 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Control for Schema-Guided Natural Language Generation
Sep 24, 2021

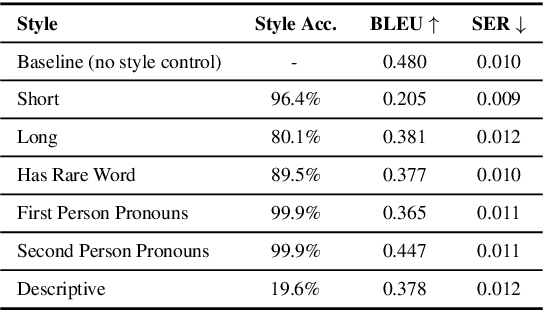

Natural Language Generation (NLG) for task-oriented dialogue systems focuses on communicating specific content accurately, fluently, and coherently. While these attributes are crucial for a successful dialogue, it is also desirable to simultaneously accomplish specific stylistic goals, such as response length, point-of-view, descriptiveness, sentiment, formality, and empathy. In this work, we focus on stylistic control and evaluation for schema-guided NLG, with joint goals of achieving both semantic and stylistic control. We experiment in detail with various controlled generation methods for large pretrained language models: specifically, conditional training, guided fine-tuning, and guided decoding. We discuss their advantages and limitations, and evaluate them with a broad range of automatic and human evaluation metrics. Our results show that while high style accuracy and semantic correctness are easier to achieve for more lexically-defined styles with conditional training, stylistic control is also achievable for more semantically complex styles using discriminator-based guided decoding methods. The results also suggest that methods that are more scalable (with less hyper-parameters tuning) and that disentangle content generation and stylistic variations are more effective at achieving semantic correctness and style accuracy.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
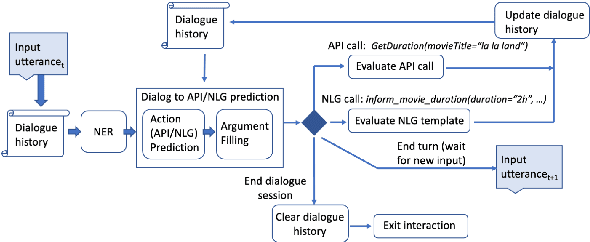

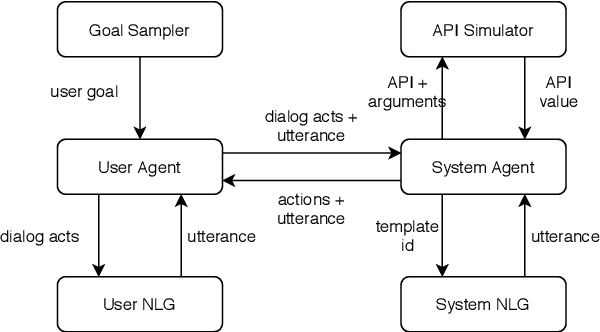
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Schema-Guided Natural Language Generation
May 11, 2020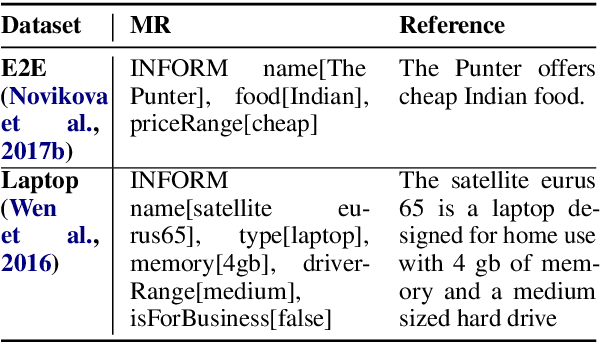


