 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis
Nov 06, 2023We propose SegGen, a highly-effective training data generation method for image segmentation, which pushes the performance limits of state-of-the-art segmentation models to a significant extent. SegGen designs and integrates two data generation strategies: MaskSyn and ImgSyn. (i) MaskSyn synthesizes new mask-image pairs via our proposed text-to-mask generation model and mask-to-image generation model, greatly improving the diversity in segmentation masks for model supervision; (ii) ImgSyn synthesizes new images based on existing masks using the mask-to-image generation model, strongly improving image diversity for model inputs. On the highly competitive ADE20K and COCO benchmarks, our data generation method markedly improves the performance of state-of-the-art segmentation models in semantic segmentation, panoptic segmentation, and instance segmentation. Notably, in terms of the ADE20K mIoU, Mask2Former R50 is largely boosted from 47.2 to 49.9 (+2.7); Mask2Former Swin-L is also significantly increased from 56.1 to 57.4 (+1.3). These promising results strongly suggest the effectiveness of our SegGen even when abundant human-annotated training data is utilized. Moreover, training with our synthetic data makes the segmentation models more robust towards unseen domains. Project website: https://seggenerator.github.io
CoDA: Collaborative Novel Box Discovery and Cross-modal Alignment for Open-vocabulary 3D Object Detection
Oct 04, 2023Open-vocabulary 3D Object Detection (OV-3DDet) aims to detect objects from an arbitrary list of categories within a 3D scene, which remains seldom explored in the literature. There are primarily two fundamental problems in OV-3DDet, i.e., localizing and classifying novel objects. This paper aims at addressing the two problems simultaneously via a unified framework, under the condition of limited base categories. To localize novel 3D objects, we propose an effective 3D Novel Object Discovery strategy, which utilizes both the 3D box geometry priors and 2D semantic open-vocabulary priors to generate pseudo box labels of the novel objects. To classify novel object boxes, we further develop a cross-modal alignment module based on discovered novel boxes, to align feature spaces between 3D point cloud and image/text modalities. Specifically, the alignment process contains a class-agnostic and a class-discriminative alignment, incorporating not only the base objects with annotations but also the increasingly discovered novel objects, resulting in an iteratively enhanced alignment. The novel box discovery and crossmodal alignment are jointly learned to collaboratively benefit each other. The novel object discovery can directly impact the cross-modal alignment, while a better feature alignment can, in turn, boost the localization capability, leading to a unified OV-3DDet framework, named CoDA, for simultaneous novel object localization and classification. Extensive experiments on two challenging datasets (i.e., SUN-RGBD and ScanNet) demonstrate the effectiveness of our method and also show a significant mAP improvement upon the best-performing alternative method by 80%. Codes and pre-trained models are released on the project page.
MCTformer+: Multi-Class Token Transformer for Weakly Supervised Semantic Segmentation
Aug 06, 2023



This paper proposes a novel transformer-based framework that aims to enhance weakly supervised semantic segmentation (WSSS) by generating accurate class-specific object localization maps as pseudo labels. Building upon the observation that the attended regions of the one-class token in the standard vision transformer can contribute to a class-agnostic localization map, we explore the potential of the transformer model to capture class-specific attention for class-discriminative object localization by learning multiple class tokens. We introduce a Multi-Class Token transformer, which incorporates multiple class tokens to enable class-aware interactions with the patch tokens. To achieve this, we devise a class-aware training strategy that establishes a one-to-one correspondence between the output class tokens and the ground-truth class labels. Moreover, a Contrastive-Class-Token (CCT) module is proposed to enhance the learning of discriminative class tokens, enabling the model to better capture the unique characteristics and properties of each class. As a result, class-discriminative object localization maps can be effectively generated by leveraging the class-to-patch attentions associated with different class tokens. To further refine these localization maps, we propose the utilization of patch-level pairwise affinity derived from the patch-to-patch transformer attention. Furthermore, the proposed framework seamlessly complements the Class Activation Mapping (CAM) method, resulting in significantly improved WSSS performance on the PASCAL VOC 2012 and MS COCO 2014 datasets. These results underline the importance of the class token for WSSS.
Learning Unified Decompositional and Compositional NeRF for Editable Novel View Synthesis
Aug 05, 2023



