 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-based Distortions in Contextualized Word Embeddings
Apr 17, 2021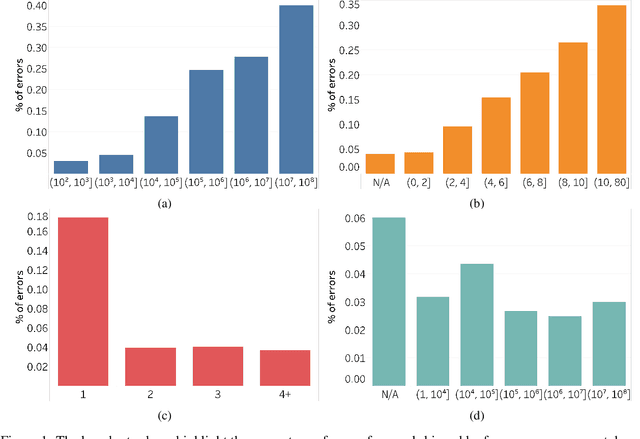
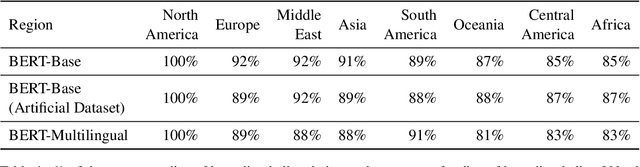
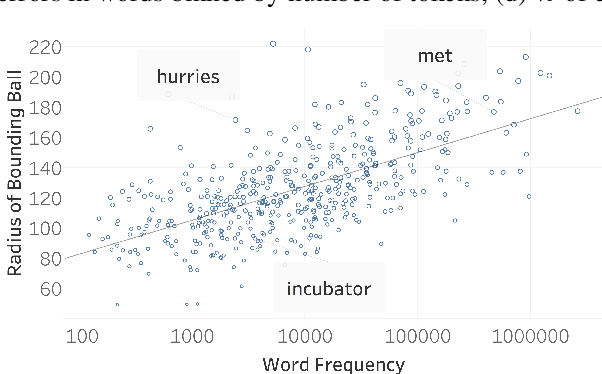
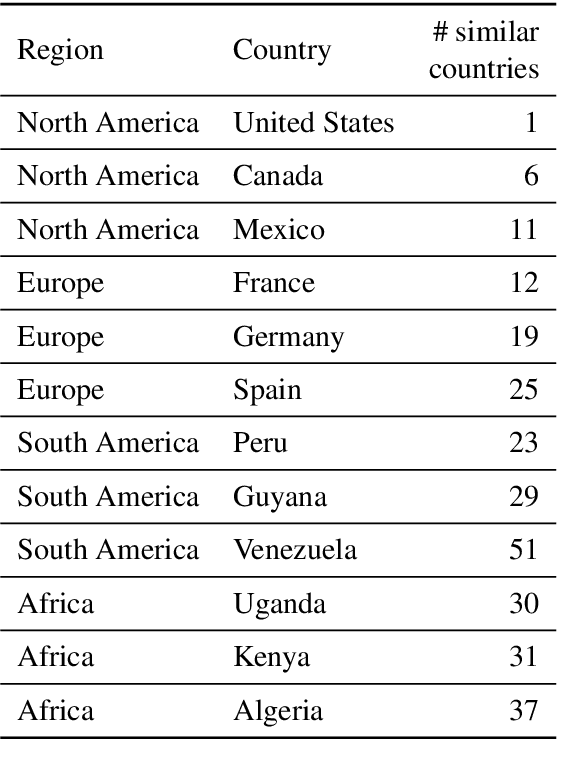
How does word frequency in pre-training data affect the behavior of similarity metrics in contextualized BERT embeddings? Are there systematic ways in which some word relationships are exaggerated or understated? In this work, we explore the geometric characteristics of contextualized word embeddings with two novel tools: (1) an identity probe that predicts the identity of a word using its embedding; (2) the minimal bounding sphere for a word's contextualized representations. Our results reveal that words of high and low frequency differ significantly with respect to their representational geometry. Such differences introduce distortions: when compared to human judgments, point estimates of embedding similarity (e.g., cosine similarity) can over- or under-estimate the semantic similarity of two words, depending on the frequency of those words in the training data. This has downstream societal implications: BERT-Base has more trouble differentiating between South American and African countries than North American and European ones. We find that these distortions persist when using BERT-Multilingual, suggesting that they cannot be easily fixed with additional data, which in turn introduces new distortions.
