantee that generated responses are factually correct. In this paper, we examine factual correctness in knowledge-grounded neural response generation models. We present a human annotation setup to identify three different response types: responses that are factually consistent with respect to the input knowledge, responses that contain hallucinated knowledge, and non-verifiable chitchat style responses. We use this setup to annotate responses generated using different stateof-the-art models, knowledge snippets, and decoding strategies. In addition, to facilitate the development of a factual consistency detector, we automatically create a new corpus called Conv-FEVER that is adapted from the Wizard of Wikipedia dataset and includes factually consistent and inconsistent responses. We demonstrate the benefit of our Conv-FEVER dataset by showing that the models trained on this data perform reasonably well to detect factually inconsistent responses with respect to the provided knowledge through evaluation on our human annotated data. We will release the Conv-FEVER dataset and the human annotated responses.
"How Robust r u?": Evaluating Task-Oriented Dialogue Systems on Spoken Conversations
Sep 28, 2021
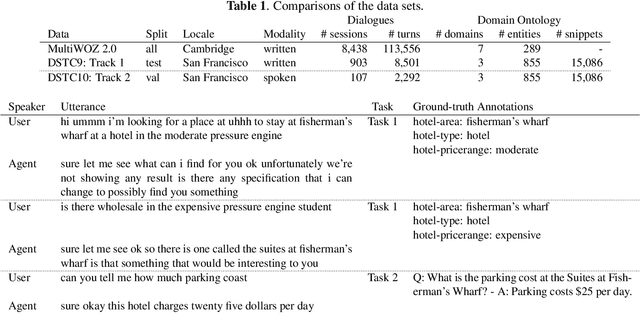
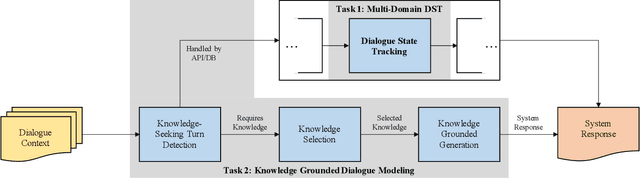

Most prior work in dialogue modeling has been on written conversations mostly because of existing data sets. However, written dialogues are not sufficient to fully capture the nature of spoken conversations as well as the potential speech recognition errors in practical spoken dialogue systems. This work presents a new benchmark on spoken task-oriented conversations, which is intended to study multi-domain dialogue state tracking and knowledge-grounded dialogue modeling. We report that the existing state-of-the-art models trained on written conversations are not performing well on our spoken data, as expected. Furthermore, we observe improvements in task performances when leveraging n-best speech recognition hypotheses such as by combining predictions based on individual hypotheses. Our data set enables speech-based benchmarking of task-oriented dialogue systems.
Style Control for Schema-Guided Natural Language Generation
Sep 24, 2021

