 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-injected Prompt Learning for Chinese Biomedical Entity Normalization
Aug 23, 2023The Biomedical Entity Normalization (BEN) task aims to align raw, unstructured medical entities to standard entities, thus promoting data coherence and facilitating better downstream medical applications. Recently, prompt learning methods have shown promising results in this task. However, existing research falls short in tackling the more complex Chinese BEN task, especially in the few-shot scenario with limited medical data, and the vast potential of the external medical knowledge base has yet to be fully harnessed. To address these challenges, we propose a novel Knowledge-injected Prompt Learning (PL-Knowledge) method. Specifically, our approach consists of five stages: candidate entity matching, knowledge extraction, knowledge encoding, knowledge injection, and prediction output. By effectively encoding the knowledge items contained in medical entities and incorporating them into our tailor-made knowledge-injected templates, the additional knowledge enhances the model's ability to capture latent relationships between medical entities, thus achieving a better match with the standard entities. We extensively evaluate our model on a benchmark dataset in both few-shot and full-scale scenarios. Our method outperforms existing baselines, with an average accuracy boost of 12.96\% in few-shot and 0.94\% in full-data cases, showcasing its excellence in the BEN task.
Zhongjing: Enhancing the Chinese Medical Capabilities of Large Language Model through Expert Feedback and Real-world Multi-turn Dialogue
Aug 14, 2023Recent advances in Large Language Models (LLMs) have achieved remarkable breakthroughs in understanding and responding to user intents. However, their performance lag behind general use cases in some expertise domains, such as Chinese medicine. Existing efforts to incorporate Chinese medicine into LLMs rely on Supervised Fine-Tuning (SFT) with single-turn and distilled dialogue data. These models lack the ability for doctor-like proactive inquiry and multi-turn comprehension and cannot always align responses with safety and professionalism experts. In this work, we introduce Zhongjing, the first Chinese medical LLaMA-based LLM that implements an entire training pipeline from pre-training to reinforcement learning with human feedback (RLHF). Additionally, we introduce a Chinese multi-turn medical dialogue dataset of 70,000 authentic doctor-patient dialogues, CMtMedQA, which significantly enhances the model's capability for complex dialogue and proactive inquiry initiation. We define a refined annotation rule and evaluation criteria given the biomedical domain's unique characteristics. Results show that our model outperforms baselines in various capacities and matches the performance of ChatGPT in a few abilities, despite having 50x training data with previous best model and 100x parameters with ChatGPT. RLHF further improves the model's instruction-following ability and safety.We also release our code, datasets and model for further research.
Optimizing Deep Transformers for Chinese-Thai Low-Resource Translation
Dec 24, 2022In this paper, we study the use of deep Transformer translation model for the CCMT 2022 Chinese-Thai low-resource machine translation task. We first explore the experiment settings (including the number of BPE merge operations, dropout probability, embedding size, etc.) for the low-resource scenario with the 6-layer Transformer. Considering that increasing the number of layers also increases the regularization on new model parameters (dropout modules are also introduced when using more layers), we adopt the highest performance setting but increase the depth of the Transformer to 24 layers to obtain improved translation quality. Our work obtains the SOTA performance in the Chinese-to-Thai translation in the constrained evaluation.
NAPG: Non-Autoregressive Program Generation for Hybrid Tabular-Textual Question Answering
Nov 07, 2022



Hybrid tabular-textual question answering (QA) requires reasoning from heterogeneous information, and the types of reasoning are mainly divided into numerical reasoning and span extraction. Despite being the main challenge of the task compared to extractive QA, current numerical reasoning method simply uses LSTM to autoregressively decode program sequences, and each decoding step produces either an operator or an operand. However, the step-by-step decoding suffers from exposure bias, and the accuracy of program generation drops sharply with progressive decoding. In this paper, we propose a non-autoregressive program generation framework, which facilitates program generation in parallel. Our framework, which independently generates complete program tuples containing both operators and operands, can significantly boost the speed of program generation while addressing the error accumulation issue. Our experiments on the MultiHiertt dataset shows that our model can bring about large improvements (+7.97 EM and +6.38 F1 points) over the strong baseline, establishing the new state-of-the-art performance, while being much faster (21x) in program generation. The performance drop of our method is also significantly smaller than the baseline with increasing numbers of numerical reasoning steps.
