 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Pluralising Culture Alignment for Large Language Models
Oct 16, 2024As large language models (LLMs) become increasingly accessible in many countries, it is essential to align them to serve pluralistic human values across cultures. However, pluralistic culture alignment in LLMs remain an open problem. In this paper, we propose CultureSPA, a Self-Pluralising Culture Alignment framework that allows LLMs to simultaneously align to pluralistic cultures. The framework first generates questions on various culture topics, then yields LLM outputs in response to these generated questions under both culture-aware and culture-unaware settings. By comparing culture-aware/unaware outputs, we are able to detect and collect culture-related instances. These instances are employed to fine-tune LLMs to serve pluralistic cultures in either a culture-joint or culture-specific way. Extensive experiments demonstrate that CultureSPA significantly improves the alignment of LLMs to diverse cultures without compromising general abilities. And further improvements can be achieved if CultureSPA is combined with advanced prompt engineering techniques. Comparisons between culture-joint and culture-specific tuning strategies, along with variations in data quality and quantity, illustrate the robustness of our method. We also explore the mechanisms underlying CultureSPA and the relations between different cultures it reflects.
LANDeRMT: Detecting and Routing Language-Aware Neurons for Selectively Finetuning LLMs to Machine Translation
Sep 29, 2024



Recent advancements in large language models (LLMs) have shown promising results in multilingual translation even with limited bilingual supervision. The major challenges are catastrophic forgetting and parameter interference for finetuning LLMs when provided parallel training data. To address these challenges, we propose LANDeRMT, a \textbf{L}anguage-\textbf{A}ware \textbf{N}euron \textbf{De}tecting and \textbf{R}outing framework that selectively finetunes LLMs to \textbf{M}achine \textbf{T}ranslation with diverse translation training data. In LANDeRMT, we evaluate the awareness of neurons to MT tasks and categorize them into language-general and language-specific neurons. This categorization enables selective parameter updates during finetuning, mitigating parameter interference and catastrophic forgetting issues. For the detected neurons, we further propose a conditional awareness-based routing mechanism to dynamically adjust language-general and language-specific capacity within LLMs, guided by translation signals. Experimental results demonstrate that the proposed LANDeRMT is very effective in learning translation knowledge, significantly improving translation quality over various strong baselines for multiple language pairs.
Meta-RTL: Reinforcement-Based Meta-Transfer Learning for Low-Resource Commonsense Reasoning
Sep 27, 2024



Meta learning has been widely used to exploit rich-resource source tasks to improve the performance of low-resource target tasks. Unfortunately, most existing meta learning approaches treat different source tasks equally, ignoring the relatedness of source tasks to the target task in knowledge transfer. To mitigate this issue, we propose a reinforcement-based multi-source meta-transfer learning framework (Meta-RTL) for low-resource commonsense reasoning. In this framework, we present a reinforcement-based approach to dynamically estimating source task weights that measure the contribution of the corresponding tasks to the target task in the meta-transfer learning. The differences between the general loss of the meta model and task-specific losses of source-specific temporal meta models on sampled target data are fed into the policy network of the reinforcement learning module as rewards. The policy network is built upon LSTMs that capture long-term dependencies on source task weight estimation across meta learning iterations. We evaluate the proposed Meta-RTL using both BERT and ALBERT as the backbone of the meta model on three commonsense reasoning benchmark datasets. Experimental results demonstrate that Meta-RTL substantially outperforms strong baselines and previous task selection strategies and achieves larger improvements on extremely low-resource settings.
CMoralEval: A Moral Evaluation Benchmark for Chinese Large Language Models
Aug 19, 2024



What a large language model (LLM) would respond in ethically relevant context? In this paper, we curate a large benchmark CMoralEval for morality evaluation of Chinese LLMs. The data sources of CMoralEval are two-fold: 1) a Chinese TV program discussing Chinese moral norms with stories from the society and 2) a collection of Chinese moral anomies from various newspapers and academic papers on morality. With these sources, we aim to create a moral evaluation dataset characterized by diversity and authenticity. We develop a morality taxonomy and a set of fundamental moral principles that are not only rooted in traditional Chinese culture but also consistent with contemporary societal norms. To facilitate efficient construction and annotation of instances in CMoralEval, we establish a platform with AI-assisted instance generation to streamline the annotation process. These help us curate CMoralEval that encompasses both explicit moral scenarios (14,964 instances) and moral dilemma scenarios (15,424 instances), each with instances from different data sources. We conduct extensive experiments with CMoralEval to examine a variety of Chinese LLMs. Experiment results demonstrate that CMoralEval is a challenging benchmark for Chinese LLMs. The dataset is publicly available at \url{https://github.com/tjunlp-lab/CMoralEval}.
FuxiTranyu: A Multilingual Large Language Model Trained with Balanced Data
Aug 13, 2024



