 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle Research Football: A Novel Reinforcement Learning Environment
Jul 25, 2019


Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Football Environment, a new reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. The resulting environment is challenging, easy to use and customize, and it is available under a permissive open-source license. In addition, it provides support for multiplayer and multi-agent experiments. We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used reinforcement algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.
MULEX: Disentangling Exploitation from Exploration in Deep RL
Jul 01, 2019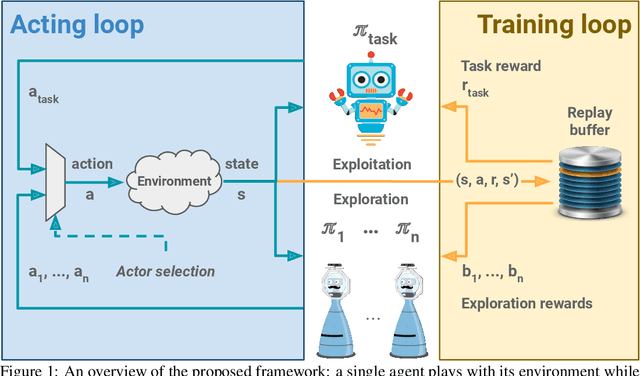
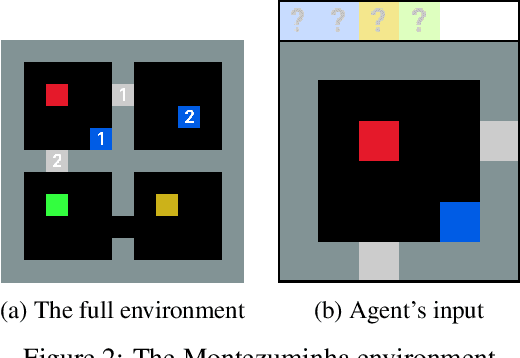
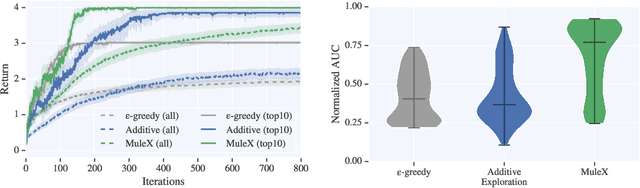
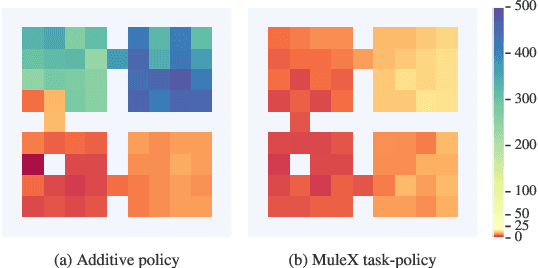
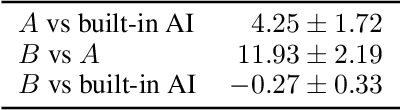
An agent learning through interactions should balance its action selection process between probing the environment to discover new rewards and using the information acquired in the past to adopt useful behaviour. This trade-off is usually obtained by perturbing either the agent's actions (e.g., e-greedy or Gibbs sampling) or the agent's parameters (e.g., NoisyNet), or by modifying the reward it receives (e.g., exploration bonus, intrinsic motivation, or hand-shaped rewards). Here, we adopt a disruptive but simple and generic perspective, where we explicitly disentangle exploration and exploitation. Different losses are optimized in parallel, one of them coming from the true objective (maximizing cumulative rewards from the environment) and others being related to exploration. Every loss is used in turn to learn a policy that generates transitions, all shared in a single replay buffer. Off-policy methods are then applied to these transitions to optimize each loss. We showcase our approach on a hard-exploration environment, show its sample-efficiency and robustness, and discuss further implications.
