 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionformer: A simple, Effective and Unified Baseline for Human Fashion Segmentation and Recognition
Apr 10, 2022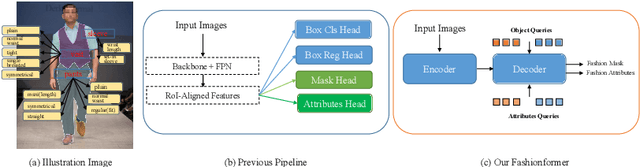
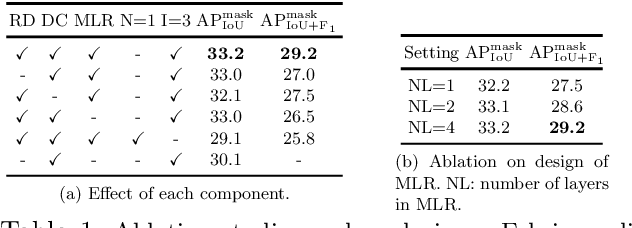
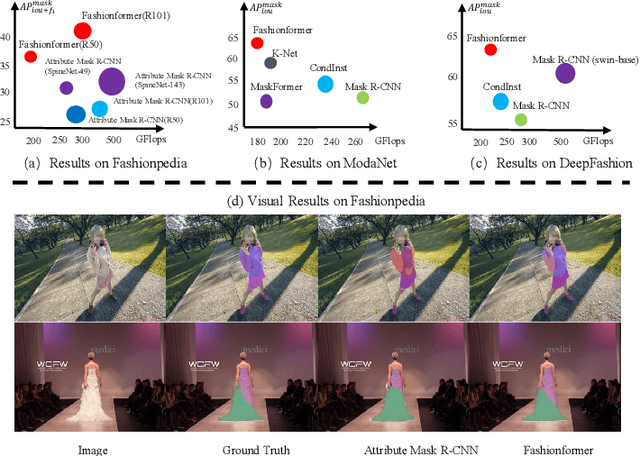
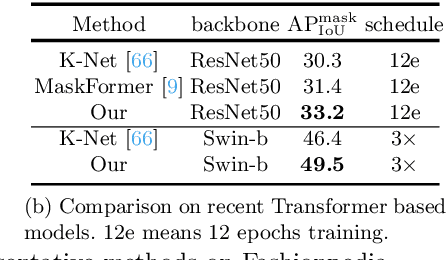
Human fashion understanding is one important computer vision task since it has the comprehensive information that can be used for real-world applications. In this work, we focus on joint human fashion segmentation and attribute recognition. Contrary to the previous works that separately model each task as a multi-head prediction problem, our insight is to bridge these two tasks with one unified model via vision transformer modeling to benefit each task. In particular, we introduce the object query for segmentation and the attribute query for attribute prediction. Both queries and their corresponding features can be linked via mask prediction. Then we adopt a two-stream query learning framework to learn the decoupled query representations. For attribute stream, we design a novel Multi-Layer Rendering module to explore more fine-grained features. The decoder design shares the same spirits with DETR, thus we name the proposed method Fahsionformer. Extensive experiments on three human fashion datasets including Fashionpedia, ModaNet and Deepfashion illustrate the effectiveness of our approach. In particular, our method with the same backbone achieve relative 10% improvements than previous works in case of \textit{a joint metric ( AP$^{\text{mask}}_{\text{IoU+F}_1}$) for both segmentation and attribute recognition}. To the best of our knowledge, we are the first unified end-to-end vision transformer framework for human fashion analysis. We hope this simple yet effective method can serve as a new flexible baseline for fashion analysis. Code will be available at https://github.com/xushilin1/FashionFormer.
