 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWake Word Detection with Streaming Transformers
Paper and Code
Feb 08, 2021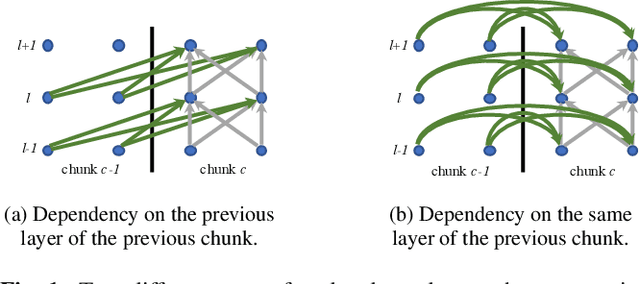
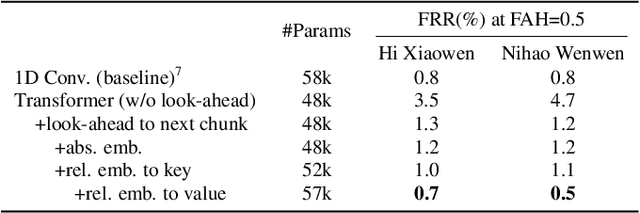
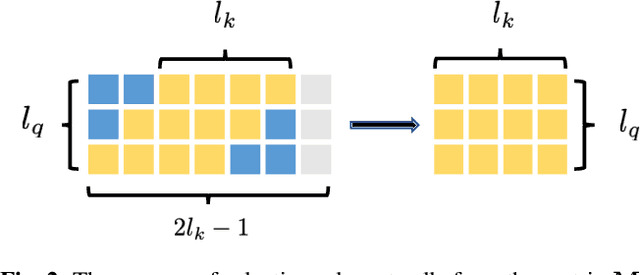
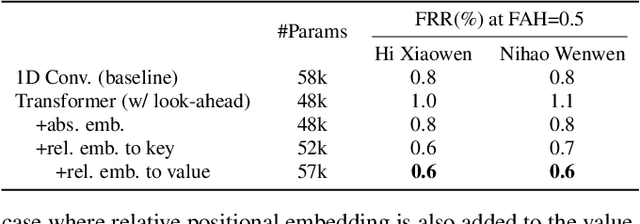
Modern wake word detection systems usually rely on neural networks for acoustic modeling. Transformers has recently shown superior performance over LSTM and convolutional networks in various sequence modeling tasks with their better temporal modeling power. However it is not clear whether this advantage still holds for short-range temporal modeling like wake word detection. Besides, the vanilla Transformer is not directly applicable to the task due to its non-streaming nature and the quadratic time and space complexity. In this paper we explore the performance of several variants of chunk-wise streaming Transformers tailored for wake word detection in a recently proposed LF-MMI system, including looking-ahead to the next chunk, gradient stopping, different positional embedding methods and adding same-layer dependency between chunks. Our experiments on the Mobvoi wake word dataset demonstrate that our proposed Transformer model outperforms the baseline convolution network by 25% on average in false rejection rate at the same false alarm rate with a comparable model size, while still maintaining linear complexity w.r.t. the sequence length.