 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Robustness Transferable across Languages in Multilingual Neural Machine Translation?
Oct 31, 2023



Robustness, the ability of models to maintain performance in the face of perturbations, is critical for developing reliable NLP systems. Recent studies have shown promising results in improving the robustness of models through adversarial training and data augmentation. However, in machine translation, most of these studies have focused on bilingual machine translation with a single translation direction. In this paper, we investigate the transferability of robustness across different languages in multilingual neural machine translation. We propose a robustness transfer analysis protocol and conduct a series of experiments. In particular, we use character-, word-, and multi-level noises to attack the specific translation direction of the multilingual neural machine translation model and evaluate the robustness of other translation directions. Our findings demonstrate that the robustness gained in one translation direction can indeed transfer to other translation directions. Additionally, we empirically find scenarios where robustness to character-level noise and word-level noise is more likely to transfer.
Large Language Model Alignment: A Survey
Sep 26, 2023



Recent years have witnessed remarkable progress made in large language models (LLMs). Such advancements, while garnering significant attention, have concurrently elicited various concerns. The potential of these models is undeniably vast; however, they may yield texts that are imprecise, misleading, or even detrimental. Consequently, it becomes paramount to employ alignment techniques to ensure these models to exhibit behaviors consistent with human values. This survey endeavors to furnish an extensive exploration of alignment methodologies designed for LLMs, in conjunction with the extant capability research in this domain. Adopting the lens of AI alignment, we categorize the prevailing methods and emergent proposals for the alignment of LLMs into outer and inner alignment. We also probe into salient issues including the models' interpretability, and potential vulnerabilities to adversarial attacks. To assess LLM alignment, we present a wide variety of benchmarks and evaluation methodologies. After discussing the state of alignment research for LLMs, we finally cast a vision toward the future, contemplating the promising avenues of research that lie ahead. Our aspiration for this survey extends beyond merely spurring research interests in this realm. We also envision bridging the gap between the AI alignment research community and the researchers engrossed in the capability exploration of LLMs for both capable and safe LLMs.
Watermarking Conditional Text Generation for AI Detection: Unveiling Challenges and a Semantic-Aware Watermark Remedy
Jul 25, 2023To mitigate potential risks associated with language models, recent AI detection research proposes incorporating watermarks into machine-generated text through random vocabulary restrictions and utilizing this information for detection. While these watermarks only induce a slight deterioration in perplexity, our empirical investigation reveals a significant detriment to the performance of conditional text generation. To address this issue, we introduce a simple yet effective semantic-aware watermarking algorithm that considers the characteristics of conditional text generation and the input context. Experimental results demonstrate that our proposed method yields substantial improvements across various text generation models, including BART and Flan-T5, in tasks such as summarization and data-to-text generation while maintaining detection ability.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
CBBQ: A Chinese Bias Benchmark Dataset Curated with Human-AI Collaboration for Large Language Models
Jun 28, 2023Holistically measuring societal biases of large language models is crucial for detecting and reducing ethical risks in highly capable AI models. In this work, we present a Chinese Bias Benchmark dataset that consists of over 100K questions jointly constructed by human experts and generative language models, covering stereotypes and societal biases in 14 social dimensions related to Chinese culture and values. The curation process contains 4 essential steps: bias identification via extensive literature review, ambiguous context generation, AI-assisted disambiguous context generation, snd manual review \& recomposition. The testing instances in the dataset are automatically derived from 3K+ high-quality templates manually authored with stringent quality control. The dataset exhibits wide coverage and high diversity. Extensive experiments demonstrate the effectiveness of the dataset in detecting model bias, with all 10 publicly available Chinese large language models exhibiting strong bias in certain categories. Additionally, we observe from our experiments that fine-tuned models could, to a certain extent, heed instructions and avoid generating outputs that are morally harmful in some types, in the way of "moral self-correction". Our dataset and results are publicly available at \href{https://github.com/YFHuangxxxx/CBBQ}{https://github.com/YFHuangxxxx/CBBQ}, offering debiasing research opportunities to a widened community.
M3KE: A Massive Multi-Level Multi-Subject Knowledge Evaluation Benchmark for Chinese Large Language Models
May 21, 2023



