 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-accelerated Guided Source Separation for Meeting Transcription
Dec 10, 2022Guided source separation (GSS) is a type of target-speaker extraction method that relies on pre-computed speaker activities and blind source separation to perform front-end enhancement of overlapped speech signals. It was first proposed during the CHiME-5 challenge and provided significant improvements over the delay-and-sum beamforming baseline. Despite its strengths, however, the method has seen limited adoption for meeting transcription benchmarks primarily due to its high computation time. In this paper, we describe our improved implementation of GSS that leverages the power of modern GPU-based pipelines, including batched processing of frequencies and segments, to provide 300x speed-up over CPU-based inference. The improved inference time allows us to perform detailed ablation studies over several parameters of the GSS algorithm -- such as context duration, number of channels, and noise class, to name a few. We provide end-to-end reproducible pipelines for speaker-attributed transcription of popular meeting benchmarks: LibriCSS, AMI, and AliMeeting. Our code and recipes are publicly available: https://github.com/desh2608/gss.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022



Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Delay-penalized transducer for low-latency streaming ASR
Oct 31, 2022In streaming automatic speech recognition (ASR), it is desirable to reduce latency as much as possible while having minimum impact on recognition accuracy. Although a few existing methods are able to achieve this goal, they are difficult to implement due to their dependency on external alignments. In this paper, we propose a simple way to penalize symbol delay in transducer model, so that we can balance the trade-off between symbol delay and accuracy for streaming models without external alignments. Specifically, our method adds a small constant times (T/2 - t), where T is the number of frames and t is the current frame, to all the non-blank log-probabilities (after normalization) that are fed into the two dimensional transducer recursion. For both streaming Conformer models and unidirectional long short-term memory (LSTM) models, experimental results show that it can significantly reduce the symbol delay with an acceptable performance degradation. Our method achieves similar delay-accuracy trade-off to the previously published FastEmit, but we believe our method is preferable because it has a better justification: it is equivalent to penalizing the average symbol delay. Our work is open-sourced and publicly available (https://github.com/k2-fsa/k2).
Fast and parallel decoding for transducer
Oct 31, 2022The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
Pruned RNN-T for fast, memory-efficient ASR training
Jun 23, 2022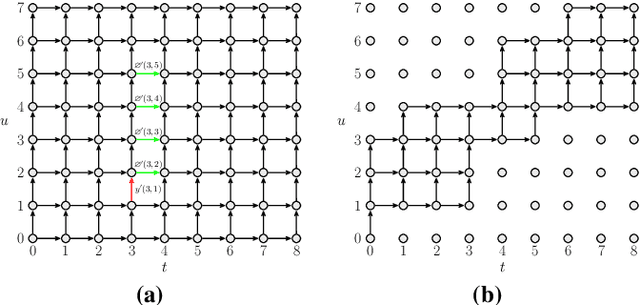

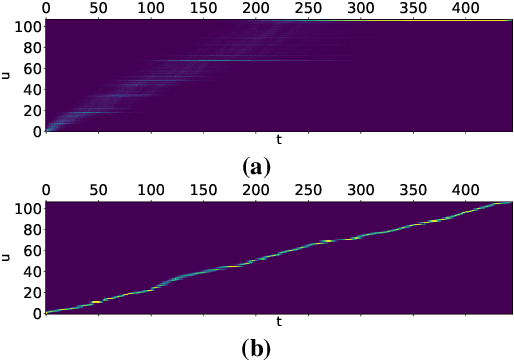
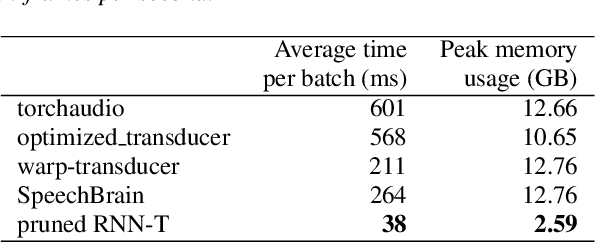
The RNN-Transducer (RNN-T) framework for speech recognition has been growing in popularity, particularly for deployed real-time ASR systems, because it combines high accuracy with naturally streaming recognition. One of the drawbacks of RNN-T is that its loss function is relatively slow to compute, and can use a lot of memory. Excessive GPU memory usage can make it impractical to use RNN-T loss in cases where the vocabulary size is large: for example, for Chinese character-based ASR. We introduce a method for faster and more memory-efficient RNN-T loss computation. We first obtain pruning bounds for the RNN-T recursion using a simple joiner network that is linear in the encoder and decoder embeddings; we can evaluate this without using much memory. We then use those pruning bounds to evaluate the full, non-linear joiner network.
