 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveMLP: An MLP-like Architecture with Active Token Mixer
Mar 11, 2022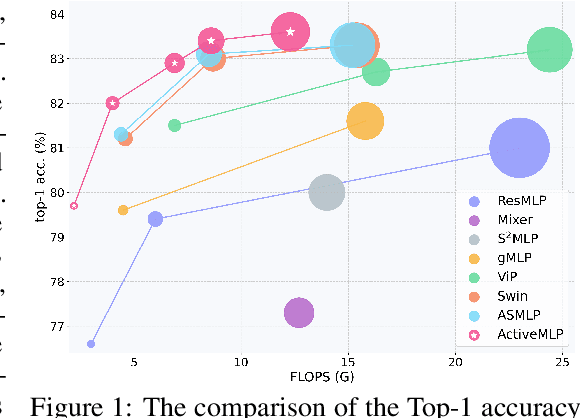

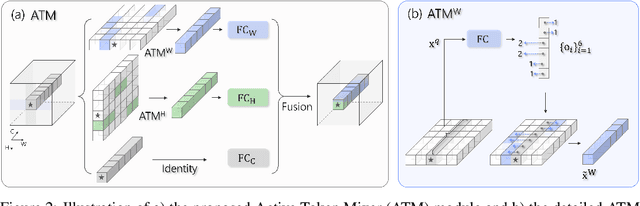
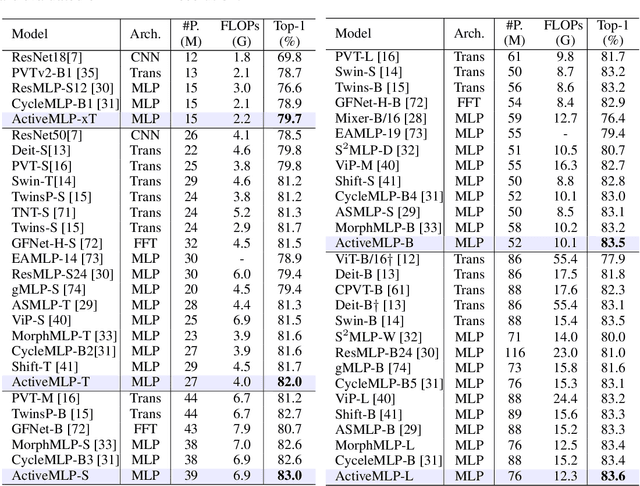
This paper presents ActiveMLP, a general MLP-like backbone for computer vision. The three existing dominant network families, i.e., CNNs, Transformers and MLPs, differ from each other mainly in the ways to fuse contextual information into a given token, leaving the design of more effective token-mixing mechanisms at the core of backbone architecture development. In ActiveMLP, we propose an innovative token-mixer, dubbed Active Token Mixer (ATM), to actively incorporate contextual information from other tokens in the global scope into the given one. This fundamental operator actively predicts where to capture useful contexts and learns how to fuse the captured contexts with the original information of the given token at channel levels. In this way, the spatial range of token-mixing is expanded and the way of token-mixing is reformed. With this design, ActiveMLP is endowed with the merits of global receptive fields and more flexible content-adaptive information fusion. Extensive experiments demonstrate that ActiveMLP is generally applicable and comprehensively surpasses different families of SOTA vision backbones by a clear margin on a broad range of vision tasks, including visual recognition and dense prediction tasks. The code and models will be available at https://github.com/microsoft/ActiveMLP.
