 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOAM-TCD: A globally diverse dataset of high-resolution tree cover maps
Jul 16, 2024Accurately quantifying tree cover is an important metric for ecosystem monitoring and for assessing progress in restored sites. Recent works have shown that deep learning-based segmentation algorithms are capable of accurately mapping trees at country and continental scales using high-resolution aerial and satellite imagery. Mapping at high (ideally sub-meter) resolution is necessary to identify individual trees, however there are few open-access datasets containing instance level annotations and those that exist are small or not geographically diverse. We present a novel open-access dataset for individual tree crown delineation (TCD) in high-resolution aerial imagery sourced from OpenAerialMap (OAM). Our dataset, OAM-TCD, comprises 5072 2048x2048 px images at 10 cm/px resolution with associated human-labeled instance masks for over 280k individual and 56k groups of trees. By sampling imagery from around the world, we are able to better capture the diversity and morphology of trees in different terrestrial biomes and in both urban and natural environments. Using our dataset, we train reference instance and semantic segmentation models that compare favorably to existing state-of-the-art models. We assess performance through k-fold cross-validation and comparison with existing datasets; additionally we demonstrate compelling results on independent aerial imagery captured over Switzerland and compare to municipal tree inventories and LIDAR-derived canopy maps in the city of Zurich. Our dataset, models and training/benchmark code are publicly released under permissive open-source licenses: Creative Commons (majority CC BY 4.0), and Apache 2.0 respectively.
GEO-Bench: Toward Foundation Models for Earth Monitoring
Jun 06, 2023



Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing. Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited. To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models. We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.
Data Debugging with Shapley Importance over End-to-End Machine Learning Pipelines
Apr 26, 2022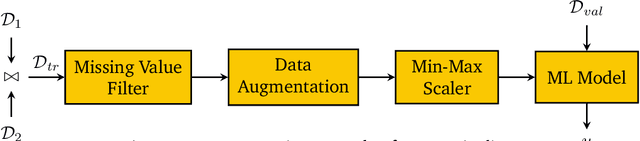
Developing modern machine learning (ML) applications is data-centric, of which one fundamental challenge is to understand the influence of data quality to ML training -- "Which training examples are 'guilty' in making the trained ML model predictions inaccurate or unfair?" Modeling data influence for ML training has attracted intensive interest over the last decade, and one popular framework is to compute the Shapley value of each training example with respect to utilities such as validation accuracy and fairness of the trained ML model. Unfortunately, despite recent intensive interest and research, existing methods only consider a single ML model "in isolation" and do not consider an end-to-end ML pipeline that consists of data transformations, feature extractors, and ML training. We present DataScope (ease.ml/datascope), the first system that efficiently computes Shapley values of training examples over an end-to-end ML pipeline, and illustrate its applications in data debugging for ML training. To this end, we first develop a novel algorithmic framework that computes Shapley value over a specific family of ML pipelines that we call canonical pipelines: a positive relational algebra query followed by a K-nearest-neighbor (KNN) classifier. We show that, for many subfamilies of canonical pipelines, computing Shapley value is in PTIME, contrasting the exponential complexity of computing Shapley value in general. We then put this to practice -- given an sklearn pipeline, we approximate it with a canonical pipeline to use as a proxy. We conduct extensive experiments illustrating different use cases and utilities. Our results show that DataScope is up to four orders of magnitude faster over state-of-the-art Monte Carlo-based methods, while being comparably, and often even more, effective in data debugging.