Leveraging neural representations for facilitating access to untranscribed speech from endangered languages
Mar 26, 2021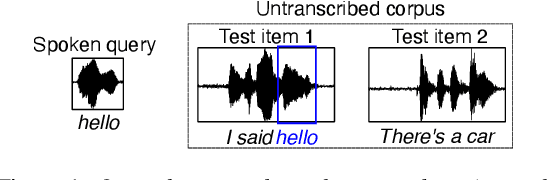
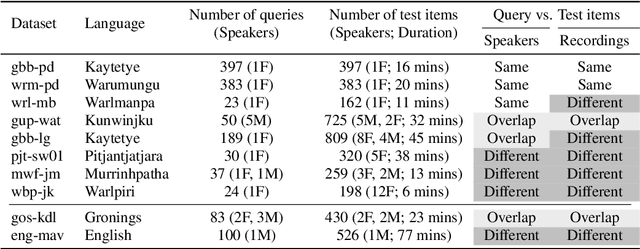
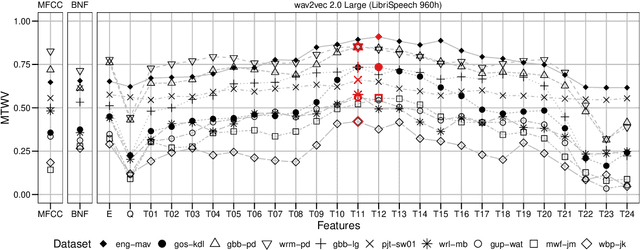
For languages with insufficient resources to train speech recognition systems, query-by-example spoken term detection (QbE-STD) offers a way of accessing an untranscribed speech corpus by helping identify regions where spoken query terms occur. Yet retrieval performance can be poor when the query and corpus are spoken by different speakers and produced in different recording conditions. Using data selected from a variety of speakers and recording conditions from 7 Australian Aboriginal languages and a regional variety of Dutch, all of which are endangered or vulnerable, we evaluated whether QbE-STD performance on these languages could be improved by leveraging representations extracted from the pre-trained English wav2vec 2.0 model. Compared to the use of Mel-frequency cepstral coefficients and bottleneck features, we find that representations from the middle layers of the wav2vec 2.0 Transformer offer large gains in task performance (between 56% and 86%). While features extracted using the pre-trained English model yielded improved detection on all the evaluation languages, better detection performance was associated with the evaluation language's phonological similarity to English.
Language Through a Prism: A Spectral Approach for Multiscale Language Representations
Nov 09, 2020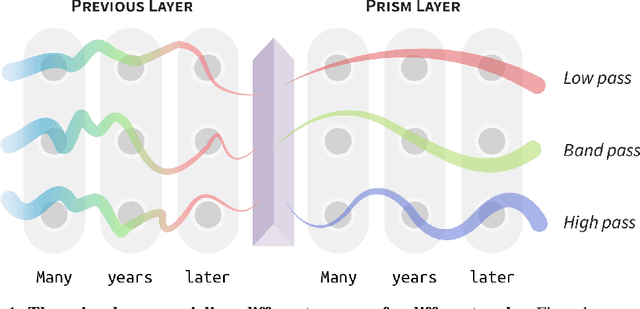
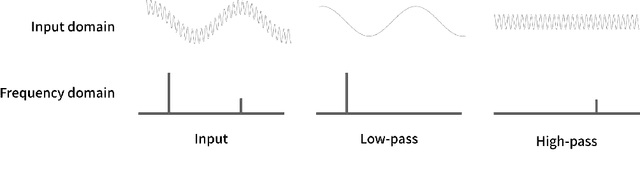
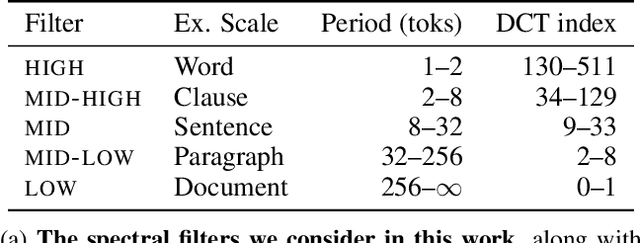
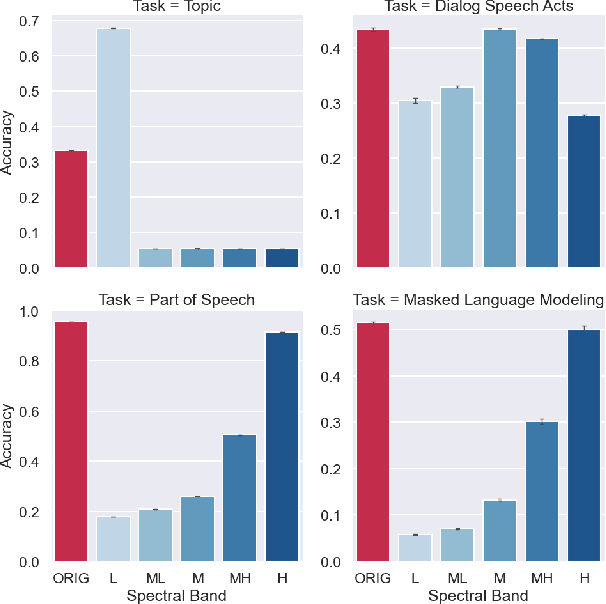
Language exhibits structure at different scales, ranging from subwords to words, sentences, paragraphs, and documents. To what extent do deep models capture information at these scales, and can we force them to better capture structure across this hierarchy? We approach this question by focusing on individual neurons, analyzing the