 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo Wide, Then Narrow: Efficient Training of Deep Thin Networks
Jul 01, 2020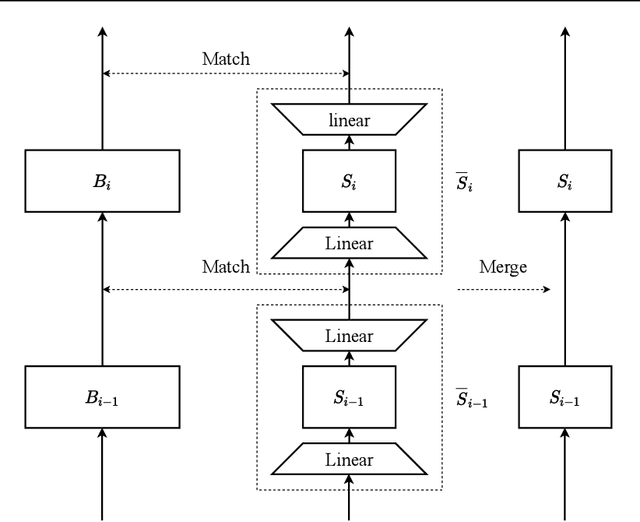
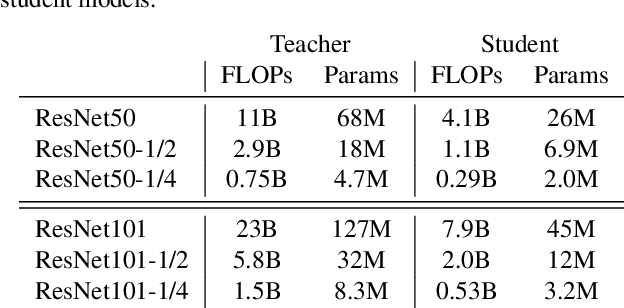
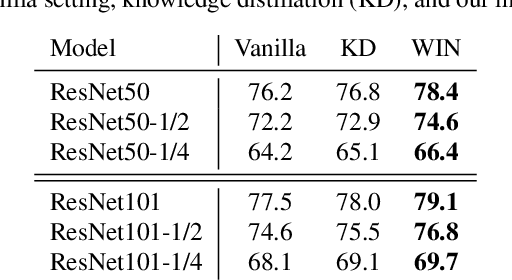
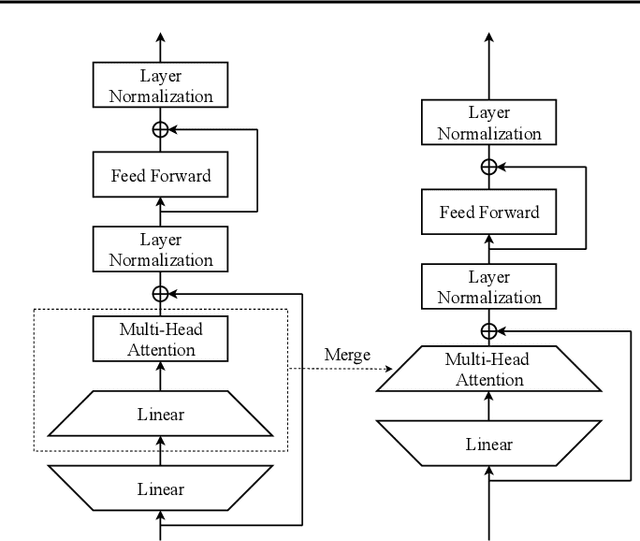
For deploying a deep learning model into production, it needs to be both accurate and compact to meet the latency and memory constraints. This usually results in a network that is deep (to ensure performance) and yet thin (to improve computational efficiency). In this paper, we propose an efficient method to train a deep thin network with a theoretic guarantee. Our method is motivated by model compression. It consists of three stages. In the first stage, we sufficiently widen the deep thin network and train it until convergence. In the second stage, we use this well-trained deep wide network to warm up (or initialize) the original deep thin network. This is achieved by letting the thin network imitate the immediate outputs of the wide network from layer to layer. In the last stage, we further fine tune this well initialized deep thin network. The theoretical guarantee is established by using mean field analysis, which shows the advantage of layerwise imitation over traditional training deep thin networks from scratch by backpropagation. We also conduct large-scale empirical experiments to validate our approach. By training with our method, ResNet50 can outperform ResNet101, and BERT_BASE can be comparable with BERT_LARGE, where both the latter models are trained via the standard training procedures as in the literature.
