 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusAD: Time-Frequency Fusion with Adaptive Denoising for General Time Series Analysis
Dec 16, 2025



Time series analysis plays a vital role in fields such as finance, healthcare, industry, and meteorology, underpinning key tasks including classification, forecasting, and anomaly detection. Although deep learning models have achieved remarkable progress in these areas in recent years, constructing an efficient, multi-task compatible, and generalizable unified framework for time series analysis remains a significant challenge. Existing approaches are often tailored to single tasks or specific data types, making it difficult to simultaneously handle multi-task modeling and effectively integrate information across diverse time series types. Moreover, real-world data are often affected by noise, complex frequency components, and multi-scale dynamic patterns, which further complicate robust feature extraction and analysis. To ameliorate these challenges, we propose FusAD, a unified analysis framework designed for diverse time series tasks. FusAD features an adaptive time-frequency fusion mechanism, integrating both Fourier and Wavelet transforms to efficiently capture global-local and multi-scale dynamic features. With an adaptive denoising mechanism, FusAD automatically senses and filters various types of noise, highlighting crucial sequence variations and enabling robust feature extraction in complex environments. In addition, the framework integrates a general information fusion and decoding structure, combined with masked pre-training, to promote efficient learning and transfer of multi-granularity representations. Extensive experiments demonstrate that FusAD consistently outperforms state-of-the-art models on mainstream time series benchmarks for classification, forecasting, and anomaly detection tasks, while maintaining high efficiency and scalability. Code is available at https://github.com/zhangda1018/FusAD.
Exploring the Underwater World Segmentation without Extra Training
Nov 11, 2025Accurate segmentation of marine organisms is vital for biodiversity monitoring and ecological assessment, yet existing datasets and models remain largely limited to terrestrial scenes. To bridge this gap, we introduce \textbf{AquaOV255}, the first large-scale and fine-grained underwater segmentation dataset containing 255 categories and over 20K images, covering diverse categories for open-vocabulary (OV) evaluation. Furthermore, we establish the first underwater OV segmentation benchmark, \textbf{UOVSBench}, by integrating AquaOV255 with five additional underwater datasets to enable comprehensive evaluation. Alongside, we present \textbf{Earth2Ocean}, a training-free OV segmentation framework that transfers terrestrial vision--language models (VLMs) to underwater domains without any additional underwater training. Earth2Ocean consists of two core components: a Geometric-guided Visual Mask Generator (\textbf{GMG}) that refines visual features via self-similarity geometric priors for local structure perception, and a Category-visual Semantic Alignment (\textbf{CSA}) module that enhances text embeddings through multimodal large language model reasoning and scene-aware template construction. Extensive experiments on the UOVSBench benchmark demonstrate that Earth2Ocean achieves significant performance improvement on average while maintaining efficient inference.
Robust and Efficient Quantum Reservoir Computing with Discrete Time Crystal
Aug 21, 2025The rapid development of machine learning and quantum computing has placed quantum machine learning at the forefront of research. However, existing quantum machine learning algorithms based on quantum variational algorithms face challenges in trainability and noise robustness. In order to address these challenges, we introduce a gradient-free, noise-robust quantum reservoir computing algorithm that harnesses discrete time crystal dynamics as a reservoir. We first calibrate the memory, nonlinear, and information scrambling capacities of the quantum reservoir, revealing their correlation with dynamical phases and non-equilibrium phase transitions. We then apply the algorithm to the binary classification task and establish a comparative quantum kernel advantage. For ten-class classification, both noisy simulations and experimental results on superconducting quantum processors match ideal simulations, demonstrating the enhanced accuracy with increasing system size and confirming the topological noise robustness. Our work presents the first experimental demonstration of quantum reservoir computing for image classification based on digital quantum simulation. It establishes the correlation between quantum many-body non-equilibrium phase transitions and quantum machine learning performance, providing new design principles for quantum reservoir computing and broader quantum machine learning algorithms in the NISQ era.
FGAseg: Fine-Grained Pixel-Text Alignment for Open-Vocabulary Semantic Segmentation
Jan 03, 2025