Large language models have recently made tremendous progress in a variety of aspects, e.g., cross-task generalization, instruction following. Comprehensively evaluating the capability of large language models in multiple tasks is of great importance. In this paper, we propose M3KE, a Massive Multi-Level Multi-Subject Knowledge Evaluation benchmark, which is developed to measure knowledge acquired by Chinese large language models by testing their multitask accuracy in zero- and few-shot settings. We have collected 20,477 questions from 71 tasks. Our selection covers all major levels of Chinese education system, ranging from the primary school to college, as well as a wide variety of subjects, including humanities, history, politics, law, education, psychology, science, technology, art and religion. All questions are multiple-choice questions with four options, hence guaranteeing a standardized and unified assessment process. We've assessed a number of state-of-the-art open-source Chinese large language models on the proposed benchmark. The size of these models varies from 335M to 130B parameters. Experiment results demonstrate that they perform significantly worse than GPT-3.5 that reaches an accuracy of ~ 48% on M3KE. The dataset is available at https://github.com/tjunlp-lab/M3KE.
Inverse Reinforcement Learning for Text Summarization
Dec 19, 2022Current state-of-the-art summarization models are trained with either maximum likelihood estimation (MLE) or reinforcement learning (RL). In this study, we investigate the third training paradigm and argue that inverse reinforcement learning (IRL) may be more suitable for text summarization. IRL focuses on estimating the reward function of an agent, given a set of observations of that agent's behavior. Generally, IRL provides advantages in situations where the reward function is not explicitly known or where it is difficult to define or interact with the environment directly. These situations are exactly what we observe in summarization. Thus, we introduce inverse reinforcement learning into text summarization and define a suite of sub-rewards that are important for summarization optimization. By simultaneously estimating the reward function and optimizing the summarization agent with expert demonstrations, we show that the model trained with IRL produces summaries that closely follow human behavior, in terms of better ROUGE, coverage, novelty, compression ratio and factuality when compared to the baselines trained with MLE and RL.
FewFedWeight: Few-shot Federated Learning Framework across Multiple NLP Tasks
Dec 16, 2022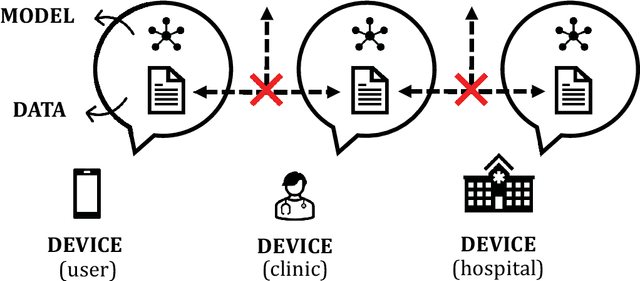
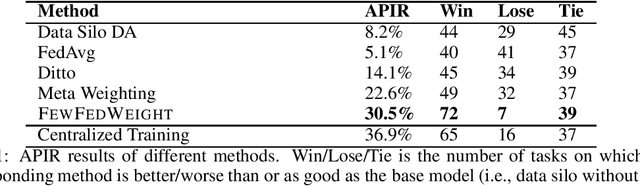
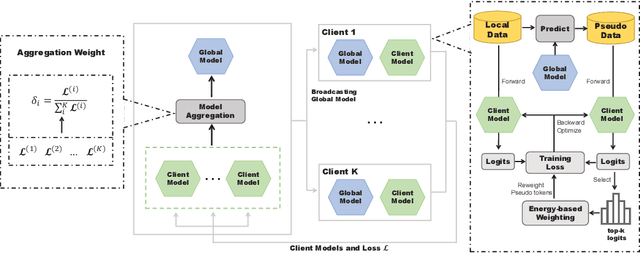

Massively multi-task learning with large language models has recently made substantial progress on few-shot generalization. However, this is usually performed in a centralized learning fashion, ignoring the privacy sensitivity issue of (annotated) data used in multiple tasks. To mitigate this issue, we propose FewFedWeight, a few-shot federated learning framework across multiple tasks, to achieve the best of both worlds: privacy preservation and cross-task generalization. FewFedWeight trains client models in isolated devices without sharing data. It broadcasts the global model in the server to each client and produces pseudo data for clients so that knowledge from the global model can be explored to enhance few-shot learning of each client model. An energy-based algorithm is further proposed to weight pseudo samples in order to reduce the negative impact of noise from the generated pseudo data. Adaptive model weights of client models are also tuned according to their performance. We use these model weights to dynamically aggregate client models to update the global model. Experiments on 118 NLP tasks show that FewFedWeight can significantly improve the performance of client models on 61% tasks with an average performance improvement rate of 30.5% over the baseline and substantially outperform FedAvg and other decentralized learning methods.
Swing Distillation: A Privacy-Preserving Knowledge Distillation Framework
Dec 16, 2022



Knowledge distillation (KD) has been widely used for model compression and knowledge transfer. Typically, a big teacher model trained on sufficient data transfers knowledge to a small student model. However, despite the success of KD, little effort has been made to study whether KD leaks the training data of the teacher model. In this paper, we experimentally reveal that KD suffers from the risk of privacy leakage. To alleviate this issue, we propose a novel knowledge distillation method, swing distillation, which can effectively protect the private information of the teacher model from flowing to the student model. In our framework, the temperature coefficient is dynamically and adaptively adjusted according to the degree of private information contained in the data, rather than a predefined constant hyperparameter. It assigns different temperatures to tokens according to the likelihood that a token in a position contains private information. In addition, we inject noise into soft targets provided to the student model, in order to avoid unshielded knowledge transfer. Experiments on multiple datasets and tasks demonstrate that the proposed swing distillation can significantly reduce (by over 80% in terms of canary exposure) the risk of privacy leakage in comparison to KD with competitive or better performance. Furthermore, swing distillation is robust against the increasing privacy budget.
NAPG: Non-Autoregressive Program Generation for Hybrid Tabular-Textual Question Answering
Nov 07, 2022



Hybrid tabular-textual question answering (QA) requires reasoning from heterogeneous information, and the types of reasoning are mainly divided into numerical reasoning and span extraction. Despite being the main challenge of the task compared to extractive QA, current numerical reasoning method simply uses LSTM to autoregressively decode program sequences, and each decoding step produces either an operator or an operand. However, the step-by-step decoding suffers from exposure bias, and the accuracy of program generation drops sharply with progressive decoding. In this paper, we propose a non-autoregressive program generation framework, which facilitates program generation in parallel. Our framework, which independently generates complete program tuples containing both operators and operands, can significantly boost the speed of program generation while addressing the error accumulation issue. Our experiments on the MultiHiertt dataset shows that our model can bring about large improvements (+7.97 EM and +6.38 F1 points) over the strong baseline, establishing the new state-of-the-art performance, while being much faster (21x) in program generation. The performance drop of our method is also significantly smaller than the baseline with increasing numbers of numerical reasoning steps.