An Empirical Study of Remote Sensing Pretraining
Apr 06, 2022
Deep learning has largely reshaped remote sensing research for aerial image understanding. Nevertheless, most of existing deep models are initialized with ImageNet pretrained weights, where the natural images inevitably presents a large domain gap relative to the aerial images, probably limiting the finetuning performance on downstream aerial scene tasks. This issue motivates us to conduct an empirical study of remote sensing pretraining (RSP). To this end, we train different networks from scratch with the help of the largest remote sensing scene recognition dataset up to now-MillionAID, to obtain the remote sensing pretrained backbones, including both convolutional neural networks (CNN) and vision transformers such as Swin and ViTAE, which have shown promising performance on computer vision tasks. Then, we investigate the impact of ImageNet pretraining (IMP) and RSP on a series of downstream tasks including scene recognition, semantic segmentation, object detection, and change detection using the CNN and vision transformers backbones. We have some empirical findings as follows. First, vision transformers generally outperforms CNN backbones, where ViTAE achieves the best performance, owing to its strong representation capacity by introducing intrinsic inductive bias from convolutions to transformers. Second, both IMP and RSP help deliver better performance, where IMP enjoys a versatility by learning more universal representations from diverse images belonging to much more categories while RSP is distinctive in perceiving remote sensing related semantics. Third, RSP mitigates the data discrepancy of IMP for remote sensing but may still suffer from the task discrepancy, where downstream tasks require different representations from the scene recognition task. These findings call for further research efforts on both large-scale pretraining datasets and effective pretraining methods.
BMD: A General Class-balanced Multicentric Dynamic Prototype Strategy for Source-free Domain Adaptation
Apr 06, 2022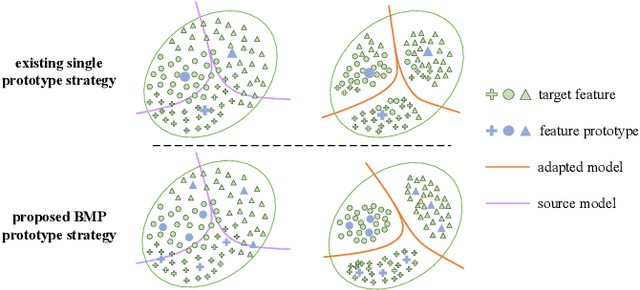
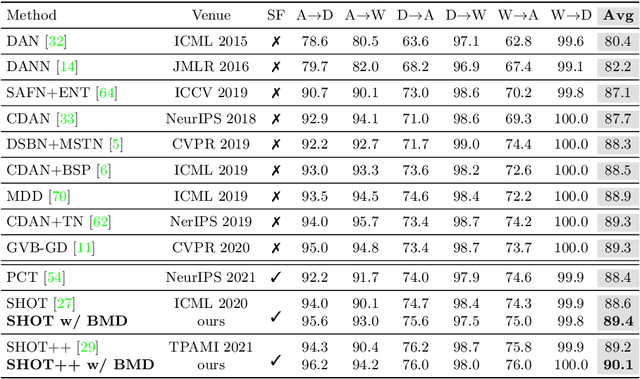
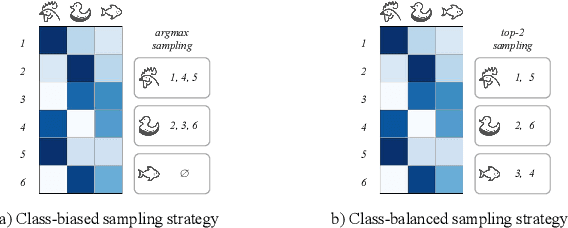
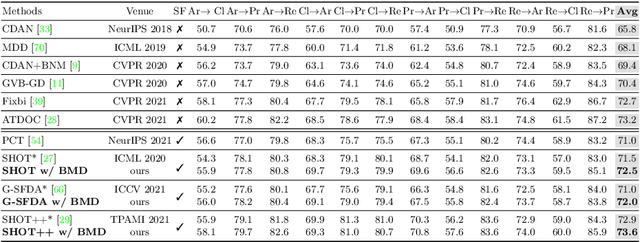
Source-free Domain Adaptation (SFDA) aims to adapt a pre-trained source model to the unlabeled target domain without accessing the well-labeled source data, which is a much more practical setting due to the data privacy, security, and transmission issues. To make up for the absence of source data, most existing methods introduced feature prototype based pseudo-labeling strategies to realize self-training model adaptation. However, feature prototypes are obtained by instance-level predictions based feature clustering, which is category-biased and tends to result in noisy labels since the visual domain gaps between source and target are usually different between categories. In addition, we found that a monocentric feature prototype may be ineffective to represent each category and introduce negative transfer, especially for those hard-transfer data. To address these issues, we propose a general class-Balanced Multicentric Dynamic prototype (BMD) strategy for the SFDA task. Specifically, for each target category, we first introduce a global inter-class balanced sampling strategy to aggregate potential representative target samples. Then, we design an intra-class multicentric clustering strategy to achieve more robust and representative prototypes generation. In contrast to existing strategies that update the pseudo label at a fixed training period, we further introduce a dynamic pseudo labeling strategy to incorporate network update information during model adaptation. Extensive experiments show that the proposed model-agnostic BMD strategy significantly improves representative SFDA methods to yield new state-of-the-art results, e.g., improving SHOT from 82.9\% to 85.8\% on VisDA-C and NRC from 52.6\% to 57.0\% on PointDA. The code is available at https://github.com/ispc-lab/BMD.