Mask-based Latent Reconstruction for Reinforcement Learning
Jan 28, 2022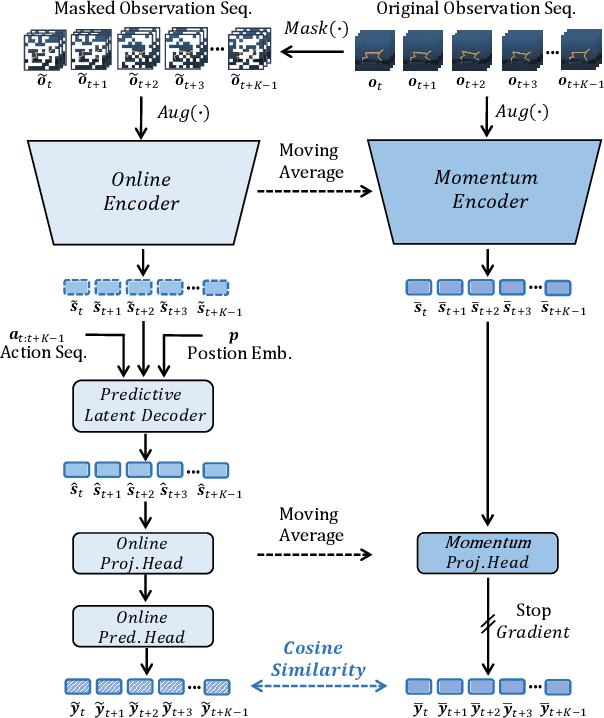
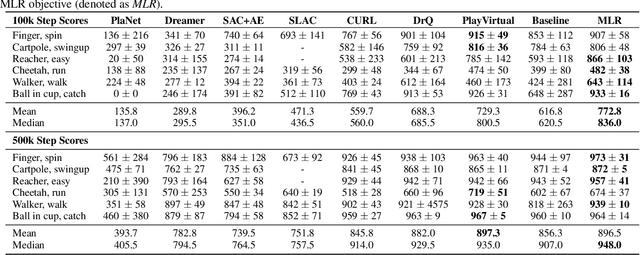
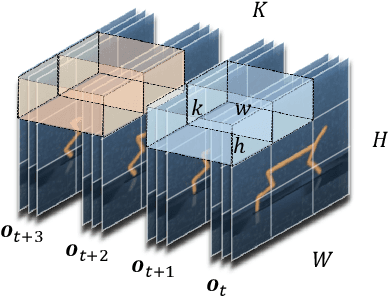
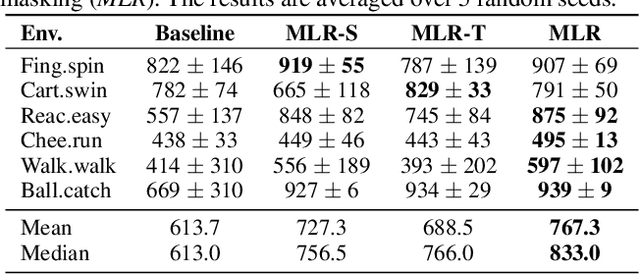
For deep reinforcement learning (RL) from pixels, learning effective state representations is crucial for achieving high performance. However, in practice, limited experience and high-dimensional input prevent effective representation learning. To address this, motivated by the success of masked modeling in other research fields, we introduce mask-based reconstruction to promote state representation learning in RL. Specifically, we propose a simple yet effective self-supervised method, Mask-based Latent Reconstruction (MLR), to predict the complete state representations in the latent space from the observations with spatially and temporally masked pixels. MLR enables the better use of context information when learning state representations to make them more informative, which facilitates RL agent training. Extensive experiments show that our MLR significantly improves the sample efficiency in RL and outperforms the state-of-the-art sample-efficient RL methods on multiple continuous benchmark environments.
Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
Dec 13, 2021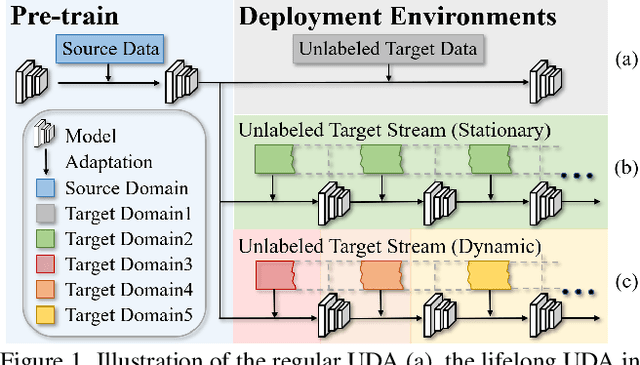

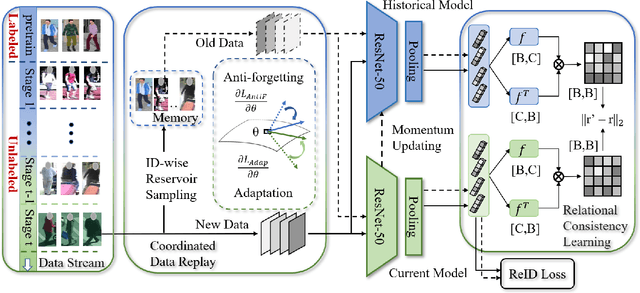
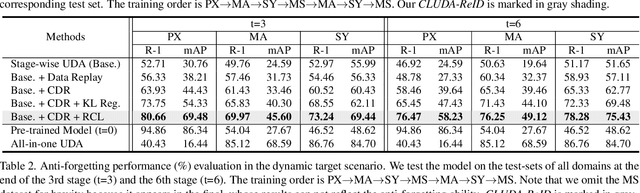
Unsupervised domain adaptive person re-identification (ReID) has been extensively investigated to mitigate the adverse effects of domain gaps. Those works assume the target domain data can be accessible all at once. However, for the real-world streaming data, this hinders the timely adaptation to changing data statistics and sufficient exploitation of increasing samples. In this paper, to address more practical scenarios, we propose a new task, Lifelong Unsupervised Domain Adaptive (LUDA) person ReID. This is challenging because it requires the model to continuously adapt to unlabeled data of the target environments while alleviating catastrophic forgetting for such a fine-grained person retrieval task. We design an effective scheme for this task, dubbed CLUDA-ReID, where the anti-forgetting is harmoniously coordinated with the adaptation. Specifically, a meta-based Coordinated Data Replay strategy is proposed to replay old data and update the network with a coordinated optimization direction for both adaptation and memorization. Moreover, we propose Relational Consistency Learning for old knowledge distillation/inheritance in line with the objective of retrieval-based tasks. We set up two evaluation settings to simulate the practical application scenarios. Extensive experiments demonstrate the effectiveness of our CLUDA-ReID for both scenarios with stationary target streams and scenarios with dynamic target streams.
Confounder Identification-free Causal Visual Feature Learning
Nov 26, 2021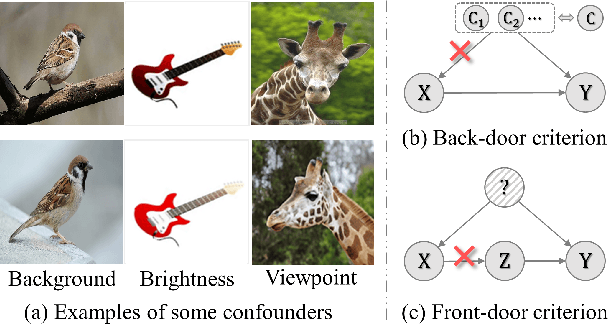
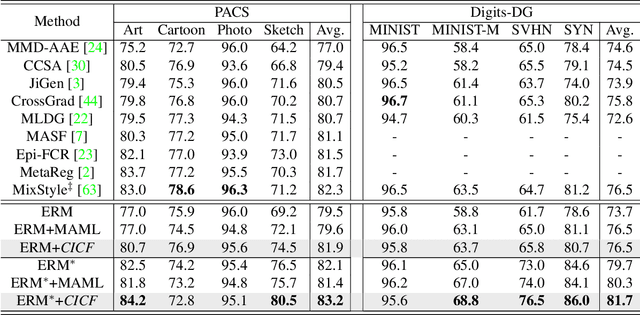
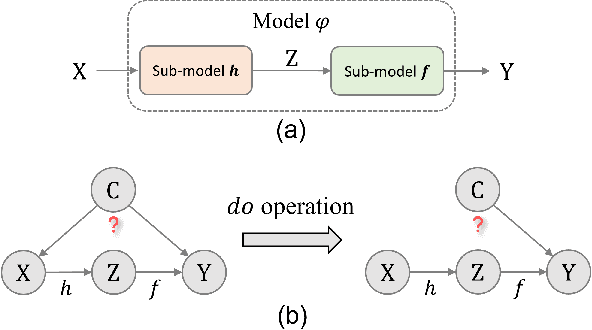
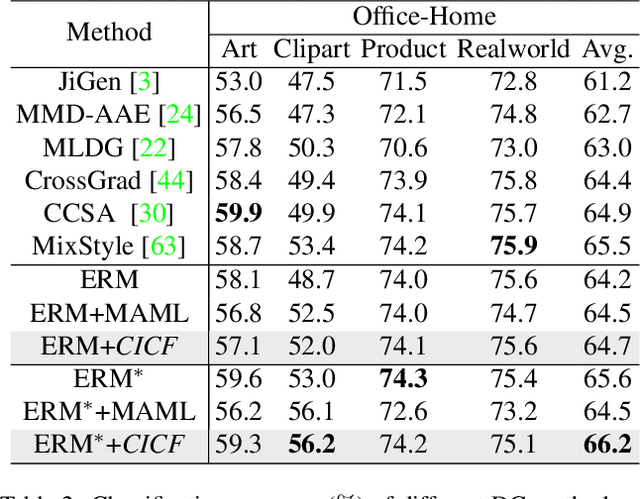
Confounders in deep learning are in general detrimental to model's generalization where they infiltrate feature representations. Therefore, learning causal features that are free of interference from confounders is important. Most previous causal learning based approaches employ back-door criterion to mitigate the adverse effect of certain specific confounder, which require the explicit identification of confounder. However, in real