Large language models (LLMs) have demonstrated prowess in a wide range of tasks. However, many LLMs exhibit significant performance discrepancies between high- and low-resource languages. To mitigate this challenge, we present FuxiTranyu, an open-source multilingual LLM, which is designed to satisfy the need of the research community for balanced and high-performing multilingual capabilities. FuxiTranyu-8B, the base model with 8 billion parameters, is trained from scratch on a meticulously balanced multilingual data repository that contains 600 billion tokens covering 43 natural languages and 16 programming languages. In addition to the base model, we also develop two instruction-tuned models: FuxiTranyu-8B-SFT that is fine-tuned on a diverse multilingual instruction dataset, and FuxiTranyu-8B-DPO that is further refined with DPO on a preference dataset for enhanced alignment ability. Extensive experiments on a wide range of multilingual benchmarks demonstrate the competitive performance of FuxiTranyu against existing multilingual LLMs, e.g., BLOOM-7B, PolyLM-13B, Llama-2-Chat-7B and Mistral-7B-Instruct. Interpretability analyses at both the neuron and representation level suggest that FuxiTranyu is able to learn consistent multilingual representations across different languages. To promote further research into multilingual LLMs and their working mechanisms, we release both the base and instruction-tuned FuxiTranyu models together with 58 pretraining checkpoints at HuggingFace and Github.
Towards Understanding Multi-Task Learning (Generalization) of LLMs via Detecting and Exploring Task-Specific Neurons
Jul 09, 2024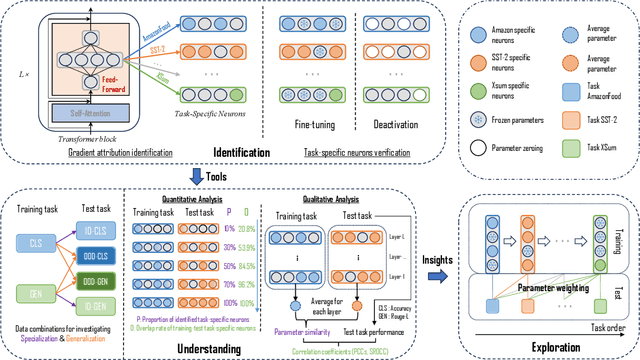
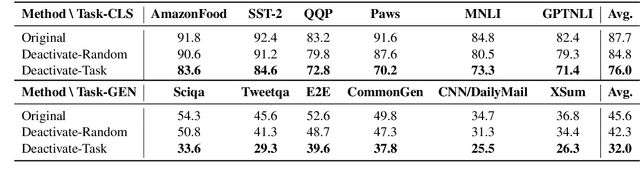
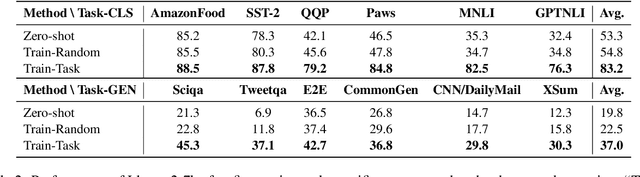
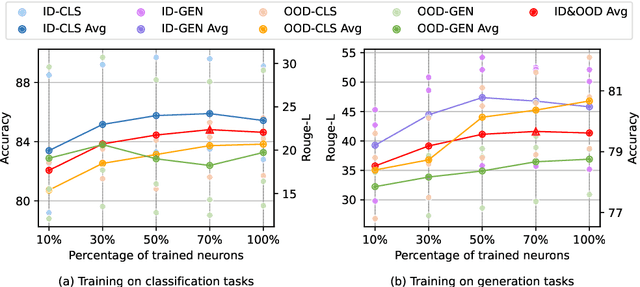
While large language models (LLMs) have demonstrated superior multi-task capabilities, understanding the learning mechanisms behind this is still a challenging problem. In this paper, we attempt to understand such mechanisms from the perspective of neurons. Specifically, we detect task-sensitive neurons in LLMs via gradient attribution on task-specific data. Through extensive deactivation and fine-tuning experiments, we demonstrate that the detected neurons are highly correlated with the given task, which we term as task-specific neurons. With these identified task-specific neurons, we delve into two common problems in multi-task learning and continuous learning: Generalization and Catastrophic Forgetting. We find that the overlap of task-specific neurons is strongly associated with generalization and specialization across tasks. Interestingly, at certain layers of LLMs, there is a high similarity in the parameters of different task-specific neurons, and such similarity is highly correlated with the generalization performance. Inspired by these findings, we propose a neuron-level continuous fine-tuning method that only fine-tunes the current task-specific neurons during continuous learning, and extensive experiments demonstrate the effectiveness of the proposed method. Our study provides insights into the interpretability of LLMs in multi-task learning.
DART: Deep Adversarial Automated Red Teaming for LLM Safety
Jul 04, 2024



