 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Shortcut Transition from Cross-Family OOD Failure in a Minimal Model
May 13, 2026Shortcut features are often invoked to explain out-of-distribution (OOD) failure, but training correlation, learned shortcut use, and test-time failure need not coincide. We study a minimal binary model with one invariant coordinate and one family-dependent shortcut coordinate. In the deterministic regime, positive average shortcut correlation pulls logistic ERM toward positive shortcut weight, but ridge regularization keeps the classifier invariant-dominated and prevents deterministic OOD failure. When the invariant coordinate is noisy, ridge-logistic ERM switches to the shortcut rule once the training shortcut signal exceeds the invariant signal. Whether that transition causes failure depends on the held-out family: weaker shortcut correlation yields positive excess risk, and sign-flipped families yield above-chance error. Synthetic checks match these analytic regimes and show that the same training-side transition can have different held-out consequences. The model separates shortcut attraction, shortcut-rule transition, and cross-family OOD failure.
Targeted Tests for LLM Reasoning: An Audit-Constrained Protocol
May 12, 2026Fixed reasoning benchmarks evaluate canonical prompts, but semantically valid changes in presentation can still change model behavior. Studies of prompt variation can reveal such failures, but without audit they can mix genuine model errors with invalid perturbations, extraction artifacts, and unmatched search procedures. We propose an audit-constrained protocol for targeted reasoning evaluation. Prompt variants are generated from a finite component grammar, rendered deterministically, evaluated under a fixed query budget, and counted as model errors only after semantic and extraction audit. Within this protocol we instantiate Component-Adaptive Prompt Sampling (CAPS), a score-based sampler over prompt components, and compare it with equal-budget uniform component sampling under the same task bank, renderer, model interface, decoding settings, and audit procedure. Across three audited slices, the protocol identifies confirmed model-error prompt keys while excluding formatting and extraction artifacts, but matched comparisons do not show that CAPS improves audited yield or unique prompt-key discovery over uniform sampling. The contribution is methodological: targeted prompt variation can be studied under a reconstructable, reviewable, budget-matched protocol, and proxy-guided policies should be judged by audited yield rather than raw mismatch counts or selected examples alone.
A Controlled Counterexample to Strong Proxy-Based Explanations of OOD Performance: in a Fixed Pretraining-and-Probing Setup
May 12, 2026Task-agnostic structure proxies are often used to interpret why one pretraining corpus transfers better than another, but such explanations require the proxy to track the structure that matters for the downstream task. We test this requirement in a fixed pretraining-and-probing setup motivated by computationally bounded notions of learned structure, including epiplexity. The core question is whether a proxy ranking of two pretraining datasets must agree with their ranking by OOD probe accuracy. We show that it need not. First, we give a controlled construction in which a formal structure quantity, its operational proxy, and the task-relevant structure for a target family separate. We then instantiate the same mechanism in a synthetic sequence-model experiment: under the primary all-sample evaluation, the OOD accuracy ranking reverses the proxy ranking in two of three seeds, with auxiliary diagnostics and ablations supporting the same interpretation. The counterexample does not reject structure-based explanations in general; it identifies a boundary on strong proxy-based explanations. A proxy for total learned structure can fail to track the task-relevant structure that drives OOD performance, even in a controlled setting.