behavior of their activations at different timescales. We show that signal processing provides a natural framework for separating structure across scales, enabling us to 1) disentangle scale-specific information in existing embeddings and 2) train models to learn more about particular scales. Concretely, we apply spectral filters to the activations of a neuron across an input, producing filtered embeddings that perform well on part of speech tagging (word-level), dialog speech acts classification (utterance-level), or topic classification (document-level), while performing poorly on the other tasks. We also present a prism layer for training models, which uses spectral filters to constrain different neurons to model structure at different scales. Our proposed BERT + Prism model can better predict masked tokens using long-range context and produces multiscale representations that perform better at utterance- and document-level tasks. Our methods are general and readily applicable to other domains besides language, such as images, audio, and video.
DeSMOG: Detecting Stance in Media On Global Warming
Oct 28, 2020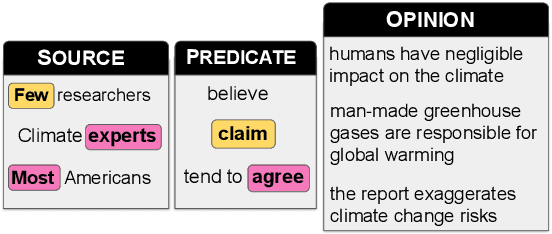
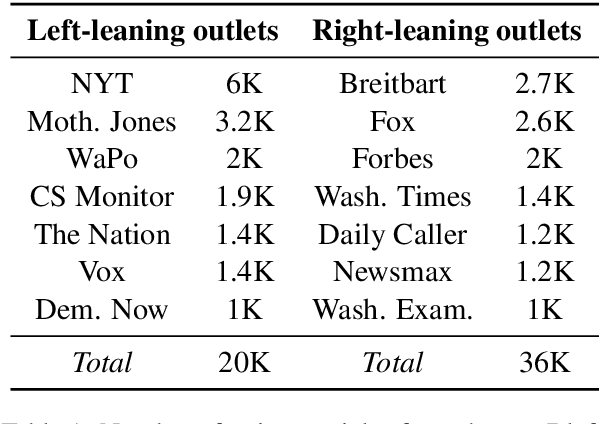
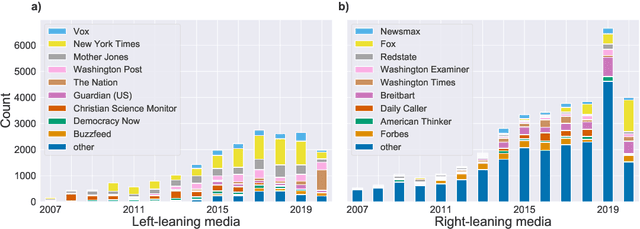
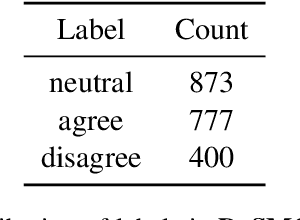
Citing opinions is a powerful yet understudied strategy in argumentation. For example, an environmental activist might say, "Leading scientists agree that global warming is a serious concern," framing a clause which affirms their own stance ("that global warming is serious") as an opinion endorsed ("[scientists] agree") by a reputable source ("leading"). In contrast, a global warming denier might frame the same clause as the opinion of an untrustworthy source with a predicate connoting doubt: "Mistaken scientists claim [...]