Adaptive Temporal-Difference Learning for Policy Evaluation with Per-State Uncertainty Estimates
Jun 19, 2019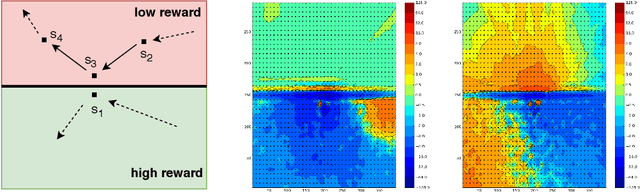
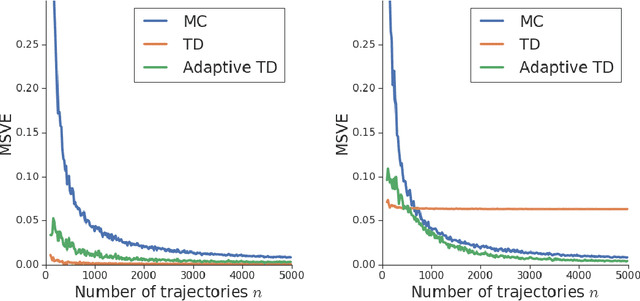
We consider the core reinforcement-learning problem of on-policy value function approximation from a batch of trajectory data, and focus on various issues of Temporal Difference (TD) learning and Monte Carlo (MC) policy evaluation. The two methods are known to achieve complementary bias-variance trade-off properties, with TD tending to achieve lower variance but potentially higher bias. In this paper, we argue that the larger bias of TD can be a result of the amplification of local approximation errors. We address this by proposing an algorithm that adaptively switches between TD and MC in each state, thus mitigating the propagation of errors. Our method is based on learned confidence intervals that detect biases of TD estimates. We demonstrate in a variety of policy evaluation tasks that this simple adaptive algorithm performs competitively with the best approach in hindsight, suggesting that learned confidence intervals are a powerful technique for adapting policy evaluation to use TD or MC returns in a data-driven way.
Episodic Curiosity through Reachability
Feb 22, 2019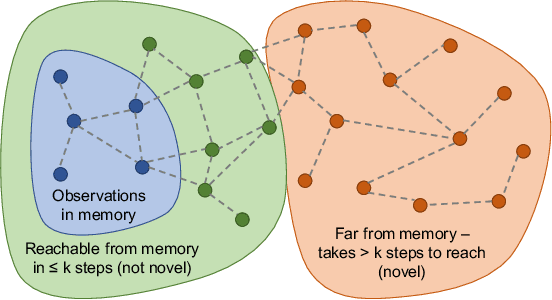
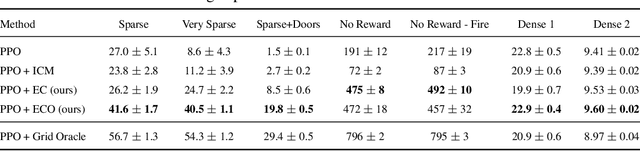
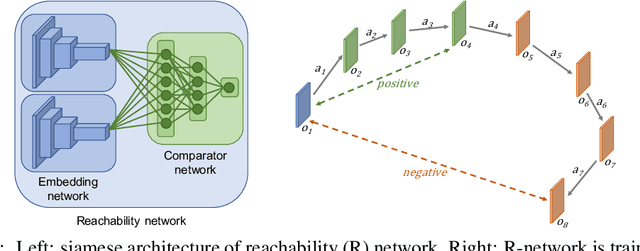
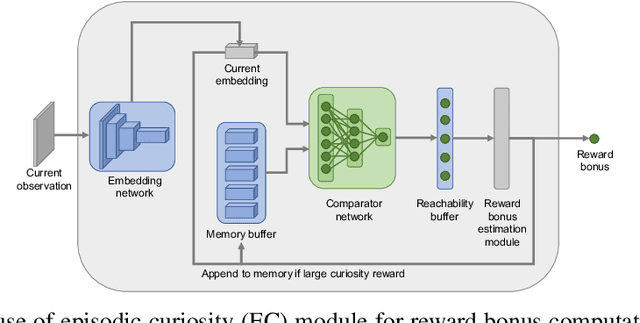
Rewards are sparse in the real world and most today's reinforcement learning algorithms struggle with such sparsity. One solution to this problem is to allow the agent to create rewards for itself - thus making rewards dense and more suitable for learning. In particular, inspired by curious behaviour in animals, observing something novel could be rewarded with a bonus. Such bonus is summed up with the real task reward - making it possible for RL algorithms to learn from the combined reward. We propose a new curiosity method which uses episodic memory to form the novelty bonus. To determine the bonus, the current observation is compared with the observations in memory. Crucially, the comparison is done based on how many environment steps it takes to reach the current observation from those in memory - which incorporates rich information about environment dynamics. This allows us to overcome the known "couch-potato" issues of prior work - when the agent finds a way to instantly gratify itself by exploiting actions which lead to hardly predictable consequences. We test our approach in visually rich 3D environments in ViZDoom, DMLab and MuJoCo. In navigational tasks from ViZDoom and DMLab, our agent outperforms the state-of-the-art curiosity method ICM. In MuJoCo, an ant equipped with our curiosity module learns locomotion out of the first-person-view curiosity only.