scenarios, confounders are typically diverse and difficult to be identified. In this paper, we propose a novel Confounder Identification-free Causal Visual Feature Learning (CICF) method, which obviates the need for identifying confounders. CICF models the interventions among different samples based on front-door criterion, and then approximates the global-scope intervening effect upon the instance-level interventions from the perspective of optimization. In this way, we aim to find a reliable optimization direction, which avoids the intervening effects of confounders, to learn causal features. Furthermore, we uncover the relation between CICF and the popular meta-learning strategy MAML, and provide an interpretation of why MAML works from the theoretical perspective of causal learning for the first time. Thanks to the effective learning of causal features, our CICF enables models to have superior generalization capability. Extensive experiments on domain generalization benchmark datasets demonstrate the effectiveness of our CICF, which achieves the state-of-the-art performance.
Multi-Scale Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
Nov 07, 2021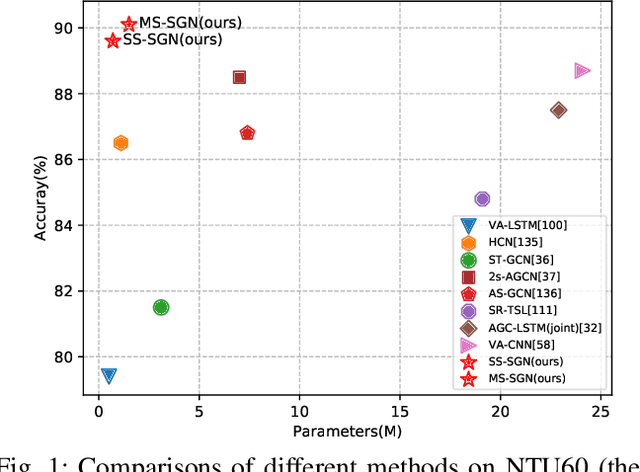

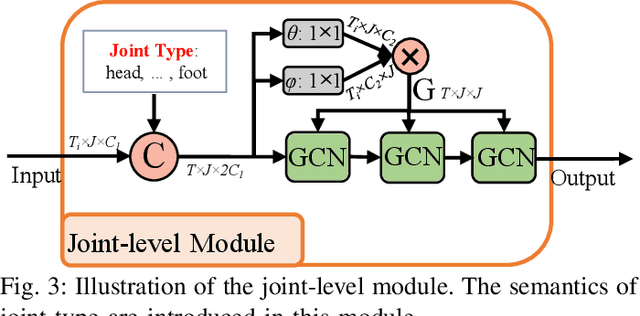
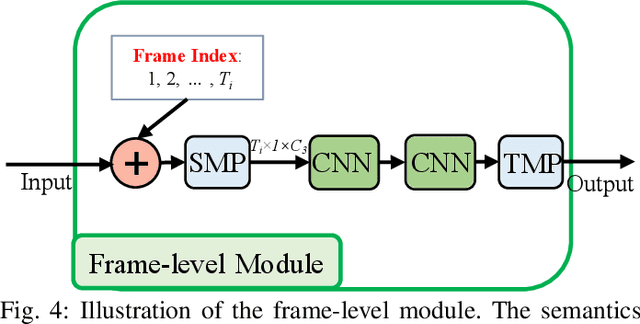
Skeleton data is of low dimension. However, there is a trend of using very deep and complicated feedforward neural networks to model the skeleton sequence without considering the complexity in recent year. In this paper, a simple yet effective multi-scale semantics-guided neural network (MS-SGN) is proposed for skeleton-based action recognition. We explicitly introduce the high level semantics of joints (joint type and frame index) into the network to enhance the feature representation capability of joints. Moreover, a multi-scale strategy is proposed to be robust to the temporal scale variations. In addition, we exploit the relationship of joints hierarchically through two modules, i.e., a joint-level module for modeling the correlations of joints in the same frame and a frame-level module for modeling the temporal dependencies of frames. With an order of magnitude smaller model size than most previous methods, MSSGN achieves the state-of-the-art performance on the NTU60, NTU120, and SYSU datasets.
