 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive Unlabeled Contrastive Learning
Jun 01, 2022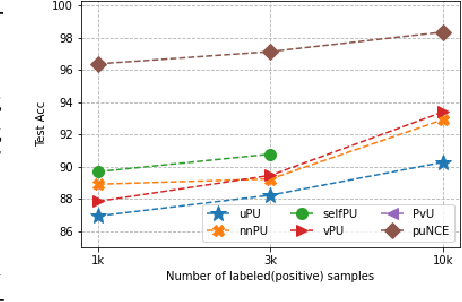
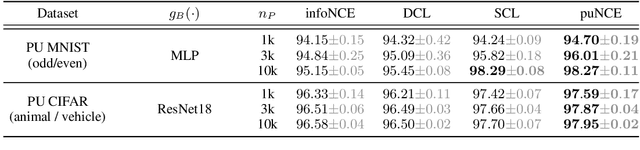
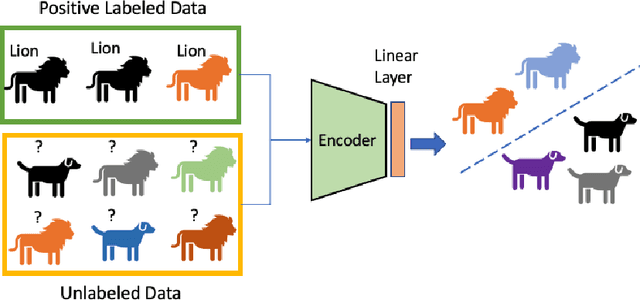
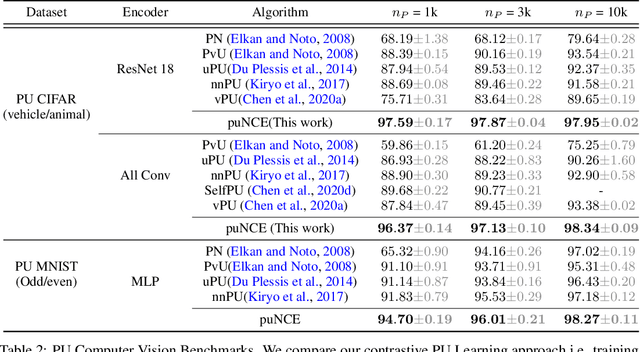
Self-supervised pretraining on unlabeled data followed by supervised finetuning on labeled data is a popular paradigm for learning from limited labeled examples. In this paper, we investigate and extend this paradigm to the classical positive unlabeled (PU) setting - the weakly supervised task of learning a binary classifier only using a few labeled positive examples and a set of unlabeled samples. We propose a novel PU learning objective positive unlabeled Noise Contrastive Estimation (puNCE) that leverages the available explicit (from labeled samples) and implicit (from unlabeled samples) supervision to learn useful representations from positive unlabeled input data. The underlying idea is to assign each training sample an individual weight; labeled positives are given unit weight; unlabeled samples are duplicated, one copy is labeled positive and the other as negative with weights $\pi$ and $(1-\pi)$ where $\pi$ denotes the class prior. Extensive experiments across vision and natural language tasks reveal that puNCE consistently improves over existing unsupervised and supervised contrastive baselines under limited supervision.