Clustering Meets Implicit Generative Models
Aug 02, 2018
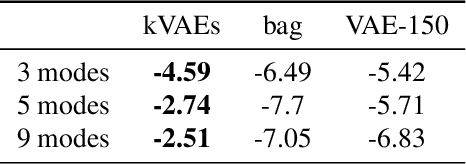
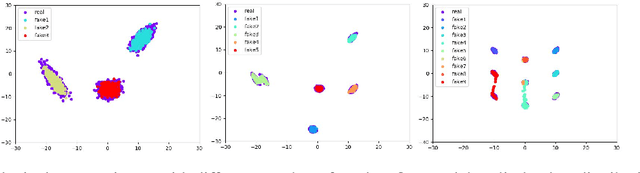
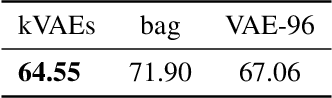
Clustering is a cornerstone of unsupervised learning which can be thought as disentangling the multiple generative mechanisms underlying the data. In this paper we introduce an algorithmic framework to train mixtures of implicit generative models which we instantiate for variational autoencoders. Relying on an additional set of discriminators, we propose a competitive procedure in which the models only need to approximate the portion of the data distribution from which they can produce realistic samples. As a byproduct, each model is simpler to train, and a clustering interpretation arises naturally from the partitioning of the training points among the models. We empirically show that our approach splits the training distribution in a reasonable way and increases the quality of the generated samples.
Temporal Difference Learning with Neural Networks - Study of the Leakage Propagation Problem
Jul 09, 2018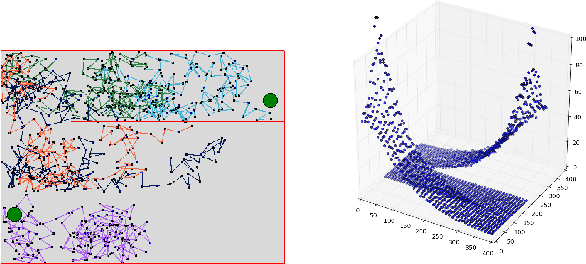
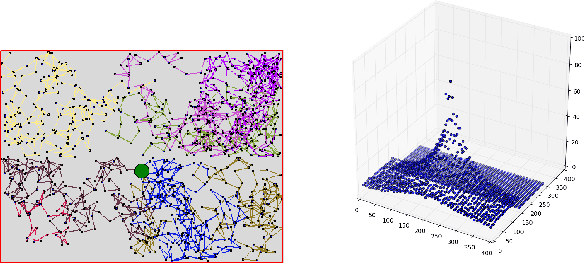
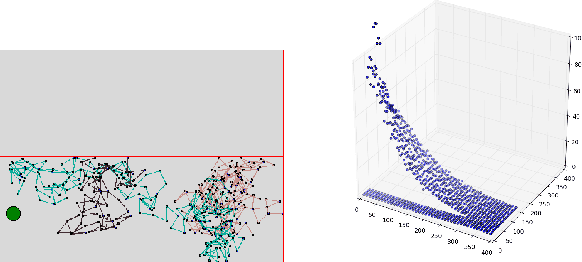
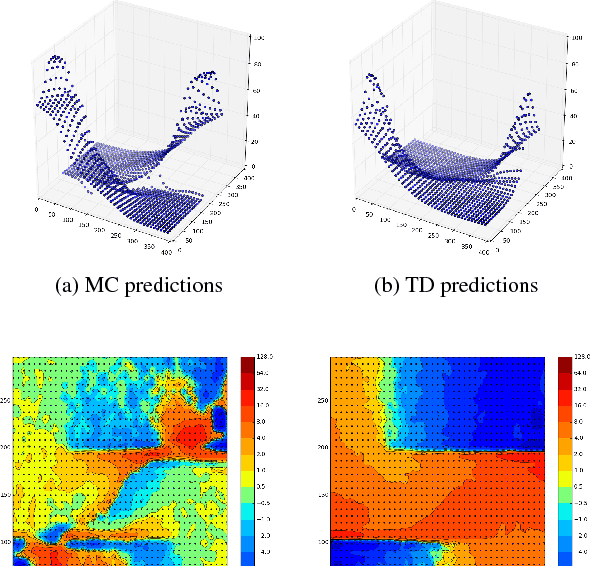
Temporal-Difference learning (TD) [Sutton, 1988] with function approximation can converge to solutions that are worse than those obtained by Monte-Carlo regression, even in the simple case of on-policy evaluation. To increase our understanding of the problem, we investigate the issue of approximation errors in areas of sharp discontinuities of the value function being further propagated by bootstrap updates. We show empirical evidence of this leakage propagation, and show analytically that it must occur, in a simple Markov chain, when function approximation errors are present. For reversible policies, the result can be interpreted as the tension between two terms of the loss function that TD minimises, as recently described by [Ollivier, 2018]. We show that the upper bounds from [Tsitsiklis and Van Roy, 1997] hold, but they do not imply that leakage propagation occurs and under what conditions. Finally, we test whether the problem could be mitigated with a better state representation, and whether it can be learned in an unsupervised manner, without rewards or privileged information.