Scalable Deep Generative Modeling for Sparse Graphs
Jun 28, 2020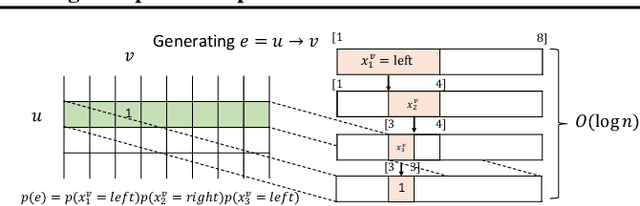
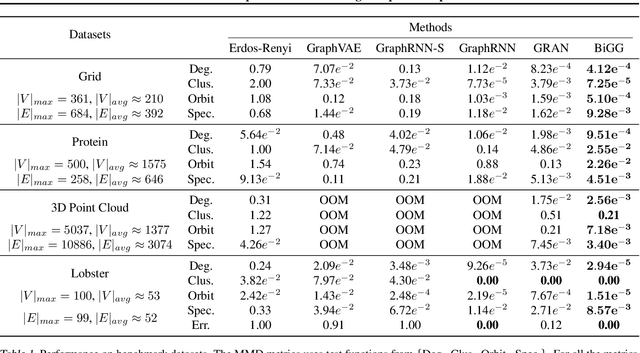
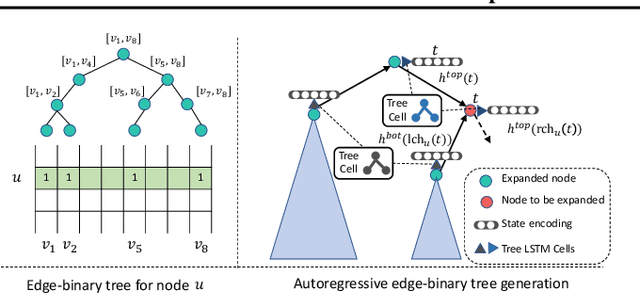

Learning graph generative models is a challenging task for deep learning and has wide applicability to a range of domains like chemistry, biology and social science. However current deep neural methods suffer from limited scalability: for a graph with $n$ nodes and $m$ edges, existing deep neural methods require $\Omega(n^2)$ complexity by building up the adjacency matrix. On the other hand, many real world graphs are actually sparse in the sense that $m\ll n^2$. Based on this, we develop a novel autoregressive model, named BiGG, that utilizes this sparsity to avoid generating the full adjacency matrix, and importantly reduces the graph generation time complexity to $O((n + m)\log n)$. Furthermore, during training this autoregressive model can be parallelized with $O(\log n)$ synchronization stages, which makes it much more efficient than other autoregressive models that require $\Omega(n)$. Experiments on several benchmarks show that the proposed approach not only scales to orders of magnitude larger graphs than previously possible with deep autoregressive graph generative models, but also yields better graph generation quality.
