 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTQuant: Spatio-Temporal Adaptive Framework for Optimizer Quantization in Large Multimodal Model Training
Apr 09, 2026Quantization is an effective way to reduce the memory cost of large-scale model training. However, most existing methods adopt fixed-precision policies, which ignore the fact that optimizer-state distributions vary significantly across layers and training steps. Such uniform designs often introduce noticeable accuracy degradation. To move beyond fixed quantization, we propose STQuant, a distributed training framework that reduces the memory footprint of optimizer states via dynamic precision allocation across layers, state variables, and training steps, while maintaining model quality. Naively applying dynamic quantization during training is challenging for two reasons. First, optimizer states are numerically sensitive, and quantization noise can destabilize quality. Second, jointly considering multiple states and layers induces a large combinatorial search space. STQuant addresses these challenges with two key techniques: 1) a provably near-optimal factor selection strategy that accurately identifies the most influential factors for precision adaptation. 2) a dynamic transition decision algorithm that reduces the search cost from exponential to linear complexity. Experiments on GPT-2 and ViT show that STQuant reduces optimizer-state memory by 84.4%, achieving an average bit-width of as low as 5.1 bits, compared with existing solutions. Moreover, STQuant incurs only O(N/K) computational overhead and requires O(1) extra space.
Efficient and Principled Scientific Discovery through Bayesian Optimization: A Tutorial
Apr 01, 2026Traditional scientific discovery relies on an iterative hypothesise-experiment-refine cycle that has driven progress for centuries, but its intuitive, ad-hoc implementation often wastes resources, yields inefficient designs, and misses critical insights. This tutorial presents Bayesian Optimisation (BO), a principled probability-driven framework that formalises and automates this core scientific cycle. BO uses surrogate models (e.g., Gaussian processes) to model empirical observations as evolving hypotheses, and acquisition functions to guide experiment selection, balancing exploitation of known knowledge and exploration of uncharted domains to eliminate guesswork and manual trial-and-error. We first frame scientific discovery as an optimisation problem, then unpack BO's core components, end-to-end workflows, and real-world efficacy via case studies in catalysis, materials science, organic synthesis, and molecule discovery. We also cover critical technical extensions for scientific applications, including batched experimentation, heteroscedasticity, contextual optimisation, and human-in-the-loop integration. Tailored for a broad audience, this tutorial bridges AI advances in BO with practical natural science applications, offering tiered content to empower cross-disciplinary researchers to design more efficient experiments and accelerate principled scientific discovery.
Dynamical Mode Recognition of Turbulent Flames in a Swirl-stabilized Annular Combustor by a Time-series Learning Approach
Mar 17, 2025Thermoacoustic instability in annular combustors, essential to aero engines and modern gas turbines, can severely impair operational stability and efficiency, accurately recognizing and understanding various combustion modes is the prerequisite for understanding and controlling combustion instabilities. However, the high-dimensional spatial-temporal dynamics of turbulent flames typically pose considerable challenges to mode recognition. Based on the bidirectional temporal and nonlinear dimensionality reduction models, this study introduces a two-layer bidirectional long short-term memory variational autoencoder, Bi-LSTM-VAE model, to effectively recognize dynamical modes in annular combustion systems. Specifically, leveraging 16 pressure signals from a swirl-stabilized annular combustor, the model maps complex dynamics into a low-dimensional latent space while preserving temporal dependency and nonlinear behavior features through the recurrent neural network structure. The results show that the novel Bi-LSTM-VAE method enables a clear representation of combustion states in two-dimensional state space. Analysis of latent variable distributions reveals distinct patterns corresponding to a wide range of equivalence ratios and premixed fuel and air mass flow rates, offering novel insights into mode classification and transitions, highlighting this model's potential for deciphering complex thermoacoustic phenomena.