BatchFormerV2: Exploring Sample Relationships for Dense Representation Learning
Apr 04, 2022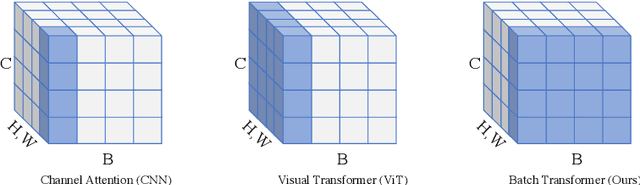
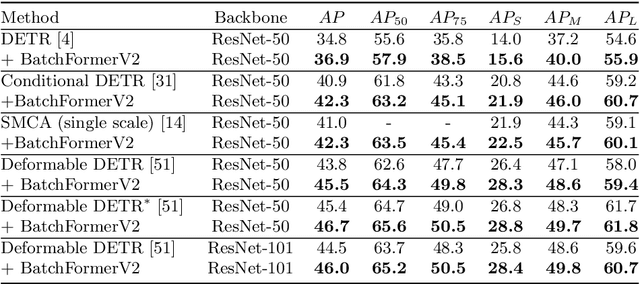
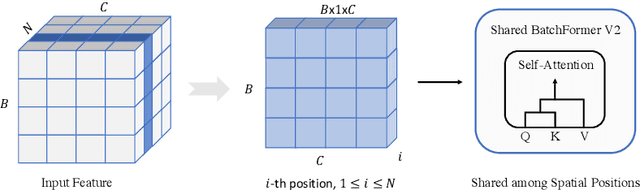

Attention mechanisms have been very popular in deep neural networks, where the Transformer architecture has achieved great success in not only natural language processing but also visual recognition applications. Recently, a new Transformer module, applying on batch dimension rather than spatial/channel dimension, i.e., BatchFormer [18], has been introduced to explore sample relationships for overcoming data scarcity challenges. However, it only works with image-level representations for classification. In this paper, we devise a more general batch Transformer module, BatchFormerV2, which further enables exploring sample relationships for dense representation learning. Specifically, when applying the proposed module, it employs a two-stream pipeline during training, i.e., either with or without a BatchFormerV2 module, where the batchformer stream can be removed for testing. Therefore, the proposed method is a plug-and-play module and can be easily integrated into different vision Transformers without any extra inference cost. Without bells and whistles, we show the effectiveness of the proposed method for a variety of popular visual recognition tasks, including image classification and two important dense prediction tasks: object detection and panoptic segmentation. Particularly, BatchFormerV2 consistently improves current DETR-based detection methods (e.g., DETR, Deformable-DETR, Conditional DETR, and SMCA) by over 1.3%. Code will be made publicly available.
