 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the limiting dynamics of SGD: modified loss, phase space oscillations, and anomalous diffusion
Jul 19, 2021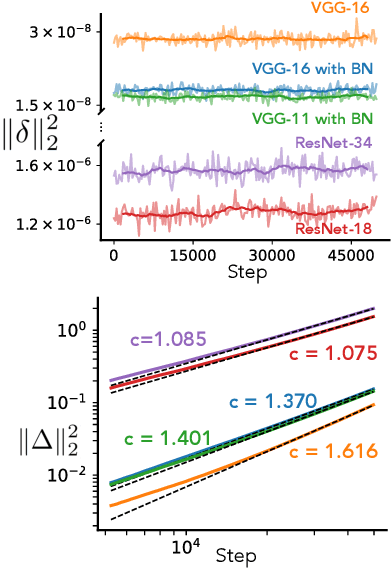
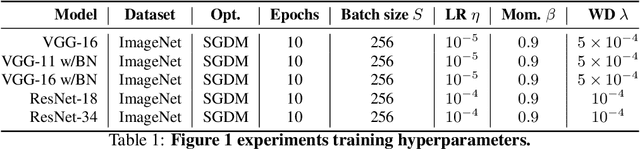
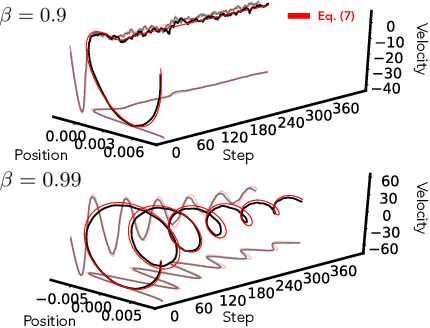

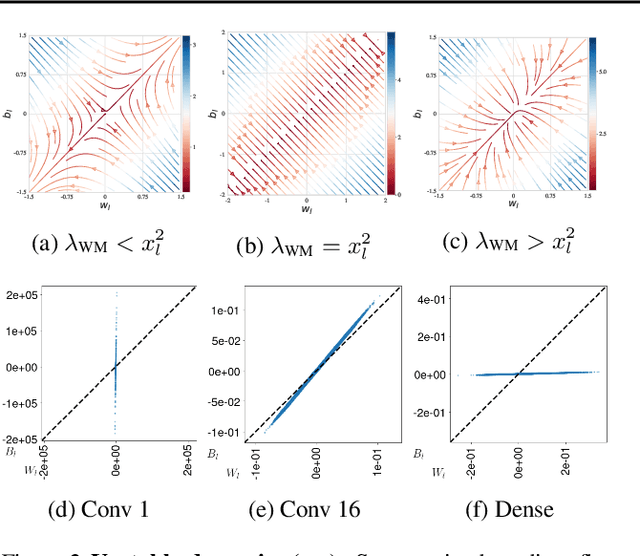
In this work we explore the limiting dynamics of deep neural networks trained with stochastic gradient descent (SGD). We find empirically that long after performance has converged, networks continue to move through parameter space by a process of anomalous diffusion in which distance travelled grows as a power law in the number of gradient updates with a nontrivial exponent. We reveal an intricate interaction between the hyperparameters of optimization, the structure in the gradient noise, and the Hessian matrix at the end of training that explains this anomalous diffusion. To build this understanding, we first derive a continuous-time model for SGD with finite learning rates and batch sizes as an underdamped Langevin equation. We study this equation in the setting of linear regression, where we can derive exact, analytic expressions for the phase space dynamics of the parameters and their instantaneous velocities from initialization to stationarity. Using the Fokker-Planck equation, we show that the key ingredient driving these dynamics is not the original training loss, but rather the combination of a modified loss, which implicitly regularizes the velocity, and probability currents, which cause oscillations in phase space. We identify qualitative and quantitative predictions of this theory in the dynamics of a ResNet-18 model trained on ImageNet. Through the lens of statistical physics, we uncover a mechanistic origin for the anomalous limiting dynamics of deep neural networks trained with SGD.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines
Jun 17, 2021
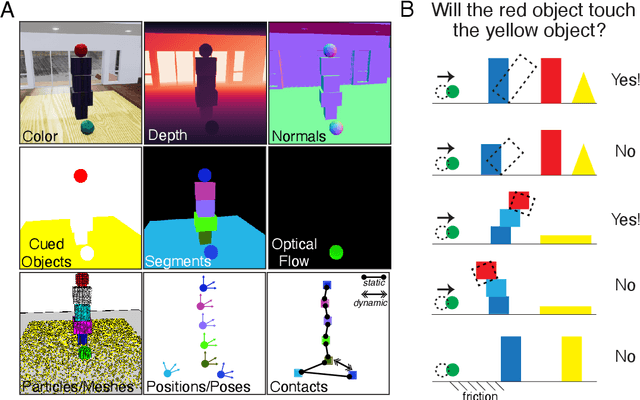
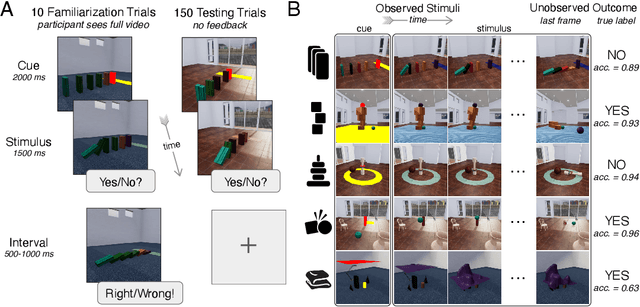
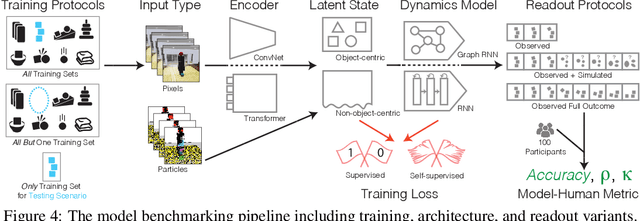
While machine learning algorithms excel at many challenging visual tasks, it is unclear that they can make predictions about commonplace real world physical events. Here, we present a visual and physical prediction benchmark that precisely measures this capability. In realistically simulating a wide variety of physical phenomena -- rigid and soft-body collisions, stable multi-object configurations, rolling