TOPS: Transition-based VOlatility-controlled Policy Search and its Global Convergence
Jan 24, 2022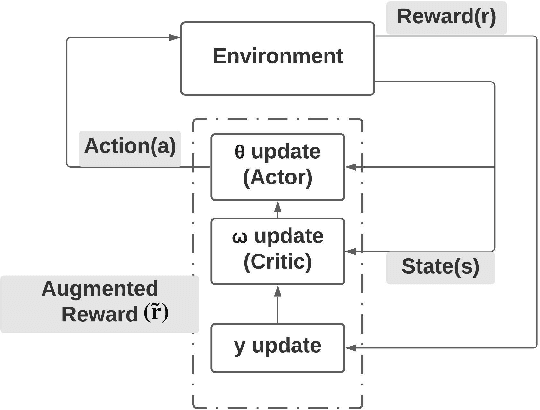
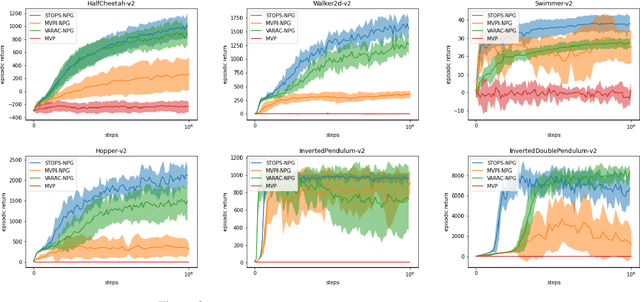
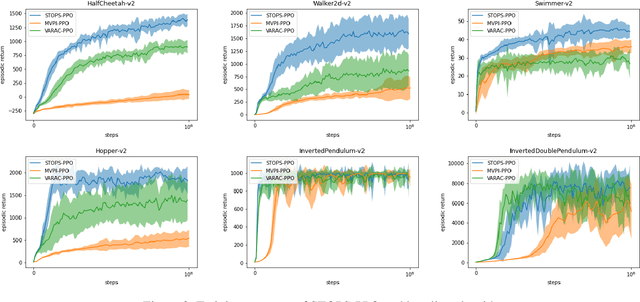
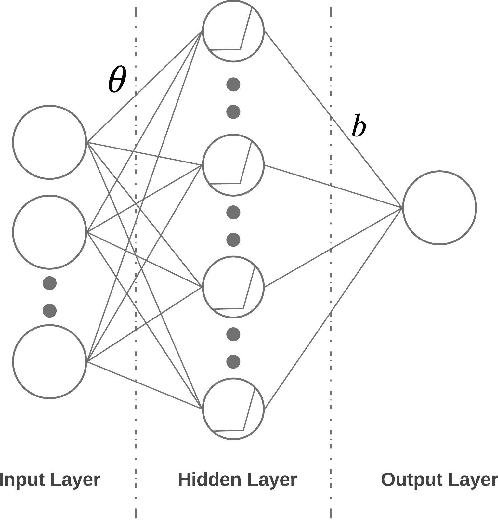
Risk-averse problems receive far less attention than risk-neutral control problems in reinforcement learning, and existing risk-averse approaches are challenging to deploy to real-world applications. One primary reason is that such risk-averse algorithms often learn from consecutive trajectories with a certain length, which significantly increases the potential danger of causing dangerous failures in practice. This paper proposes Transition-based VOlatility-controlled Policy Search (TOPS), a novel algorithm that solves risk-averse problems by learning from (possibly non-consecutive) transitions instead of only consecutive trajectories. By using an actor-critic scheme with an overparameterized two-layer neural network, our algorithm finds a globally optimal policy at a sublinear rate with proximal policy optimization and natural policy gradient, with effectiveness comparable to the state-of-the-art convergence rate of risk-neutral policy-search methods. The algorithm is evaluated on challenging Mujoco robot simulation tasks under the mean-variance evaluation metric. Both theoretical analysis and experimental results demonstrate a state-of-the-art level of risk-averse policy search methods.