Frequency-aware SGD for Efficient Embedding Learning with Provable Benefits
Oct 24, 2021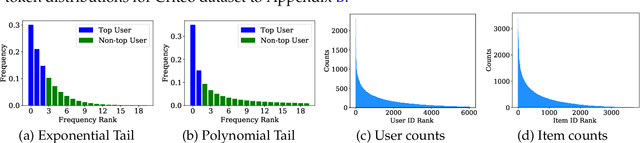
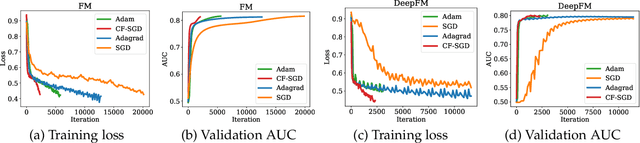

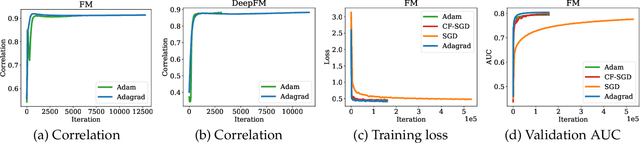
Embedding learning has found widespread applications in recommendation systems and natural language modeling, among other domains. To learn quality embeddings efficiently, adaptive learning rate algorithms have demonstrated superior empirical performance over SGD, largely accredited to their token-dependent learning rate. However, the underlying mechanism for the efficiency of token-dependent learning rate remains underexplored. We show that incorporating frequency information of tokens in the embedding learning problems leads to provably efficient algorithms, and demonstrate that common adaptive algorithms implicitly exploit the frequency information to a large extent. Specifically, we propose (Counter-based) Frequency-aware Stochastic Gradient Descent, which applies a frequency-dependent learning rate for each token, and exhibits provable speed-up compared to SGD when the token distribution is imbalanced. Empirically, we show the proposed algorithms are able to improve or match adaptive algorithms on benchmark recommendation tasks and a large-scale industrial recommendation system, closing the performance gap between SGD and adaptive algorithms. Our results are the first to show token-dependent learning rate provably improves convergence for non-convex embedding learning problems.
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021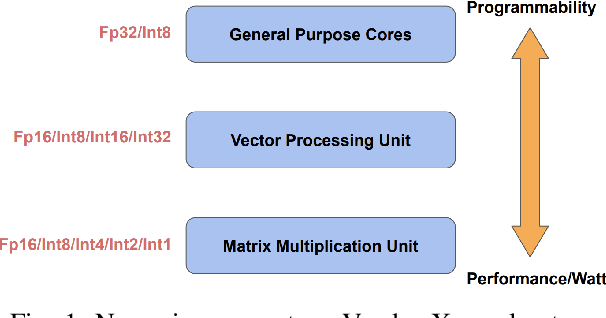
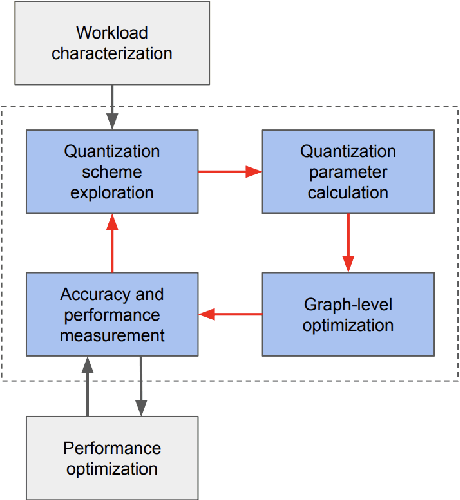
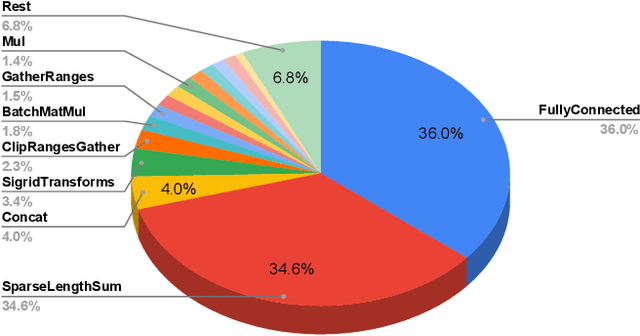
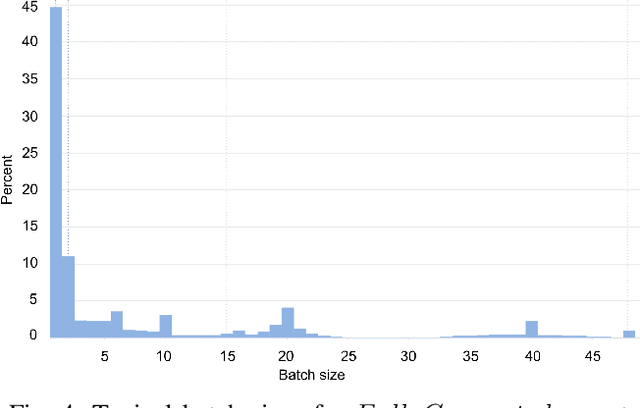
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021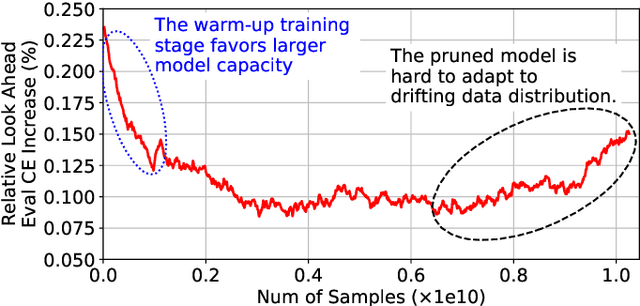

