 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIU-Net: U-Net in U-Net for Infrared Small Object Detection
Dec 02, 2022Learning-based infrared small object detection methods currently rely heavily on the classification backbone network. This tends to result in tiny object loss and feature distinguishability limitations as the network depth increases. Furthermore, small objects in infrared images are frequently emerged bright and dark, posing severe demands for obtaining precise object contrast information. For this reason, we in this paper propose a simple and effective ``U-Net in U-Net'' framework, UIU-Net for short, and detect small objects in infrared images. As the name suggests, UIU-Net embeds a tiny U-Net into a larger U-Net backbone, enabling the multi-level and multi-scale representation learning of objects. Moreover, UIU-Net can be trained from scratch, and the learned features can enhance global and local contrast information effectively. More specifically, the UIU-Net model is divided into two modules: the resolution-maintenance deep supervision (RM-DS) module and the interactive-cross attention (IC-A) module. RM-DS integrates Residual U-blocks into a deep supervision network to generate deep multi-scale resolution-maintenance features while learning global context information. Further, IC-A encodes the local context information between the low-level details and high-level semantic features. Extensive experiments conducted on two infrared single-frame image datasets, i.e., SIRST and Synthetic datasets, show the effectiveness and superiority of the proposed UIU-Net in comparison with several state-of-the-art infrared small object detection methods. The proposed UIU-Net also produces powerful generalization performance for video sequence infrared small object datasets, e.g., ATR ground/air video sequence dataset. The codes of this work are available openly at \url{https://github.com/danfenghong/IEEE_TIP_UIU-Net}.
Panchromatic and Multispectral Image Fusion via Alternating Reverse Filtering Network
Oct 15, 2022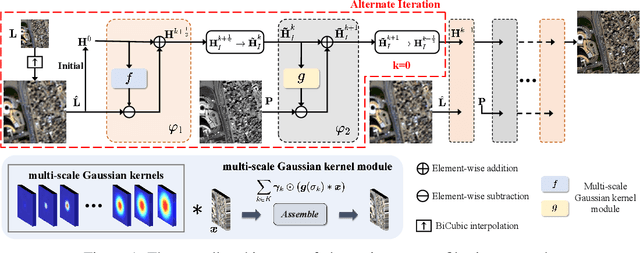
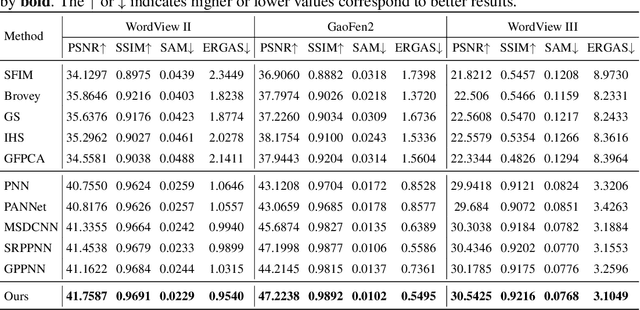
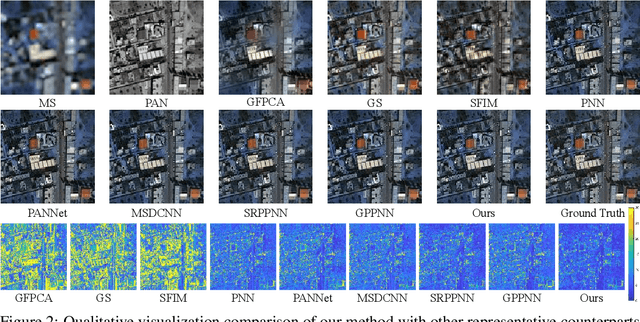

Panchromatic (PAN) and multi-spectral (MS) image fusion, named Pan-sharpening, refers to super-resolve the low-resolution (LR) multi-spectral (MS) images in the spatial domain to generate the expected high-resolution (HR) MS images, conditioning on the corresponding high-resolution PAN images. In this paper, we present a simple yet effective \textit{alternating reverse filtering network} for pan-sharpening. Inspired by the classical reverse filtering that reverses images to the status before filtering, we formulate pan-sharpening as an alternately iterative reverse filtering process, which fuses LR MS and HR MS in an interpretable manner. Different from existing model-driven methods that require well-designed priors and degradation assumptions, the reverse filtering process avoids the dependency on pre-defined exact priors. To guarantee the stability and convergence of the iterative process via contraction mapping on a metric space, we develop the learnable multi-scale Gaussian kernel module, instead of using specific filters. We demonstrate the theoretical feasibility of such formulations. Extensive experiments on diverse scenes to thoroughly verify the performance of our method, significantly outperforming the state of the arts.