Skeleton-Based Mutually Assisted Interacted Object Localization and Human Action Recognition
Oct 28, 2021
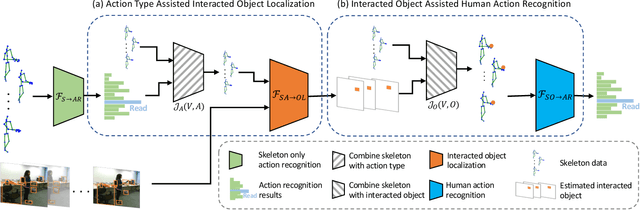

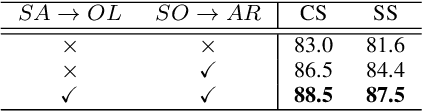
Skeleton data carries valuable motion information and is widely explored in human action recognition. However, not only the motion information but also the interaction with the environment provides discriminative cues to recognize the action of persons. In this paper, we propose a joint learning framework for mutually assisted "interacted object localization" and "human action recognition" based on skeleton data. The two tasks are serialized together and collaborate to promote each other, where preliminary action type derived from skeleton alone helps improve interacted object localization, which in turn provides valuable cues for the final human action recognition. Besides, we explore the temporal consistency of interacted object as constraint to better localize the interacted object with the absence of ground-truth labels. Extensive experiments on the datasets of SYSU-3D, NTU60 RGB+D and Northwestern-UCLA show that our method achieves the best or competitive performance with the state-of-the-art methods for human action recognition. Visualization results show that our method can also provide reasonable interacted object localization results.
WEDGE: Web-Image Assisted Domain Generalization for Semantic Segmentation
Sep 29, 2021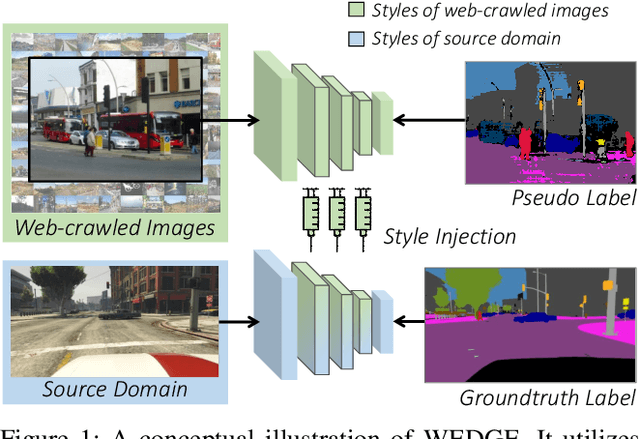
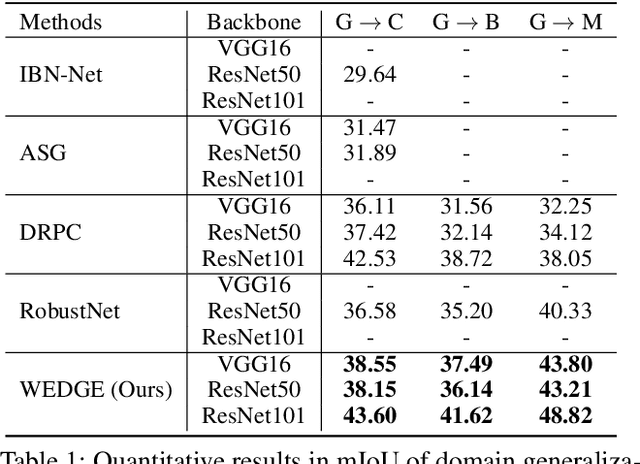
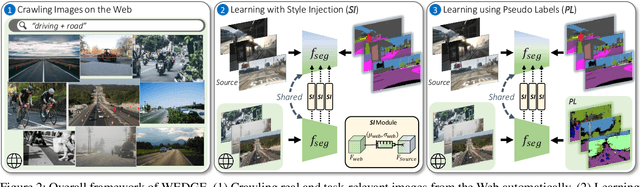
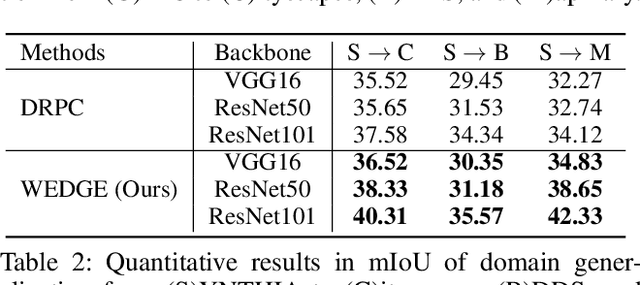
Domain generalization for semantic segmentation is highly demanded in real applications, where a trained model is expected to work well in previously unseen domains. One challenge lies in the lack of data which could cover the diverse distributions of the possible unseen domains for training. In this paper, we propose a WEb-image assisted Domain GEneralization (WEDGE) scheme, which is the first to exploit the diversity of web-crawled images for generalizable semantic segmentation. To explore and exploit the real-world data distributions, we collect a web-crawled dataset which presents large diversity in terms of weather conditions, sites, lighting, camera styles, etc. We also present a method which injects the style representation of the web-crawled data into the source domain on-the-fly during training, which enables the network to experience images of diverse styles with reliable labels for effective training. Moreover, we use the web-crawled dataset with predicted pseudo labels for training to further enhance the capability of the network. Extensive experiments demonstrate that our method clearly outperforms existing domain generalization techniques.
Pose-Guided Feature Learning with Knowledge Distillation for Occluded Person Re-Identification
Aug 23, 2021
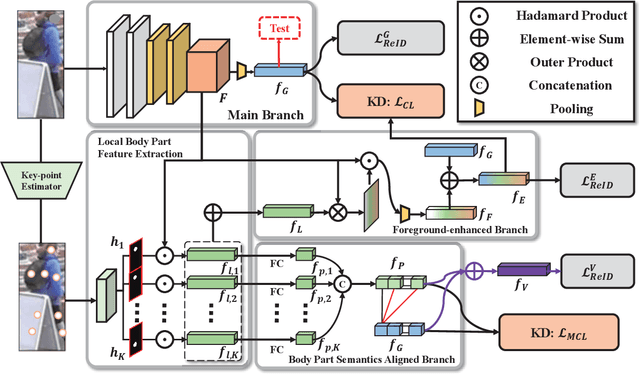
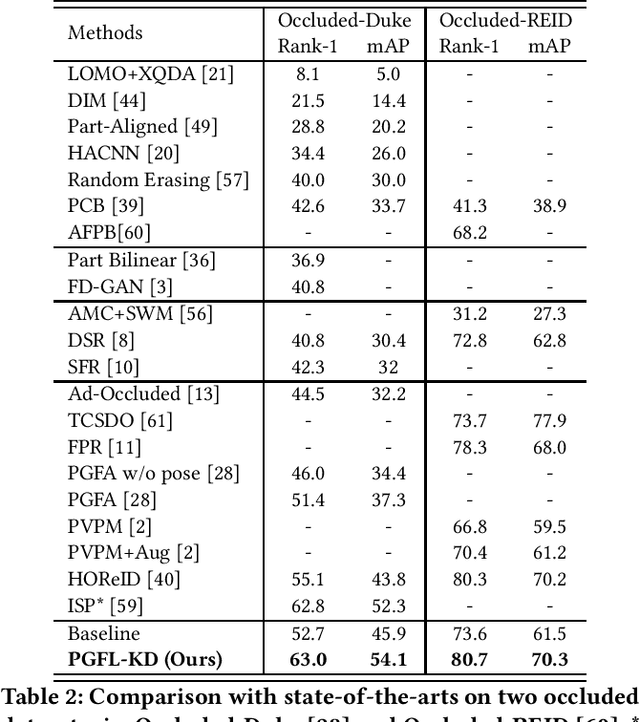
Occluded person re-identification (ReID) aims to match person images with occlusion. It is fundamentally challenging because of the serious occlusion which aggravates the misalignment problem between images. At the cost of incorporating a pose estimator, many works introduce pose information to alleviate the misalignment in both training and testing. To achieve high accuracy while preserving low inference complexity, we propose a network named Pose-Guided Feature Learning with Knowledge Distillation (PGFL-KD), where the pose information is exploited to regularize the learning of semantics aligned features but is discarded in testing. PGFL-KD consists of a main branch (MB), and two pose-guided branches, \ieno, a foreground-enhanced branch (FEB), and a body part semantics aligned branch (SAB). The FEB intends to emphasise the features of visible body parts while excluding the interference of obstructions and background (\ieno, foreground feature alignment). The SAB