INT: Towards Infinite-frames 3D Detection with An Efficient Framework
Sep 30, 2022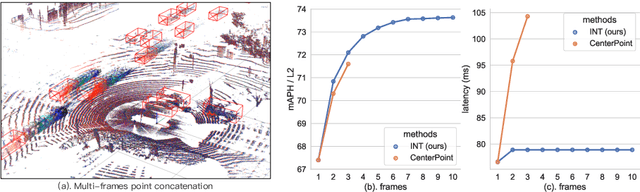
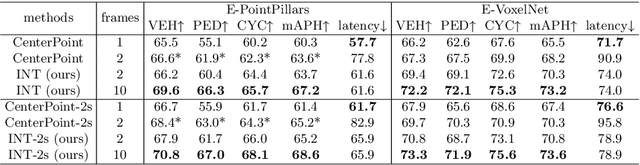
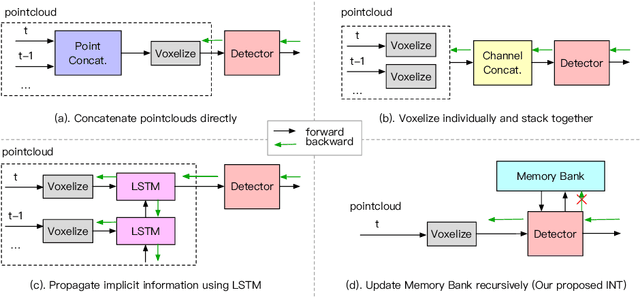
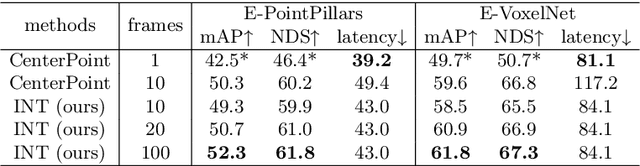
It is natural to construct a multi-frame instead of a single-frame 3D detector for a continuous-time stream. Although increasing the number of frames might improve performance, previous multi-frame studies only used very limited frames to build their systems due to the dramatically increased computational and memory cost. To address these issues, we propose a novel on-stream training and prediction framework that, in theory, can employ an infinite number of frames while keeping the same amount of computation as a single-frame detector. This infinite framework (INT), which can be used with most existing detectors, is utilized, for example, on the popular CenterPoint, with significant latency reductions and performance improvements. We've also conducted extensive experiments on two large-scale datasets, nuScenes and Waymo Open Dataset, to demonstrate the scheme's effectiveness and efficiency. By employing INT on CenterPoint, we can get around 7% (Waymo) and 15% (nuScenes) performance boost with only 2~4ms latency overhead, and currently SOTA on the Waymo 3D Detection leaderboard.
LSEC: Large-scale spectral ensemble clustering
Jun 18, 2021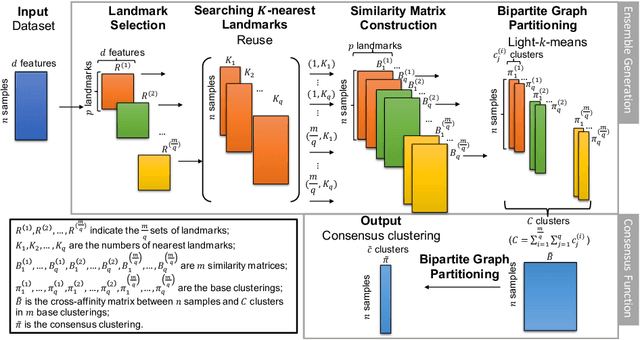


Ensemble clustering is a fundamental problem in the machine learning field, combining multiple base clusterings into a better clustering result. However, most of the existing methods are unsuitable for large-scale ensemble clustering tasks due to the efficiency bottleneck. In this paper, we propose a large-scale spectral ensemble clustering (LSEC) method to strike a good balance between efficiency and effectiveness. In LSEC, a large-scale spectral clustering based efficient ensemble generation framework is designed to generate various base clusterings within a low computational complexity. Then all based clustering are combined through a bipartite graph partition based consensus function into a better consensus clustering result. The LSEC method achieves a lower computational complexity than most existing ensemble clustering methods. Experiments conducted on ten large-scale datasets show the efficiency and effectiveness of the LSEC method. The MATLAB code of the proposed method and experimental datasets are available at https://github.com/Li- Hongmin/MyPaperWithCode.