Tensor Decompositions for Hyperspectral Data Processing in Remote Sensing: A Comprehensive Review
May 13, 2022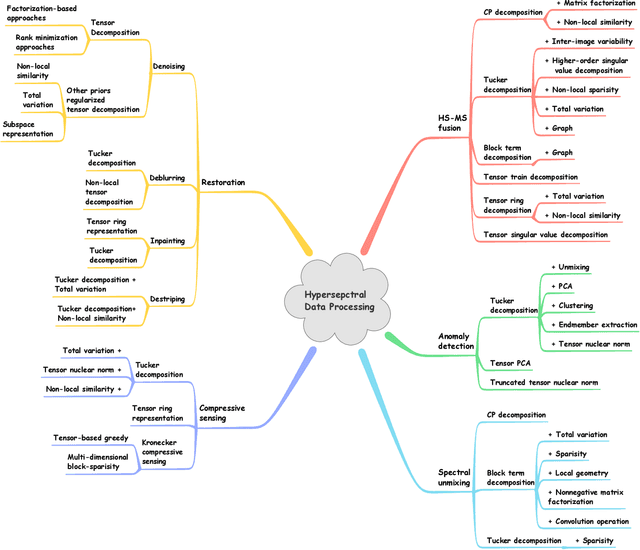



Owing to the rapid development of sensor technology, hyperspectral (HS) remote sensing (RS) imaging has provided a significant amount of spatial and spectral information for the observation and analysis of the Earth's surface at a distance of data acquisition devices, such as aircraft, spacecraft, and satellite. The recent advancement and even revolution of the HS RS technique offer opportunities to realize the full potential of various applications, while confronting new challenges for efficiently processing and analyzing the enormous HS acquisition data. Due to the maintenance of the 3-D HS inherent structure, tensor decomposition has aroused widespread concern and research in HS data processing tasks over the past decades. In this article, we aim at presenting a comprehensive overview of tensor decomposition, specifically contextualizing the five broad topics in HS data processing, and they are HS restoration, compressed sensing, anomaly detection, super-resolution, and spectral unmixing. For each topic, we elaborate on the remarkable achievements of tensor decomposition models for HS RS with a pivotal description of the existing methodologies and a representative exhibition on the experimental results. As a result, the remaining challenges of the follow-up research directions are outlined and discussed from the perspective of the real HS RS practices and tensor decomposition merged with advanced priors and even with deep neural networks. This article summarizes different tensor decomposition-based HS data processing methods and categorizes them into different classes from simple adoptions to complex combinations with other priors for the algorithm beginners. We also expect this survey can provide new investigations and development trends for the experienced researchers who understand tensor decomposition and HS RS to some extent.
Decoupled-and-Coupled Networks: Self-Supervised Hyperspectral Image Super-Resolution with Subpixel Fusion
May 07, 2022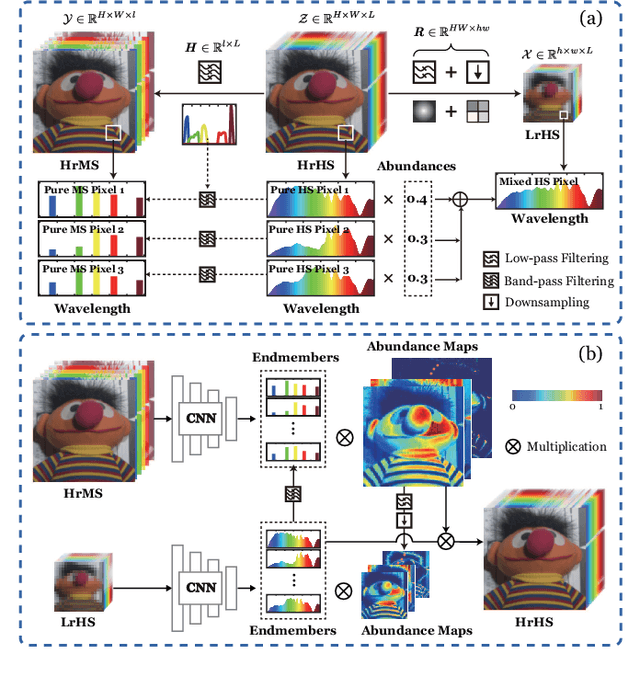
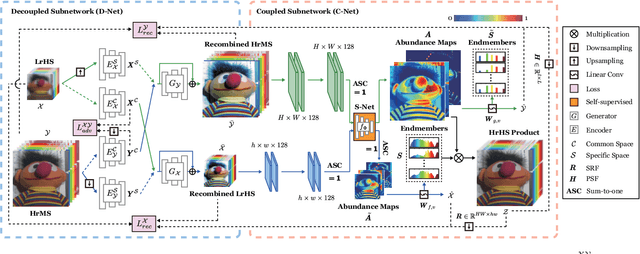
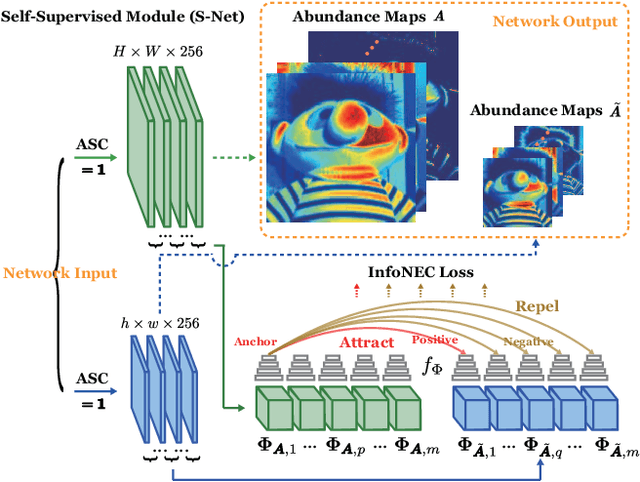
