 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyrightShield: Spatial Similarity Guided Backdoor Defense against Copyright Infringement in Diffusion Models
Dec 02, 2024



The diffusion model has gained significant attention due to its remarkable data generation ability in fields such as image synthesis. However, its strong memorization and replication abilities with respect to the training data also make it a prime target for copyright infringement attacks. This paper provides an in-depth analysis of the spatial similarity of replication in diffusion model and leverages this key characteristic to design a method for detecting poisoning data. By employing a joint assessment of spatial-level and feature-level information from the detected segments, we effectively identify covertly dispersed poisoned samples. Building upon detected poisoning data, we propose a novel defense method specifically targeting copyright infringement attacks by introducing a protection constraint term into the loss function to mitigate the impact of poisoning. Extensive experimental results demonstrate that our approach achieves an average F1 score of 0.709 in detecting copyright infringement backdoors, resulting in an average increase of 68.1% in First-Attack Epoch (FAE) and an average decrease of 51.4% in Copyright Infringement Rate (CIR) of the poisoned model, effectively defending against copyright infringement. Additionally, we introduce the concept of copyright feature inversion, which aids in determining copyright responsibility and expands the application scenarios of defense strategies.
SPAgent: Adaptive Task Decomposition and Model Selection for General Video Generation and Editing
Nov 28, 2024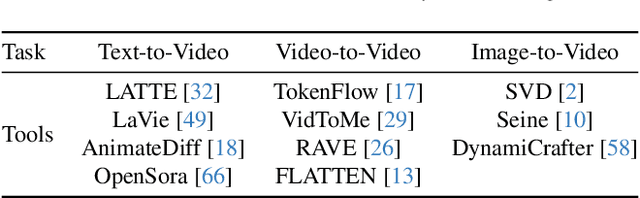
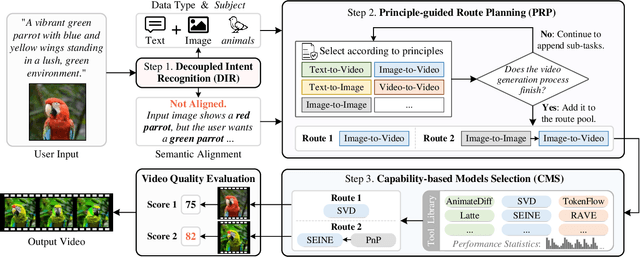

While open-source video generation and editing models have made significant progress, individual models are typically limited to specific tasks, failing to meet the diverse needs of users. Effectively coordinating these models can unlock a wide range of video generation and editing capabilities. However, manual coordination is complex and time-consuming, requiring users to deeply understand task requirements and possess comprehensive knowledge of each model's performance, applicability, and limitations, thereby increasing the barrier to entry. To address these challenges, we propose a novel video generation and editing system powered by our Semantic Planning Agent (SPAgent). SPAgent bridges the gap between diverse user intents and the effective utilization of existing generative models, enhancing the adaptability, efficiency, and overall quality of video generation and editing. Specifically, the SPAgent assembles a tool library integrating state-of-the-art open-source image and video generation and editing models as tools. After fine-tuning on our manually annotated dataset, SPAgent can automatically coordinate the tools for video generation and editing, through our novelly designed three-step framework: (1) decoupled intent recognition, (2) principle-guided route planning, and (3) capability-based execution model selection. Additionally, we enhance the SPAgent's video quality evaluation capability, enabling it to autonomously assess and incorporate new video generation and editing models into its tool library without human intervention. Experimental results demonstrate that the SPAgent effectively coordinates models to generate or edit videos, highlighting its versatility and adaptability across various video tasks.
A Unified Analysis for Finite Weight Averaging
Nov 20, 2024



Averaging iterations of Stochastic Gradient Descent (SGD) have achieved empirical success in training deep learning models, such as Stochastic Weight Averaging (SWA), Exponential Moving Average (EMA), and LAtest Weight Averaging (LAWA). Especially, with a finite weight averaging method, LAWA can attain faster convergence and better generalization. However, its theoretical explanation is still less explored since there are fundamental differences between finite and infinite settings. In this work, we first generalize SGD and LAWA as Finite Weight Averaging (FWA) and explain their advantages compared to SGD from the perspective of optimization and generalization. A key challenge is the inapplicability of traditional methods in the sense of expectation or optimal values for infinite-dimensional settings in analyzing FWA's convergence. Second, the cumulative gradients introduced by FWA introduce additional confusion to the generalization analysis, especially making it more difficult to discuss them under different assumptions. Extending the final iteration convergence analysis to the FWA, this paper, under a convexity assumption, establishes a convergence bound $\mathcal{O}(\log\left(\frac{T}{k}\right)/\sqrt{T})$, where $k\in[1, T/2]$ is a constant representing the last $k$ iterations. Compared to SGD with $\mathcal{O}(\log(T)/\sqrt{T})$, we prove theoretically that FWA has a faster convergence rate and explain the effect of the number of average points. In the generalization analysis, we find a recursive representation for bounding the cumulative gradient using mathematical induction. We provide bounds for constant and decay learning rates and the convex and non-convex cases to show the good generalization performance of FWA. Finally, experimental results on several benchmarks verify our theoretical results.
Continual Task Learning through Adaptive Policy Self-Composition
Nov 18, 2024