Spatially adaptive image compression using a tiled deep network
Feb 07, 2018
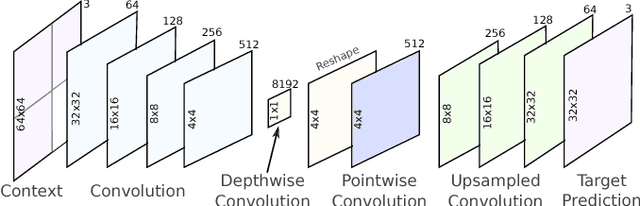

Deep neural networks represent a powerful class of function approximators that can learn to compress and reconstruct images. Existing image compression algorithms based on neural networks learn quantized representations with a constant spatial bit rate across each image. While entropy coding introduces some spatial variation, traditional codecs have benefited significantly by explicitly adapting the bit rate based on local image complexity and visual saliency. This paper introduces an algorithm that combines deep neural networks with quality-sensitive bit rate adaptation using a tiled network. We demonstrate the importance of spatial context prediction and show improved quantitative (PSNR) and qualitative (subjective rater assessment) results compared to a non-adaptive baseline and a recently published image compression model based on fully-convolutional neural networks.
Full Resolution Image Compression with Recurrent Neural Networks
Jul 07, 2017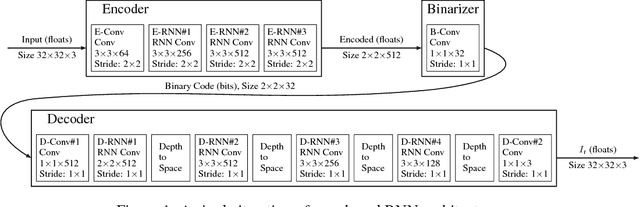
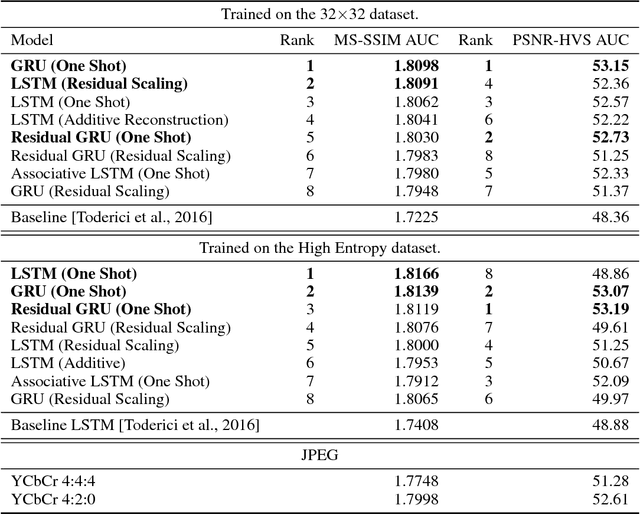
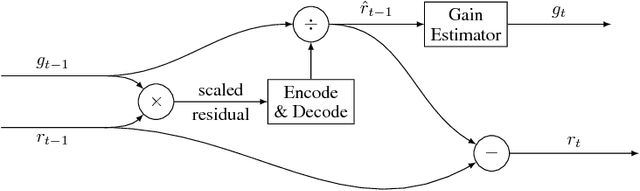
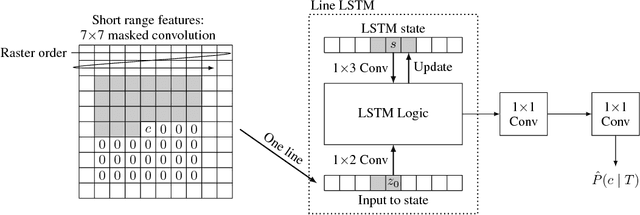
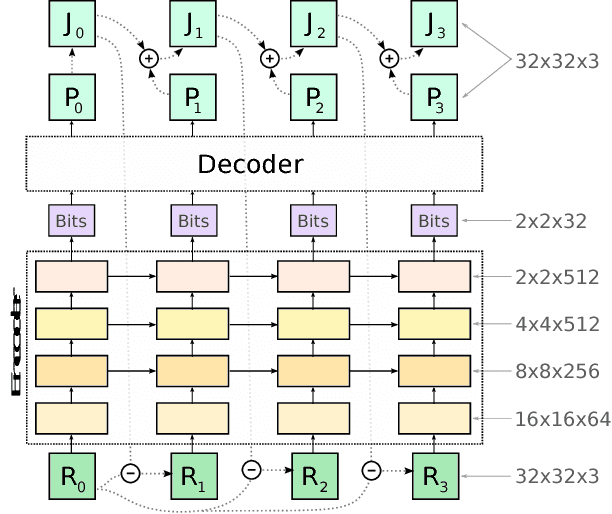
This paper presents a set of full-resolution lossy image compression methods based on neural networks. Each of the architectures we describe can provide variable compression rates during deployment without requiring retraining of the network: each network need only be trained once. All of our architectures