Dynamic Focus-aware Positional Queries for Semantic Segmentation
Apr 04, 2022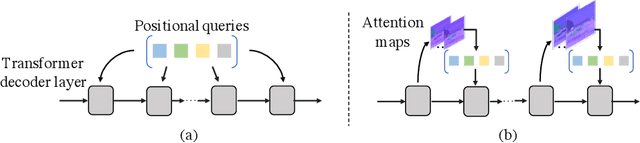
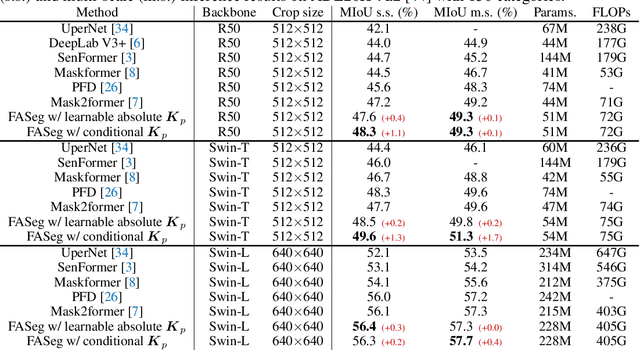
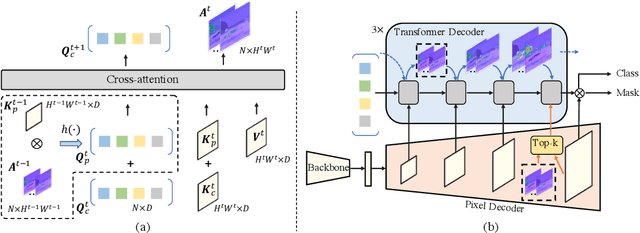
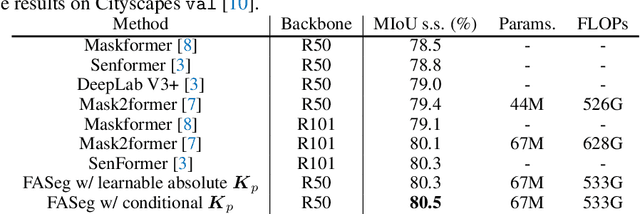
Most of the latest top semantic segmentation approaches are based on vision Transformers, particularly DETR-like frameworks, which employ a set of queries in the Transformer decoder. Each query is composed of a content query that preserves semantic information and a positional query that provides positional guidance for aggregating the query-specific context. However, the positional queries in the Transformer decoder layers are typically represented as fixed learnable weights, which often encode dataset statistics for segments and can be inaccurate for individual samples. Therefore, in this paper, we propose to generate positional queries dynamically conditioned on the cross-attention scores and the localization information of the preceding layer. By doing so, each query is aware of its previous focus, thus providing more accurate positional guidance and encouraging the cross-attention consistency across the decoder layers. In addition, we also propose an efficient way to deal with high-resolution cross-attention by dynamically determining the contextual tokens based on the low-resolution cross-attention maps to perform local relation aggregation. Our overall framework termed FASeg (Focus-Aware semantic Segmentation) provides a simple yet effective solution for semantic segmentation. Extensive experiments on ADE20K and Cityscapes show that our FASeg achieves state-of-the-art performance, e.g., obtaining 48.3% and 49.6% mIoU respectively for single-scale inference on ADE20K validation set with ResNet-50 and Swin-T backbones, and barely increases the computation consumption from Mask2former. Source code will be made publicly available at https://github.com/zip-group/FASeg.
Rethinking Portrait Matting with Privacy Preserving
Mar 31, 2022


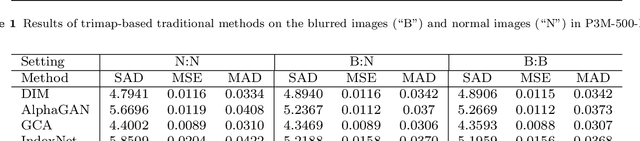
Recently, there has been an increasing concern about the privacy issue raised by using personally identifiable information in machine learning. However, previous portrait matting methods were all based on identifiable portrait images. To fill the gap, we present P3M-10k in this paper, which is the first large-scale anonymized benchmark for Privacy-Preserving Portrait Matting (P3M). P3M-10k consists of 10,000 high-resolution face-blurred portrait images along with high-quality alpha mattes. We systematically evaluate both trimap-free and trimap-based matting methods on P3M-10k and find that existing matting methods show different generalization abilities under the privacy preserving training setting, i.e., training only on face-blurred images while testing on arbitrary images. Based on the gained insights, we propose a unified matting model named P3M-Net consisting of three carefully designed integration modules that can perform privacy-insensitive semantic perception and detail-reserved matting simultaneously. We further design multiple variants of P3M-Net with different CNN and transformer backbones and identify the difference in their generalization abilities. To further mitigate this issue, we devise a simple yet effective Copy and Paste strategy (P3M-CP) that can borrow facial information from public celebrity images without privacy concerns and direct the network to reacquire the face context at both data and feature levels. P3M-CP only brings a few additional computations during training, while enabling the matting model to process both face-blurred and normal images without extra effort during inference. Extensive experiments on P3M-10k demonstrate the superiority of P3M-Net over state-of-the-art methods and the effectiveness of P3M-CP in improving the generalization ability of P3M-Net, implying a great significance of P3M for future research and real-world applications.
BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
Mar 29, 2022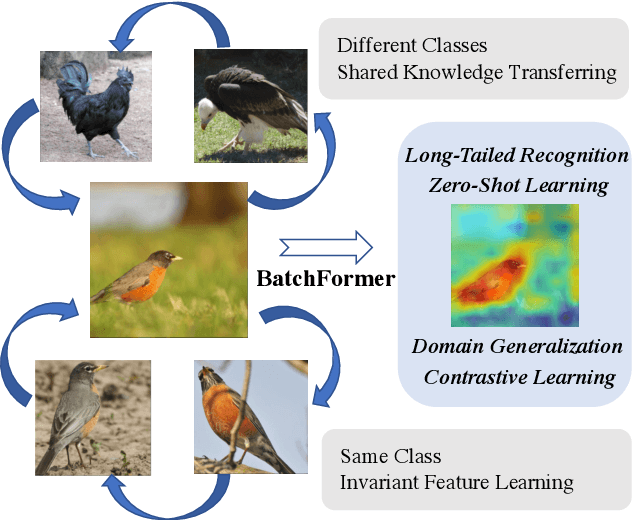
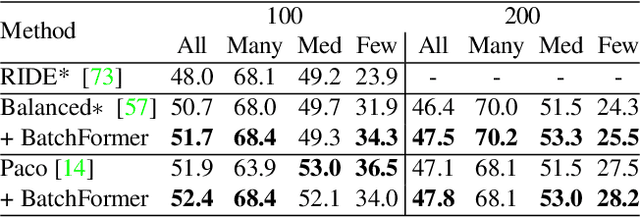
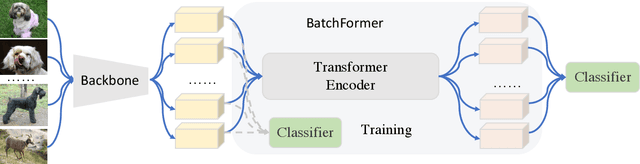
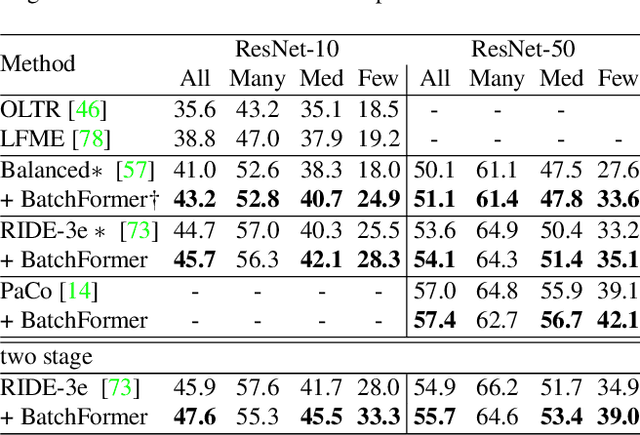
Despite the success of deep neural networks, there are still many challenges in deep representation learning due to the data scarcity issues such as data imbalance, unseen distribution, and domain shift. To address the above-mentioned issues, a variety of methods have been devised to explore the sample relationships in a vanilla way (i.e., from the perspectives of either the input or the loss function), failing to explore the internal structure of deep neural networks for learning with sample relationships. Inspired by this, we propose to enable deep neural networks themselves with the ability to learn the sample relationships from each mini-batch. Specifically, we introduce a batch transformer module or BatchFormer, which is then applied into the batch dimension of each mini-batch to implicitly explore sample relationships during training. By doing this, the proposed method enables the collaboration of different samples, e.g., the head-class samples can also contribute to the learning of the tail classes for long-tailed recognition. Furthermore, to mitigate the gap between training and testing, we share the classifier between with or without the BatchFormer during training, which can thus be removed during testing. We perform extensive experiments on over ten datasets and the proposed method achieves significant improvements on different data scarcity applications without any bells and whistles, including the tasks of long-tailed recognition, compositional zero-shot learning, domain generalization, and contrastive learning. Code will be made publicly available at https://github.com/zhihou7/BatchFormer.