Learning Hard Retrieval Cross Attention for Transformer
Sep 30, 2020
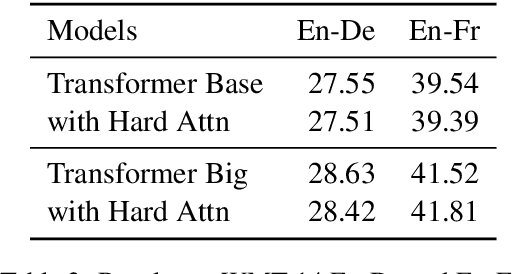
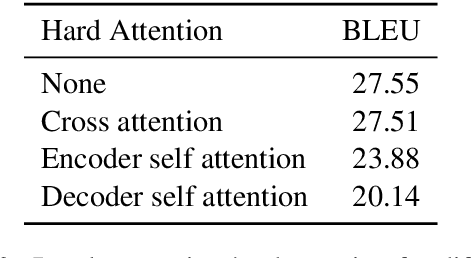
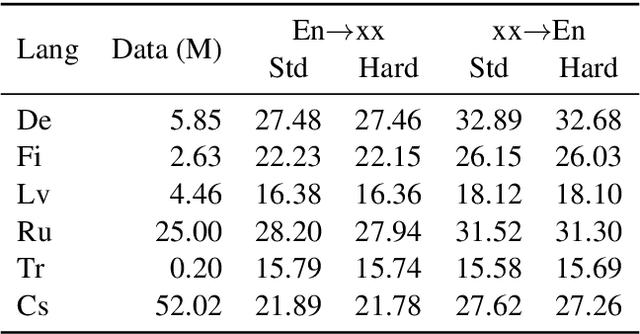
The Transformer translation model that based on the multi-head attention mechanism can be parallelized easily and lead to competitive performance in machine translation. The multi-head attention network performs the scaled dot-product attention function in parallel, empowering the model by jointly attending to information from different representation subspaces at different positions. Though its advantages in parallelization, many previous works suggest the computation of the attention mechanism is not sufficiently efficient, especially when processing long sequences, and propose approaches to improve its efficiency with long sentences. In this paper, we accelerate the inference of the scaled dot-product attention in another perspective. Specifically, instead of squeezing the sequence to attend, we simplify the computation of the scaled dot-product attention by learning a hard retrieval attention which only attends to one token in the sentence rather than all tokens. Since the hard attention mechanism only attends to one position, the matrix multiplication between attention probabilities and the value sequence in the standard scaled dot-product attention can be replaced by a simple and efficient retrieval operation. As a result, our hard retrieval attention mechanism can empirically accelerate the scaled dot-product attention for both long and short sequences by 66.5%, while performing competitively in a wide range of machine translation tasks when using for cross attention networks.
Transformer with Depth-Wise LSTM
Jul 13, 2020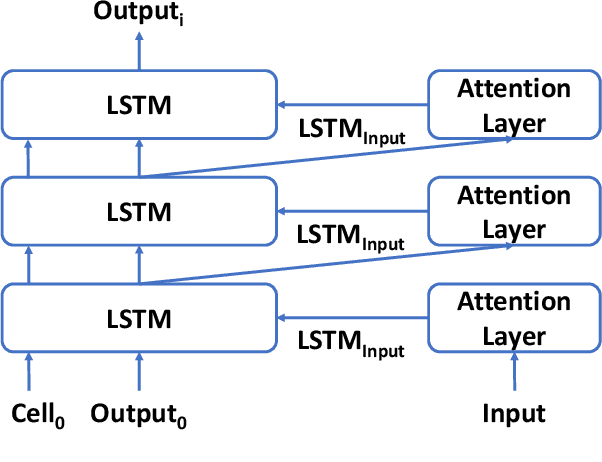