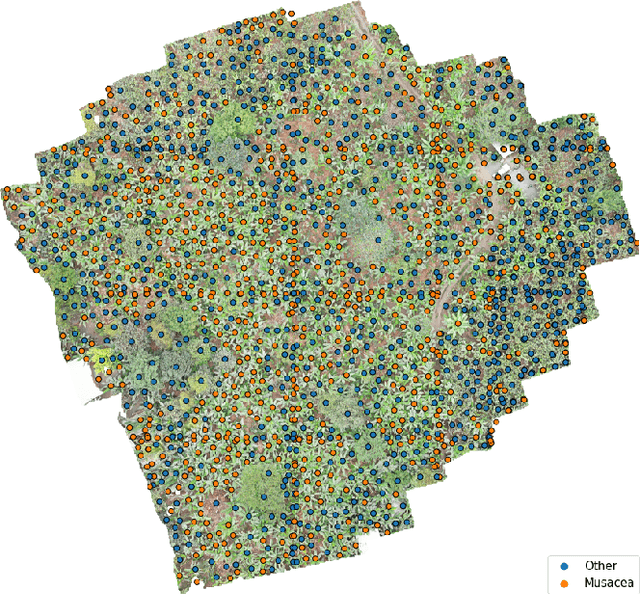
ReforesTree: A Dataset for Estimating Tropical Forest Carbon Stock with Deep Learning and Aerial Imagery
Jan 26, 2022
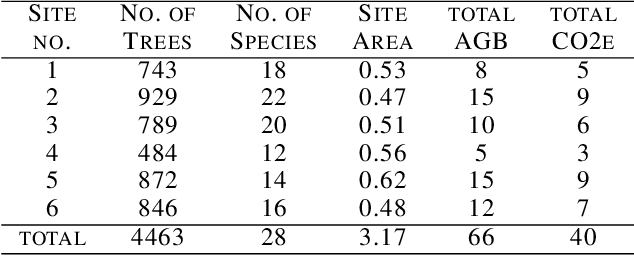
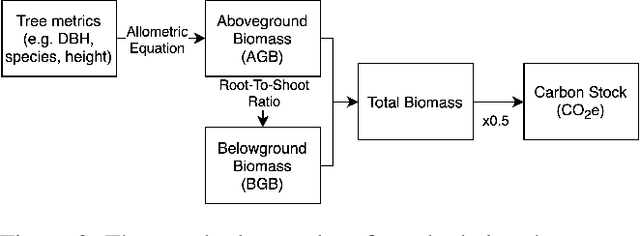
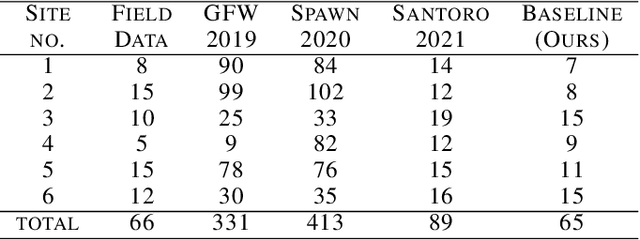
Forest biomass is a key influence for future climate, and the world urgently needs highly scalable financing schemes, such as carbon offsetting certifications, to protect and restore forests. Current manual forest carbon stock inventory methods of measuring single trees by hand are time, labour, and cost-intensive and have been shown to be subjective. They can lead to substantial overestimation of the carbon stock and ultimately distrust in forest financing. The potential for impact and scale of leveraging advancements in machine learning and remote sensing technologies is promising but needs to be of high quality in order to replace the current forest stock protocols for certifications. In this paper, we present ReforesTree, a benchmark dataset of forest carbon stock in six agro-forestry carbon offsetting sites in Ecuador. Furthermore, we show that a deep learning-based end-to-end model using individual tree detection from low cost RGB-only drone imagery is accurately estimating forest carbon stock within official carbon offsetting certification standards. Additionally, our baseline CNN model outperforms state-of-the-art satellite-based forest biomass and carbon stock estimates for this type of small-scale, tropical agro-forestry sites. We present this dataset to encourage machine learning research in this area to increase accountability and transparency of monitoring, verification and reporting (MVR) in carbon offsetting projects, as well as scaling global reforestation financing through accurate remote sensing.
Toward Foundation Models for Earth Monitoring: Proposal for a Climate Change Benchmark
Dec 01, 2021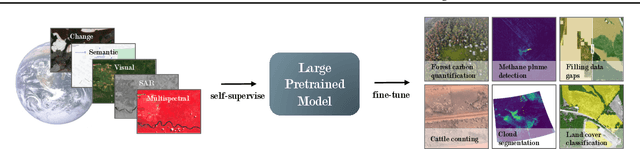
Recent progress in self-supervision shows that pre-training large neural networks on vast amounts of unsupervised data can lead to impressive increases in generalisation for downstream tasks. Such models, recently coined as foundation models, have been transformational to the field of natural language processing. While similar models have also been trained on large corpuses of images, they are not well suited for remote sensing data. To stimulate the development of foundation models for Earth monitoring, we propose to develop a new benchmark comprised of a variety of downstream tasks related to climate change. We believe that this can lead to substantial improvements in many existing applications and facilitate the development of new applications. This proposal is also a call for collaboration with the aim of developing a better evaluation process to mitigate potential downsides of foundation models for Earth monitoring.