and sliding, projectile motion -- our dataset presents a more comprehensive challenge than existing benchmarks. Moreover, we have collected human responses for our stimuli so that model predictions can be directly compared to human judgments. We compare an array of algorithms -- varying in their architecture, learning objective, input-output structure, and training data -- on their ability to make diverse physical predictions. We find that graph neural networks with access to the physical state best capture human behavior, whereas among models that receive only visual input, those with object-centric representations or pretraining do best but fall far short of human accuracy. This suggests that extracting physically meaningful representations of scenes is the main bottleneck to achieving human-like visual prediction. We thus demonstrate how our benchmark can identify areas for improvement and measure progress on this key aspect of physical understanding.
The ThreeDWorld Transport Challenge: A Visually Guided Task-and-Motion Planning Benchmark for Physically Realistic Embodied AI
Mar 25, 2021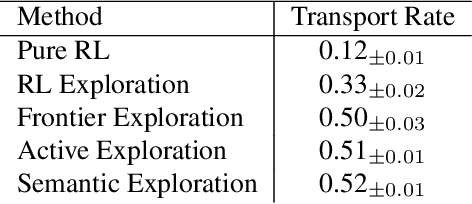

We introduce a visually-guided and physics-driven task-and-motion planning benchmark, which we call the ThreeDWorld Transport Challenge. In this challenge, an embodied agent equipped with two 9-DOF articulated arms is spawned randomly in a simulated physical home environment. The agent is required to find a small set of objects scattered around the house, pick them up, and transport them to a desired final location. We also position containers around the house that can be used as tools to assist with transporting objects efficiently. To complete the task, an embodied agent must plan a sequence of actions to change the state of a large number of objects in the face of realistic physical constraints. We build this benchmark challenge using the ThreeDWorld simulation: a virtual 3D environment where all objects respond to physics, and where can be controlled using fully physics-driven navigation and interaction API. We evaluate several existing agents on this benchmark. Experimental results suggest that: 1) a pure RL model struggles on this challenge; 2) hierarchical planning-based agents can transport some objects but still far from solving this task. We anticipate that this benchmark will empower researchers to develop more intelligent physics-driven robots for the physical world.