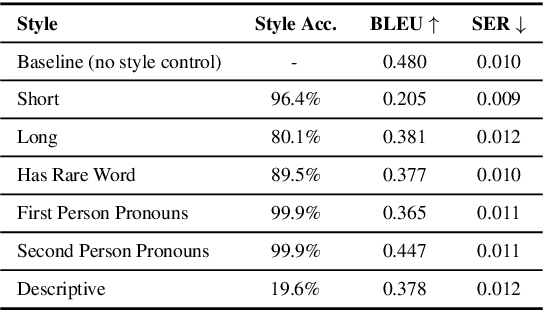

Natural Language Generation (NLG) for task-oriented dialogue systems focuses on communicating specific content accurately, fluently, and coherently. While these attributes are crucial for a successful dialogue, it is also desirable to simultaneously accomplish specific stylistic goals, such as response length, point-of-view, descriptiveness, sentiment, formality, and empathy. In this work, we focus on stylistic control and evaluation for schema-guided NLG, with joint goals of achieving both semantic and stylistic control. We experiment in detail with various controlled generation methods for large pretrained language models: specifically, conditional training, guided fine-tuning, and guided decoding. We discuss their advantages and limitations, and evaluate them with a broad range of automatic and human evaluation metrics. Our results show that while high style accuracy and semantic correctness are easier to achieve for more lexically-defined styles with conditional training, stylistic control is also achievable for more semantically complex styles using discriminator-based guided decoding methods. The results also suggest that methods that are more scalable (with less hyper-parameters tuning) and that disentangle content generation and stylistic variations are more effective at achieving semantic correctness and style accuracy.
Commonsense-Focused Dialogues for Response Generation: An Empirical Study
Sep 21, 2021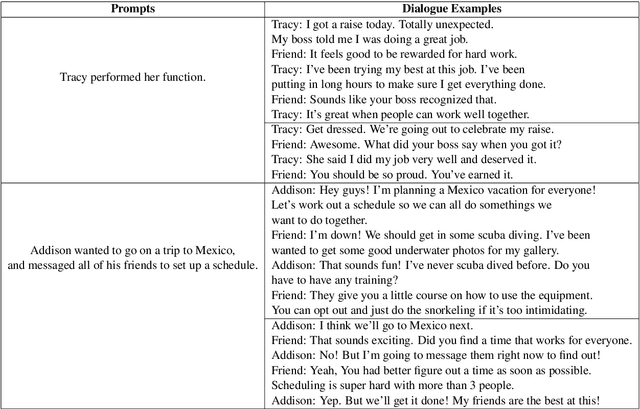
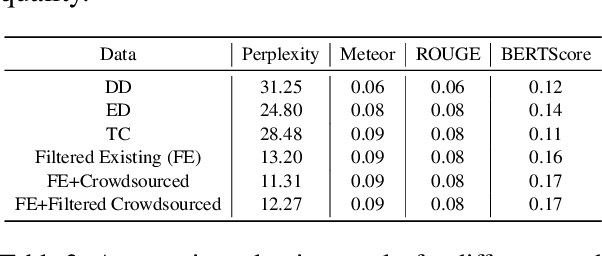
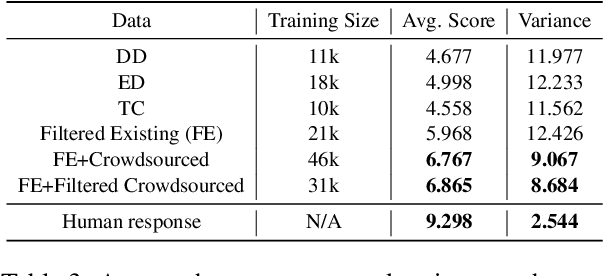
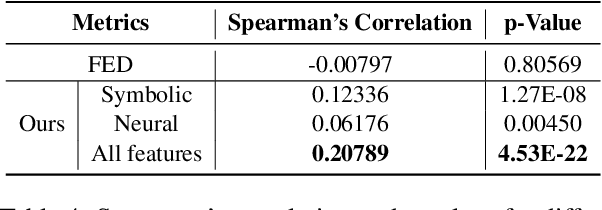
Smooth and effective communication requires the ability to perform latent or explicit commonsense inference. Prior commonsense reasoning benchmarks (such as SocialIQA and CommonsenseQA) mainly focus on the discriminative task of choosing the right answer from a set of candidates, and do not involve interactive language generation as in dialogue. Moreover, existing dialogue datasets do not explicitly focus on exhibiting commonsense as a facet. In this paper, we present an empirical study of commonsense in dialogue response generation. We first auto-extract commonsensical dialogues from existing dialogue datasets by leveraging ConceptNet, a commonsense knowledge graph. Furthermore, building on social contexts/situations in SocialIQA, we collect a new dialogue dataset with 25K dialogues aimed at exhibiting social commonsense in an interactive setting. We evaluate response generation models trained using these datasets and find that models trained on both extracted and our collected data produce responses that consistently exhibit more commonsense than baselines. Finally we propose an approach for automatic evaluation of commonsense that relies on features derived from ConceptNet and pre-trained language and dialog models, and show reasonable correlation with human evaluation of responses' commonsense quality. We are releasing a subset of our collected data, Commonsense-Dialogues, containing about 11K dialogs.