Enormous efforts have been recently made to super-resolve hyperspectral (HS) images with the aid of high spatial resolution multispectral (MS) images. Most prior works usually perform the fusion task by means of multifarious pixel-level priors. Yet the intrinsic effects of a large distribution gap between HS-MS data due to differences in the spatial and spectral resolution are less investigated. The gap might be caused by unknown sensor-specific properties or highly-mixed spectral information within one pixel (due to low spatial resolution). To this end, we propose a subpixel-level HS super-resolution framework by devising a novel decoupled-and-coupled network, called DC-Net, to progressively fuse HS-MS information from the pixel- to subpixel-level, from the image- to feature-level. As the name suggests, DC-Net first decouples the input into common (or cross-sensor) and sensor-specific components to eliminate the gap between HS-MS images before further fusion, and then fully blends them by a model-guided coupled spectral unmixing (CSU) net. More significantly, we append a self-supervised learning module behind the CSU net by guaranteeing the material consistency to enhance the detailed appearances of the restored HS product. Extensive experimental results show the superiority of our method both visually and quantitatively and achieve a significant improvement in comparison with the state-of-the-arts. Furthermore, the codes and datasets will be available at https://sites.google.com/view/danfeng-hong for the sake of reproducibility.
Deep Learning in Multimodal Remote Sensing Data Fusion: A Comprehensive Review
May 03, 2022
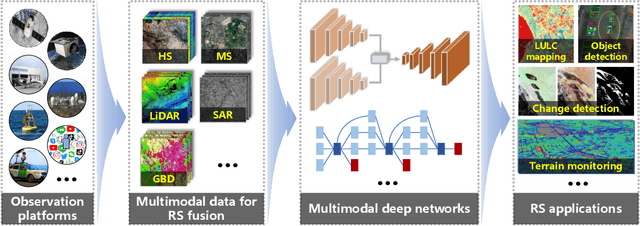
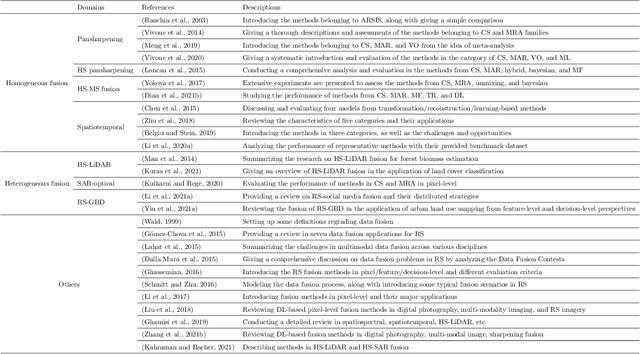
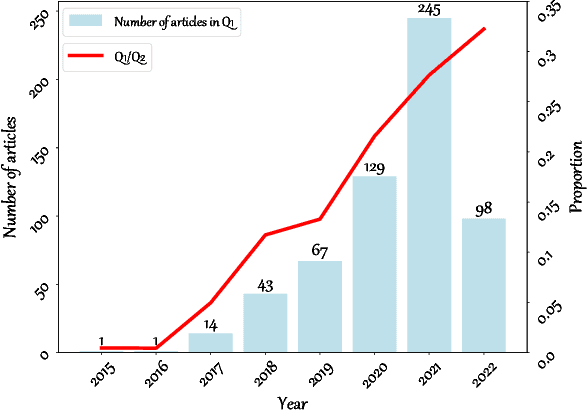
With the extremely rapid advances in remote sensing (RS) technology, a great quantity of Earth observation (EO) data featuring considerable and complicated heterogeneity is readily available nowadays, which renders researchers an opportunity to tackle current geoscience applications in a fresh way. With the joint utilization of EO data, much research on multimodal RS data fusion has made tremendous progress in recent years, yet these developed traditional algorithms inevitably meet the performance bottleneck due to the lack of the ability to comprehensively analyse and interpret these strongly heterogeneous data. Hence, this non-negligible limitation further arouses an intense demand for an alternative tool with powerful processing competence. Deep learning (DL), as a cutting-edge technology, has witnessed remarkable breakthroughs in numerous computer vision tasks owing to its impressive ability in data representation and reconstruction. Naturally, it has been successfully applied to the field of multimodal RS data fusion, yielding great improvement compared with traditional methods. This survey aims to present a systematic overview in DL-based multimodal RS data