Open-vocabulary segmentation aims to identify and segment specific regions and objects based on text-based descriptions. A common solution is to leverage powerful vision-language models (VLMs), such as CLIP, to bridge the gap between vision and text information. However, VLMs are typically pretrained for image-level vision-text alignment, focusing on global semantic features. In contrast, segmentation tasks require fine-grained pixel-level alignment and detailed category boundary information, which VLMs alone cannot provide. As a result, information extracted directly from VLMs can't meet the requirements of segmentation tasks. To address this limitation, we propose FGAseg, a model designed for fine-grained pixel-text alignment and category boundary supplementation. The core of FGAseg is a Pixel-Level Alignment module that employs a cross-modal attention mechanism and a text-pixel alignment loss to refine the coarse-grained alignment from CLIP, achieving finer-grained pixel-text semantic alignment. Additionally, to enrich category boundary information, we introduce the alignment matrices as optimizable pseudo-masks during forward propagation and propose Category Information Supplementation module. These pseudo-masks, derived from cosine and convolutional similarity, provide essential global and local boundary information between different categories. By combining these two strategies, FGAseg effectively enhances pixel-level alignment and category boundary information, addressing key challenges in open-vocabulary segmentation. Extensive experiments demonstrate that FGAseg outperforms existing methods on open-vocabulary semantic segmentation benchmarks.
Quantum-inspired Interpretable Deep Learning Architecture for Text Sentiment Analysis
Aug 15, 2024Text has become the predominant form of communication on social media, embedding a wealth of emotional nuances. Consequently, the extraction of emotional information from text is of paramount importance. Despite previous research making some progress, existing text sentiment analysis models still face challenges in integrating diverse semantic information and lack interpretability. To address these issues, we propose a quantum-inspired deep learning architecture that combines fundamental principles of quantum mechanics (QM principles) with deep learning models for text sentiment analysis. Specifically, we analyze the commonalities between text representation and QM principles to design a quantum-inspired text representation method and further develop a quantum-inspired text embedding layer. Additionally, we design a feature extraction layer based on long short-term memory (LSTM) networks and self-attention mechanisms (SAMs). Finally, we calculate the text density matrix using the quantum complex numbers principle and apply 2D-convolution neural networks (CNNs) for feature condensation and dimensionality reduction. Through a series of visualization, comparative, and ablation experiments, we demonstrate that our model not only shows significant advantages in accuracy and efficiency compared to previous related models but also achieves a certain level of interpretability by integrating QM principles. Our code is available at QISA.
StitchFusion: Weaving Any Visual Modalities to Enhance Multimodal Semantic Segmentation
Aug 02, 2024



Multimodal semantic segmentation shows significant potential for enhancing segmentation accuracy in complex scenes. However, current methods often incorporate specialized feature fusion modules tailored to specific modalities, thereby restricting input flexibility and increasing the number of training parameters. To address these challenges, we propose StitchFusion, a straightforward yet effective modal fusion framework that integrates large-scale pre-trained models directly as encoders and feature fusers. This approach facilitates comprehensive multi-modal and multi-scale feature fusion, accommodating any visual modal inputs. Specifically, Our framework achieves modal integration during encoding by sharing multi-modal visual information. To enhance information exchange across modalities, we introduce a multi-directional adapter module (MultiAdapter) to enable cross-modal information transfer during encoding. By leveraging MultiAdapter to propagate multi-scale information across pre-trained encoders during the encoding process, StitchFusion achieves multi-modal visual information integration during encoding. Extensive comparative experiments demonstrate that our model achieves state-of-the-art performance on four multi-modal segmentation datasets with minimal additional parameters. Furthermore, the experimental integration of MultiAdapter with existing Feature Fusion Modules (FFMs) highlights their complementary nature. Our code is available at StitchFusion_repo.
When Box Meets Graph Neural Network in Tag-aware Recommendation
Jun 17, 2024



Last year has witnessed the re-flourishment of tag-aware recommender systems supported by the LLM-enriched tags. Unfortunately, though large efforts have been made, current solutions may fail to describe the diversity and uncertainty inherent in user preferences with only tag-driven profiles. Recently, with the development of geometry-based techniques, e.g., box embedding, diversity of user preferences now could be fully modeled as the range within a box in high dimension space. However, defect still exists as these approaches are incapable of capturing high-order neighbor signals, i.e., semantic-rich multi-hop relations within the user-tag-item tripartite graph, which severely limits the effectiveness of user modeling. To deal with this challenge, in this paper, we propose a novel algorithm, called BoxGNN, to perform the message aggregation via combination of logical operations, thereby incorporating high-order signals. Specifically, we first embed users, items, and tags as hyper-boxes rather than simple points in the representation space, and define two logical operations to facilitate the subsequent process. Next, we perform the message aggregation mechanism via the combination of logical operations, to obtain the corresponding high-order box representations. Finally, we adopt a volume-based learning objective with Gumbel smoothing techniques to refine the representation of boxes. Extensive experiments on two publicly available datasets and one LLM-enhanced e-commerce dataset have validated the superiority of BoxGNN compared with various state-of-the-art baselines. The code is released online
U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation
May 24, 2024