Divide-and-conquer based Large-Scale Spectral Clustering
Apr 30, 2021

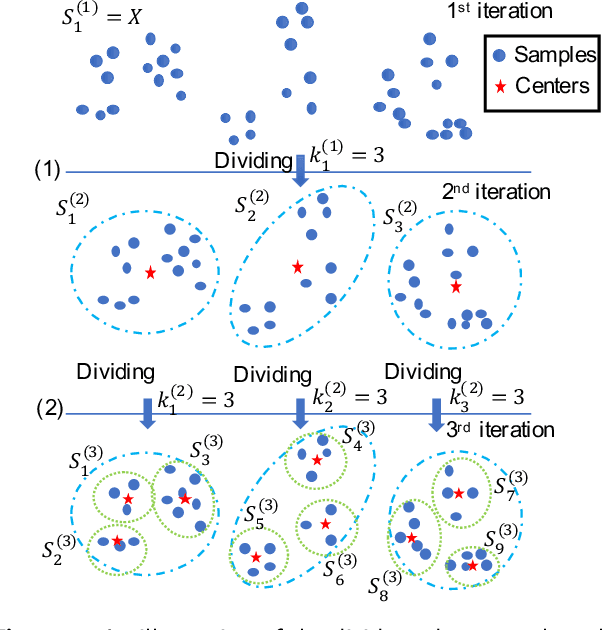
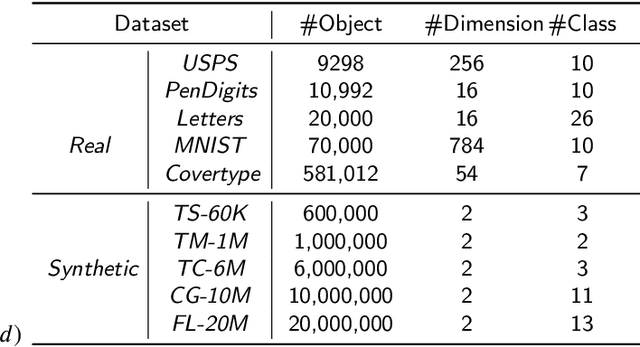
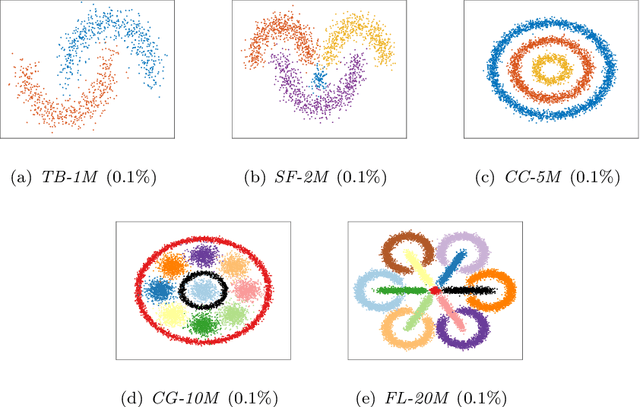
Spectral clustering is one of the most popular clustering methods. However, how to balance the efficiency and effectiveness of the large-scale spectral clustering with limited computing resources has not been properly solved for a long time. In this paper, we propose a divide-and-conquer based large-scale spectral clustering method to strike a good balance between efficiency and effectiveness. In the proposed method, a divide-and-conquer based landmark selection algorithm and a novel approximate similarity matrix approach are designed to construct a sparse similarity matrix within extremely low cost. Then clustering results can be computed quickly through a bipartite graph partition process. The proposed method achieves the lower computational complexity than most existing large-scale spectral clustering. Experimental results on ten large-scale datasets have demonstrated the efficiency and effectiveness of the proposed methods. The MATLAB code of the proposed method and experimental datasets are available at https://github.com/Li-Hongmin/MyPaperWithCode.
Robust event-stream pattern tracking based on correlative filter
Mar 17, 2018
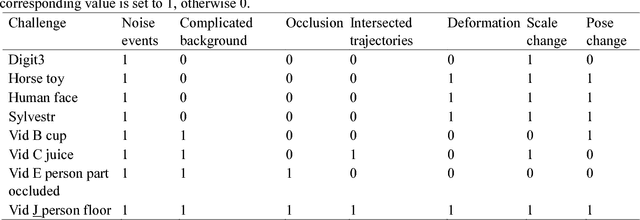

Object tracking based on retina-inspired and event-based dynamic vision sensor (DVS) is challenging for the noise events, rapid change of event-stream shape, chaos of complex background textures, and occlusion. To address these challenges, this paper presents a robust event-stream pattern tracking method based on correlative filter mechanism. In the proposed method, rate coding is used to encode the event-stream object in each segment. Feature representations from hierarchical convolutional layers of a deep convolutional neural network (CNN) are used to represent the appearance of the rate encoded event-stream object. The results prove that our method not only achieves good tracking performance in many complicated scenes with noise events, complex background textures, occlusion, and intersected trajectories, but also is robust to variable scale, variable pose, and non-rigid deformations. In addition, this correlative filter based event-stream tracking has the advantage of high speed. The proposed approach will promote the potential applications of these event-based vision sensors in self-driving, robots and many other high-speed scenes.