Tackling the Overestimation of Forest Carbon with Deep Learning and Aerial Imagery
Aug 19, 2021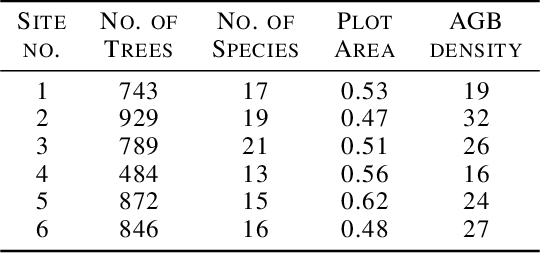
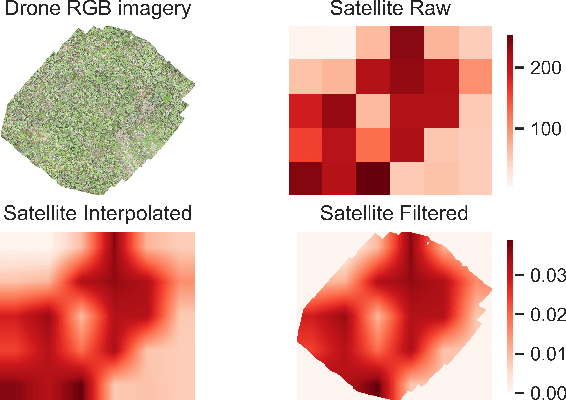
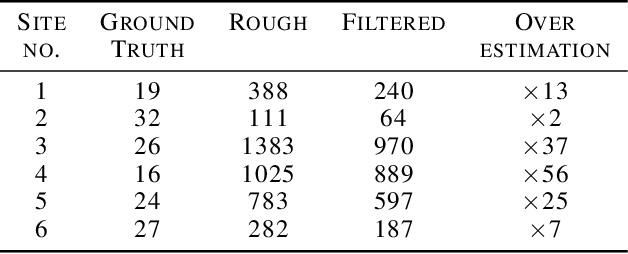
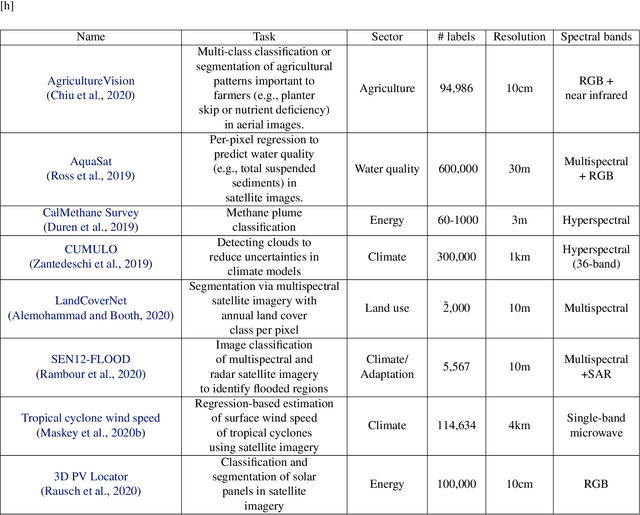
Forest carbon offsets are increasingly popular and can play a significant role in financing climate mitigation, forest conservation, and reforestation. Measuring how much carbon is stored in forests is, however, still largely done via expensive, time-consuming, and sometimes unaccountable field measurements. To overcome these limitations, many verification bodies are leveraging machine learning (ML) algorithms to estimate forest carbon from satellite or aerial imagery. Aerial imagery allows for tree species or family classification, which improves the satellite imagery-based forest type classification. However, aerial imagery is significantly more expensive to collect and it is unclear by how much the higher resolution improves the forest carbon estimation. This proposal paper describes the first systematic comparison of forest carbon estimation from aerial imagery, satellite imagery, and ground-truth field measurements via deep learning-based algorithms for a tropical reforestation project. Our initial results show that forest carbon estimates from satellite imagery can overestimate above-ground biomass by up to 10-times for tropical reforestation projects. The significant difference between aerial and satellite-derived forest carbon measurements shows the potential for aerial imagery-based ML algorithms and raises the importance to extend this study to a global benchmark between options for carbon measurements.