Neural Mechanics: Symmetry and Broken Conservation Laws in Deep Learning Dynamics
Dec 08, 2020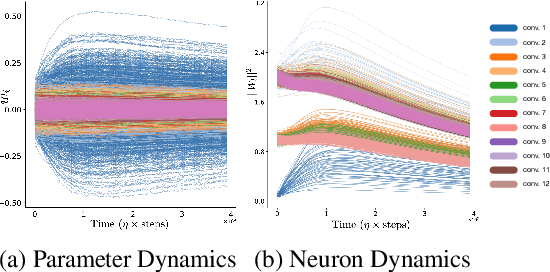
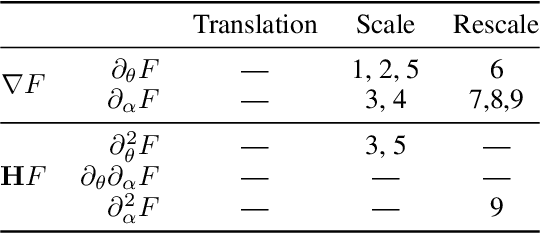
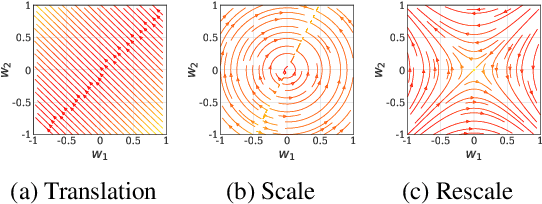

Predicting the dynamics of neural network parameters during training is one of the key challenges in building a theoretical foundation for deep learning. A central obstacle is that the motion of a network in high-dimensional parameter space undergoes discrete finite steps along complex stochastic gradients derived from real-world datasets. We circumvent this obstacle through a unifying theoretical framework based on intrinsic symmetries embedded in a network's architecture that are present for any dataset. We show that any such symmetry imposes stringent geometric constraints on gradients and Hessians, leading to an associated conservation law in the continuous-time limit of stochastic gradient descent (SGD), akin to Noether's theorem in physics. We further show that finite learning rates used in practice can actually break these symmetry induced conservation laws. We apply tools from finite difference methods to derive modified gradient flow, a differential equation that better approximates the numerical trajectory taken by SGD at finite learning rates. We combine modified gradient flow with our framework of symmetries to derive exact integral expressions for the dynamics of certain parameter combinations. We empirically validate our analytic predictions for learning dynamics on VGG-16 trained on Tiny ImageNet. Overall, by exploiting symmetry, our work demonstrates that we can analytically describe the learning dynamics of various parameter combinations at finite learning rates and batch sizes for state of the art architectures trained on any dataset.