." Our work studies opinion-framing in the global warming (GW) debate, an increasingly partisan issue that has received little attention in NLP. We introduce DeSMOG, a dataset of stance-labeled GW sentences, and train a BERT classifier to study novel aspects of argumentation in how different sides of a debate represent their own and each other's opinions. From 56K news articles, we find that similar linguistic devices for self-affirming and opponent-doubting discourse are used across GW-accepting and skeptic media, though GW-skeptical media shows more opponent-doubt. We also find that authors often characterize sources as hypocritical, by ascribing opinions expressing the author's own view to source entities known to publicly endorse the opposing view. We release our stance dataset, model, and lexicons of framing devices for future work on opinion-framing and the automatic detection of GW stance.
* 9 pages, 6 figures (excluding references and appendices). To appear in Findings of EMNLP 2020
Causal Effects of Linguistic Properties
Oct 24, 2020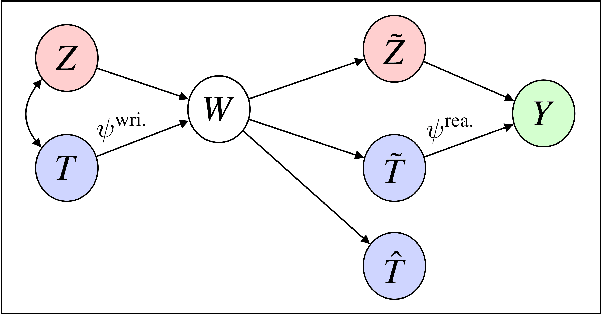
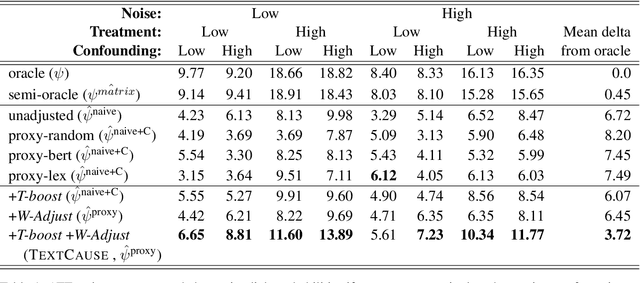
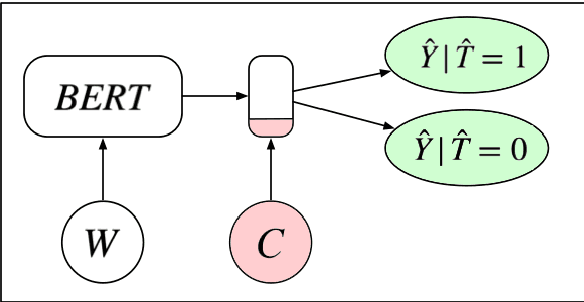

We consider the problem of estimating the causal effects of linguistic properties on downstream outcomes. For example, does writing a complaint politely lead to a faster response time? How much will a positive product review increase sales? This paper focuses on two challenges related to the problem. First, we formalize the causal quantity of interest as the effect of a writer's intent, and establish the assumptions necessary to identify this from observational data. Second, in practice we only have access to noisy proxies for these linguistic properties---e.g., predictions from classifiers and lexicons. We propose an estimator for this setting and prove that its bias is bounded when we perform an adjustment for the text. The method leverages (1) a pre-trained language model (BERT) to adjust for the text, and (2) distant supervision to improve the quality of noisy proxies. We show that our algorithm produces better causal estimates than related methods on two datasets: predicting the effect of music review sentiment on sales, and complaint politeness on response time.