fusion. More specifically, some essential knowledge about this topic is first given. Subsequently, a literature survey is conducted to analyse the trends of this field. Some prevalent sub-fields in the multimodal RS data fusion are then reviewed in terms of the to-be-fused data modalities, i.e., spatiospectral, spatiotemporal, light detection and ranging-optical, synthetic aperture radar-optical, and RS-Geospatial Big Data fusion. Furthermore, We collect and summarize some valuable resources for the sake of the development in multimodal RS data fusion. Finally, the remaining challenges and potential future directions are highlighted.
Multimodal Fusion Transformer for Remote Sensing Image Classification
Mar 31, 2022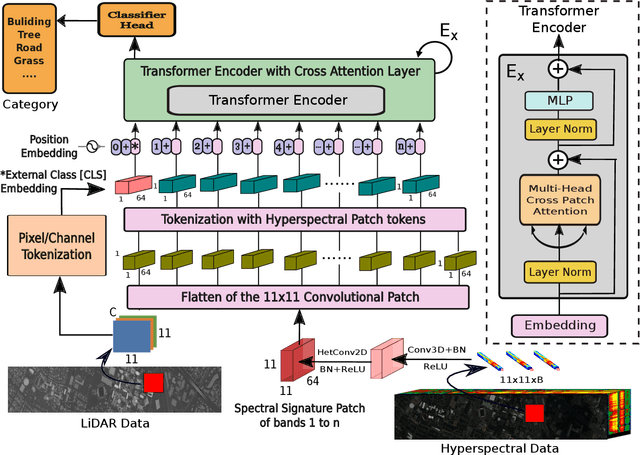


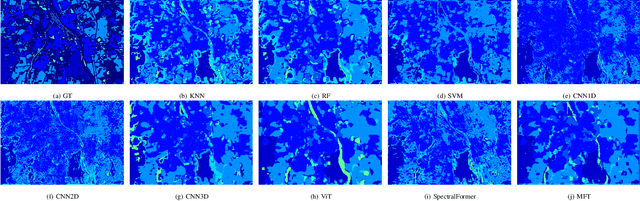
Vision transformer (ViT) has been trending in image classification tasks due to its promising performance when compared to convolutional neural networks (CNNs). As a result, many researchers have tried to incorporate ViT models in hyperspectral image (HSI) classification tasks, but without achieving satisfactory performance. To this paper, we introduce a new multimodal fusion transformer (MFT) network for HSI land-cover classification, which utilizes other sources of multimodal data in addition to HSI. Instead of using conventional feature fusion techniques, other multimodal data are used as an external classification (CLS) token in the transformer encoder, which helps achieving better generalization. ViT and other similar transformer models use a randomly initialized external classification token {and fail to generalize well}. However, the use of a feature embedding derived from other sources of multimodal data, such as light detection and ranging (LiDAR), offers the potential to improve those models by means of a CLS. The concept of tokenization is used in our work to generate CLS and HSI patch tokens, helping to learn key features in a reduced feature space. We also introduce a new attention mechanism for improving the exchange of information between HSI tokens and the CLS (e.g., LiDAR) token. Extensive experiments are carried out on widely used and benchmark datasets i.e., the University of Houston, Trento, University of Southern Mississippi Gulfpark (MUUFL), and Augsburg. In the results section, we compare the proposed MFT model with other state-of-the-art transformer models, classical CNN models, as well as conventional classifiers. The superior performance achieved by the proposed model is due to the use of multimodal information as external classification tokens.