Identifying Learning Rules From Neural Network Observables
Oct 22, 2020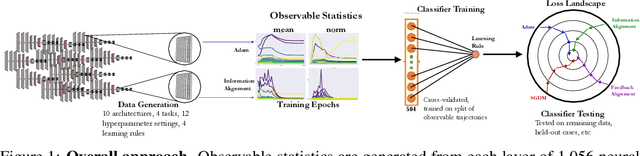
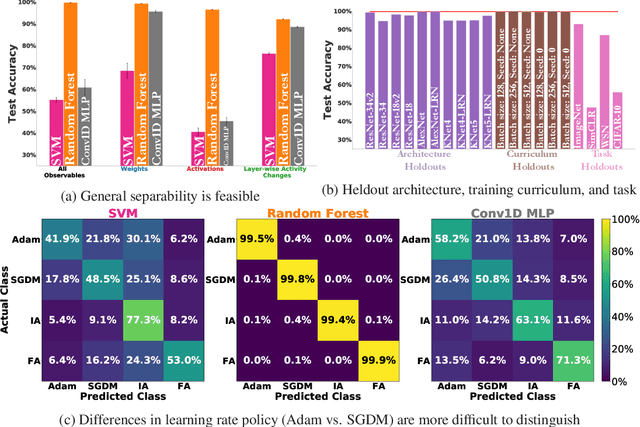
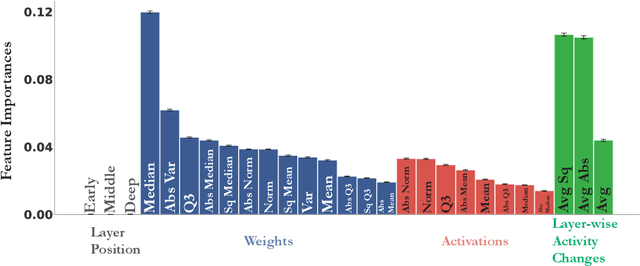
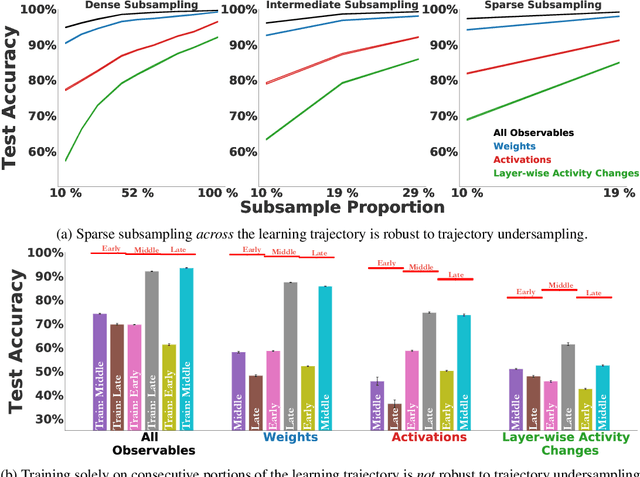
The brain modifies its synaptic strengths during learning in order to better adapt to its environment. However, the underlying plasticity rules that govern learning are unknown. Many proposals have been suggested, including Hebbian mechanisms, explicit error backpropagation, and a variety of alternatives. It is an open question as to what specific experimental measurements would need to be made to determine whether any given learning rule is operative in a real biological system. In this work, we take a "virtual experimental" approach to this problem. Simulating idealized neuroscience experiments with artificial neural networks, we generate a large-scale dataset of learning trajectories of aggregate statistics measured in a variety of neural network architectures, loss functions, learning rule hyperparameters, and parameter initializations. We then take a discriminative approach, training linear and simple non-linear classifiers to identify learning rules from features based on these observables. We show that different classes of learning rules can be separated solely on the basis of aggregate statistics of the weights, activations, or instantaneous layer-wise activity changes, and that these results generalize to limited access to the trajectory and held-out architectures and learning curricula. We identify the statistics of each observable that are most relevant for rule identification, finding that statistics from network activities across training are more robust to unit undersampling and measurement noise than those obtained from the synaptic strengths. Our results suggest that activation patterns, available from electrophysiological recordings of post-synaptic activities on the order of several hundred units, frequently measured at wider intervals over the course of learning, may provide a good basis on which to identify learning rules.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
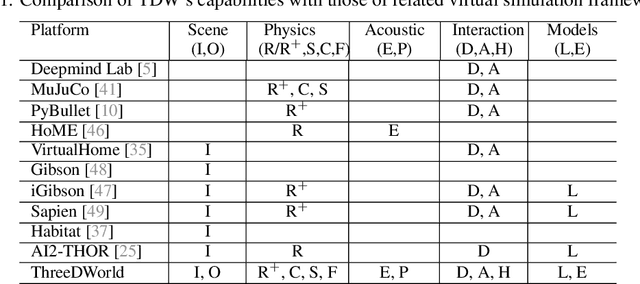

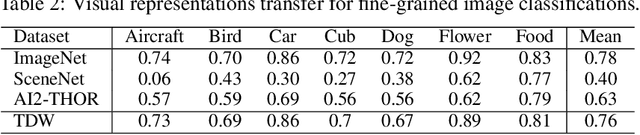
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.