Improving Factual Completeness and Consistency of Image-to-Text Radiology Report Generation
Oct 20, 2020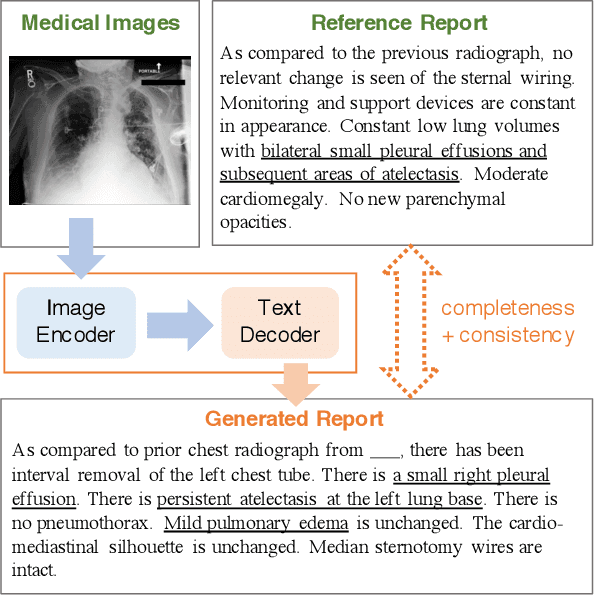

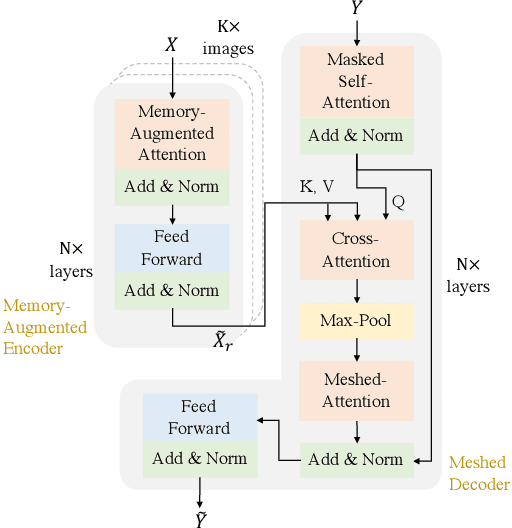
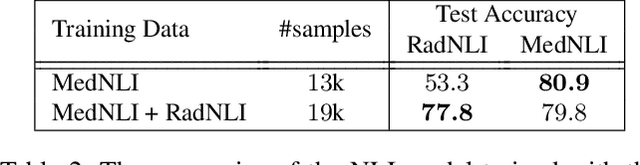
Neural image-to-text radiology report generation systems offer the potential to accelerate clinical processes by saving radiologists from the repetitive labor of drafting radiology reports and preventing medical errors. However, existing report generation systems, despite achieving high performances on natural language generation metrics such as CIDEr or BLEU, still suffer from incomplete and inconsistent generations, rendering these systems unusable in practice. In this work, we aim to overcome this problem by proposing two new metrics that encourage the factual completeness and consistency of generated radiology reports. The first metric, the Exact Entity Match score, evaluates a generation by its coverage of radiology domain entities against the references. The second metric, the Entailing Entity Match score, augments the first metric by introducing a natural language inference model into the entity match process to encourage consistent generations that can be entailed from the references. To achieve this, we also developed an in-domain NLI model via weak supervision to improve its performance on radiology text. We further propose a report generation system that optimizes these two new metrics via reinforcement learning. On two open radiology report datasets, our system not only achieves the best performance on these two metrics compared to baselines, but also leads to as much as +2.0 improvement on the F1 score of a clinical finding metric. We show via analysis and examples that our system leads to generations that are more complete and consistent compared to the baselines.