Deep Learning for UAV-based Object Detection and Tracking: A Survey
Oct 25, 2021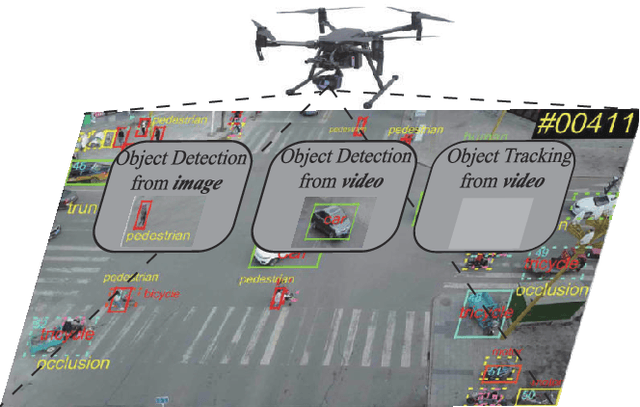
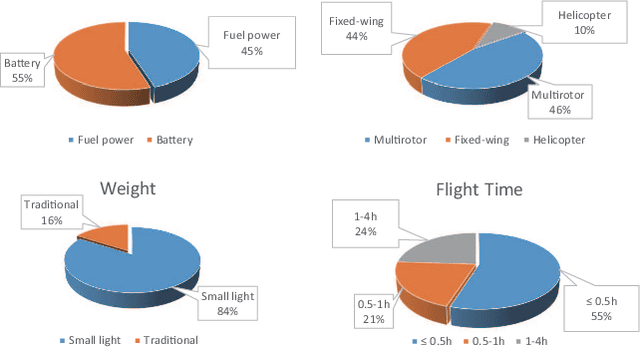
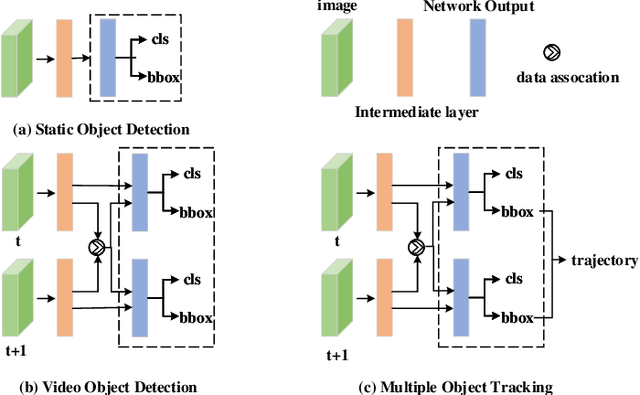
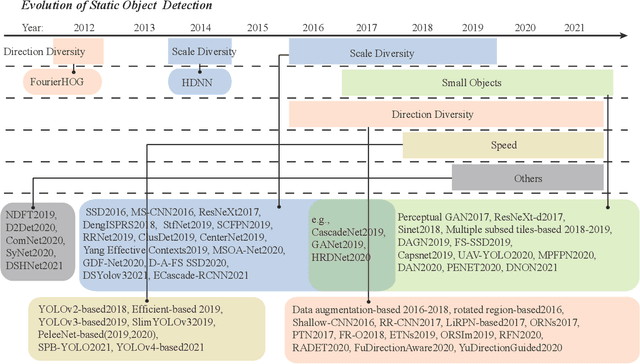
Owing to effective and flexible data acquisition, unmanned aerial vehicle (UAV) has recently become a hotspot across the fields of computer vision (CV) and remote sensing (RS). Inspired by recent success of deep learning (DL), many advanced object detection and tracking approaches have been widely applied to various UAV-related tasks, such as environmental monitoring, precision agriculture, traffic management. This paper provides a comprehensive survey on the research progress and prospects of DL-based UAV object detection and tracking methods. More specifically, we first outline the challenges, statistics of existing methods, and provide solutions from the perspectives of DL-based models in three research topics: object detection from the image, object detection from the video, and object tracking from the video. Open datasets related to UAV-dominated object detection and tracking are exhausted, and four benchmark datasets are employed for performance evaluation using some state-of-the-art methods. Finally, prospects and considerations for the future work are discussed and summarized. It is expected that this survey can facilitate those researchers who come from remote sensing field with an overview of DL-based UAV object detection and tracking methods, along with some thoughts on their further developments.
SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers
Jul 07, 2021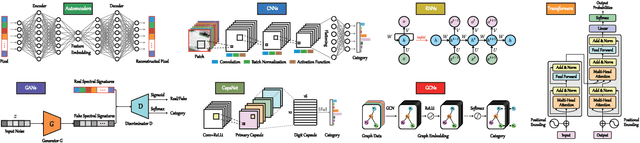
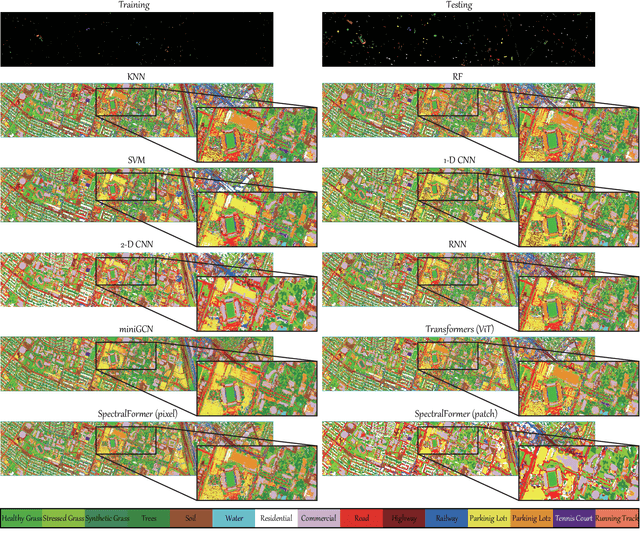
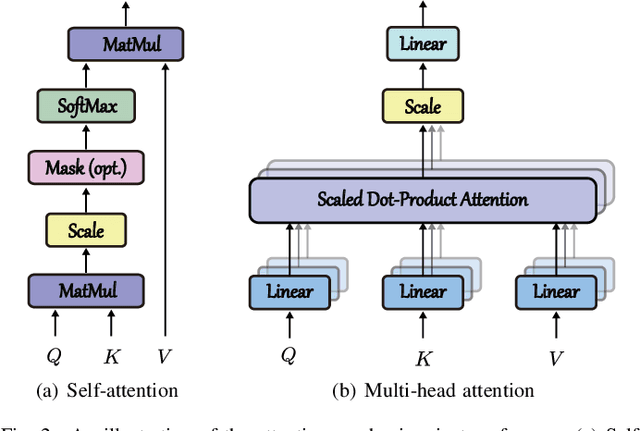
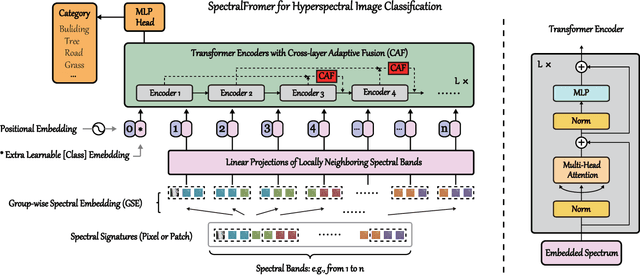
Hyperspectral (HS) images are characterized by approximately contiguous spectral information, enabling the fine identification of materials by capturing subtle spectral discrepancies. Owing to their excellent locally contextual modeling ability, convolutional neural networks (CNNs) have been proven to be a powerful feature extractor in HS image classification. However, CNNs fail to mine and represent the sequence attributes of spectral signatures well due to the limitations of their inherent network backbone. To solve this issue, we rethink HS image classification from a sequential perspective with transformers, and propose a novel backbone network called \ul{SpectralFormer}. Beyond band-wise representations in classic transformers, SpectralFormer is capable of learning spectrally local sequence information from neighboring bands of HS images, yielding group-wise spectral embeddings. More significantly, to reduce the possibility of losing valuable information in the layer-wise propagation process, we devise a cross-layer skip connection to convey memory-like components from shallow to deep layers by adaptively learning to fuse "soft" residuals across layers. It is worth noting that the proposed SpectralFormer is a highly flexible backbone network, which can be applicable to both pixel- and patch-wise inputs. We evaluate the classification performance of the proposed SpectralFormer on three HS datasets by conducting extensive experiments, showing the superiority over classic transformers and achieving a significant improvement in comparison with state-of-the-art backbone networks. The codes of this work will be available at \url{https://sites.google.com/view/danfeng-hong} for the sake of reproducibility.