TrueBranch: Metric Learning-based Verification of Forest Conservation Projects
Apr 21, 2020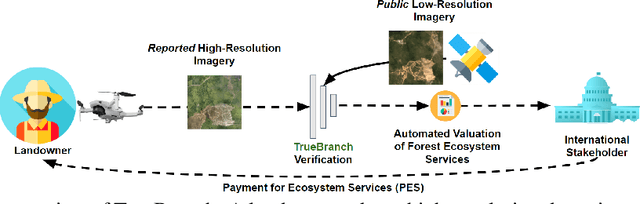
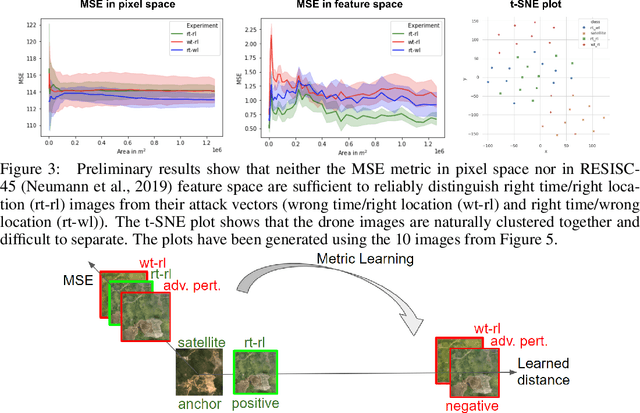

International stakeholders increasingly invest in offsetting carbon emissions, for example, via issuing Payments for Ecosystem Services (PES) to forest conservation projects. Issuing trusted payments requires a transparent monitoring, reporting, and verification (MRV) process of the ecosystem services (e.g., carbon stored in forests). The current MRV process, however, is either too expensive (on-ground inspection of forest) or inaccurate (satellite). Recent works propose low-cost and accurate MRV via automatically determining forest carbon from drone imagery, collected by the landowners. The automation of MRV, however, opens up the possibility that landowners report untruthful drone imagery. To be robust against untruthful reporting, we propose TrueBranch, a metric learning-based algorithm that verifies the truthfulness of drone imagery from forest conservation projects. TrueBranch aims to detect untruthfully reported drone imagery by matching it with public satellite imagery. Preliminary results suggest that nominal distance metrics are not sufficient to reliably detect untruthfully reported imagery. TrueBranch leverages metric learning to create a feature embedding in which truthfully and untruthfully collected imagery is easily distinguishable by distance thresholding.
Efficient Task-Specific Data Valuation for Nearest Neighbor Algorithms
Sep 11, 2019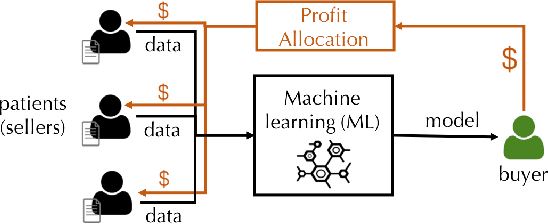

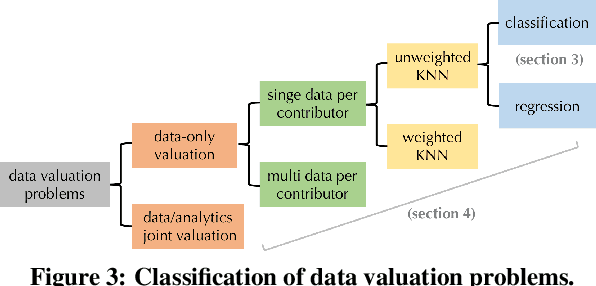

Given a data set $\mathcal{D}$ containing millions of data points and a data consumer who is willing to pay for \$$X$ to train a machine learning (ML) model over $\mathcal{D}$, how should we distribute this \$$X$ to each data point to reflect its "value"? In this paper, we define the "relative value of data" via the Shapley value, as it uniquely possesses properties with appealing real-world interpretations, such as fairness, rationality and decentralizability. For general, bounded utility functions, the Shapley value is known to be challenging to compute: to get Shapley values for all $N$ data points, it requires $O(2^N)$ model evaluations for exact computation and $O(N\log N)$ for $(\epsilon, \delta)$-approximation. In this paper, we focus on one popular family of ML models relying on $K$-nearest neighbors ($K$NN). The most surprising result is that for unweighted $K$NN classifiers and regressors, the Shapley value of all $N$ data points can be computed, exactly, in $O(N\log N)$ time -- an exponential improvement on computational complexity! Moreover, for $(\epsilon, \delta)$-approximation, we are able to develop an algorithm based on Locality Sensitive Hashing (LSH) with only sublinear complexity $O(N^{h(\epsilon,K)}\log N)$ when $\epsilon$ is not too small and $K$ is not too large. We empirically evaluate our algorithms on up to $10$ million data points and even our exact algorithm is up to three orders of magnitude faster than the baseline approximation algorithm. The LSH-based approximation algorithm can accelerate the value calculation process even further. We then extend our algorithms to other scenarios such as (1) weighed $K$NN classifiers, (2) different data points are clustered by different data curators, and (3) there are data analysts providing computation who also requires proper valuation.