Robust Unlearnable Examples: Protecting Data Against Adversarial Learning
Mar 28, 2022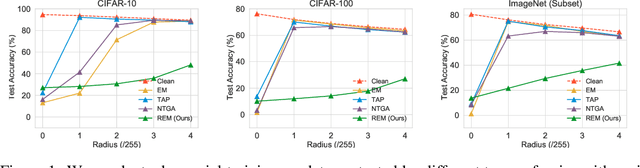
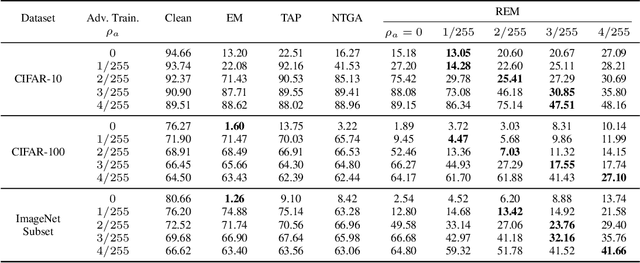
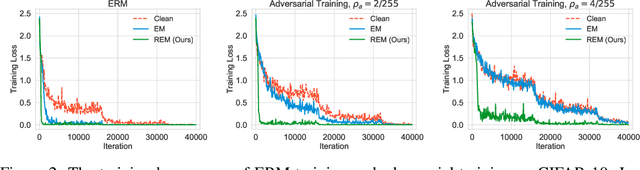
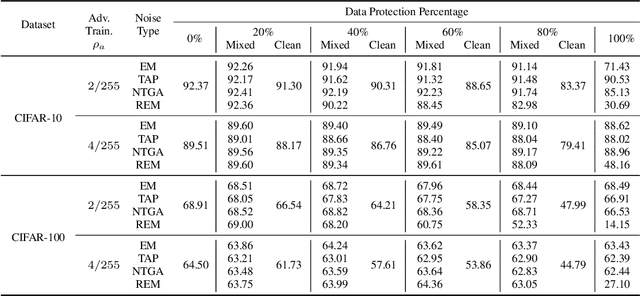
The tremendous amount of accessible data in cyberspace face the risk of being unauthorized used for training deep learning models. To address this concern, methods are proposed to make data unlearnable for deep learning models by adding a type of error-minimizing noise. However, such conferred unlearnability is found fragile to adversarial training. In this paper, we design new methods to generate robust unlearnable examples that are protected from adversarial training. We first find that the vanilla error-minimizing noise, which suppresses the informative knowledge of data via minimizing the corresponding training loss, could not effectively minimize the adversarial training loss. This explains the vulnerability of error-minimizing noise in adversarial training. Based on the observation, robust error-minimizing noise is then introduced to reduce the adversarial training loss. Experiments show that the unlearnability brought by robust error-minimizing noise can effectively protect data from adversarial training in various scenarios. The code is available at \url{https://github.com/fshp971/robust-unlearnable-examples}.
Discovering Human-Object Interaction Concepts via Self-Compositional Learning
Mar 27, 2022
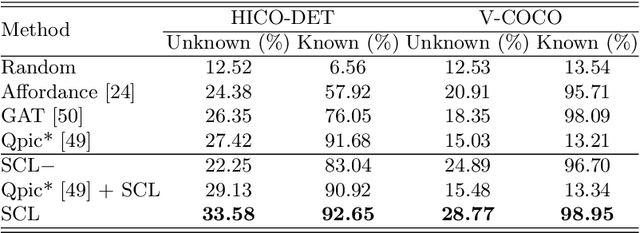
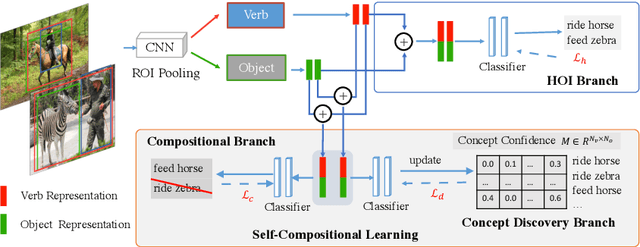
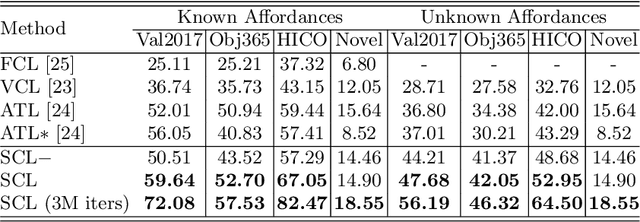
A comprehensive understanding of human-object interaction (HOI) requires detecting not only a small portion of predefined HOI concepts (or categories) but also other reasonable HOI concepts, while current approaches usually fail to explore a huge portion of unknown HOI concepts (i.e., unknown but reasonable combinations of verbs and objects). In this paper, 1) we introduce a novel and challenging task for a comprehensive HOI understanding, which is termed as HOI Concept Discovery; and 2) we devise a self-compositional learning framework (or SCL) for HOI concept discovery. Specifically, we maintain an online updated concept confidence matrix during training: 1) we assign pseudo-labels for