 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeather-Conditioned Branch Routing for Robust LiDAR-Radar 3D Object Detection
Apr 07, 2026Robust 3D object detection in adverse weather is highly challenging due to the varying reliability of different sensors. While existing LiDAR-4D radar fusion methods improve robustness, they predominantly rely on fixed or weakly adaptive pipelines, failing to dy-namically adjust modality preferences as environmental conditions change. To bridge this gap, we reformulate multi-modal perception as a weather-conditioned branch routing problem. Instead of computing a single fused output, our framework explicitly maintains three parallel 3D feature streams: a pure LiDAR branch, a pure 4D radar branch, and a condition-gated fusion branch. Guided by a condition token extracted from visual and semantic prompts, a lightweight router dynamically predicts sample-specific weights to softly aggregate these representations. Furthermore, to prevent branch collapse, we introduce a weather-supervised learning strategy with auxiliary classification and diversity regularization to enforce distinct, condition-dependent routing behaviors. Extensive experiments on the K-Radar benchmark demonstrate that our method achieves state-of-the-art performance. Furthermore, it provides explicit and highly interpretable insights into modality preferences, transparently revealing how adaptive routing robustly shifts reliance between LiDAR and 4D radar across diverse adverse-weather scenarios. The source code with be released.
Critique Before Thinking: Mitigating Hallucination through Rationale-Augmented Instruction Tuning
May 12, 2025Despite significant advancements in multimodal reasoning tasks, existing Large Vision-Language Models (LVLMs) are prone to producing visually ungrounded responses when interpreting associated images. In contrast, when humans embark on learning new knowledge, they often rely on a set of fundamental pre-study principles: reviewing outlines to grasp core concepts, summarizing key points to guide their focus and enhance understanding. However, such preparatory actions are notably absent in the current instruction tuning processes. This paper presents Re-Critic, an easily scalable rationale-augmented framework designed to incorporate fundamental rules and chain-of-thought (CoT) as a bridge to enhance reasoning abilities. Specifically, Re-Critic develops a visual rationale synthesizer that scalably augments raw instructions with rationale explanation. To probe more contextually grounded responses, Re-Critic employs an in-context self-critic mechanism to select response pairs for preference tuning. Experiments demonstrate that models fine-tuned with our rationale-augmented dataset yield gains that extend beyond hallucination-specific tasks to broader multimodal reasoning tasks.
Joint Plasticity Learning for Camera Incremental Person Re-Identification
Oct 18, 2022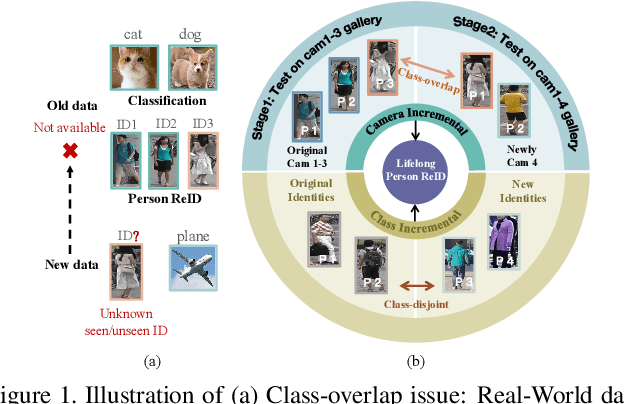

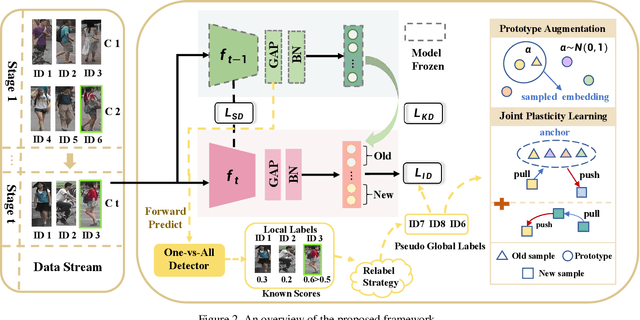
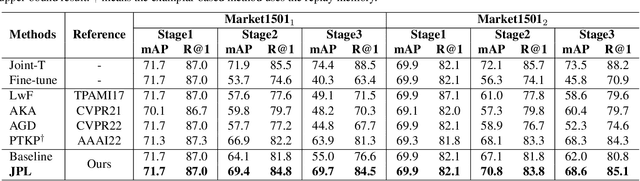
Recently, incremental learning for person re-identification receives increasing attention, which is considered a more practical setting in real-world applications. However, the existing works make the strong assumption that the cameras are fixed and the new-emerging data is class-disjoint from previous classes. In this paper, we focus on a new and more practical task, namely Camera Incremental person ReID (CIP-ReID). CIP-ReID requires ReID models to continuously learn informative representations without forgetting the previously learned ones only through the data from newly installed cameras. This is challenging as the new data only have local supervision in new cameras with no access to the old data due to privacy issues, and they may also contain persons seen by previous cameras. To address this problem, we propose a non-exemplar-based framework, named JPL-ReID. JPL-ReID first adopts a one-vs-all detector to discover persons who have been presented in previous cameras. To maintain learned representations, JPL-ReID utilizes a similarity distillation strategy with no previous training data available. Simultaneously, JPL-ReID is capable of learning new knowledge to improve the generalization ability using a Joint Plasticity Learning objective. The comprehensive experimental results on two datasets demonstrate that our proposed method significantly outperforms the comparative methods and can achieve state-of-the-art results with remarkable advantages.