Utility is in the Eye of the User: A Critique of NLP Leaderboards
Oct 15, 2020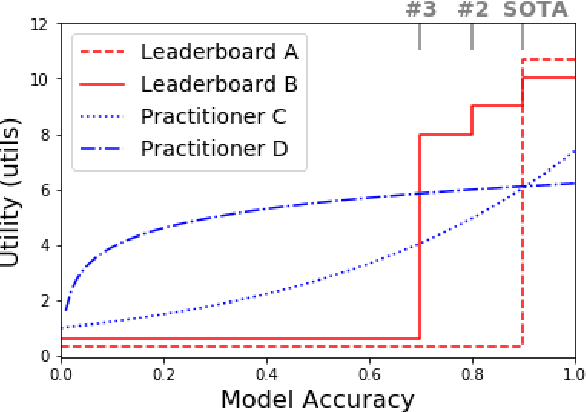
Benchmarks such as GLUE have helped drive advances in NLP by incentivizing the creation of more accurate models. While this leaderboard paradigm has been remarkably successful, a historical focus on performance-based evaluation has been at the expense of other qualities that the NLP community values in models, such as compactness, fairness, and energy efficiency. In this opinion paper, we study the divergence between what is incentivized by leaderboards and what is useful in practice through the lens of microeconomic theory. We frame both the leaderboard and NLP practitioners as consumers and the benefit they get from a model as its utility to them. With this framing, we formalize how leaderboards -- in their current form -- can be poor proxies for the NLP community at large. For example, a highly inefficient model would provide less utility to practitioners but not to a leaderboard, since it is a cost that only the former must bear. To allow practitioners to better estimate a model's utility to them, we advocate for more transparency on leaderboards, such as the reporting of statistics that are of practical concern (e.g., model size, energy efficiency, and inference latency).
With Little Power Comes Great Responsibility
Oct 13, 2020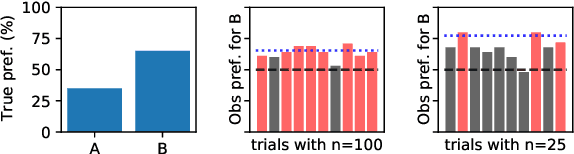

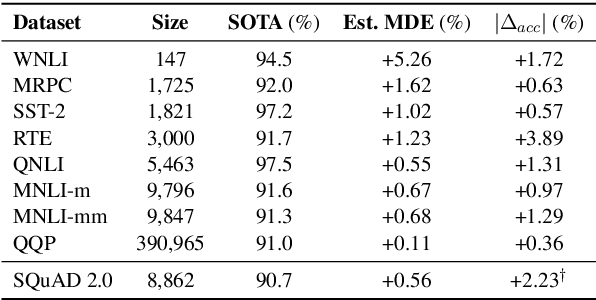
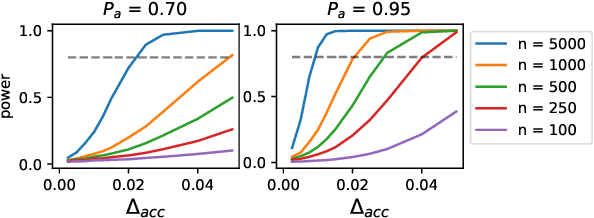
Despite its importance to experimental design, statistical power (the probability that, given a real effect, an experiment will reject the null hypothesis) has largely been ignored by the NLP community. Underpowered experiments make it more difficult to discern the difference between statistical noise and meaningful model improvements, and increase the chances of exaggerated findings. By meta-analyzing a set of existing NLP papers and datasets, we characterize typical power for a variety of settings and conclude that underpowered experiments are common in the NLP literature. In particular, for several tasks in the popular GLUE benchmark, small test sets mean that most attempted comparisons to state of the art models will not be adequately powered. Similarly, based on reasonable assumptions, we find that the most typical experimental design for human rating studies will be underpowered to detect small model differences, of the sort that are frequently studied. For machine translation, we find that typical test sets of 2000 sentences have approximately 75% power to detect differences of 1 BLEU point. To improve the situation going forward, we give an overview of best practices for power analysis in NLP and release a series of notebooks to assist with future power analyses.