Implicit neural representations have shown powerful capacity in modeling real-world 3D scenes, offering superior performance in novel view synthesis. In this paper, we target a more challenging scenario, i.e., joint scene novel view synthesis and editing based on implicit neural scene representations. State-of-the-art methods in this direction typically consider building separate networks for these two tasks (i.e., view synthesis and editing). Thus, the modeling of interactions and correlations between these two tasks is very limited, which, however, is critical for learning high-quality scene representations. To tackle this problem, in this paper, we propose a unified Neural Radiance Field (NeRF) framework to effectively perform joint scene decomposition and composition for modeling real-world scenes. The decomposition aims at learning disentangled 3D representations of different objects and the background, allowing for scene editing, while scene composition models an entire scene representation for novel view synthesis. Specifically, with a two-stage NeRF framework, we learn a coarse stage for predicting a global radiance field as guidance for point sampling, and in the second fine-grained stage, we perform scene decomposition by a novel one-hot object radiance field regularization module and a pseudo supervision via inpainting to handle ambiguous background regions occluded by objects. The decomposed object-level radiance fields are further composed by using activations from the decomposition module. Extensive quantitative and qualitative results show the effectiveness of our method for scene decomposition and composition, outperforming state-of-the-art methods for both novel-view synthesis and editing tasks.
TaskExpert: Dynamically Assembling Multi-Task Representations with Memorial Mixture-of-Experts
Jul 28, 2023Learning discriminative task-specific features simultaneously for multiple distinct tasks is a fundamental problem in multi-task learning. Recent state-of-the-art models consider directly decoding task-specific features from one shared task-generic feature (e.g., feature from a backbone layer), and utilize carefully designed decoders to produce multi-task features. However, as the input feature is fully shared and each task decoder also shares decoding parameters for different input samples, it leads to a static feature decoding process, producing less discriminative task-specific representations. To tackle this limitation, we propose TaskExpert, a novel multi-task mixture-of-experts model that enables learning multiple representative task-generic feature spaces and decoding task-specific features in a dynamic manner. Specifically, TaskExpert introduces a set of expert networks to decompose the backbone feature into several representative task-generic features. Then, the task-specific features are decoded by using dynamic task-specific gating networks operating on the decomposed task-generic features. Furthermore, to establish long-range modeling of the task-specific representations from different layers of TaskExpert, we design a multi-task feature memory that updates at each layer and acts as an additional feature expert for dynamic task-specific feature decoding. Extensive experiments demonstrate that our TaskExpert clearly outperforms previous best-performing methods on all 9 metrics of two competitive multi-task learning benchmarks for visual scene understanding (i.e., PASCAL-Context and NYUD-v2). Codes and models will be made publicly available at https://github.com/prismformore/Multi-Task-Transformer
* Accepted by ICCV 2023
Implicit Identity Representation Conditioned Memory Compensation Network for Talking Head video Generation
Jul 20, 2023Talking head video generation aims to animate a human face in a still image with dynamic poses and expressions using motion information derived from a target-driving video, while maintaining the person's identity in the source image. However, dramatic and complex motions in the driving video cause ambiguous generation, because the still source image cannot provide sufficient appearance information for occluded regions or delicate expression variations, which produces severe artifacts and significantly degrades the generation quality. To tackle this problem, we propose to learn a global facial representation space, and design a novel implicit identity representation conditioned memory compensation network, coined as MCNet, for high-fidelity talking head generation.~Specifically, we devise a network module to learn a unified spatial facial meta-memory bank from all training samples, which can provide rich facial structure and appearance priors to compensate warped source facial features for the generation. Furthermore, we propose an effective query mechanism based on implicit identity representations learned from the discrete keypoints of the source image. It can greatly facilitate the retrieval of more correlated information from the memory bank for the compensation. Extensive experiments demonstrate that MCNet can learn representative and complementary facial memory, and can clearly outperform previous state-of-the-art talking head generation methods on VoxCeleb1 and CelebV datasets. Please check our \href{https://github.com/harlanhong/ICCV2023-MCNET}{Project}.
Contrastive Multi-Task Dense Prediction
Jul 16, 2023



This paper targets the problem of multi-task dense prediction which aims to achieve simultaneous learning and inference on a bunch of multiple dense prediction tasks in a single framework. A core objective in design is how to effectively model cross-task interactions to achieve a comprehensive improvement on different tasks based on their inherent complementarity and consistency. Existing works typically design extra expensive distillation modules to perform explicit interaction computations among different task-specific features in both training and inference, bringing difficulty in adaptation for different task sets, and reducing efficiency due to clearly increased size of multi-task models. In contrast, we introduce feature-wise contrastive consistency into modeling the cross-task interactions for multi-task dense prediction. We propose a novel multi-task contrastive regularization method based on the consistency to effectively boost the representation learning of the different sub-tasks, which can also be easily generalized to different multi-task dense prediction frameworks, and costs no additional computation in the inference. Extensive experiments on two challenging datasets (i.e. NYUD-v2 and Pascal-Context) clearly demonstrate the superiority of the proposed multi-task contrastive learning approach for dense predictions, establishing new state-of-the-art performances.
InvPT++: Inverted Pyramid Multi-Task Transformer for Visual Scene Understanding
Jun 08, 2023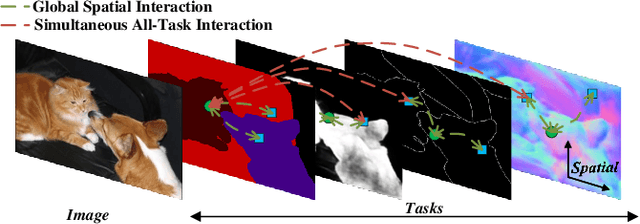