consist of a recurrent neural network (RNN)-based encoder and decoder, a binarizer, and a neural network for entropy coding. We compare RNN types (LSTM, associative LSTM) and introduce a new hybrid of GRU and ResNet. We also study "one-shot" versus additive reconstruction architectures and introduce a new scaled-additive framework. We compare to previous work, showing improvements of 4.3%-8.8% AUC (area under the rate-distortion curve), depending on the perceptual metric used. As far as we know, this is the first neural network architecture that is able to outperform JPEG at image compression across most bitrates on the rate-distortion curve on the Kodak dataset images, with and without the aid of entropy coding.
Toward Optimal Run Racing: Application to Deep Learning Calibration
Jun 20, 2017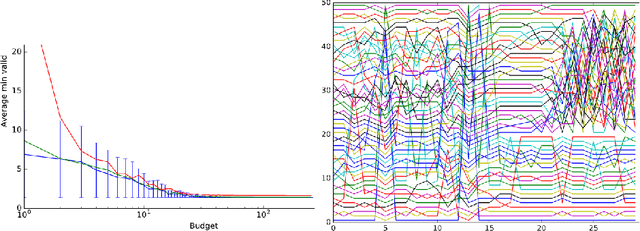
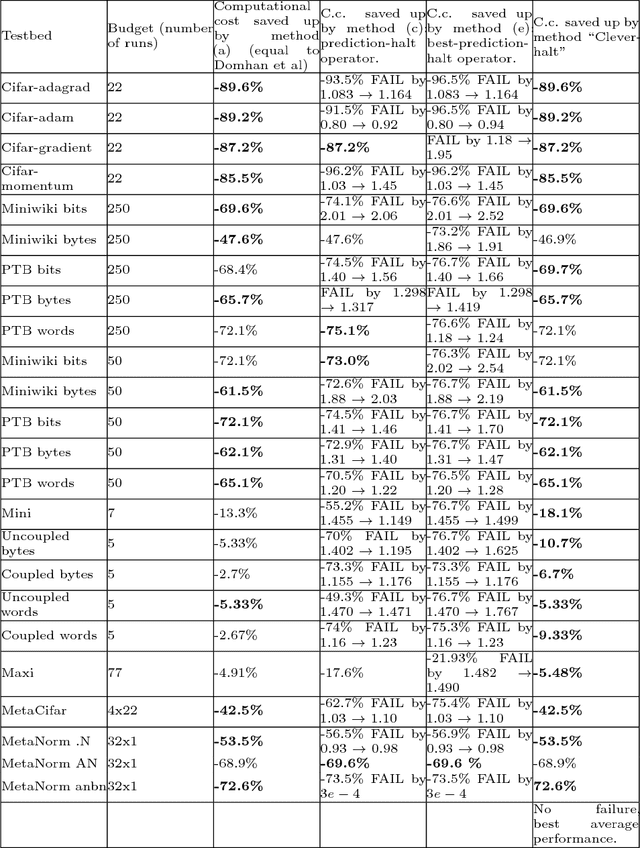
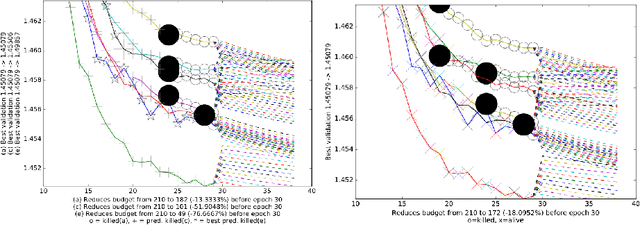
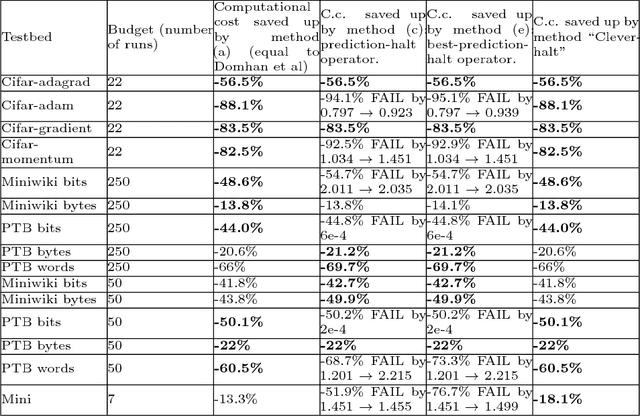
This paper aims at one-shot learning of deep neural nets, where a highly parallel setting is considered to address the algorithm calibration problem - selecting the best neural architecture and learning hyper-parameter values depending on the dataset at hand. The notoriously expensive calibration problem is optimally reduced by detecting and early stopping non-optimal runs. The theoretical contribution regards the optimality guarantees within the multiple hypothesis testing framework. Experimentations on the Cifar10, PTB and Wiki benchmarks demonstrate the relevance of the approach with a principled and consistent improvement on the state of the art with no extra hyper-parameter.