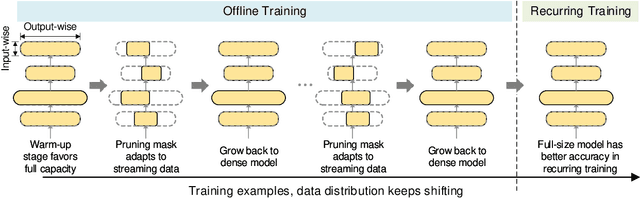

Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
Adaptive Dense-to-Sparse Paradigm for Pruning Online Recommendation System with Non-Stationary Data
Oct 21, 2020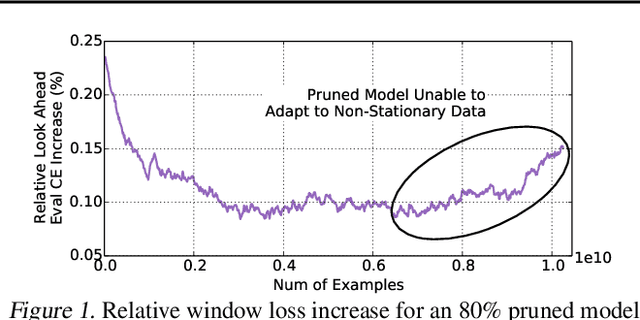
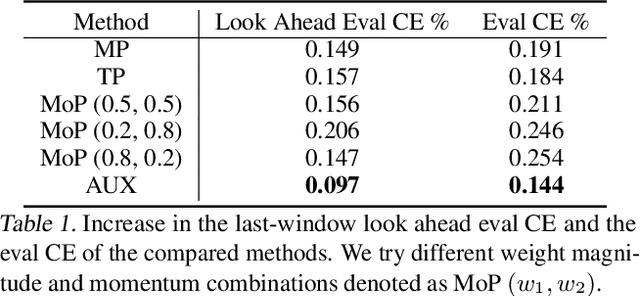
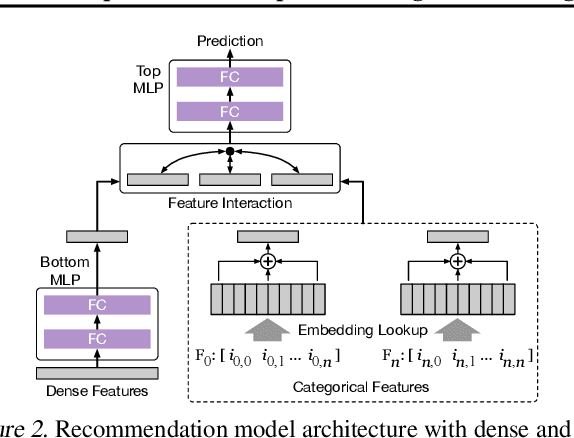
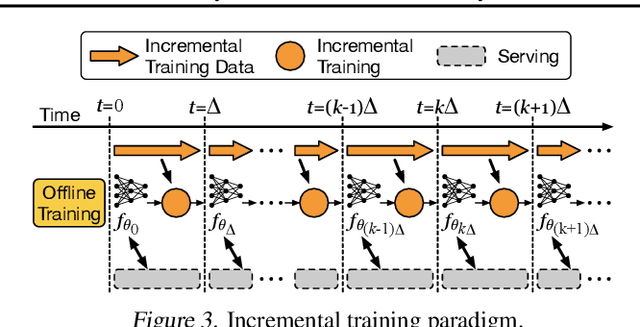
Large scale deep learning provides a tremendous opportunity to improve the quality of content recommendation systems by employing both wider and deeper models, but this comes at great infrastructural cost and carbon footprint in modern data centers. Pruning is an effective technique that reduces both memory and compute demand for model inference. However, pruning for online recommendation systems is challenging due to the continuous data distribution shift (a.k.a non-stationary data). Although incremental training on the full model is able to adapt to the non-stationary data, directly applying it on the pruned model leads to accuracy loss. This is because the sparsity pattern after pruning requires adjustment to learn new patterns. To the best of our knowledge, this is the first work to provide in-depth analysis and discussion of applying pruning to online recommendation systems with non-stationary data distribution. Overall, this work makes the following contributions: 1) We present an adaptive dense to sparse paradigm equipped with a novel pruning algorithm for pruning a large scale recommendation system with non-stationary data distribution; 2) We design the pruning algorithm to automatically learn the sparsity across layers to avoid repeating hand-tuning, which is critical for pruning the heterogeneous architectures of recommendation systems trained with non-stationary data.