Training a generalizable agent to continually learn a sequence of tasks from offline trajectories is a natural requirement for long-lived agents, yet remains a significant challenge for current offline reinforcement learning (RL) algorithms. Specifically, an agent must be able to rapidly adapt to new tasks using newly collected trajectories (plasticity), while retaining knowledge from previously learned tasks (stability). However, systematic analyses of this setting are scarce, and it remains unclear whether conventional continual learning (CL) methods are effective in continual offline RL (CORL) scenarios. In this study, we develop the Offline Continual World benchmark and demonstrate that traditional CL methods struggle with catastrophic forgetting, primarily due to the unique distribution shifts inherent to CORL scenarios. To address this challenge, we introduce CompoFormer, a structure-based continual transformer model that adaptively composes previous policies via a meta-policy network. Upon encountering a new task, CompoFormer leverages semantic correlations to selectively integrate relevant prior policies alongside newly trained parameters, thereby enhancing knowledge sharing and accelerating the learning process. Our experiments reveal that CompoFormer outperforms conventional CL methods, particularly in longer task sequences, showcasing a promising balance between plasticity and stability.
Aligning Few-Step Diffusion Models with Dense Reward Difference Learning
Nov 18, 2024



Aligning diffusion models with downstream objectives is essential for their practical applications. However, standard alignment methods often struggle with step generalization when directly applied to few-step diffusion models, leading to inconsistent performance across different denoising step scenarios. To address this, we introduce Stepwise Diffusion Policy Optimization (SDPO), a novel alignment method tailored for few-step diffusion models. Unlike prior approaches that rely on a single sparse reward from only the final step of each denoising trajectory for trajectory-level optimization, SDPO incorporates dense reward feedback at every intermediate step. By learning the differences in dense rewards between paired samples, SDPO facilitates stepwise optimization of few-step diffusion models, ensuring consistent alignment across all denoising steps. To promote stable and efficient training, SDPO introduces an online reinforcement learning framework featuring several novel strategies designed to effectively exploit the stepwise granularity of dense rewards. Experimental results demonstrate that SDPO consistently outperforms prior methods in reward-based alignment across diverse step configurations, underscoring its robust step generalization capabilities. Code is avaliable at https://github.com/ZiyiZhang27/sdpo.
Neuron: Learning Context-Aware Evolving Representations for Zero-Shot Skeleton Action Recognition
Nov 18, 2024



Zero-shot skeleton action recognition is a non-trivial task that requires robust unseen generalization with prior knowledge from only seen classes and shared semantics. Existing methods typically build the skeleton-semantics interactions by uncontrollable mappings and conspicuous representations, thereby can hardly capture the intricate and fine-grained relationship for effective cross-modal transferability. To address these issues, we propose a novel dyNamically Evolving dUal skeleton-semantic syneRgistic framework with the guidance of cOntext-aware side informatioN (dubbed Neuron), to explore more fine-grained cross-modal correspondence from micro to macro perspectives at both spatial and temporal levels, respectively. Concretely, 1) we first construct the spatial-temporal evolving micro-prototypes and integrate dynamic context-aware side information to capture the intricate and synergistic skeleton-semantic correlations step-by-step, progressively refining cross-model alignment; and 2) we introduce the spatial compression and temporal memory mechanisms to guide the growth of spatial-temporal micro-prototypes, enabling them to absorb structure-related spatial representations and regularity-dependent temporal patterns. Notably, such processes are analogous to the learning and growth of neurons, equipping the framework with the capacity to generalize to novel unseen action categories. Extensive experiments on various benchmark datasets demonstrated the superiority of the proposed method.
Learn from Downstream and Be Yourself in Multimodal Large Language Model Fine-Tuning
Nov 17, 2024