A maximum-entropy approach to off-policy evaluation in average-reward MDPs
Jun 17, 2020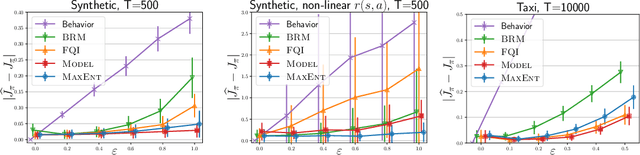
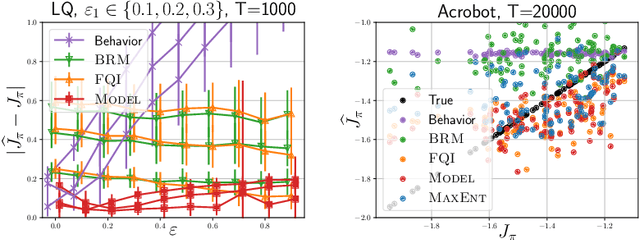
This work focuses on off-policy evaluation (OPE) with function approximation in infinite-horizon undiscounted Markov decision processes (MDPs). For MDPs that are ergodic and linear (i.e. where rewards and dynamics are linear in some known features), we provide the first finite-sample OPE error bound, extending existing results beyond the episodic and discounted cases. In a more general setting, when the feature dynamics are approximately linear and for arbitrary rewards, we propose a new approach for estimating stationary distributions with function approximation. We formulate this problem as finding the maximum-entropy distribution subject to matching feature expectations under empirical dynamics. We show that this results in an exponential-family distribution whose sufficient statistics are the features, paralleling maximum-entropy approaches in supervised learning. We demonstrate the effectiveness of the proposed OPE approaches in multiple environments.
On the Global Convergence Rates of Softmax Policy Gradient Methods
May 13, 2020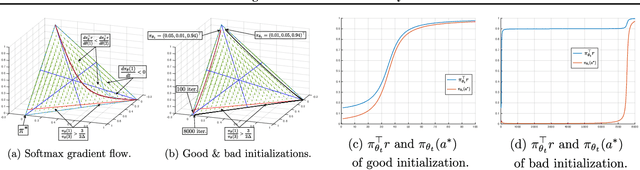
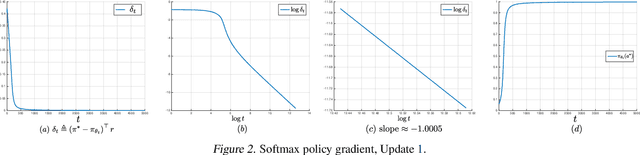
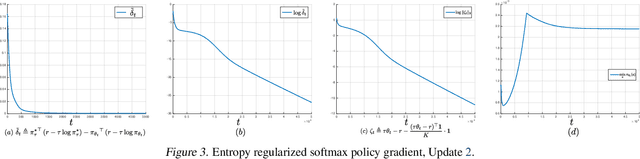
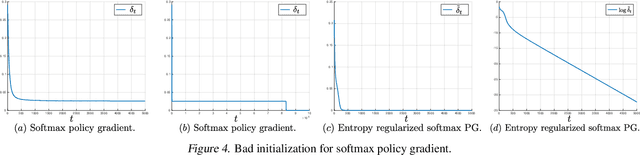
We make three contributions toward better understanding policy gradient methods in the tabular setting. First, we show that with the true gradient, policy gradient with a softmax parametrization converges at a $O(1/t)$ rate, with constants depending on the problem and initialization. This result significantly expands the recent asymptotic convergence results. The analysis relies on two findings: that the softmax policy gradient satisfies a \L{}ojasiewicz inequality, and the minimum probability of an optimal action during optimization can be bounded in terms of its initial value. Second, we analyze entropy regularized policy gradient and show that it enjoys a significantly faster linear convergence rate $O(e^{-t})$ toward softmax optimal policy. This result resolves an open question in the recent literature. Finally, combining the above two results and additional new $\Omega(1/t)$ lower bound results, we explain how entropy regularization improves policy optimization, even with the true gradient, from the perspective of convergence rate. The separation of rates is further explained using the notion of non-uniform \L{}ojasiewicz degree. These results provide a theoretical understanding of the impact of entropy and corroborate existing empirical studies.