Fast Distributed Training of Deep Neural Networks: Dynamic Communication Thresholding for Model and Data Parallelism
Oct 18, 2020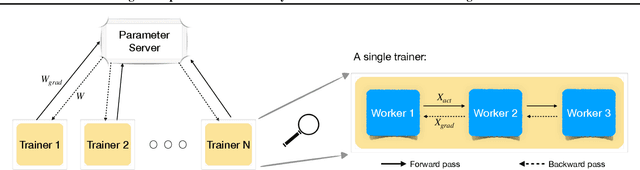
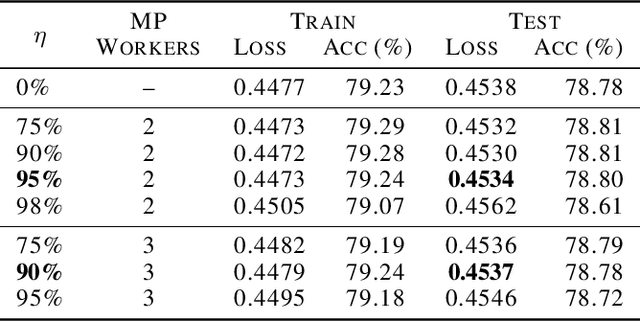
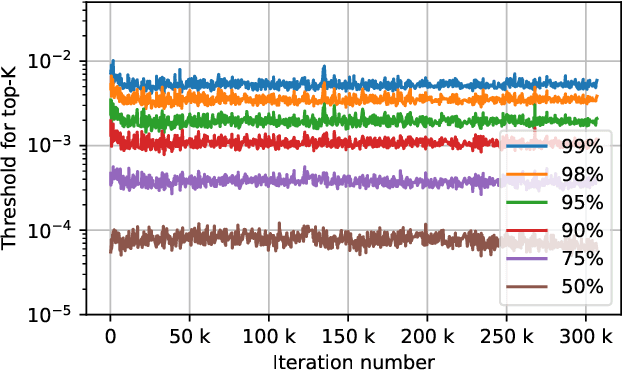
Data Parallelism (DP) and Model Parallelism (MP) are two common paradigms to enable large-scale distributed training of neural networks. Recent trends, such as the improved model performance of deeper and wider neural networks when trained with billions of data points, have prompted the use of hybrid parallelism---a paradigm that employs both DP and MP to scale further parallelization for machine learning. Hybrid training allows compute power to increase, but it runs up against the key bottleneck of communication overhead that hinders scalability. In this paper, we propose a compression framework called Dynamic Communication Thresholding (DCT) for communication-efficient hybrid training. DCT filters the entities to be communicated across the network through a simple hard-thresholding function, allowing only the most relevant information to pass through. For communication efficient DP, DCT compresses the parameter gradients sent to the parameter server during model synchronization, while compensating for the introduced errors with known techniques. For communication efficient MP, DCT incorporates a novel technique to compress the activations and gradients sent across the network during the forward and backward propagation, respectively. This is done by identifying and updating only the most relevant neurons of the neural network for each training sample in the data. Under modest assumptions, we show that the convergence of training is maintained with DCT. We evaluate DCT on natural language processing and recommender system models. DCT reduces overall communication by 20x, improving end-to-end training time on industry scale models by 37%. Moreover, we observe an improvement in the trained model performance, as the induced sparsity is possibly acting as an implicit sparsity based regularization.