Lhotse: a speech data representation library for the modern deep learning ecosystem
Oct 25, 2021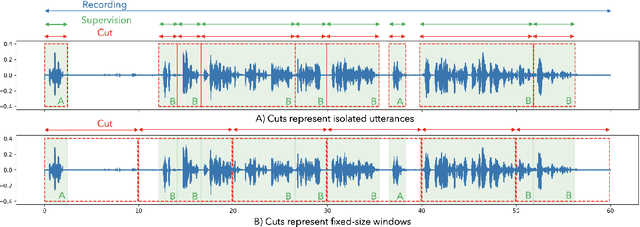
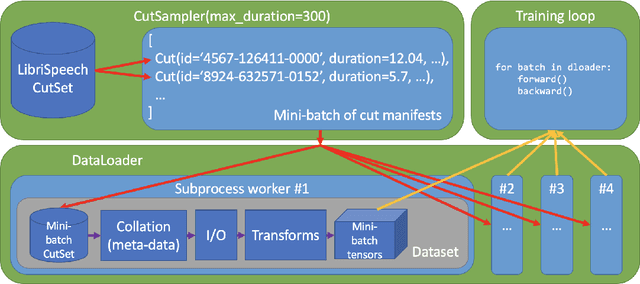
Speech data is notoriously difficult to work with due to a variety of codecs, lengths of recordings, and meta-data formats. We present Lhotse, a speech data representation library that draws upon lessons learned from Kaldi speech recognition toolkit and brings its concepts into the modern deep learning ecosystem. Lhotse provides a common JSON description format with corresponding Python classes and data preparation recipes for over 30 popular speech corpora. Various datasets can be easily combined together and re-purposed for different tasks. The library handles multi-channel recordings, long recordings, local and cloud storage, lazy and on-the-fly operations amongst other features. We introduce Cut and CutSet concepts, which simplify common data wrangling tasks for audio and help incorporate acoustic context of speech utterances. Finally, we show how Lhotse leverages PyTorch data API abstractions and adopts them to handle speech data for deep learning.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021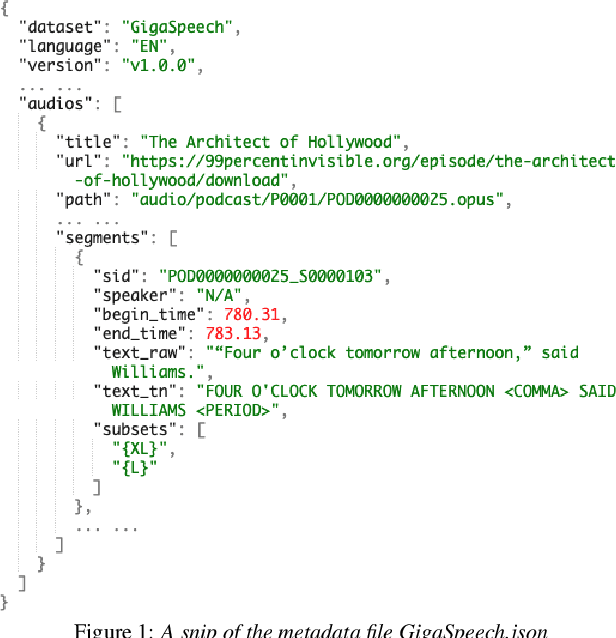
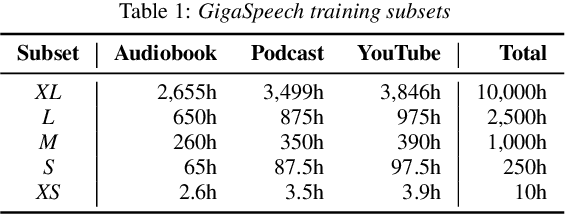
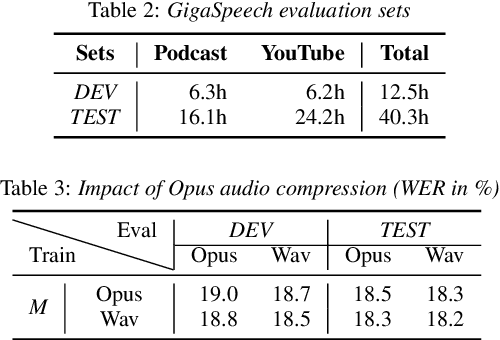
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
speechocean762: An Open-Source Non-native English Speech Corpus For Pronunciation Assessment
Apr 03, 2021
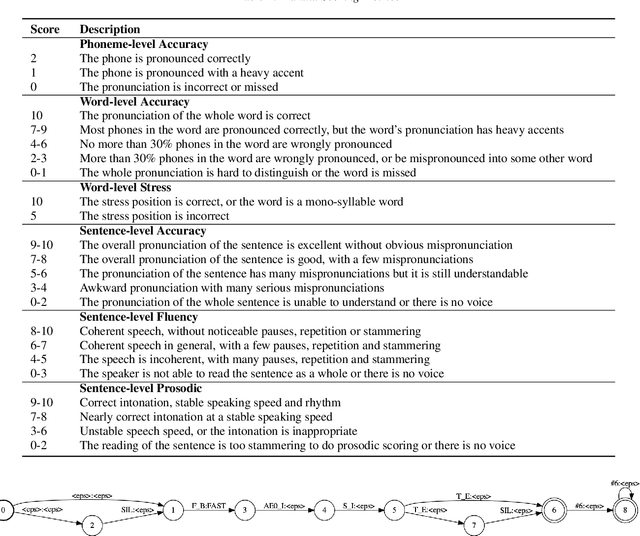