Energy-Based Processes for Exchangeable Data
Mar 17, 2020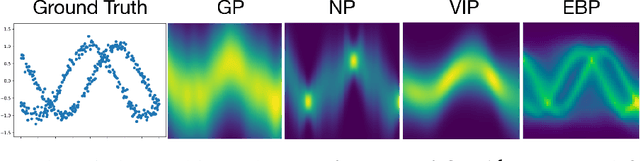
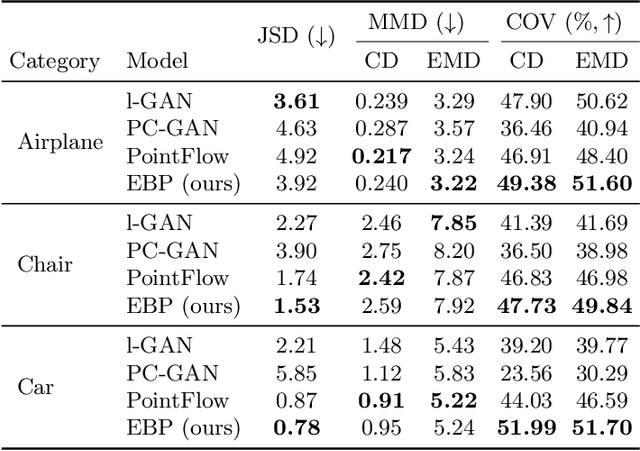


Recently there has been growing interest in modeling sets with exchangeability such as point clouds. A shortcoming of current approaches is that they restrict the cardinality of the sets considered or can only express limited forms of distribution over unobserved data. To overcome these limitations, we introduce Energy-Based Processes (EBPs), which extend energy based models to exchangeable data while allowing neural network parameterizations of the energy function. A key advantage of these models is the ability to express more flexible distributions over sets without restricting their cardinality. We develop an efficient training procedure for EBPs that demonstrates state-of-the-art performance on a variety of tasks such as point cloud generation, classification, denoising, and image completion.
Variational Inference for Deep Probabilistic Canonical Correlation Analysis
Mar 09, 2020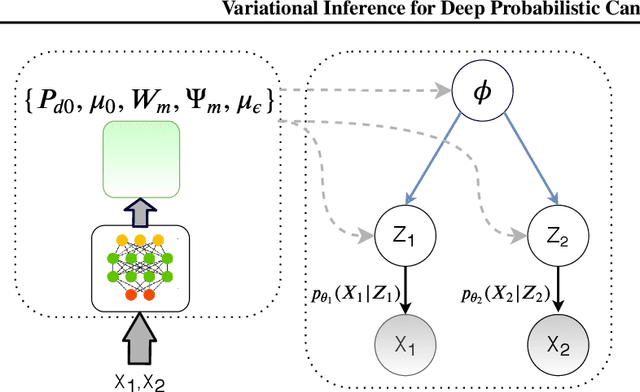
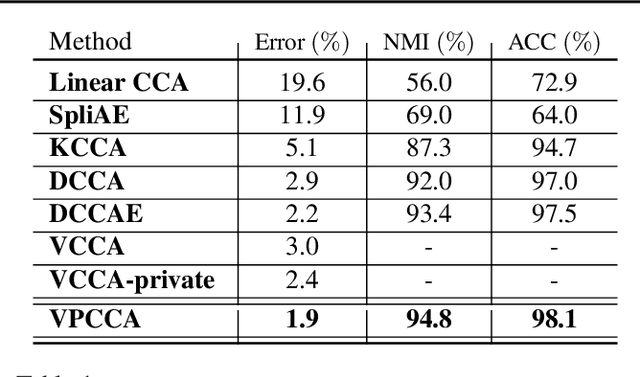

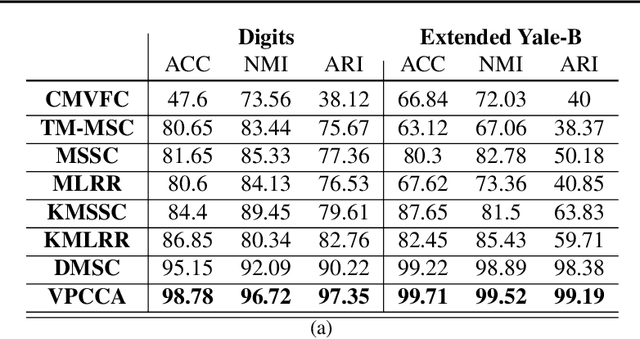
In this paper, we propose a deep probabilistic multi-view model that is composed of a linear multi-view layer based on probabilistic canonical correlation analysis (CCA) description in the latent space together with deep generative networks as observation models. The network is designed to decompose the variations of all views into a shared latent representation and a set of view-specific components where the shared latent representation is intended to describe the common underlying sources of variation among the views. An efficient variational inference procedure is developed that approximates the posterior distributions of the latent probabilistic multi-view layer while taking into account the solution of probabilistic CCA. A generalization to models with arbitrary number of views is also proposed. The empirical studies confirm that the proposed deep generative multi-view model can successfully extend deep variational inference to multi-view learning while it efficiently integrates the relationship between multiple views to alleviate the difficulty of learning.