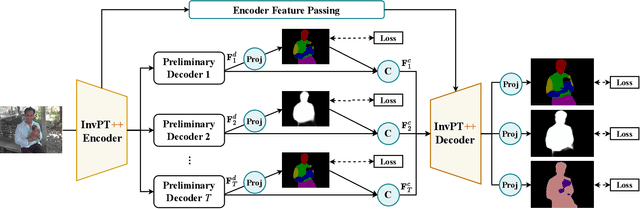
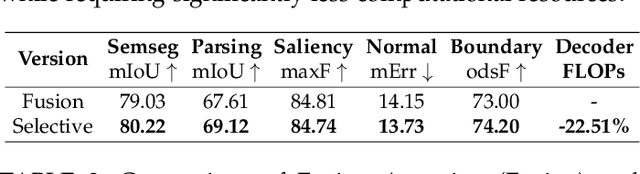
Multi-task scene understanding aims to design models that can simultaneously predict several scene understanding tasks with one versatile model. Previous studies typically process multi-task features in a more local way, and thus cannot effectively learn spatially global and cross-task interactions, which hampers the models' ability to fully leverage the consistency of various tasks in multi-task learning. To tackle this problem, we propose an Inverted Pyramid multi-task Transformer, capable of modeling cross-task interaction among spatial features of different tasks in a global context. Specifically, we first utilize a transformer encoder to capture task-generic features for all tasks. And then, we design a transformer decoder to establish spatial and cross-task interaction globally, and a novel UP-Transformer block is devised to increase the resolutions of multi-task features gradually and establish cross-task interaction at different scales. Furthermore, two types of Cross-Scale Self-Attention modules, i.e., Fusion Attention and Selective Attention, are proposed to efficiently facilitate cross-task interaction across different feature scales. An Encoder Feature Aggregation strategy is further introduced to better model multi-scale information in the decoder. Comprehensive experiments on several 2D/3D multi-task benchmarks clearly demonstrate our proposal's effectiveness, establishing significant state-of-the-art performances.
DaGAN++: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
May 10, 2023Predominant techniques on talking head generation largely depend on 2D information, including facial appearances and motions from input face images. Nevertheless, dense 3D facial geometry, such as pixel-wise depth, plays a critical role in constructing accurate 3D facial structures and suppressing complex background noises for generation. However, dense 3D annotations for facial videos is prohibitively costly to obtain. In this work, firstly, we present a novel self-supervised method for learning dense 3D facial geometry (ie, depth) from face videos, without requiring camera parameters and 3D geometry annotations in training. We further propose a strategy to learn pixel-level uncertainties to perceive more reliable rigid-motion pixels for geometry learning. Secondly, we design an effective geometry-guided facial keypoint estimation module, providing accurate keypoints for generating motion fields. Lastly, we develop a 3D-aware cross-modal (ie, appearance and depth) attention mechanism, which can be applied to each generation layer, to capture facial geometries in a coarse-to-fine manner. Extensive experiments are conducted on three challenging benchmarks (ie, VoxCeleb1, VoxCeleb2, and HDTF). The results demonstrate that our proposed framework can generate highly realistic-looking reenacted talking videos, with new state-of-the-art performances established on these benchmarks. The codes and trained models are publicly available on the GitHub project page at https://github.com/harlanhong/CVPR2022-DaGAN
DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
Apr 10, 2023



This paper presents DetCLIPv2, an efficient and scalable training framework that incorporates large-scale image-text pairs to achieve open-vocabulary object detection (OVD). Unlike previous OVD frameworks that typically rely on a pre-trained vision-language model (e.g., CLIP) or exploit image-text pairs via a pseudo labeling process, DetCLIPv2 directly learns the fine-grained word-region alignment from massive image-text pairs in an end-to-end manner. To accomplish this, we employ a maximum word-region similarity between region proposals and textual words to guide the contrastive objective. To enable the model to gain localization capability while learning broad concepts, DetCLIPv2 is trained with a hybrid supervision from detection, grounding and image-text pair data under a unified data formulation. By jointly training with an alternating scheme and adopting low-resolution input for image-text pairs, DetCLIPv2 exploits image-text pair data efficiently and effectively: DetCLIPv2 utilizes 13X more image-text pairs than DetCLIP with a similar training time and improves performance. With 13M image-text pairs for pre-training, DetCLIPv2 demonstrates superior open-vocabulary detection performance, e.g., DetCLIPv2 with Swin-T backbone achieves 40.4% zero-shot AP on the LVIS benchmark, which outperforms previous works GLIP/GLIPv2/DetCLIP by 14.4/11.4/4.5% AP, respectively, and even beats its fully-supervised counterpart by a large margin.