Super-resolution of spatiotemporal event-stream image captured by the asynchronous temporal contrast vision sensor
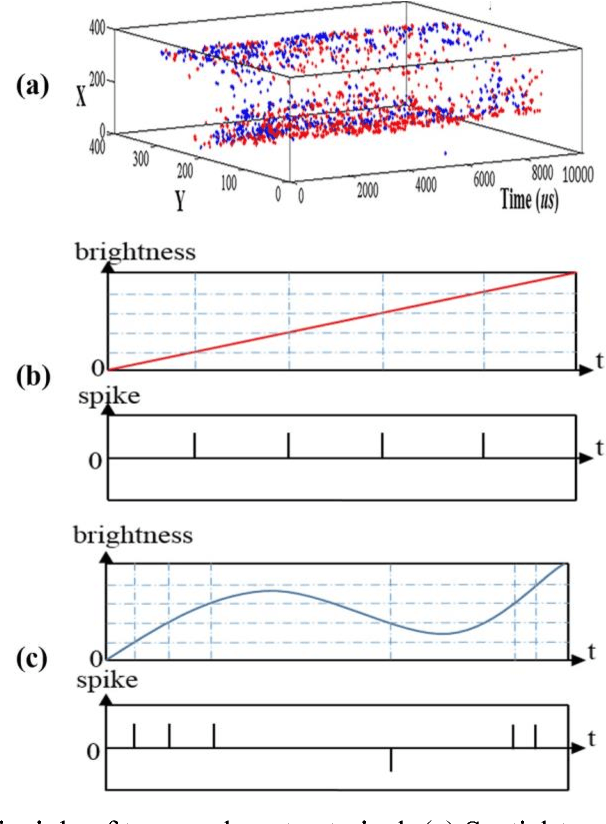
Mar 16, 2018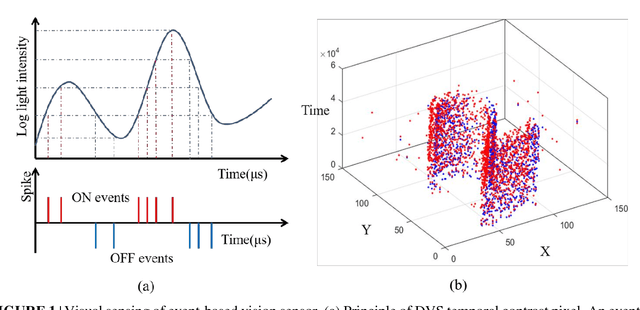
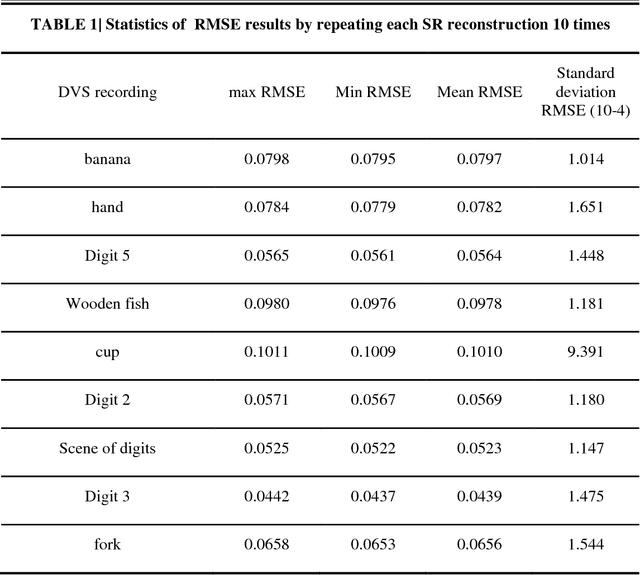
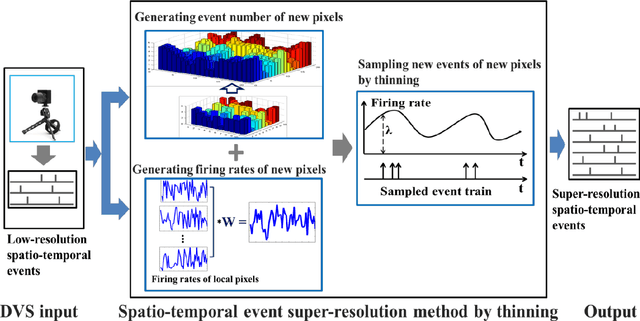
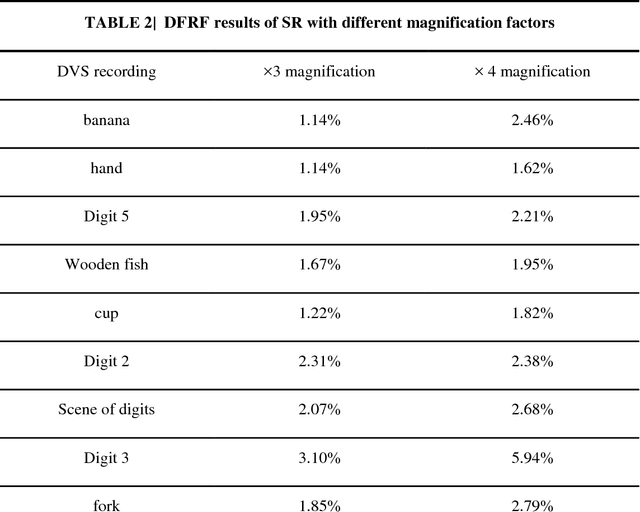
Super-resolution (SR) is a useful technology to generate a high-resolution (HR) visual output from the low-resolution (LR) visual inputs overcoming the physical limitations of the cameras. However, SR has not been applied to enhance the resolution of spatiotemporal event-stream images captured by the frame-free dynamic vision sensors (DVSs). SR of event-stream image is fundamentally different from existing frame-based schemes since basically each pixel value of DVS images is an event sequence. In this work, a two-stage scheme is proposed to solve the SR problem of the spatiotemporal event-stream image. We use a nonhomogeneous Poisson point process to model the event sequence, and sample the events of each pixel by simulating a nonhomogeneous Poisson process according to the specified event number and rate function. Firstly, the event number of each pixel of the HR DVS image is determined with a sparse signal representation based method to obtain the HR event-count map from that of the LR DVS recording. The rate function over time line of the point process of each HR pixel is computed using a spatiotemporal filter on the corresponding LR neighbor pixels. Secondly, the event sequence of each new pixel is generated with a thinning based event sampling algorithm. Two metrics are proposed to assess the event-stream SR results. The proposed method is demonstrated through obtaining HR event-stream images from a series of DVS recordings with the proposed method. Results show that the upscaled HR event streams has perceptually higher spatial texture detail than the LR DVS images. Besides, the temporal properties of the upscaled HR event streams match that of the original input very well. This work enables many potential applications of event-based vision.
Real-time Tracking Based on Neuromrophic Vision
Oct 18, 2015Real-time tracking is an important problem in computer vision in which most methods are based on the conventional cameras. Neuromorphic vision is a concept defined by incorporating neuromorphic vision sensors such as silicon retinas in vision processing system. With the development of the silicon technology, asynchronous event-based silicon retinas that mimic neuro-biological architectures has been developed in recent years. In this work, we combine the vision tracking algorithm of computer vision with the information encoding mechanism of event-based sensors which is inspired from the neural rate coding mechanism. The real-time tracking of single object with the advantage of high speed of 100 time bins per second is successfully realized. Our method demonstrates that the computer vision methods could be used for the neuromorphic vision processing and we can realize fast real-time tracking using neuromorphic vision sensors compare to the conventional camera.