Batch Stationary Distribution Estimation
Mar 02, 2020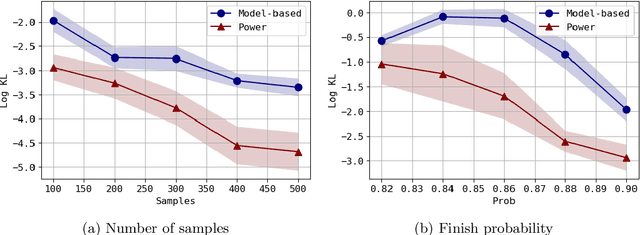
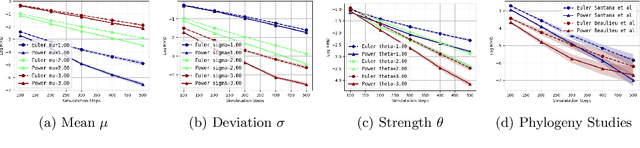
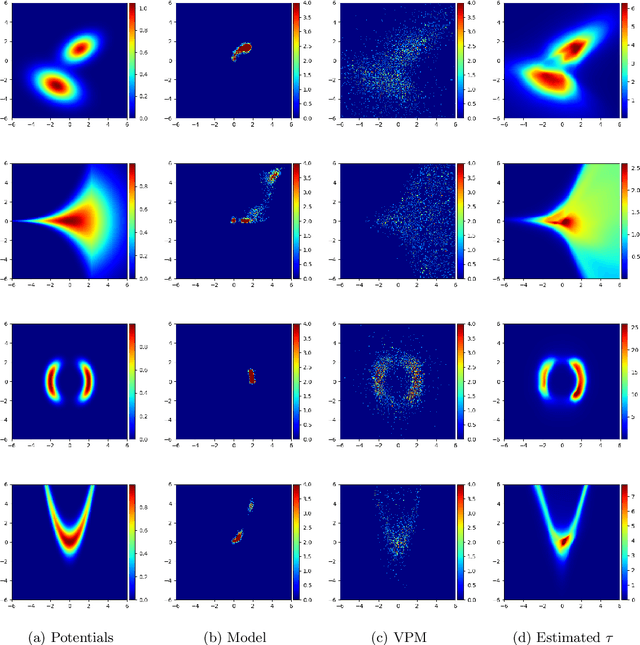
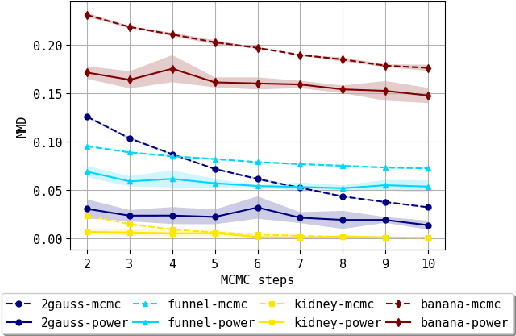
We consider the problem of approximating the stationary distribution of an ergodic Markov chain given a set of sampled transitions. Classical simulation-based approaches assume access to the underlying process so that trajectories of sufficient length can be gathered to approximate stationary sampling. Instead, we consider an alternative setting where a fixed set of transitions has been collected beforehand, by a separate, possibly unknown procedure. The goal is still to estimate properties of the stationary distribution, but without additional access to the underlying system. We propose a consistent estimator that is based on recovering a correction ratio function over the given data. In particular, we develop a variational power method (VPM) that provides provably consistent estimates under general conditions. In addition to unifying a number of existing approaches from different subfields, we also find that VPM yields significantly better estimates across a range of problems, including queueing, stochastic differential equations, post-processing MCMC, and off-policy evaluation.