FCCDN: Feature Constraint Network for VHR Image Change Detection
May 23, 2021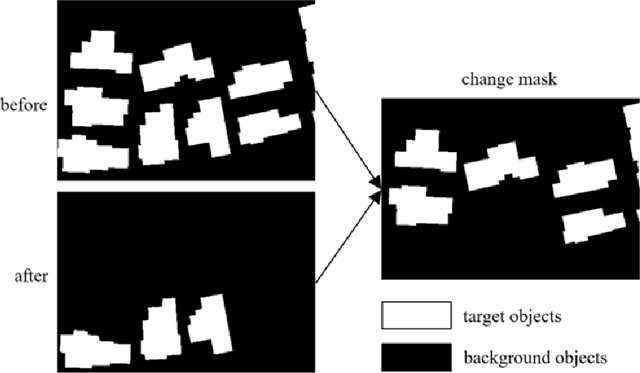

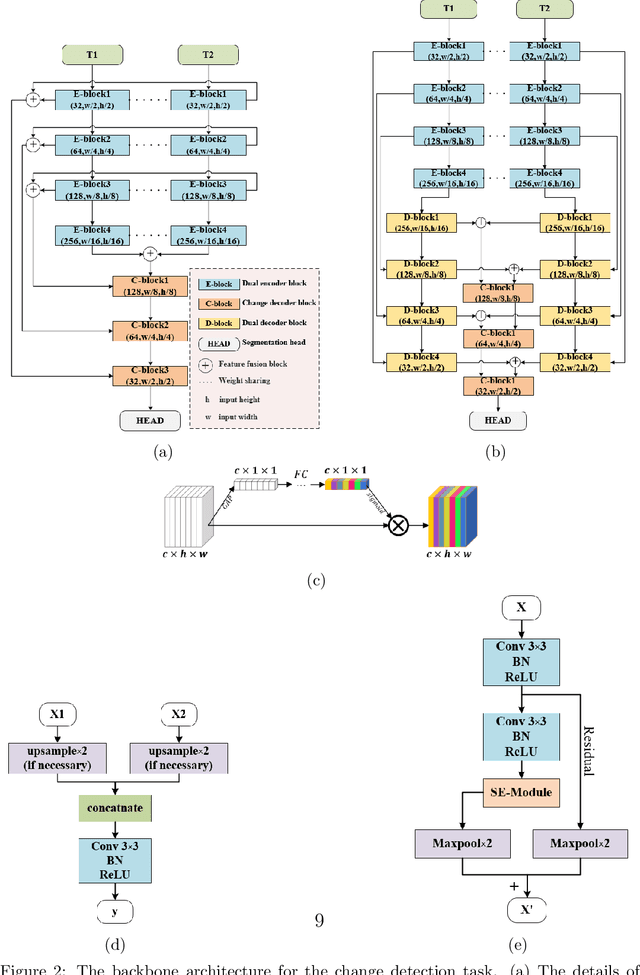
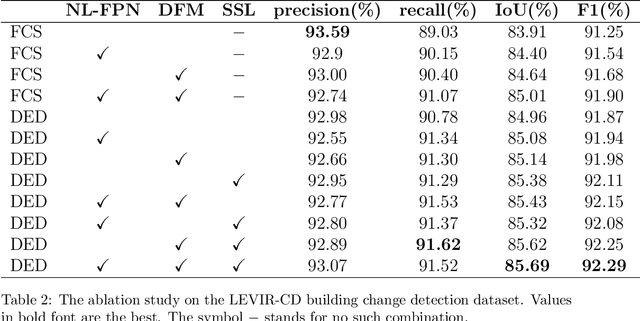
Change detection is the process of identifying pixel-wise differences of bi-temporal co-registered images. It is of great significance to Earth observation. Recently, with the emerging of deep learning (DL), deep convolutional neural networks (CNNs) based methods have shown their power and feasibility in the field of change detection. However, there is still a lack of effective supervision for change feature learning. In this work, a feature constraint change detection network (FCCDN) is proposed. We constrain features both on bi-temporal feature extraction and feature fusion. More specifically, we propose a dual encoder-decoder network backbone for the change detection task. At the center of the backbone, we design a non-local feature pyramid network to extract and fuse multi-scale features. To fuse bi-temporal features in a robust way, we build a dense connection-based feature fusion module. Moreover, a self-supervised learning-based strategy is proposed to constrain feature learning. Based on FCCDN, we achieve state-of-the-art performance on two building change detection datasets (LEVIR-CD and WHU). On the LEVIR-CD dataset, we achieve IoU of 0.8569 and F1 score of 0.9229. On the WHU dataset, we achieve IoU of 0.8820 and F1 score of 0.9373. Moreover, we, for the first time, achieve the acquire of accurate bi-temporal semantic segmentation results without using semantic segmentation labels. It is vital for the application of change detection because it saves the cost of labeling.