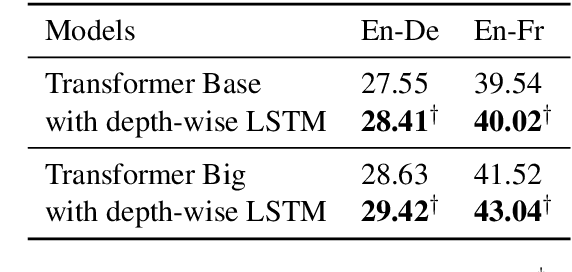
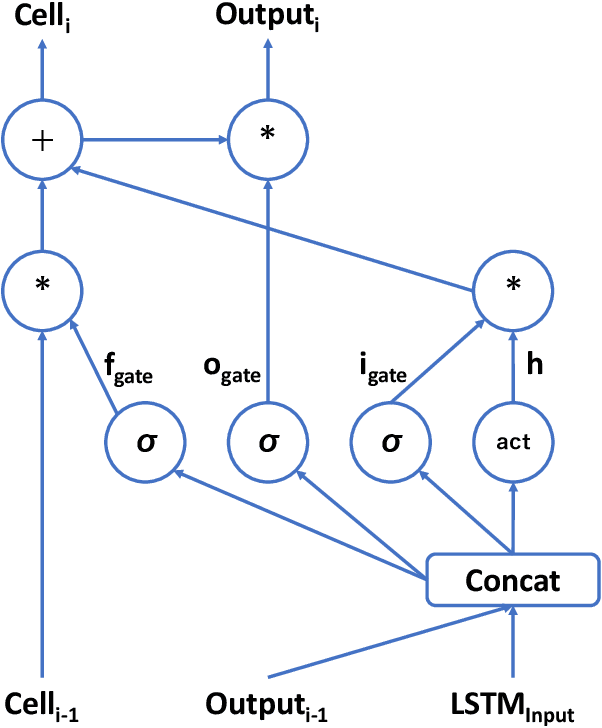

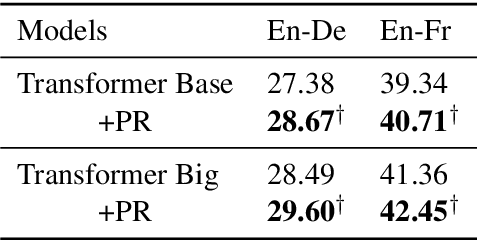
Increasing the depth of models allows neural models to model complicated functions but may also lead to optimization issues. The Transformer translation model employs the residual connection to ensure its convergence. In this paper, we suggest that the residual connection has its drawbacks, and propose to train Transformers with the depth-wise LSTM which regards outputs of layers as steps in time series instead of residual connections, under the motivation that the vanishing gradient problem suffered by deep networks is the same as recurrent networks applied to long sequences, while LSTM (Hochreiter and Schmidhuber, 1997) has been proven of good capability in capturing long-distance relationship, and its design may alleviate some drawbacks of residual connections while ensuring the convergence. We integrate the computation of multi-head attention networks and feed-forward networks with the depth-wise LSTM for the Transformer, which shows how to utilize the depth-wise LSTM like the residual connection. Our experiment with the 6-layer Transformer shows that our approach can bring about significant BLEU improvements in both WMT 14 English-German and English-French tasks, and our deep Transformer experiment demonstrates the effectiveness of the depth-wise LSTM on the convergence of deep Transformers. Additionally, we propose to measure the impacts of the layer's non-linearity on the performance by distilling the analyzing layer of the trained model into a linear transformation and observing the performance degradation with the replacement. Our analysis results support the more efficient use of per-layer non-linearity with depth-wise LSTM than with residual connections.