ConQUR: Mitigating Delusional Bias in Deep Q-learning
Feb 27, 2020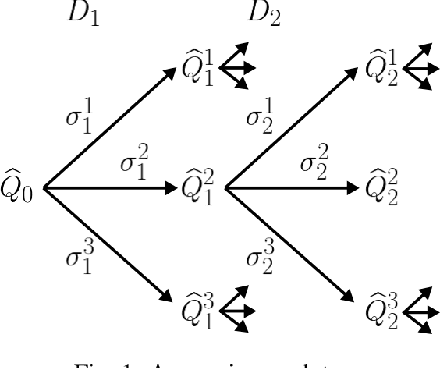
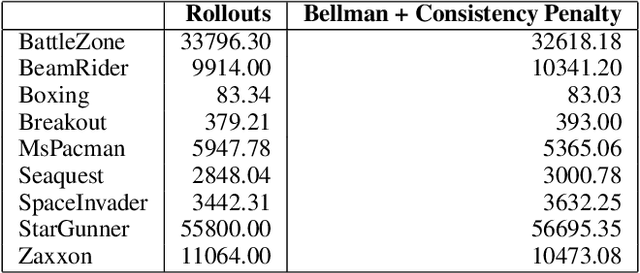
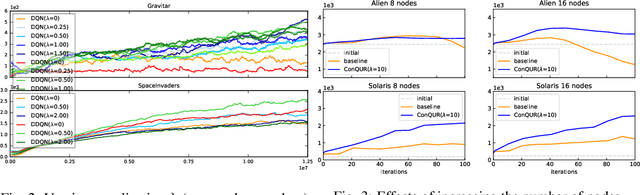
Delusional bias is a fundamental source of error in approximate Q-learning. To date, the only techniques that explicitly address delusion require comprehensive search using tabular value estimates. In this paper, we develop efficient methods to mitigate delusional bias by training Q-approximators with labels that are "consistent" with the underlying greedy policy class. We introduce a simple penalization scheme that encourages Q-labels used across training batches to remain (jointly) consistent with the expressible policy class. We also propose a search framework that allows multiple Q-approximators to be generated and tracked, thus mitigating the effect of premature (implicit) policy commitments. Experimental results demonstrate that these methods can improve the performance of Q-learning in a variety of Atari games, sometimes dramatically.