Learning Physical Graph Representations from Visual Scenes
Jun 24, 2020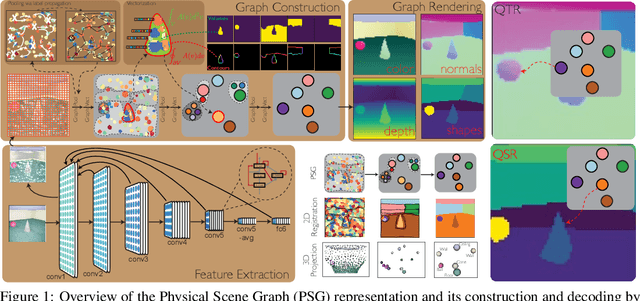
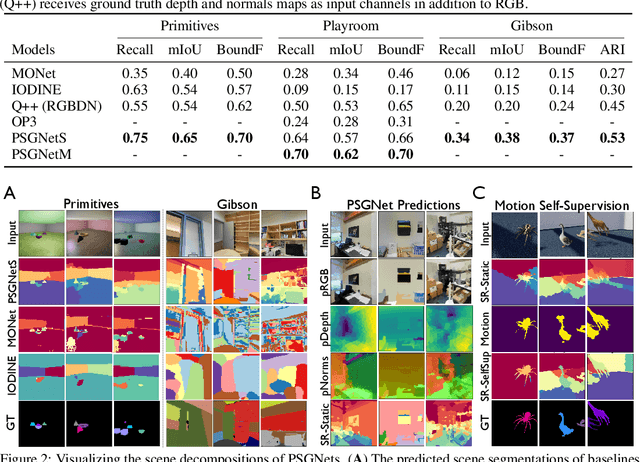
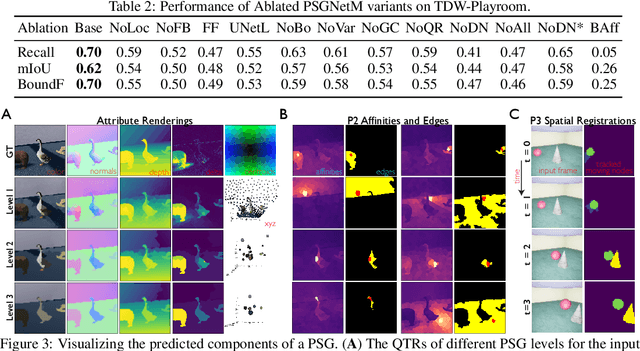

Convolutional Neural Networks (CNNs) have proved exceptional at learning representations for visual object categorization. However, CNNs do not explicitly encode objects, parts, and their physical properties, which has limited CNNs' success on tasks that require structured understanding of visual scenes. To overcome these limitations, we introduce the idea of Physical Scene Graphs (PSGs), which represent scenes as hierarchical graphs, with nodes in the hierarchy corresponding intuitively to object parts at different scales, and edges to physical connections between parts. Bound to each node is a vector of latent attributes that intuitively represent object properties such as surface shape and texture. We also describe PSGNet, a network architecture that learns to extract PSGs by reconstructing scenes through a PSG-structured bottleneck. PSGNet augments standard CNNs by including: recurrent feedback connections to combine low and high-level image information; graph pooling and vectorization operations that convert spatially-uniform feature maps into object-centric graph structures; and perceptual grouping principles to encourage the identification of meaningful scene elements. We show that PSGNet outperforms alternative self-supervised scene representation algorithms at scene segmentation tasks, especially on complex real-world images, and generalizes well to unseen object types and scene arrangements. PSGNet is also able learn from physical motion, enhancing scene estimates even for static images. We present a series of ablation studies illustrating the importance of each component of the PSGNet architecture, analyses showing that learned latent attributes capture intuitive scene properties, and illustrate the use of PSGs for compositional scene inference.