Nearest Neighbor Machine Translation
Oct 01, 2020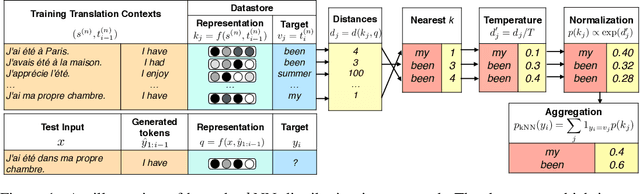
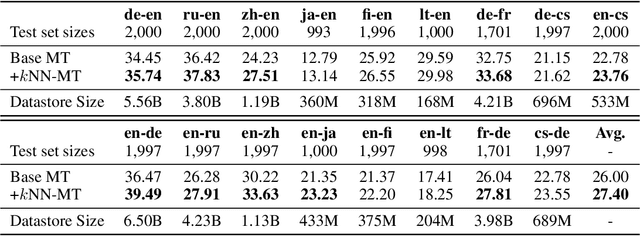
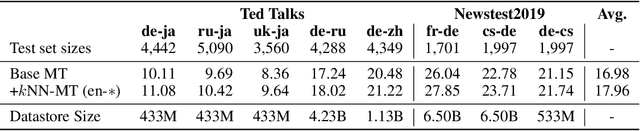
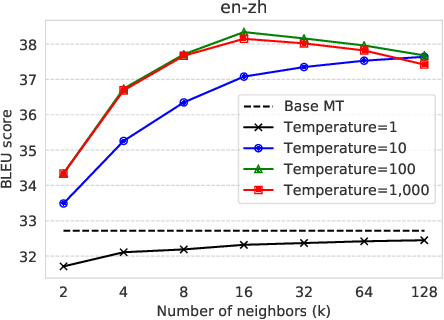
We introduce $k$-nearest-neighbor machine translation ($k$NN-MT), which predicts tokens with a nearest neighbor classifier over a large datastore of cached examples, using representations from a neural translation model for similarity search. This approach requires no additional training and scales to give the decoder direct access to billions of examples at test time, resulting in a highly expressive model that consistently improves performance across many settings. Simply adding nearest neighbor search improves a state-of-the-art German-English translation model by 1.5 BLEU. $k$NN-MT allows a single model to be adapted to diverse domains by using a domain-specific datastore, improving results by an average of 9.2 BLEU over zero-shot transfer, and achieving new state-of-the-art results---without training on these domains. A massively multilingual model can also be specialized for particular language pairs, with improvements of 3 BLEU for translating from English into German and Chinese. Qualitatively, $k$NN-MT is easily interpretable; it combines source and target context to retrieve highly relevant examples.