GenDICE: Generalized Offline Estimation of Stationary Values
Feb 21, 2020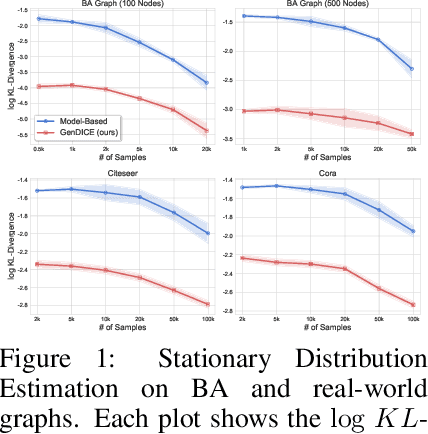
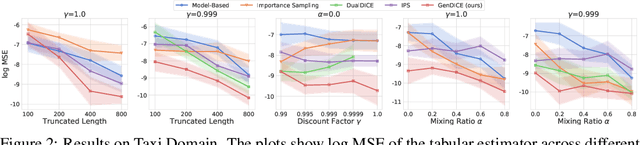
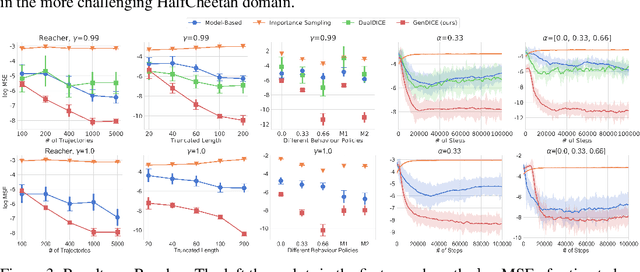
An important problem that arises in reinforcement learning and Monte Carlo methods is estimating quantities defined by the stationary distribution of a Markov chain. In many real-world applications, access to the underlying transition operator is limited to a fixed set of data that has already been collected, without additional interaction with the environment being available. We show that consistent estimation remains possible in this challenging scenario, and that effective estimation can still be achieved in important applications. Our approach is based on estimating a ratio that corrects for the discrepancy between the stationary and empirical distributions, derived from fundamental properties of the stationary distribution, and exploiting constraint reformulations based on variational divergence minimization. The resulting algorithm, GenDICE, is straightforward and effective. We prove its consistency under general conditions, provide an error analysis, and demonstrate strong empirical performance on benchmark problems, including off-line PageRank and off-policy policy evaluation.
Learning to Combat Compounding-Error in Model-Based Reinforcement Learning
Dec 24, 2019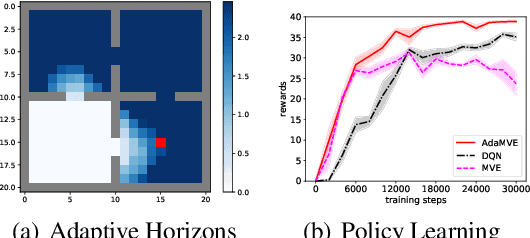
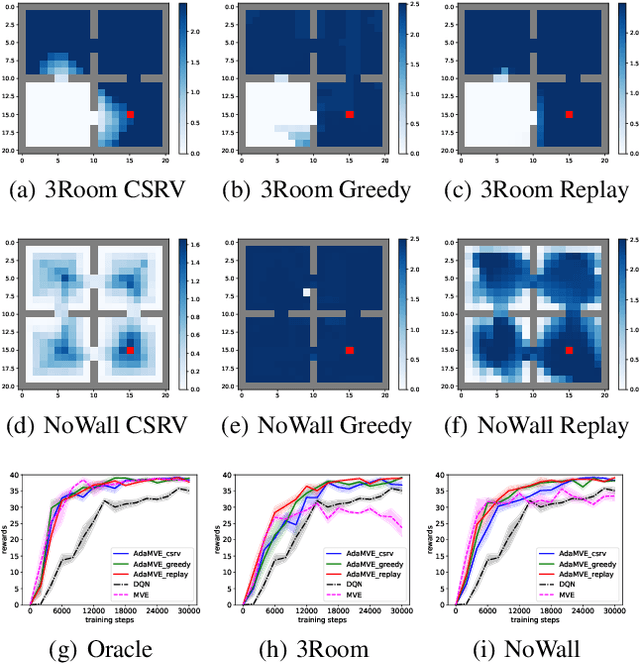
Despite its potential to improve sample complexity versus model-free approaches, model-based reinforcement learning can fail catastrophically if the model is inaccurate. An algorithm should ideally be able to trust an imperfect model over a reasonably long planning horizon, and only rely on model-free updates when the model errors get infeasibly large. In this paper, we investigate techniques for choosing the planning horizon on a state-dependent basis, where a state's planning horizon is determined by the maximum cumulative model error around that state. We demonstrate that these state-dependent model errors can be learned with Temporal Difference methods, based on a novel approach of temporally decomposing the cumulative model errors. Experimental results show that the proposed method can successfully adapt the planning horizon to account for state-dependent model accuracy, significantly improving the efficiency of policy learning compared to model-based and model-free baselines.