Pruning neural networks without any data by iteratively conserving synaptic flow
Jun 09, 2020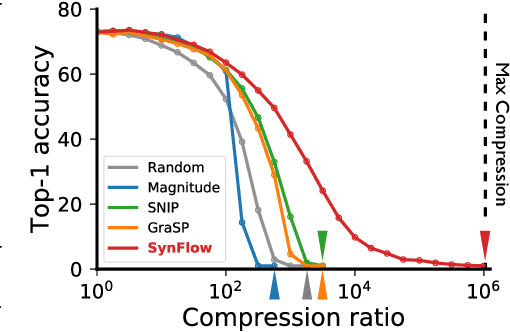

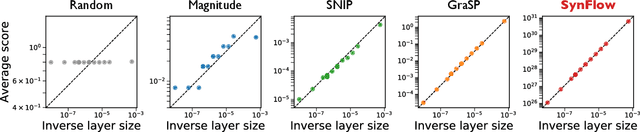
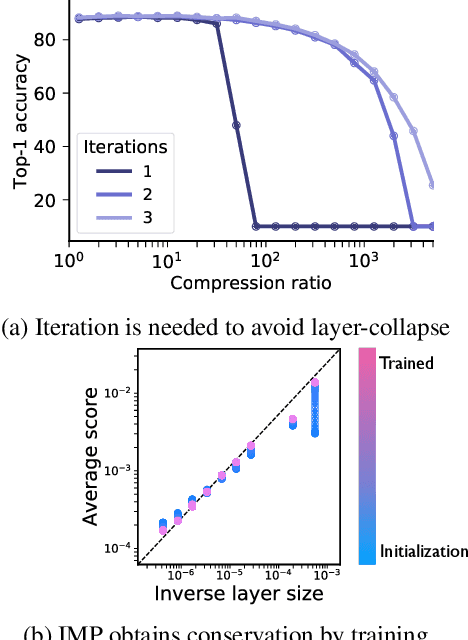
Pruning the parameters of deep neural networks has generated intense interest due to potential savings in time, memory and energy both during training and at test time. Recent works have identified, through an expensive sequence of training and pruning cycles, the existence of winning lottery tickets or sparse trainable subnetworks at initialization. This raises a foundational question: can we identify highly sparse trainable subnetworks at initialization, without ever training, or indeed without ever looking at the data? We provide an affirmative answer to this question through theory driven algorithm design. We first mathematically formulate and experimentally verify a conservation law that explains why existing gradient-based pruning algorithms at initialization suffer from layer-collapse, the premature pruning of an entire layer rendering a network untrainable. This theory also elucidates how layer-collapse can be entirely avoided, motivating a novel pruning algorithm Iterative Synaptic Flow Pruning (SynFlow). This algorithm can be interpreted as preserving the total flow of synaptic strengths through the network at initialization subject to a sparsity constraint. Notably, this algorithm makes no reference to the training data and consistently outperforms existing state-of-the-art pruning algorithms at initialization over a range of models (VGG and ResNet), datasets (CIFAR-10/100 and Tiny ImageNet), and sparsity constraints (up to 99.9 percent). Thus our data-agnostic pruning algorithm challenges the existing paradigm that data must be used to quantify which synapses are important.