This paper introduces a new open-source speech corpus named "speechocean762" designed for pronunciation assessment use, consisting of 5000 English utterances from 250 non-native speakers, where half of the speakers are children. Five experts annotated each of the utterances at sentence-level, word-level and phoneme-level. A baseline system is released in open source to illustrate the phoneme-level pronunciation assessment workflow on this corpus. This corpus is allowed to be used freely for commercial and non-commercial purposes. It is available for free download from OpenSLR, and the corresponding baseline system is published in the Kaldi speech recognition toolkit.
An Asynchronous WFST-Based Decoder For Automatic Speech Recognition
Mar 16, 2021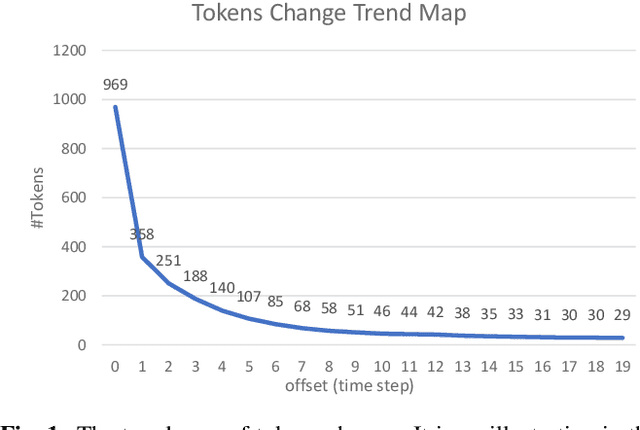
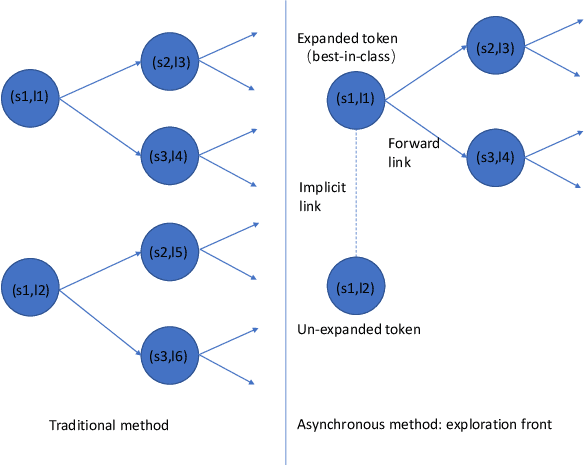
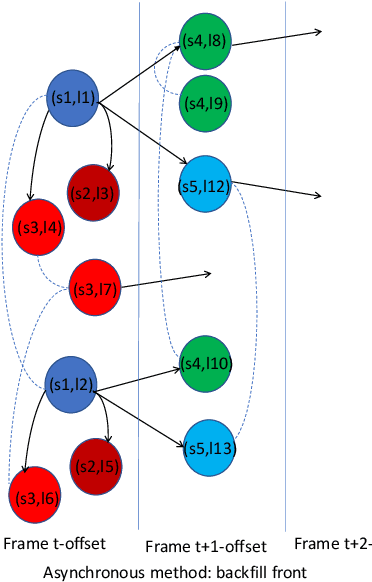
We introduce asynchronous dynamic decoder, which adopts an efficient A* algorithm to incorporate big language models in the one-pass decoding for large vocabulary continuous speech recognition. Unlike standard one-pass decoding with on-the-fly composition decoder which might induce a significant computation overhead, the asynchronous dynamic decoder has a novel design where it has two fronts, with one performing "exploration" and the other "backfill". The computation of the two fronts alternates in the decoding process, resulting in more effective pruning than the standard one-pass decoding with an on-the-fly composition decoder. Experiments show that the proposed decoder works notably faster than the standard one-pass decoding with on-the-fly composition decoder, while the acceleration will be more obvious with the increment of data complexity.