Multimodal Large Language Model (MLLM) have demonstrated strong generalization capabilities across diverse distributions and tasks, largely due to extensive pre-training datasets. Fine-tuning MLLM has become a common practice to improve performance on specific downstream tasks. However, during fine-tuning, MLLM often faces the risk of forgetting knowledge acquired during pre-training, which can result in a decline in generalization abilities. To balance the trade-off between generalization and specialization, we propose measuring the parameter importance for both pre-trained and fine-tuning distributions, based on frozen pre-trained weight magnitude and accumulated fine-tuning gradient values. We further apply an importance-aware weight allocation strategy, selectively updating relatively important parameters for downstream tasks. We conduct empirical evaluations on both image captioning and visual question-answering tasks using various MLLM architectures. The comprehensive experimental analysis demonstrates the effectiveness of the proposed solution, highlighting the efficiency of the crucial modules in enhancing downstream specialization performance while mitigating generalization degradation in MLLM Fine-Tuning.
Stability and Generalization for Distributed SGDA
Nov 14, 2024



Minimax optimization is gaining increasing attention in modern machine learning applications. Driven by large-scale models and massive volumes of data collected from edge devices, as well as the concern to preserve client privacy, communication-efficient distributed minimax optimization algorithms become popular, such as Local Stochastic Gradient Descent Ascent (Local-SGDA), and Local Decentralized SGDA (Local-DSGDA). While most existing research on distributed minimax algorithms focuses on convergence rates, computation complexity, and communication efficiency, the generalization performance remains underdeveloped, whereas generalization ability is a pivotal indicator for evaluating the holistic performance of a model when fed with unknown data. In this paper, we propose the stability-based generalization analytical framework for Distributed-SGDA, which unifies two popular distributed minimax algorithms including Local-SGDA and Local-DSGDA, and conduct a comprehensive analysis of stability error, generalization gap, and population risk across different metrics under various settings, e.g., (S)C-(S)C, PL-SC, and NC-NC cases. Our theoretical results reveal the trade-off between the generalization gap and optimization error and suggest hyperparameters choice to obtain the optimal population risk. Numerical experiments for Local-SGDA and Local-DSGDA validate the theoretical results.
Prompt Tuning with Diffusion for Few-Shot Pre-trained Policy Generalization
Nov 02, 2024



Offline reinforcement learning (RL) methods harness previous experiences to derive an optimal policy, forming the foundation for pre-trained large-scale models (PLMs). When encountering tasks not seen before, PLMs often utilize several expert trajectories as prompts to expedite their adaptation to new requirements. Though a range of prompt-tuning methods have been proposed to enhance the quality of prompts, these methods often face optimization restrictions due to prompt initialization, which can significantly constrain the exploration domain and potentially lead to suboptimal solutions. To eliminate the reliance on the initial prompt, we shift our perspective towards the generative model, framing the prompt-tuning process as a form of conditional generative modeling, where prompts are generated from random noise. Our innovation, the Prompt Diffuser, leverages a conditional diffusion model to produce prompts of exceptional quality. Central to our framework is the approach to trajectory reconstruction and the meticulous integration of downstream task guidance during the training phase. Further experimental results underscore the potency of the Prompt Diffuser as a robust and effective tool for the prompt-tuning process, demonstrating strong performance in the meta-RL tasks.
Task-Aware Harmony Multi-Task Decision Transformer for Offline Reinforcement Learning
Nov 02, 2024



The purpose of offline multi-task reinforcement learning (MTRL) is to develop a unified policy applicable to diverse tasks without the need for online environmental interaction. Recent advancements approach this through sequence modeling, leveraging the Transformer architecture's scalability and the benefits of parameter sharing to exploit task similarities. However, variations in task content and complexity pose significant challenges in policy formulation, necessitating judicious parameter sharing and management of conflicting gradients for optimal policy performance. Furthermore, identifying the optimal parameter subspace for each task often necessitates prior knowledge of the task identifier during inference, limiting applicability in real-world scenarios with variable task content and unknown current tasks. In this work, we introduce the Harmony Multi-Task Decision Transformer (HarmoDT), a novel solution designed to identify an optimal harmony subspace of parameters for each task. We formulate this as a bi-level optimization problem within a meta-learning framework, where the upper level learns masks to define the harmony subspace, while the inner level focuses on updating parameters to improve the overall performance of the unified policy. To eliminate the need for task identifiers, we further design a group-wise variant (G-HarmoDT) that clusters tasks into coherent groups based on gradient information, and utilizes a gating network to determine task identifiers during inference. Empirical evaluations across various benchmarks highlight the superiority of our approach, demonstrating its effectiveness in the multi-task context with specific improvements of 8% gain in task-provided settings, 5% in task-agnostic settings, and 10% in unseen settings.