The Role of Verb Semantics in Hungarian Verb-Object Order
Jun 16, 2020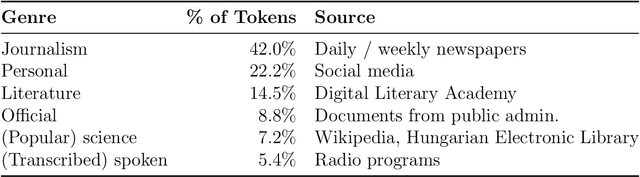
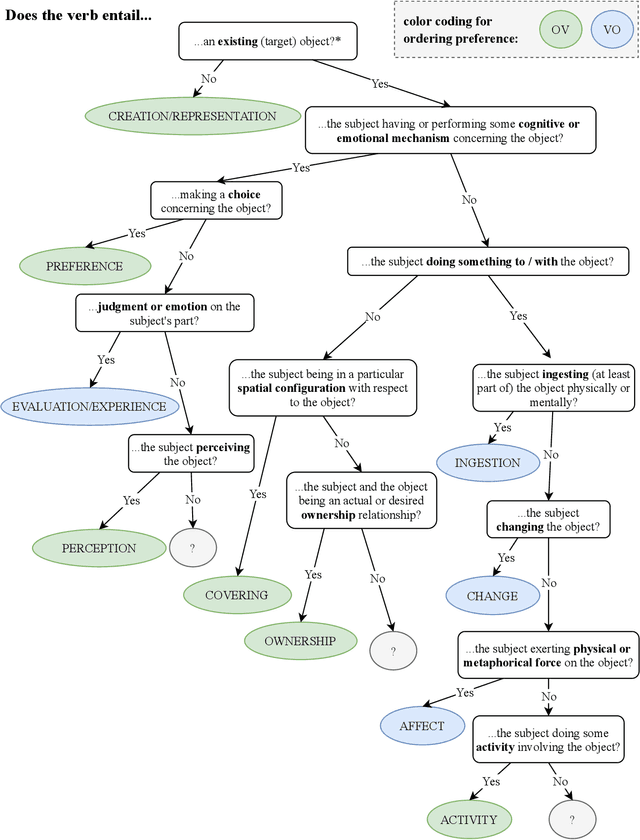
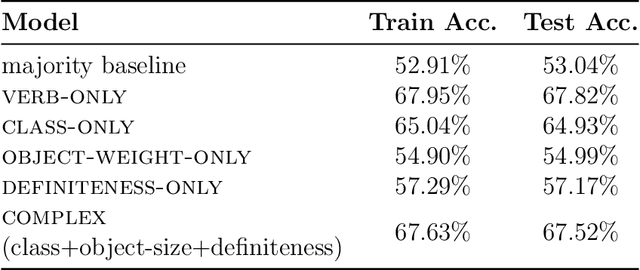
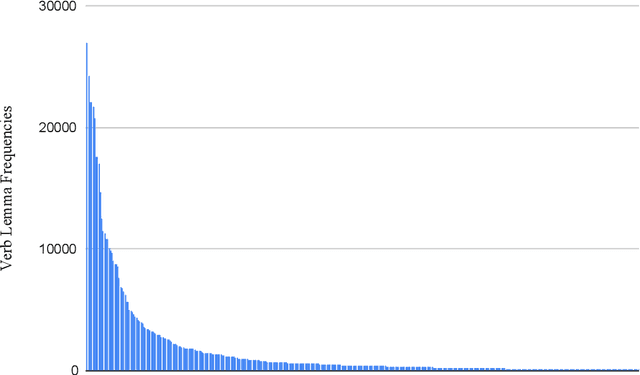
Hungarian is often referred to as a discourse-configurational language, since the structural position of constituents is determined by their logical function (topic or comment) rather than their grammatical function (e.g., subject or object). We build on work by Koml\'osy (1989) and argue that in addition to discourse context, the lexical semantics of the verb also plays a significant role in determining Hungarian word order. In order to investigate the role of lexical semantics in determining Hungarian word order, we conduct a large-scale, data-driven analysis on the ordering of 380 transitive verbs and their objects, as observed in hundreds of thousands of examples extracted from the Hungarian Gigaword Corpus. We test the effect of lexical semantics on the ordering of verbs and their objects by grouping verbs into 11 semantic classes. In addition to the semantic class of the verb, we also include two control features related to information structure, object definiteness and object NP weight, chosen to allow a comparison of their effect size to that of verb semantics. Our results suggest that all three features have a significant effect on verb-object ordering in Hungarian and among these features, the semantic class of the verb has the largest effect. Specifically, we find that stative verbs, such as fed "cover", jelent "mean" and \"ovez "surround", tend to be OV-preferring (with the exception of psych verbs which are strongly VO-preferring) and non-stative verbs, such as b\'ir\'al "judge", cs\"okkent "reduce" and cs\'okol "kiss", verbs tend to be VO-preferring. These findings support our hypothesis that lexical semantic factors influence word order in Hungarian.