 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable and Efficient Policy Evaluation
Jun 06, 2020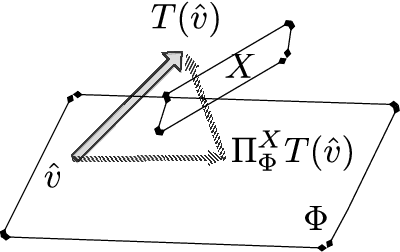
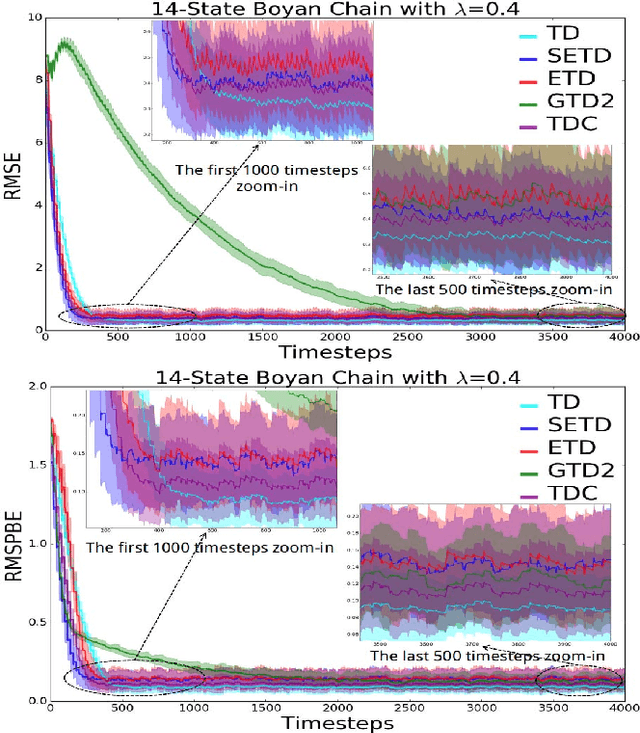
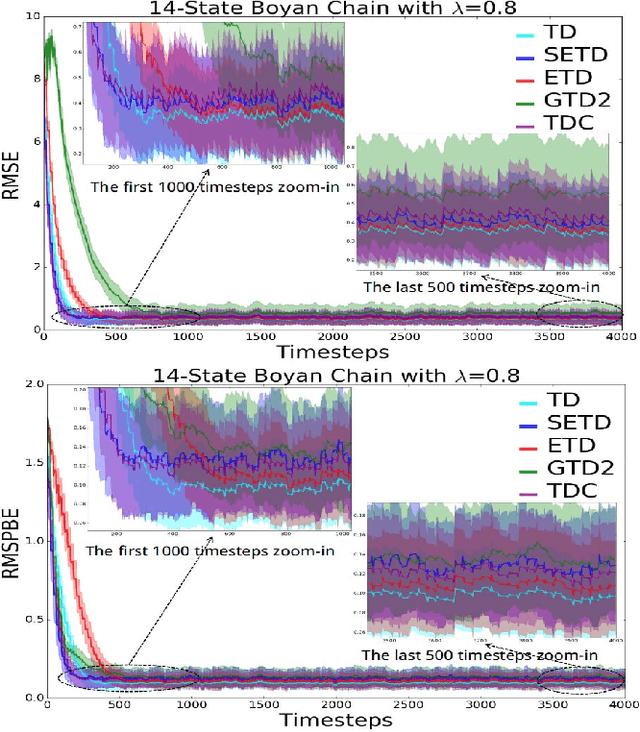
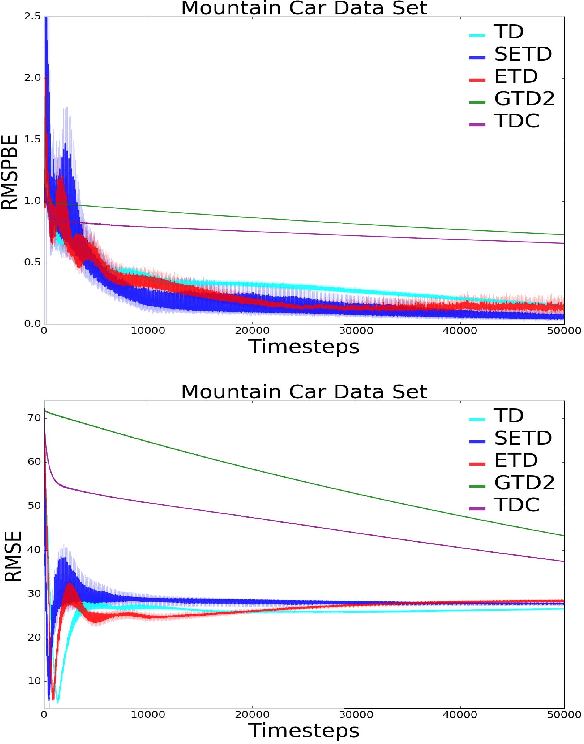
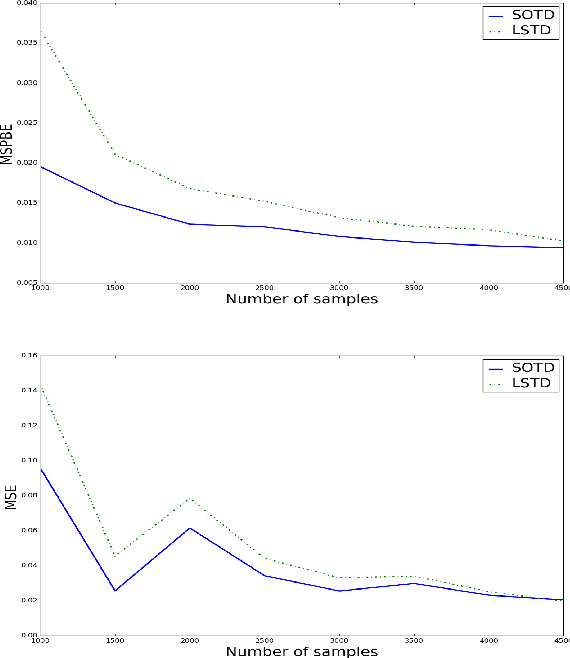
Policy evaluation algorithms are essential to reinforcement learning due to their ability to predict the performance of a policy. However, there are two long-standing issues lying in this prediction problem that need to be tackled: off-policy stability and on-policy efficiency. The conventional temporal difference (TD) algorithm is known to perform very well in the on-policy setting, yet is not off-policy stable. On the other hand, the gradient TD and emphatic TD algorithms are off-policy stable, but are not on-policy efficient. This paper introduces novel algorithms that are both off-policy stable and on-policy efficient by using the oblique projection method. The empirical experimental results on various domains validate the effectiveness of the proposed approach.
