 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLA3: Efficient Label-Aware AutoAugment
Apr 20, 2023Automated augmentation is an emerging and effective technique to search for data augmentation policies to improve generalizability of deep neural network training. Most existing work focuses on constructing a unified policy applicable to all data samples in a given dataset, without considering sample or class variations. In this paper, we propose a novel two-stage data augmentation algorithm, named Label-Aware AutoAugment (LA3), which takes advantage of the label information, and learns augmentation policies separately for samples of different labels. LA3 consists of two learning stages, where in the first stage, individual augmentation methods are evaluated and ranked for each label via Bayesian Optimization aided by a neural predictor, which allows us to identify effective augmentation techniques for each label under a low search cost. And in the second stage, a composite augmentation policy is constructed out of a selection of effective as well as complementary augmentations, which produces significant performance boost and can be easily deployed in typical model training. Extensive experiments demonstrate that LA3 achieves excellent performance matching or surpassing existing methods on CIFAR-10 and CIFAR-100, and achieves a new state-of-the-art ImageNet accuracy of 79.97% on ResNet-50 among auto-augmentation methods, while maintaining a low computational cost.
GlyphDraw: Learning to Draw Chinese Characters in Image Synthesis Models Coherently
Mar 31, 2023



Recent breakthroughs in the field of language-guided image generation have yielded impressive achievements, enabling the creation of high-quality and diverse images based on user instructions. Although the synthesis performance is fascinating, one significant limitation of current image generation models is their insufficient ability to generate coherent text within images, particularly for complex glyph structures like Chinese characters. To address this problem, we introduce GlyphDraw, a general learning framework aiming at endowing image generation models with the capacity to generate images embedded with coherent text. To the best of our knowledge, this is the first work in the field of image synthesis to address the generation of Chinese characters. % we first adopt the OCR technique to collect images with Chinese characters as training samples, and extract the text and locations as auxiliary information. We first sophisticatedly design the image-text dataset's construction strategy, then build our model specifically on a diffusion-based image generator and carefully modify the network structure to allow the model to learn drawing Chinese characters with the help of glyph and position information. Furthermore, we maintain the model's open-domain image synthesis capability by preventing catastrophic forgetting by using a variety of training techniques. Extensive qualitative and quantitative experiments demonstrate that our method not only produces accurate Chinese characters as in prompts, but also naturally blends the generated text into the background. Please refer to https://1073521013.github.io/glyph-draw.github.io
Reparameterization through Spatial Gradient Scaling
Mar 07, 2023Reparameterization aims to improve the generalization of deep neural networks by transforming convolutional layers into equivalent multi-branched structures during training. However, there exists a gap in understanding how reparameterization may change and benefit the learning process of neural networks. In this paper, we present a novel spatial gradient scaling method to redistribute learning focus among weights in convolutional networks. We prove that spatial gradient scaling achieves the same learning dynamics as a branched reparameterization yet without introducing structural changes into the network. We further propose an analytical approach that dynamically learns scalings for each convolutional layer based on the spatial characteristics of its input feature map gauged by mutual information. Experiments on CIFAR-10, CIFAR-100, and ImageNet show that without searching for reparameterized structures, our proposed scaling method outperforms the state-of-the-art reparameterization strategies at a lower computational cost.
A General-Purpose Transferable Predictor for Neural Architecture Search
Feb 21, 2023



Understanding and modelling the performance of neural architectures is key to Neural Architecture Search (NAS). Performance predictors have seen widespread use in low-cost NAS and achieve high ranking correlations between predicted and ground truth performance in several NAS benchmarks. However, existing predictors are often designed based on network encodings specific to a predefined search space and are therefore not generalizable to other search spaces or new architecture families. In this paper, we propose a general-purpose neural predictor for NAS that can transfer across search spaces, by representing any given candidate Convolutional Neural Network (CNN) with a Computation Graph (CG) that consists of primitive operators. We further combine our CG network representation with Contrastive Learning (CL) and propose a graph representation learning procedure that leverages the structural information of unlabeled architectures from multiple families to train CG embeddings for our performance predictor. Experimental results on NAS-Bench-101, 201 and 301 demonstrate the efficacy of our scheme as we achieve strong positive Spearman Rank Correlation Coefficient (SRCC) on every search space, outperforming several Zero-Cost Proxies, including Synflow and Jacov, which are also generalizable predictors across search spaces. Moreover, when using our proposed general-purpose predictor in an evolutionary neural architecture search algorithm, we can find high-performance architectures on NAS-Bench-101 and find a MobileNetV3 architecture that attains 79.2% top-1 accuracy on ImageNet.