encourages different channel groups to focus on different body parts to have body part semantics aligned representation. To get rid of the dependency on pose information when testing, we regularize the MB to learn the merits of the FEB and SAB through knowledge distillation and interaction-based training. Extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed network.
ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation
Jun 21, 2021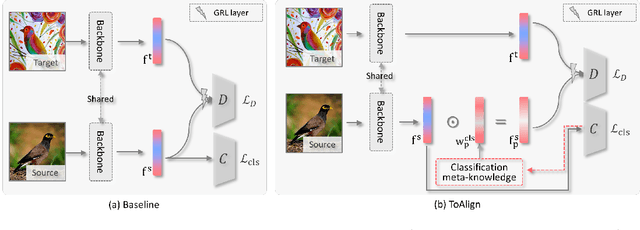
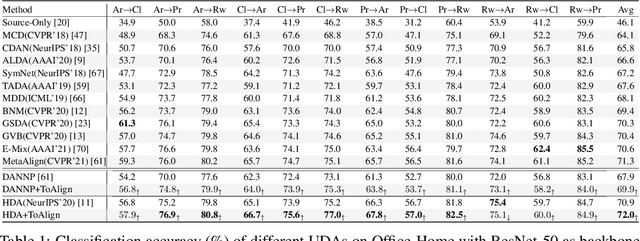
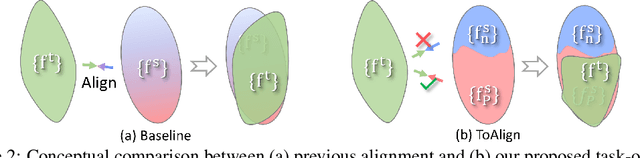
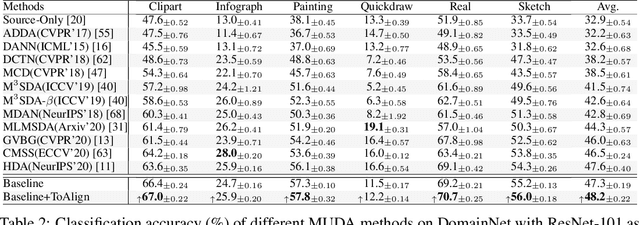
Unsupervised domain adaptive classification intends to improve theclassification performance on unlabeled target domain. To alleviate the adverse effect of domain shift, many approaches align the source and target domains in the feature space. However, a feature is usually taken as a whole for alignment without explicitly making domain alignment proactively serve the classification task, leading to sub-optimal solution. What sub-feature should be aligned for better adaptation is under-explored. In this paper, we propose an effective Task-oriented Alignment (ToAlign) for unsupervised domain adaptation (UDA). We study what features should be aligned across domains and propose to make the domain alignment proactively serve classification by performing feature decomposition and alignment under the guidance of the prior knowledge induced from the classification taskitself. Particularly, we explicitly decompose a feature in the source domain intoa task-related/discriminative feature that should be aligned, and a task-irrelevant feature that should be avoided/ignored, based on the classification meta-knowledge. Extensive experimental results on various benchmarks (e.g., Office-Home, Visda-2017, and DomainNet) under different domain adaptation settings demonstrate theeffectiveness of ToAlign which helps achieve the state-of-the-art performance.