On the Runtime-Efficacy Trade-off of Anomaly Detection Techniques for Real-Time Streaming Data
Oct 12, 2017
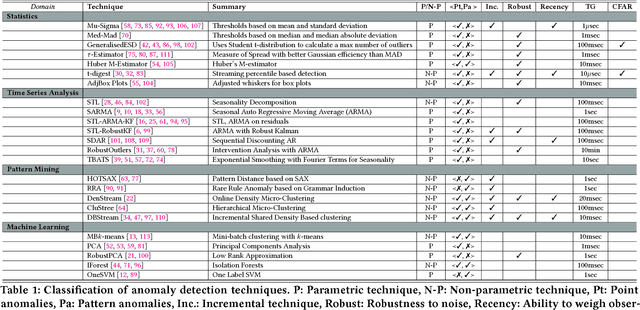
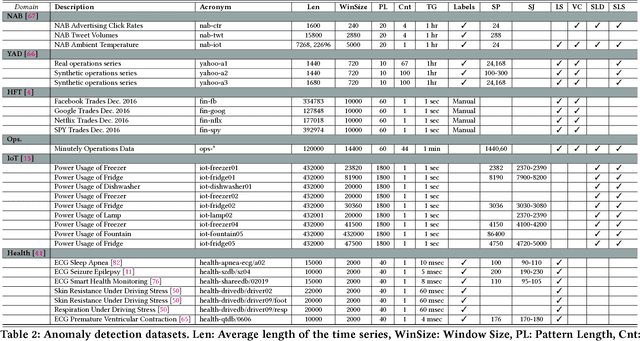
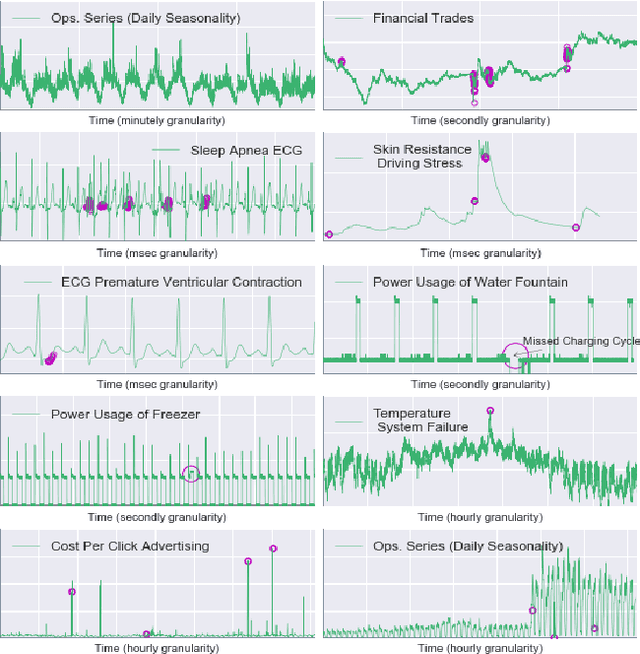
Ever growing volume and velocity of data coupled with decreasing attention span of end users underscore the critical need for real-time analytics. In this regard, anomaly detection plays a key role as an application as well as a means to verify data fidelity. Although the subject of anomaly detection has been researched for over 100 years in a multitude of disciplines such as, but not limited to, astronomy, statistics, manufacturing, econometrics, marketing, most of the existing techniques cannot be used as is on real-time data streams. Further, the lack of characterization of performance -- both with respect to real-timeliness and accuracy -- on production data sets makes model selection very challenging. To this end, we present an in-depth analysis, geared towards real-time streaming data, of anomaly detection techniques. Given the requirements with respect to real-timeliness and accuracy, the analysis presented in this paper should serve as a guide for selection of the "best" anomaly detection technique. To the best of our knowledge, this is the first characterization of anomaly detection techniques proposed in very diverse set of fields, using production data sets corresponding to a wide set of application domains.