AIO-P: Expanding Neural Performance Predictors Beyond Image Classification
Nov 30, 2022Evaluating neural network performance is critical to deep neural network design but a costly procedure. Neural predictors provide an efficient solution by treating architectures as samples and learning to estimate their performance on a given task. However, existing predictors are task-dependent, predominantly estimating neural network performance on image classification benchmarks. They are also search-space dependent; each predictor is designed to make predictions for a specific architecture search space with predefined topologies and set of operations. In this paper, we propose a novel All-in-One Predictor (AIO-P), which aims to pretrain neural predictors on architecture examples from multiple, separate computer vision (CV) task domains and multiple architecture spaces, and then transfer to unseen downstream CV tasks or neural architectures. We describe our proposed techniques for general graph representation, efficient predictor pretraining and knowledge infusion techniques, as well as methods to transfer to downstream tasks/spaces. Extensive experimental results show that AIO-P can achieve Mean Absolute Error (MAE) and Spearman's Rank Correlation (SRCC) below 1% and above 0.5, respectively, on a breadth of target downstream CV tasks with or without fine-tuning, outperforming a number of baselines. Moreover, AIO-P can directly transfer to new architectures not seen during training, accurately rank them and serve as an effective performance estimator when paired with an algorithm designed to preserve performance while reducing FLOPs.
GENNAPE: Towards Generalized Neural Architecture Performance Estimators
Nov 30, 2022



Predicting neural architecture performance is a challenging task and is crucial to neural architecture design and search. Existing approaches either rely on neural performance predictors which are limited to modeling architectures in a predefined design space involving specific sets of operators and connection rules, and cannot generalize to unseen architectures, or resort to zero-cost proxies which are not always accurate. In this paper, we propose GENNAPE, a Generalized Neural Architecture Performance Estimator, which is pretrained on open neural architecture benchmarks, and aims to generalize to completely unseen architectures through combined innovations in network representation, contrastive pretraining, and fuzzy clustering-based predictor ensemble. Specifically, GENNAPE represents a given neural network as a Computation Graph (CG) of atomic operations which can model an arbitrary architecture. It first learns a graph encoder via Contrastive Learning to encourage network separation by topological features, and then trains multiple predictor heads, which are soft-aggregated according to the fuzzy membership of a neural network. Experiments show that GENNAPE pretrained on NAS-Bench-101 can achieve superior transferability to 5 different public neural network benchmarks, including NAS-Bench-201, NAS-Bench-301, MobileNet and ResNet families under no or minimum fine-tuning. We further introduce 3 challenging newly labelled neural network benchmarks: HiAML, Inception and Two-Path, which can concentrate in narrow accuracy ranges. Extensive experiments show that GENNAPE can correctly discern high-performance architectures in these families. Finally, when paired with a search algorithm, GENNAPE can find architectures that improve accuracy while reducing FLOPs on three families.
One for All, All for One: Learning and Transferring User Embeddings for Cross-Domain Recommendation
Nov 22, 2022Cross-domain recommendation is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing techniques focus on single-target or dual-target cross-domain recommendation (CDR) and are hard to be generalized to CDR with multiple target domains. In addition, the negative transfer problem is prevalent in CDR, where the recommendation performance in a target domain may not always be enhanced by knowledge learned from a source domain, especially when the source domain has sparse data. In this study, we propose CAT-ART, a multi-target CDR method that learns to improve recommendations in all participating domains through representation learning and embedding transfer. Our method consists of two parts: a self-supervised Contrastive AuToencoder (CAT) framework to generate global user embeddings based on information from all participating domains, and an Attention-based Representation Transfer (ART) framework which transfers domain-specific user embeddings from other domains to assist with target domain recommendation. CAT-ART boosts the recommendation performance in any target domain through the combined use of the learned global user representation and knowledge transferred from other domains, in addition to the original user embedding in the target domain. We conducted extensive experiments on a collected real-world CDR dataset spanning 5 domains and involving a million users. Experimental results demonstrate the superiority of the proposed method over a range of prior arts. We further conducted ablation studies to verify the effectiveness of the proposed components. Our collected dataset will be open-sourced to facilitate future research in the field of multi-domain recommender systems and user modeling.