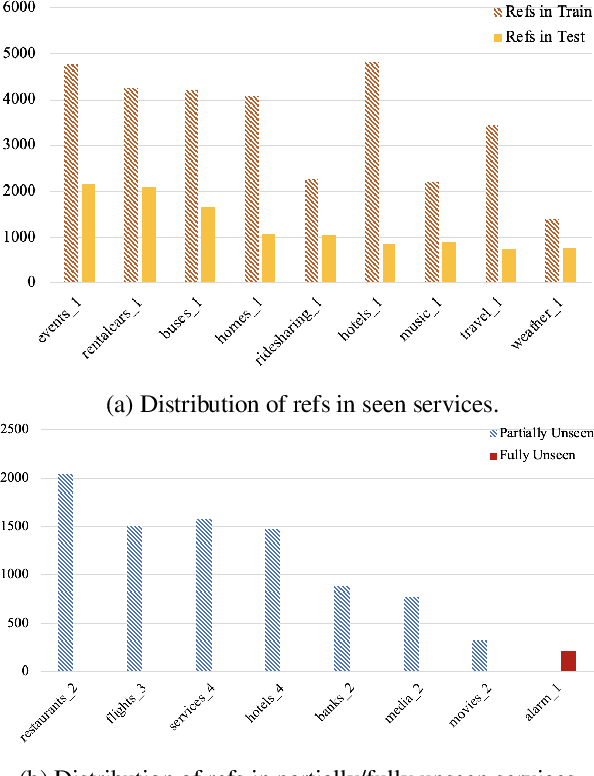
Neural network based approaches to natural language generation (NLG) have gained popularity in recent years. The goal of the task is to generate a natural language string to realize an input meaning representation, hence large datasets of paired utterances and their meaning representations are used for training the network. However, dataset creation for language generation is an arduous task, and popular datasets designed for training these generators mostly consist of simple meaning representations composed of slot and value tokens to be realized. These simple meaning representations do not include any contextual information that may be helpful for training an NLG system to generalize, such as domain information and descriptions of slots and values. In this paper, we present the novel task of Schema-Guided Natural Language Generation, in which we repurpose an existing dataset for another task: dialog state tracking. Dialog state tracking data includes a large and rich schema spanning multiple different attributes, including information about the domain, user intent, and slot descriptions. We train different state-of-the-art models for neural natural language generation on this data and show that inclusion of the rich schema allows our models to produce higher quality outputs both in terms of semantics and diversity. We also conduct experiments comparing model performance on seen versus unseen domains. Finally, we present human evaluation results and analysis demonstrating high ratings for overall output quality.
Setting Up Pepper For Autonomous Navigation And Personalized Interaction With Users
Apr 16, 2017
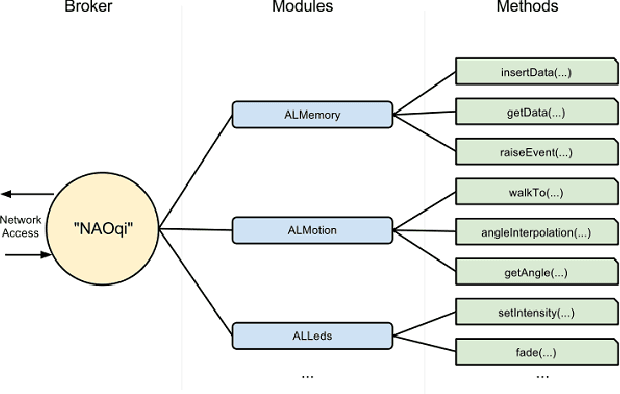
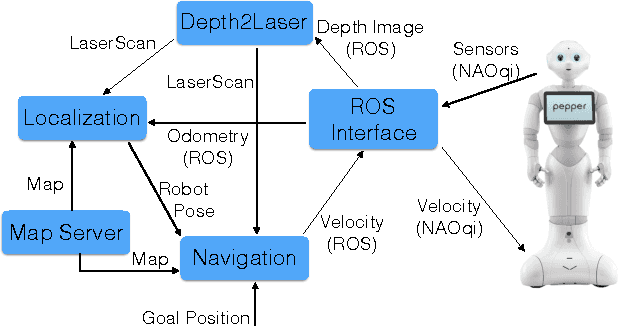
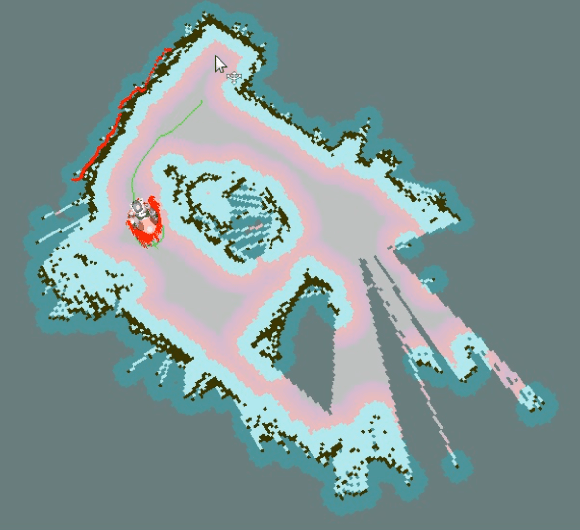
In this paper we present our work with the Pepper robot, a service robot from SoftBank Robotics. We had two main goals in this work: improving the autonomy of this robot by increasing its awareness of the environment; and enhance the robot ability to interact with its users. To achieve this goals, we used ROS, a modern open-source framework for developing robotics software, to provide Pepper with state of the art localization and navigation capabilities. Furthermore, we contribute an architecture for effective human interaction based on cloud services. Our architecture improves Pepper speech recognition capabilities by connecting it to the IBM Bluemix Speech Recognition service and enable the robot to recognize its user via an in-house face recognition web-service. We show examples of our successful integration of ROS and IBM services with Pepper's own software. As a result, we were able to make Pepper move autonomously in a environment with humans and obstacles. We were also able to have Pepper execute spoken commands from known users as well as newly introduced users that were enrolled in the robot list of trusted users via a multi-modal interface.