PlayVirtual: Augmenting Cycle-Consistent Virtual Trajectories for Reinforcement Learning
Jun 08, 2021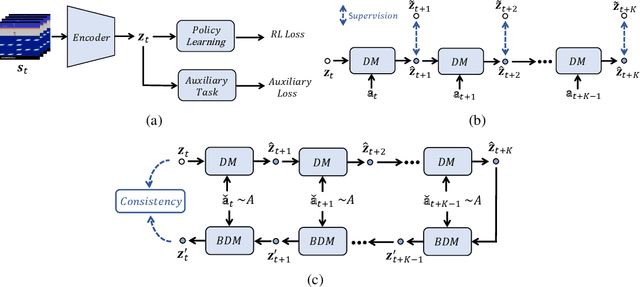
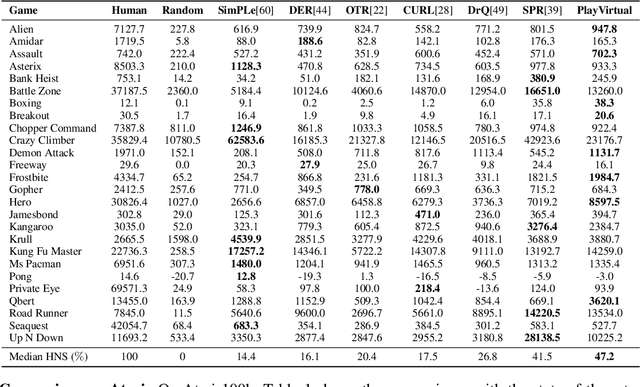
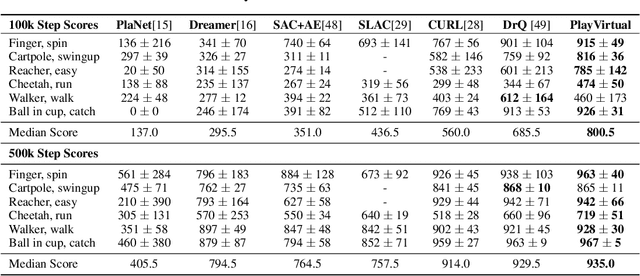
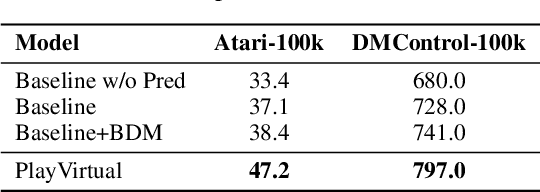
Learning good feature representations is important for deep reinforcement learning (RL). However, with limited experience, RL often suffers from data inefficiency for training. For un-experienced or less-experienced trajectories (i.e., state-action sequences), the lack of data limits the use of them for better feature learning. In this work, we propose a novel method, dubbed PlayVirtual, which augments cycle-consistent virtual trajectories to enhance the data efficiency for RL feature representation learning. Specifically, PlayVirtual predicts future states based on the current state and action by a dynamics model and then predicts the previous states by a backward dynamics model, which forms a trajectory cycle. Based on this, we augment the actions to generate a large amount of virtual state-action trajectories. Being free of groudtruth state supervision, we enforce a trajectory to meet the cycle consistency constraint, which can significantly enhance the data efficiency. We validate the effectiveness of our designs on the Atari and DeepMind Control Suite benchmarks. Our method outperforms the current state-of-the-art methods by a large margin on both benchmarks.