Mulco: Recognizing Chinese Nested Named Entities Through Multiple Scopes
Nov 20, 2022



Nested Named Entity Recognition (NNER) has been a long-term challenge to researchers as an important sub-area of Named Entity Recognition. NNER is where one entity may be part of a longer entity, and this may happen on multiple levels, as the term nested suggests. These nested structures make traditional sequence labeling methods unable to properly recognize all entities. While recent researches focus on designing better recognition methods for NNER in a variety of languages, the Chinese NNER (CNNER) still lacks attention, where a free-for-access, CNNER-specialized benchmark is absent. In this paper, we aim to solve CNNER problems by providing a Chinese dataset and a learning-based model to tackle the issue. To facilitate the research on this task, we release ChiNesE, a CNNER dataset with 20,000 sentences sampled from online passages of multiple domains, containing 117,284 entities failing in 10 categories, where 43.8 percent of those entities are nested. Based on ChiNesE, we propose Mulco, a novel method that can recognize named entities in nested structures through multiple scopes. Each scope use a designed scope-based sequence labeling method, which predicts an anchor and the length of a named entity to recognize it. Experiment results show that Mulco has outperformed several baseline methods with the different recognizing schemes on ChiNesE. We also conduct extensive experiments on ACE2005 Chinese corpus, where Mulco has achieved the best performance compared with the baseline methods.
R5: Rule Discovery with Reinforced and Recurrent Relational Reasoning
May 13, 2022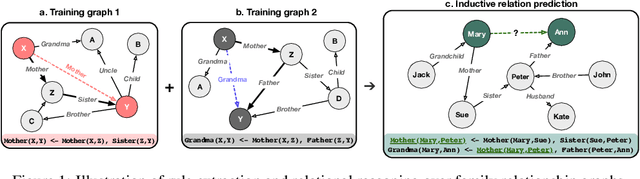
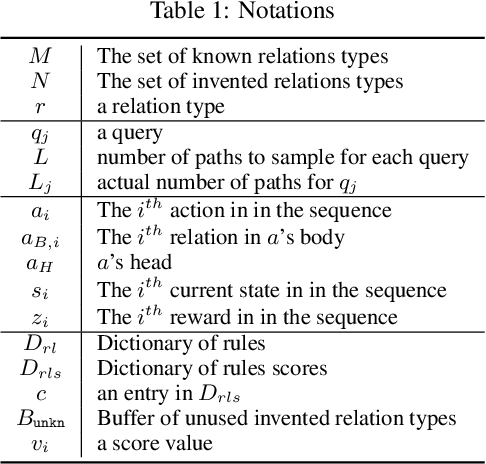
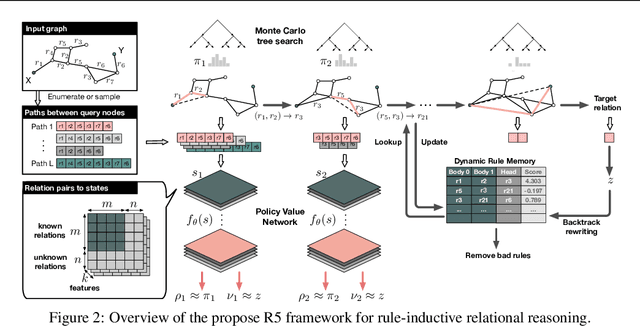
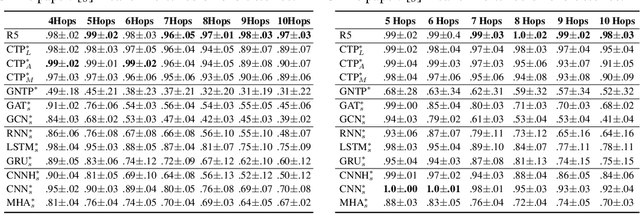
Systematicity, i.e., the ability to recombine known parts and rules to form new sequences while reasoning over relational data, is critical to machine intelligence. A model with strong systematicity is able to train on small-scale tasks and generalize to large-scale tasks. In this paper, we propose R5, a relational reasoning framework based on reinforcement learning that reasons over relational graph data and explicitly mines underlying compositional logical rules from observations. R5 has strong systematicity and being robust to noisy data. It consists of a policy value network equipped with Monte Carlo Tree Search to perform recurrent relational prediction and a backtrack rewriting mechanism for rule mining. By alternately applying the two components, R5 progressively learns a set of explicit rules from data and performs explainable and generalizable relation prediction. We conduct extensive evaluations on multiple datasets. Experimental results show that R5 outperforms various embedding-based and rule induction baselines on relation prediction tasks while achieving a high recall rate in discovering ground truth rules.