all composite HOI instances according to the concept confidence matrix for self-training; and 2) we update the concept confidence matrix using the predictions of all composite HOI instances. Therefore, the proposed method enables the learning on both known and unknown HOI concepts. We perform extensive experiments on several popular HOI datasets to demonstrate the effectiveness of the proposed method for HOI concept discovery, object affordance recognition and HOI detection. For example, the proposed self-compositional learning framework significantly improves the performance of 1) HOI concept discovery by over 10% on HICO-DET and over 3% on V-COCO, respectively; 2) object affordance recognition by over 9% mAP on MS-COCO and HICO-DET; and 3) rare-first and non-rare-first unknown HOI detection relatively over 30% and 20%, respectively. Code and models will be made publicly available at https://github.com/zhihou7/HOI-CL.
Knowledge Removal in Sampling-based Bayesian Inference
Mar 24, 2022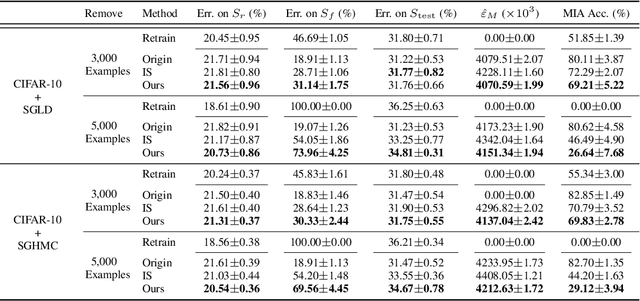
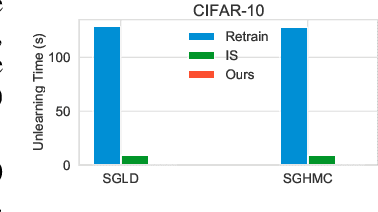
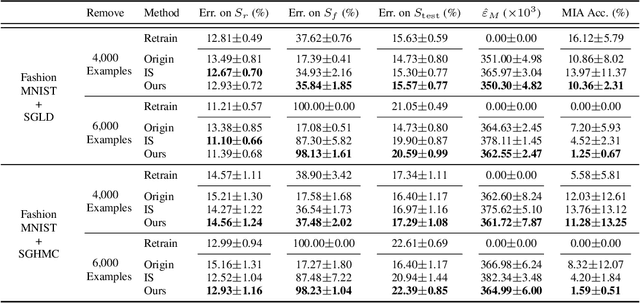

The right to be forgotten has been legislated in many countries, but its enforcement in the AI industry would cause unbearable costs. When single data deletion requests come, companies may need to delete the whole models learned with massive resources. Existing works propose methods to remove knowledge learned from data for explicitly parameterized models, which however are not appliable to the sampling-based Bayesian inference, i.e., Markov chain Monte Carlo (MCMC), as MCMC can only infer implicit distributions. In this paper, we propose the first machine unlearning algorithm for MCMC. We first convert the MCMC unlearning problem into an explicit optimization problem. Based on this problem conversion, an {\it MCMC influence function} is designed to provably characterize the learned knowledge from data, which then delivers the MCMC unlearning algorithm. Theoretical analysis shows that MCMC unlearning would not compromise the generalizability of the MCMC models. Experiments on Gaussian mixture models and Bayesian neural networks confirm the effectiveness of the proposed algorithm. The code is available at \url{https://github.com/fshp971/mcmc-unlearning}.