Towards Efficient Data Valuation Based on the Shapley Value
Feb 27, 2019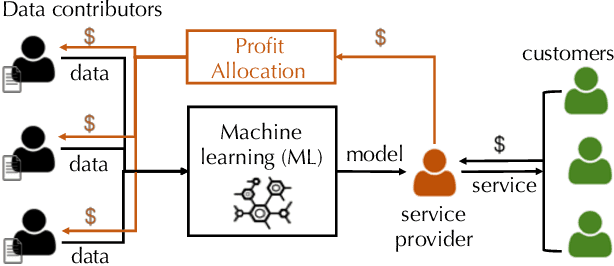

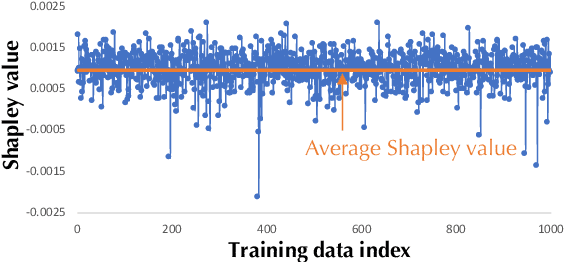
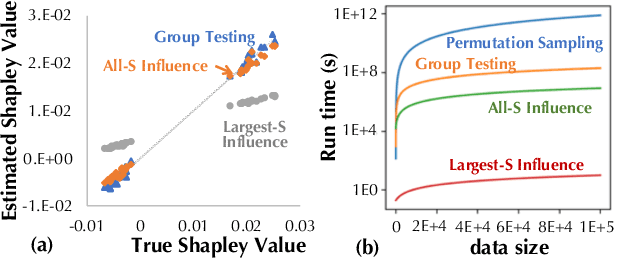
"How much is my data worth?" is an increasingly common question posed by organizations and individuals alike. An answer to this question could allow, for instance, fairly distributing profits among multiple data contributors and determining prospective compensation when data breaches happen. In this paper, we study the problem of data valuation by utilizing the Shapley value, a popular notion of value which originated in coopoerative game theory. The Shapley value defines a unique payoff scheme that satisfies many desiderata for the notion of data value. However, the Shapley value often requires exponential time to compute. To meet this challenge, we propose a repertoire of efficient algorithms for approximating the Shapley value. We also demonstrate the value of each training instance for various benchmark datasets.
DataBright: Towards a Global Exchange for Decentralized Data Ownership and Trusted Computation
Feb 13, 2018It is safe to assume that, for the foreseeable future, machine learning, especially deep learning will remain both data- and computation-hungry. In this paper, we ask: Can we build a global exchange where everyone can contribute computation and data to train the next generation of machine learning applications? We present an early, but running prototype of DataBright, a system that turns the creation of training examples and the sharing of computation into an investment mechanism. Unlike most crowdsourcing platforms, where the contributor gets paid when they submit their data, DataBright pays dividends whenever a contributor's data or hardware is used by someone to train a machine learning model. The contributor becomes a shareholder in the dataset they created. To enable the measurement of usage, a computation platform that contributors can trust is also necessary. DataBright thus merges both a data market and a trusted computation market. We illustrate that trusted computation can enable the creation of an AI market, where each data point has an exact value that should be paid to its creator. DataBright allows data creators to retain ownership of their contribution and attaches to it a measurable value. The value of the data is given by its utility in subsequent distributed computation done on the DataBright computation market. The computation market allocates tasks and subsequent payments to pooled hardware. This leads to the creation of a decentralized AI cloud. Our experiments show that trusted hardware such as Intel SGX can be added to the usual ML pipeline with no additional costs. We use this setting to orchestrate distributed computation that enables the creation of a computation market. DataBright is available for download at https://github.com/ds3lab/databright.