RecGURU: Adversarial Learning of Generalized User Representations for Cross-Domain Recommendation
Nov 19, 2021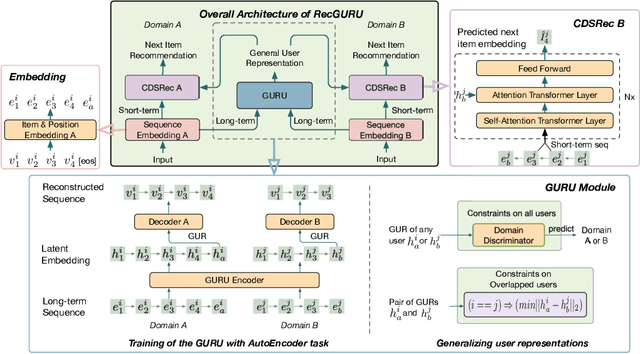
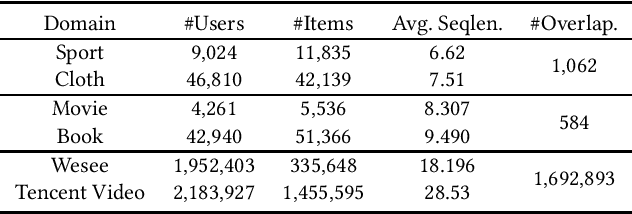
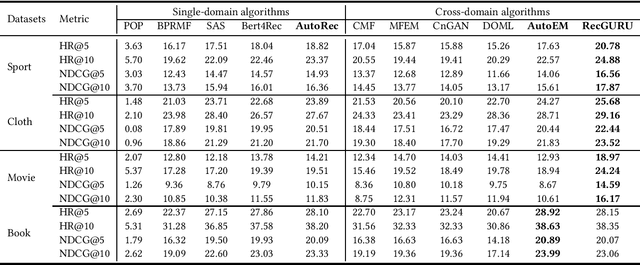
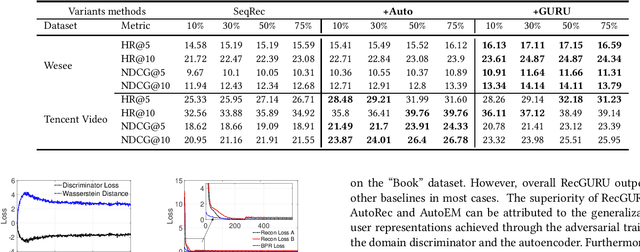
Cross-domain recommendation can help alleviate the data sparsity issue in traditional sequential recommender systems. In this paper, we propose the RecGURU algorithm framework to generate a Generalized User Representation (GUR) incorporating user information across domains in sequential recommendation, even when there is minimum or no common users in the two domains. We propose a self-attentive autoencoder to derive latent user representations, and a domain discriminator, which aims to predict the origin domain of a generated latent representation. We propose a novel adversarial learning method to train the two modules to unify user embeddings generated from different domains into a single global GUR for each user. The learned GUR captures the overall preferences and characteristics of a user and thus can be used to augment the behavior data and improve recommendations in any single domain in which the user is involved. Extensive experiments have been conducted on two public cross-domain recommendation datasets as well as a large dataset collected from real-world applications. The results demonstrate that RecGURU boosts performance and outperforms various state-of-the-art sequential recommendation and cross-domain recommendation methods. The collected data will be released to facilitate future research.