Manual Red teaming is a commonly-used method to identify vulnerabilities in large language models (LLMs), which, is costly and unscalable. In contrast, automated red teaming uses a Red LLM to automatically generate adversarial prompts to the Target LLM, offering a scalable way for safety vulnerability detection. However, the difficulty of building a powerful automated Red LLM lies in the fact that the safety vulnerabilities of the Target LLM are dynamically changing with the evolution of the Target LLM. To mitigate this issue, we propose a Deep Adversarial Automated Red Teaming (DART) framework in which the Red LLM and Target LLM are deeply and dynamically interacting with each other in an iterative manner. In each iteration, in order to generate successful attacks as many as possible, the Red LLM not only takes into account the responses from the Target LLM, but also adversarially adjust its attacking directions by monitoring the global diversity of generated attacks across multiple iterations. Simultaneously, to explore dynamically changing safety vulnerabilities of the Target LLM, we allow the Target LLM to enhance its safety via an active learning based data selection mechanism. Experimential results demonstrate that DART significantly reduces the safety risk of the target LLM. For human evaluation on Anthropic Harmless dataset, compared to the instruction-tuning target LLM, DART eliminates the violation risks by 53.4\%. We will release the datasets and codes of DART soon.
Planning with Large Language Models for Conversational Agents
Jul 04, 2024Controllability and proactivity are crucial properties of autonomous conversational agents (CAs). Controllability requires the CAs to follow the standard operating procedures (SOPs), such as verifying identity before activating credit cards. Proactivity requires the CAs to guide the conversation towards the goal during user uncooperation, such as persuasive dialogue. Existing research cannot be unified with controllability, proactivity, and low manual annotation. To bridge this gap, we propose a new framework for planning-based conversational agents (PCA) powered by large language models (LLMs), which only requires humans to define tasks and goals for the LLMs. Before conversation, LLM plans the core and necessary SOP for dialogue offline. During the conversation, LLM plans the best action path online referring to the SOP, and generates responses to achieve process controllability. Subsequently, we propose a semi-automatic dialogue data creation framework and curate a high-quality dialogue dataset (PCA-D). Meanwhile, we develop multiple variants and evaluation metrics for PCA, e.g., planning with Monte Carlo Tree Search (PCA-M), which searches for the optimal dialogue action while satisfying SOP constraints and achieving the proactive of the dialogue. Experiment results show that LLMs finetuned on PCA-D can significantly improve the performance and generalize to unseen domains. PCA-M outperforms other CoT and ToT baselines in terms of conversation controllability, proactivity, task success rate, and overall logical coherence, and is applicable in industry dialogue scenarios. The dataset and codes are available at XXXX.
IRCAN: Mitigating Knowledge Conflicts in LLM Generation via Identifying and Reweighting Context-Aware Neurons
Jun 26, 2024



It is widely acknowledged that large language models (LLMs) encode a vast reservoir of knowledge after being trained on mass data. Recent studies disclose knowledge conflicts in LLM generation, wherein outdated or incorrect parametric knowledge (i.e., encoded knowledge) contradicts new knowledge provided in the context. To mitigate such knowledge conflicts, we propose a novel framework, IRCAN (Identifying and Reweighting Context-Aware Neurons) to capitalize on neurons that are crucial in processing contextual cues. Specifically, IRCAN first identifies neurons that significantly contribute to context processing, utilizing a context-aware attribution score derived from integrated gradients. Subsequently, the identified context-aware neurons are strengthened via reweighting. In doing so, we steer LLMs to generate context-sensitive outputs with respect to the new knowledge provided in the context. Extensive experiments conducted across a variety of models and tasks demonstrate that IRCAN not only achieves remarkable improvements in handling knowledge conflicts but also offers a scalable, plug-andplay solution that can be integrated seamlessly with existing models.
MoE-CT: A Novel Approach For Large Language Models Training With Resistance To Catastrophic Forgetting
Jun 25, 2024



The advent of large language models (LLMs) has predominantly catered to high-resource languages, leaving a disparity in performance for low-resource languages. Conventional Continual Training (CT) approaches to bridge this gap often undermine a model's original linguistic proficiency when expanding to multilingual contexts. Addressing this issue, we introduce a novel MoE-CT architecture, a paradigm that innovatively separates the base model's learning from the multilingual expansion process. Our design freezes the original LLM parameters, thus safeguarding its performance in high-resource languages, while an appended MoE module, trained on diverse language datasets, augments low-resource language proficiency. Our approach significantly outperforms conventional CT methods, as evidenced by our experiments, which show marked improvements in multilingual benchmarks without sacrificing the model's original language performance. Moreover, our MoE-CT framework demonstrates enhanced resistance to forgetting and superior transfer learning capabilities. By preserving the base model's integrity and focusing on strategic parameter expansion, our methodology advances multilingual language modeling and represents a significant step forward for low-resource language inclusion in LLMs, indicating a fruitful direction for future research in language technologies.