Learning Source Phrase Representations for Neural Machine Translation
Jun 25, 2020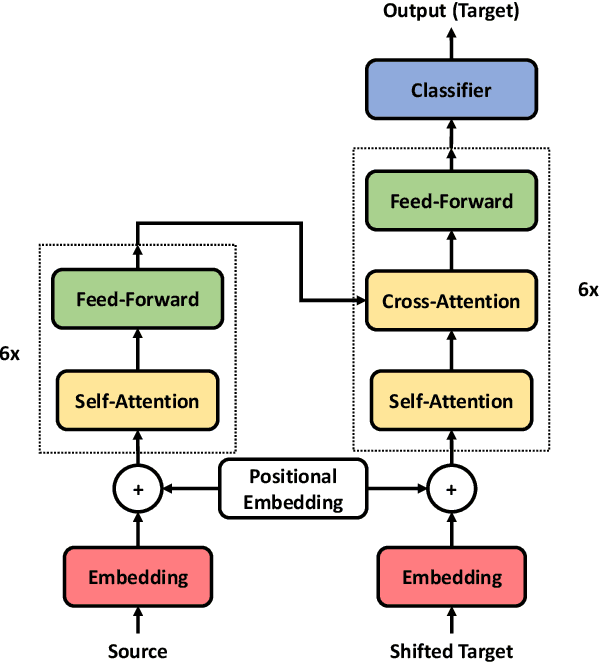
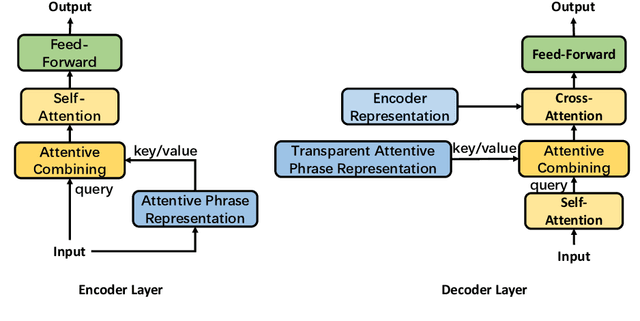
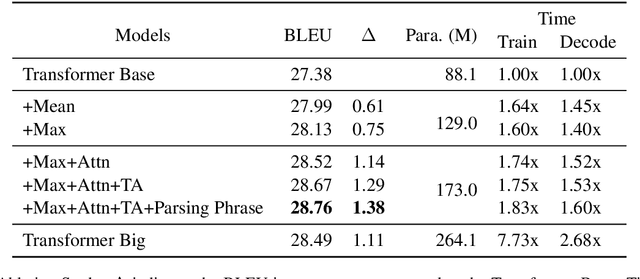
The Transformer translation model (Vaswani et al., 2017) based on a multi-head attention mechanism can be computed effectively in parallel and has significantly pushed forward the performance of Neural Machine Translation (NMT). Though intuitively the attentional network can connect distant words via shorter network paths than RNNs, empirical analysis demonstrates that it still has difficulty in fully capturing long-distance dependencies (Tang et al., 2018). Considering that modeling phrases instead of words has significantly improved the Statistical Machine Translation (SMT) approach through the use of larger translation blocks ("phrases") and its reordering ability, modeling NMT at phrase level is an intuitive proposal to help the model capture long-distance relationships. In this paper, we first propose an attentive phrase representation generation mechanism which is able to generate phrase representations from corresponding token representations. In addition, we incorporate the generated phrase representations into the Transformer translation model to enhance its ability to capture long-distance relationships. In our experiments, we obtain significant improvements on the WMT 14 English-German and English-French tasks on top of the strong Transformer baseline, which shows the effectiveness of our approach. Our approach helps Transformer Base models perform at the level of Transformer Big models, and even significantly better for long sentences, but with substantially fewer parameters and training steps. The fact that phrase representations help even in the big setting further supports our conjecture that they make a valuable contribution to long-distance relations.