Multimodal semantic segmentation is a pivotal component of computer vision and typically surpasses unimodal methods by utilizing rich information set from various sources.Current models frequently adopt modality-specific frameworks that inherently biases toward certain modalities. Although these biases might be advantageous in specific situations, they generally limit the adaptability of the models across different multimodal contexts, thereby potentially impairing performance. To address this issue, we leverage the inherent capabilities of the model itself to discover the optimal equilibrium in multimodal fusion and introduce U3M: An Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation. Specifically, this method involves an unbiased integration of multimodal visual data. Additionally, we employ feature fusion at multiple scales to ensure the effective extraction and integration of both global and local features. Experimental results demonstrate that our approach achieves superior performance across multiple datasets, verifing its efficacy in enhancing the robustness and versatility of semantic segmentation in diverse settings. Our code is available at U3M-multimodal-semantic-segmentation.
Dynamic Proxy Domain Generalizes the Crowd Localization by Better Binary Segmentation
Apr 22, 2024Crowd localization targets on predicting each instance precise location within an image. Current advanced methods propose the pixel-wise binary classification to tackle the congested prediction, in which the pixel-level thresholds binarize the prediction confidence of being the pedestrian head. Since the crowd scenes suffer from extremely varying contents, counts and scales, the confidence-threshold learner is fragile and under-generalized encountering domain knowledge shift. Moreover, at the most time, the target domain is agnostic in training. Hence, it is imperative to exploit how to enhance the generalization of confidence-threshold locator to the latent target domain. In this paper, we propose a Dynamic Proxy Domain (DPD) method to generalize the learner under domain shift. Concretely, based on the theoretical analysis to the generalization error risk upper bound on the latent target domain to a binary classifier, we propose to introduce a generated proxy domain to facilitate generalization. Then, based on the theory, we design a DPD algorithm which is composed by a training paradigm and proxy domain generator to enhance the domain generalization of the confidence-threshold learner. Besides, we conduct our method on five kinds of domain shift scenarios, demonstrating the effectiveness on generalizing the crowd localization. Our code will be available at https://github.com/zhangda1018/DPD.
INT: Towards Infinite-frames 3D Detection with An Efficient Framework
Sep 30, 2022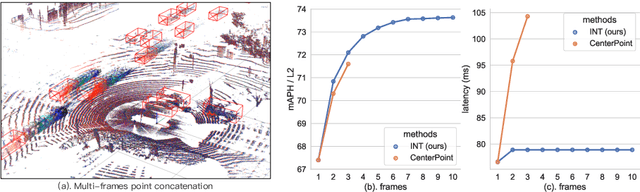
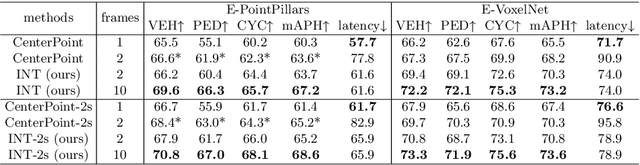
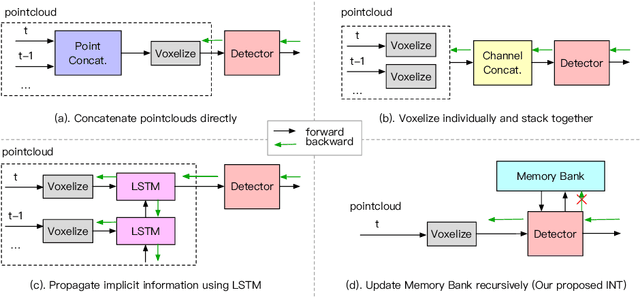
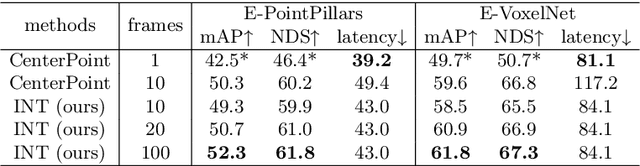
It is natural to construct a multi-frame instead of a single-frame 3D detector for a continuous-time stream. Although increasing the number of frames might improve performance, previous multi-frame studies only used very limited frames to build their systems due to the dramatically increased computational and memory cost. To address these issues, we propose a novel on-stream training and prediction framework that, in theory, can employ an infinite number of frames while keeping the same amount of computation as a single-frame detector. This infinite framework (INT), which can be used with most existing detectors, is utilized, for example, on the popular CenterPoint, with significant latency reductions and performance improvements. We've also conducted extensive experiments on two large-scale datasets, nuScenes and Waymo Open Dataset, to demonstrate the scheme's effectiveness and efficiency. By employing INT on CenterPoint, we can get around 7% (Waymo) and 15% (nuScenes) performance boost with only 2~4ms latency overhead, and currently SOTA on the Waymo 3D Detection leaderboard.