Multimodal Remote Sensing Benchmark Datasets for Land Cover Classification with A Shared and Specific Feature Learning Model
May 21, 2021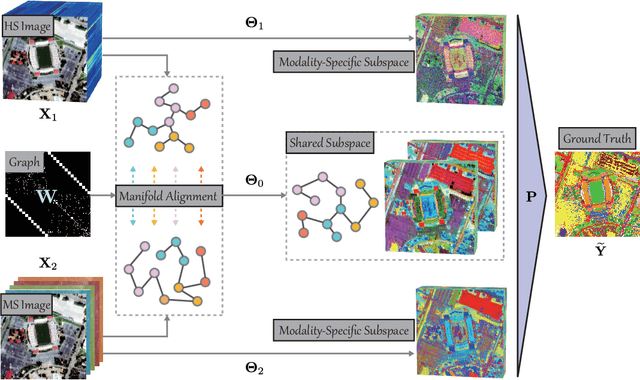

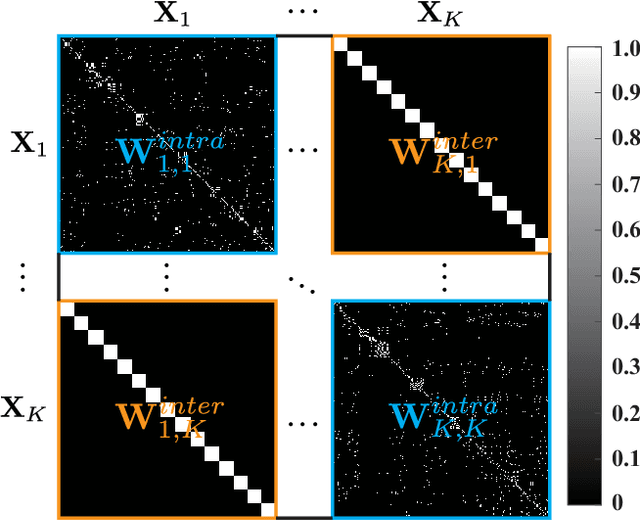
As remote sensing (RS) data obtained from different sensors become available largely and openly, multimodal data processing and analysis techniques have been garnering increasing interest in the RS and geoscience community. However, due to the gap between different modalities in terms of imaging sensors, resolutions, and contents, embedding their complementary information into a consistent, compact, accurate, and discriminative representation, to a great extent, remains challenging. To this end, we propose a shared and specific feature learning (S2FL) model. S2FL is capable of decomposing multimodal RS data into modality-shared and modality-specific components, enabling the information blending of multi-modalities more effectively, particularly for heterogeneous data sources. Moreover, to better assess multimodal baselines and the newly-proposed S2FL model, three multimodal RS benchmark datasets, i.e., Houston2013 -- hyperspectral and multispectral data, Berlin -- hyperspectral and synthetic aperture radar (SAR) data, Augsburg -- hyperspectral, SAR, and digital surface model (DSM) data, are released and used for land cover classification. Extensive experiments conducted on the three datasets demonstrate the superiority and advancement of our S2FL model in the task of land cover classification in comparison with previously-proposed state-of-the-art baselines. Furthermore, the baseline codes and datasets used in this paper will be made available freely at https://github.com/danfenghong/ISPRS_S2FL.