Dynamically Adjusting Transformer Batch Size by Monitoring Gradient Direction Change
May 05, 2020
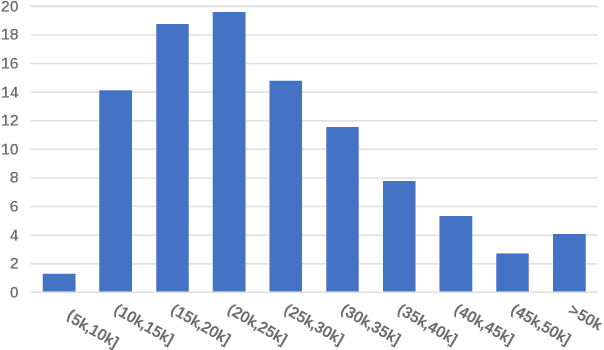
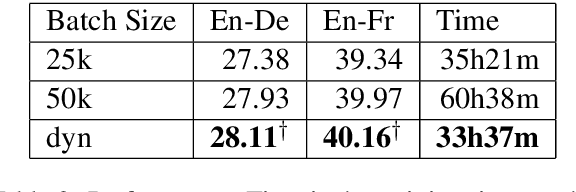
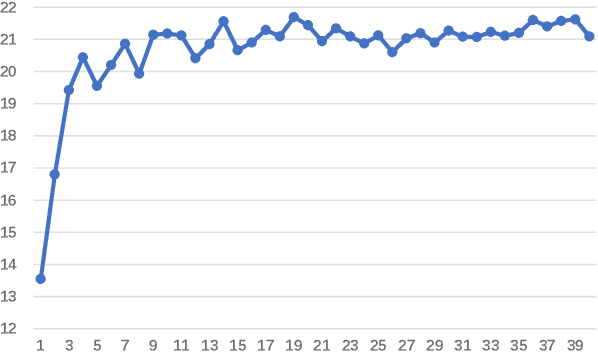
The choice of hyper-parameters affects the performance of neural models. While much previous research (Sutskever et al., 2013; Duchi et al., 2011; Kingma and Ba, 2015) focuses on accelerating convergence and reducing the effects of the learning rate, comparatively few papers concentrate on the effect of batch size. In this paper, we analyze how increasing batch size affects gradient direction, and propose to evaluate the stability of gradients with their angle change. Based on our observations, the angle change of gradient direction first tends to stabilize (i.e. gradually decrease) while accumulating mini-batches, and then starts to fluctuate. We propose to automatically and dynamically determine batch sizes by accumulating gradients of mini-batches and performing an optimization step at just the time when the direction of gradients starts to fluctuate. To improve the efficiency of our approach for large models, we propose a sampling approach to select gradients of parameters sensitive to the batch size. Our approach dynamically determines proper and efficient batch sizes during training. In our experiments on the WMT 14 English to German and English to French tasks, our approach improves the Transformer with a fixed 25k batch size by +0.73 and +0.82 BLEU respectively.
Analyzing Word Translation of Transformer Layers
Mar 21, 2020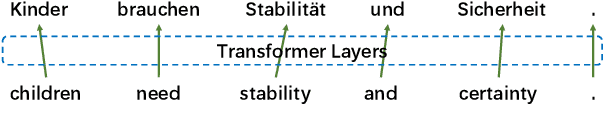
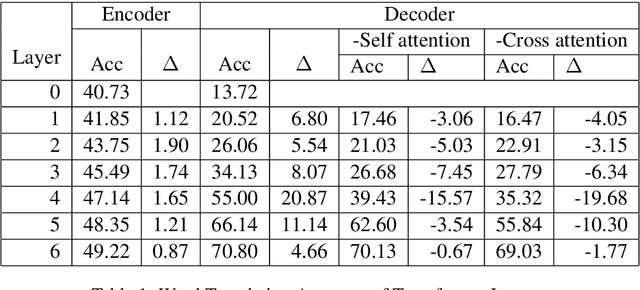
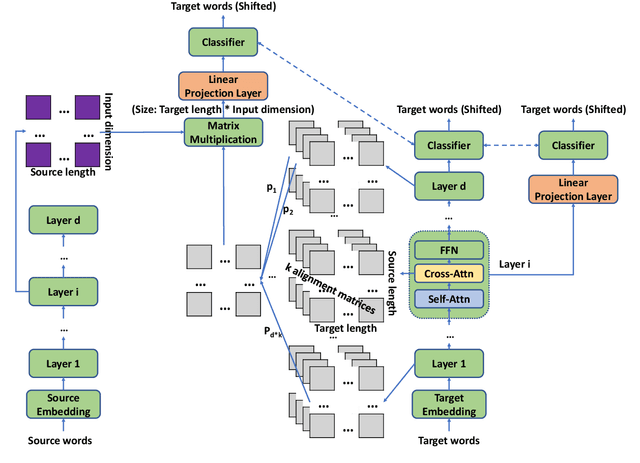
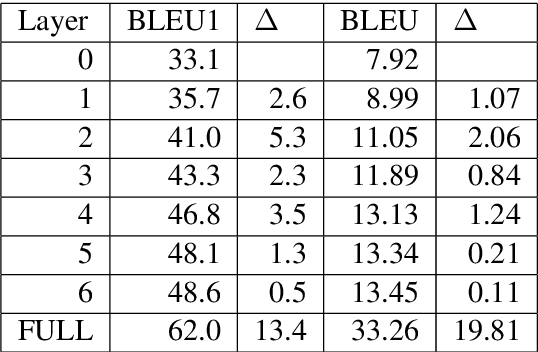
The Transformer translation model is popular for its effective parallelization and performance. Though a wide range of analysis about the Transformer has been conducted recently, the role of each Transformer layer in translation has not been studied to our knowledge. In this paper, we propose approaches to analyze the translation performed in encoder / decoder layers of the Transformer. Our approaches in general project the representations of an analyzed layer to the pre-trained classifier and measure the word translation accuracy. For the analysis of encoder layers, our approach additionally learns a weight vector to merge multiple attention matrices into one and transform the source encoding to the target side with the merged alignment matrix to align source tokens with target translations while bridging