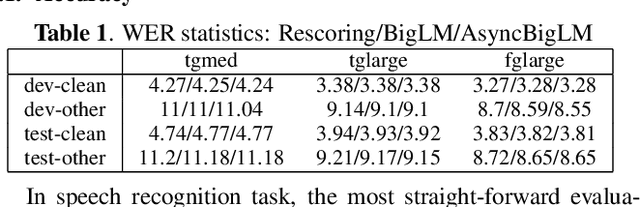
A Parallelizable Lattice Rescoring Strategy with Neural Language Models
Mar 08, 2021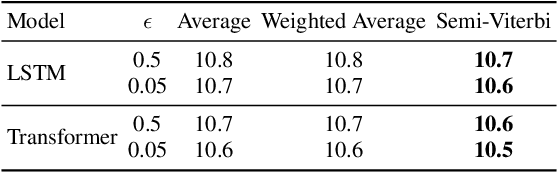
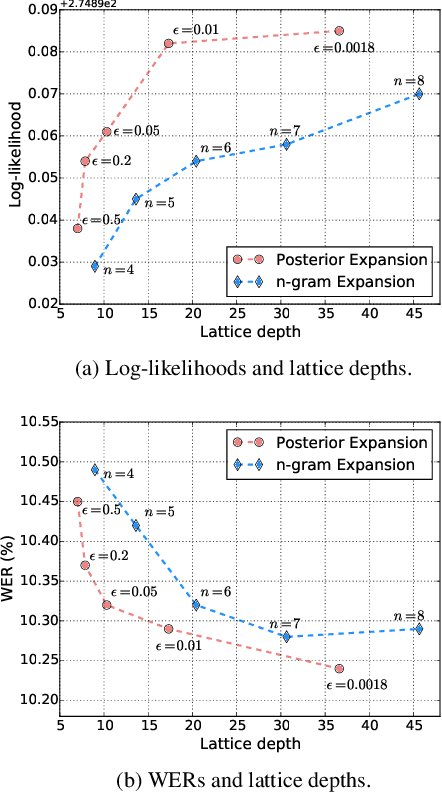

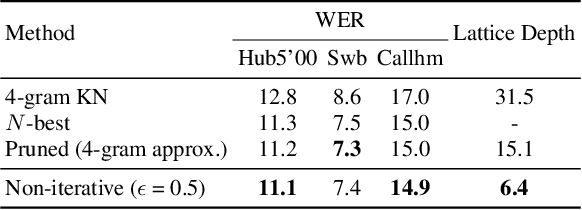
This paper proposes a parallel computation strategy and a posterior-based lattice expansion algorithm for efficient lattice rescoring with neural language models (LMs) for automatic speech recognition. First, lattices from first-pass decoding are expanded by the proposed posterior-based lattice expansion algorithm. Second, each expanded lattice is converted into a minimal list of hypotheses that covers every arc. Each hypothesis is constrained to be the best path for at least one arc it includes. For each lattice, the neural LM scores of the minimal list are computed in parallel and are then integrated back to the lattice in the rescoring stage. Experiments on the Switchboard dataset show that the proposed rescoring strategy obtains comparable recognition performance and generates more compact lattices than a competitive baseline method. Furthermore, the parallel rescoring method offers more flexibility by simplifying the integration of PyTorch-trained neural LMs for lattice rescoring with Kaldi.