O$^2$TD: -Optimal Off-Policy TD Learning
Apr 19, 2017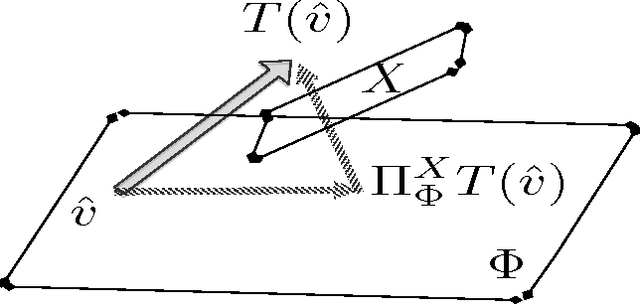
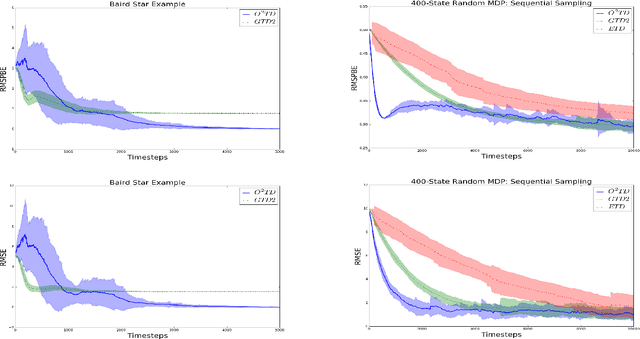
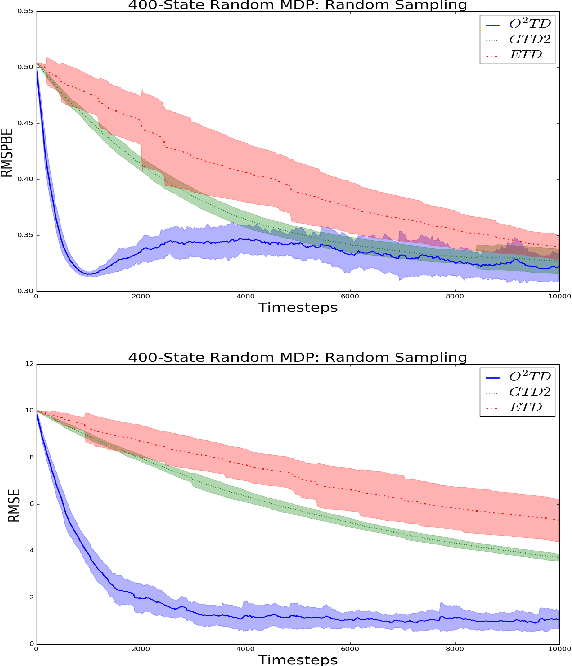
Temporal difference learning and Residual Gradient methods are the most widely used temporal difference based learning algorithms; however, it has been shown that none of their objective functions is optimal w.r.t approximating the true value function $V$. Two novel algorithms are proposed to approximate the true value function $V$. This paper makes the following contributions: (1) A batch algorithm that can help find the approximate optimal off-policy prediction of the true value function $V$. (2) A linear computational cost (per step) near-optimal algorithm that can learn from a collection of off-policy samples. (3) A new perspective of the emphatic temporal difference learning which bridges the gap between off-policy optimality and off-policy stability.