Visual Grounding of Learned Physical Models
Apr 28, 2020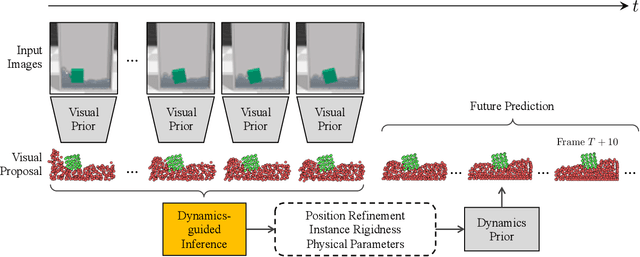
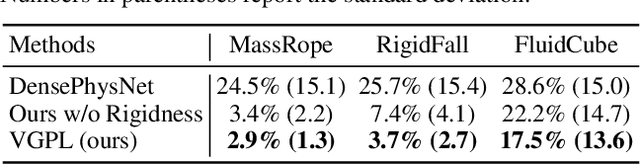
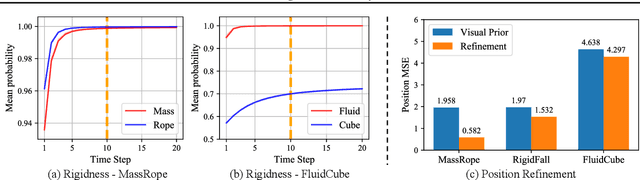

Humans intuitively recognize objects' physical properties and predict their motion, even when the objects are engaged in complicated interactions. The abilities to perform physical reasoning and to adapt to new environments, while intrinsic to humans, remain challenging to state-of-the-art computational models. In this work, we present a neural model that simultaneously reasons about physics and make future predictions based on visual and dynamics priors. The visual prior predicts a particle-based representation of the system from visual observations. An inference module operates on those particles, predicting and refining estimates of particle locations, object states, and physical parameters, subject to the constraints imposed by the dynamics prior, which we refer to as visual grounding. We demonstrate the effectiveness of our method in environments involving rigid objects, deformable materials, and fluids. Experiments show that our model can infer the physical properties within a few observations, which allows the model to quickly adapt to unseen scenarios and make accurate predictions into the future.
Two Routes to Scalable Credit Assignment without Weight Symmetry
Feb 28, 2020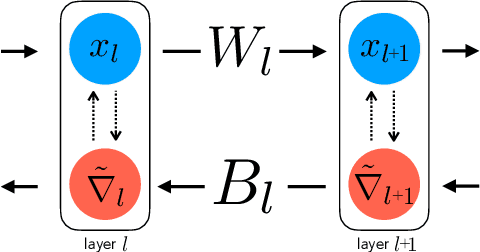


The neural plausibility of backpropagation has long been disputed, primarily for its use of non-local weight transport - the biologically dubious requirement that one neuron instantaneously measure the synaptic weights of another. Until recently, attempts to create local learning rules that avoid weight transport have typically failed in the large-scale learning scenarios where backpropagation shines, e.g. ImageNet categorization with deep convolutional networks. Here, we investigate a recently proposed local learning rule that yields competitive performance with backpropagation and find that it is highly sensitive to metaparameter choices, requiring laborious tuning that does not transfer across network architecture. Our analysis indicates the underlying mathematical reason for this instability, allowing us to identify a more robust local learning rule that better transfers without metaparameter tuning. Nonetheless, we find a performance and stability gap between this local rule and backpropagation that widens with increasing model depth. We then investigate several non-local learning rules that relax the need for instantaneous weight transport into a more biologically-plausible "weight estimation" process, showing that these rules match state-of-the-art performance on deep networks and operate effectively in the presence of noisy updates. Taken together, our results suggest two routes towards the discovery of neural implementations for credit assignment without weight symmetry: further improvement of local rules so that they perform consistently across architectures and the identification of biological implementations for non-local learning mechanisms.