Critical Hyper-Parameters: No Random, No Cry
Jun 10, 2017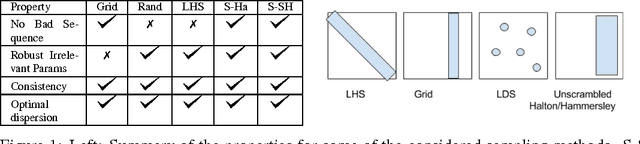
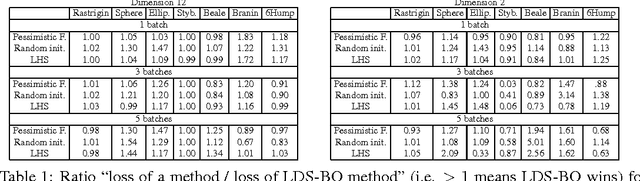

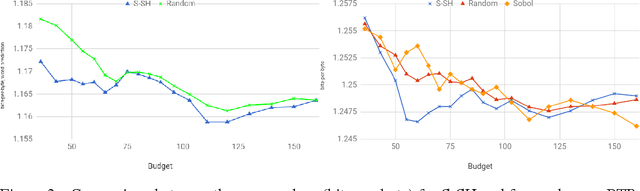
The selection of hyper-parameters is critical in Deep Learning. Because of the long training time of complex models and the availability of compute resources in the cloud, "one-shot" optimization schemes - where the sets of hyper-parameters are selected in advance (e.g. on a grid or in a random manner) and the training is executed in parallel - are commonly used. It is known that grid search is sub-optimal, especially when only a few critical parameters matter, and suggest to use random search instead. Yet, random search can be "unlucky" and produce sets of values that leave some part of the domain unexplored. Quasi-random methods, such as Low Discrepancy Sequences (LDS) avoid these issues. We show that such methods have theoretical properties that make them appealing for performing hyperparameter search, and demonstrate that, when applied to the selection of hyperparameters of complex Deep Learning models (such as state-of-the-art LSTM language models and image classification models), they yield suitable hyperparameters values with much fewer runs than random search. We propose a particularly simple LDS method which can be used as a drop-in replacement for grid or random search in any Deep Learning pipeline, both as a fully one-shot hyperparameter search or as an initializer in iterative batch optimization.