different input - output lengths. While analyzing decoder layers, we additionally study the effects of the source context and the decoding history in word prediction through bypassing the corresponding self-attention or cross-attention sub-layers. Our analysis reveals that the translation starts at the very beginning of the "encoding" (specifically at the source word embedding layer), and shows how translation evolves during the forward computation of layers. Based on observations gained in our analysis, we propose that increasing encoder depth while removing the same number of decoder layers can simply but significantly boost the decoding speed. Furthermore, simply inserting a linear projection layer before the decoder classifier which shares the weight matrix with the embedding layer can effectively provide small but consistent and significant improvements in our experiments on the WMT 14 English-German, English-French and WMT 15 Czech-English translation tasks (+0.42, +0.37 and +0.47 respectively).
Why Deep Transformers are Difficult to Converge? From Computation Order to Lipschitz Restricted Parameter Initialization
Nov 08, 2019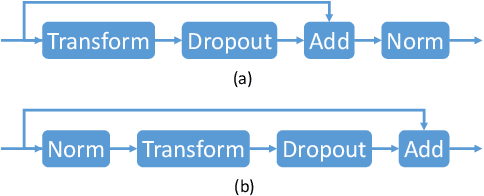
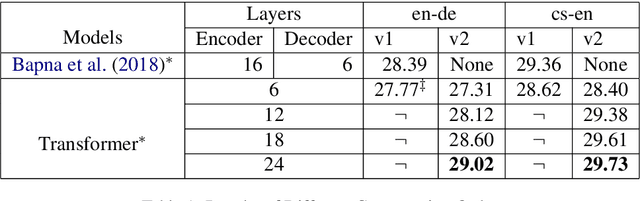

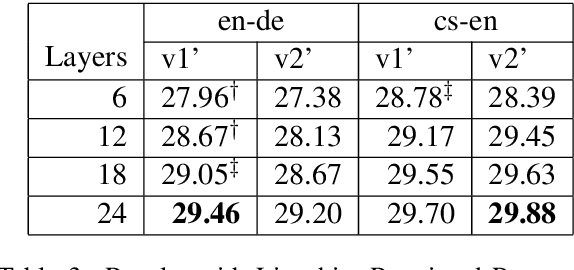
The Transformer translation model employs residual connection and layer normalization to ease the optimization difficulties caused by its multi-layer encoder/decoder structure. While several previous works show that even with residual connection and layer normalization, deep Transformers still have difficulty in training, and particularly a Transformer model with more than 12 encoder/decoder layers fails to converge. In this paper, we first empirically demonstrate that a simple modification made in the official implementation which changes the computation order of residual connection and layer normalization can effectively ease the optimization of deep Transformers. In addition, we deeply compare the subtle difference in computation order, and propose a parameter initialization method which simply puts Lipschitz restriction on the initialization of Transformers but can effectively ensure their convergence. We empirically show that with proper parameter initialization, deep Transformers with the original computation order can converge, which is quite in contrast to all previous works, and obtain significant improvements with up to 24 layers. Our proposed approach additionally enables to benefit from deep decoders compared to previous works which focus on deep encoders.