 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Right for Me is Not Yet Right for You: A Dataset for Grounding Relative Directions via Multi-Task Learning
May 05, 2022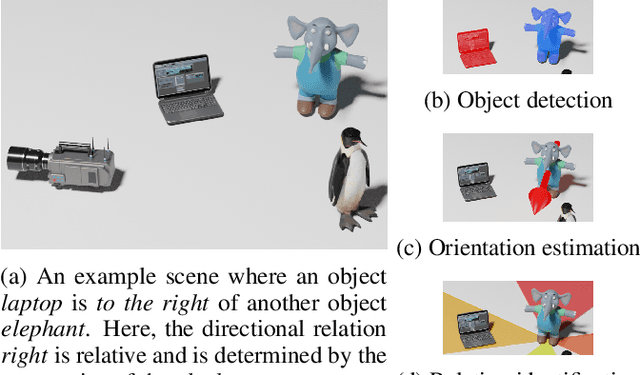


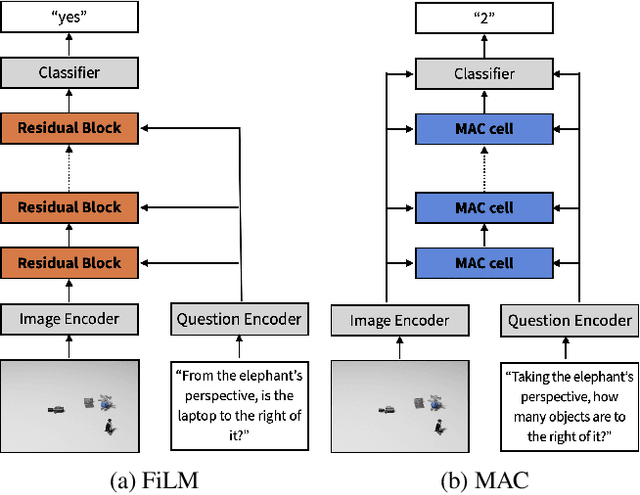
Understanding spatial relations is essential for intelligent agents to act and communicate in the physical world. Relative directions are spatial relations that describe the relative positions of target objects with regard to the intrinsic orientation of reference objects. Grounding relative directions is more difficult than grounding absolute directions because it not only requires a model to detect objects in the image and to identify spatial relation based on this information, but it also needs to recognize the orientation of objects and integrate this information into the reasoning process. We investigate the challenging problem of grounding relative directions with end-to-end neural networks. To this end, we provide GRiD-3D, a novel dataset that features relative directions and complements existing visual question answering (VQA) datasets, such as CLEVR, that involve only absolute directions. We also provide baselines for the dataset with two established end-to-end VQA models. Experimental evaluations show that answering questions on relative directions is feasible when questions in the dataset simulate the necessary subtasks for grounding relative directions. We discover that those subtasks are learned in an order that reflects the steps of an intuitive pipeline for processing relative directions.
A Multimodal German Dataset for Automatic Lip Reading Systems and Transfer Learning
Feb 27, 2022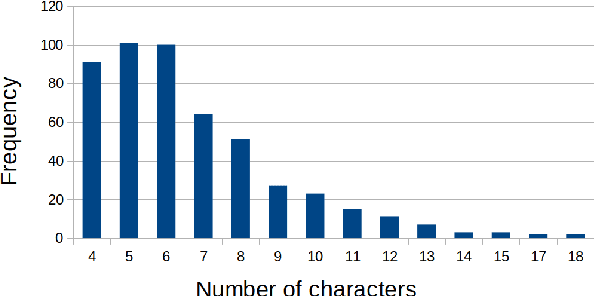
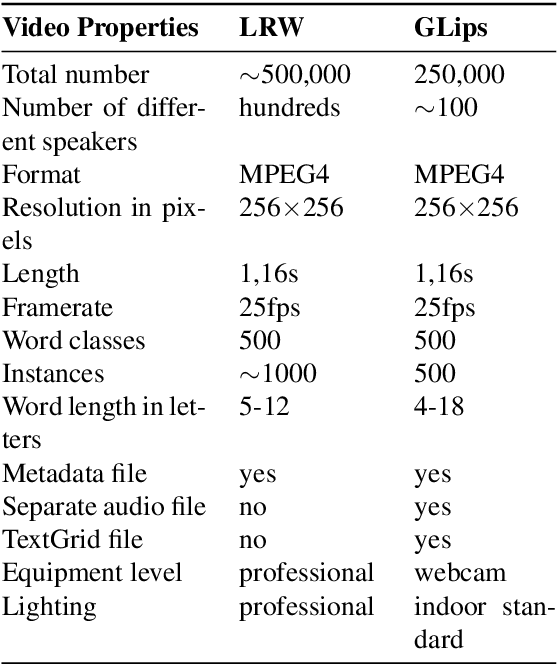
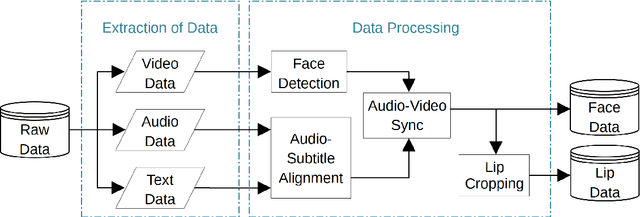

Large datasets as required for deep learning of lip reading do not exist in many languages. In this paper we present the dataset GLips (German Lips) consisting of 250,000 publicly available videos of the faces of speakers of the Hessian Parliament, which was processed for word-level lip reading using an automatic pipeline. The format is similar to that of the English language LRW (Lip Reading in the Wild) dataset, with each video encoding one word of interest in a context of 1.16 seconds duration, which yields compatibility for studying transfer learning between both datasets. By training a deep neural network, we investigate whether lip reading has language-independent features, so that datasets of different languages can be used to improve lip reading models. We demonstrate learning from scratch and show that transfer learning from LRW to GLips and vice versa improves learning speed and performance, in particular for the validation set.
Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
Jan 17, 2022
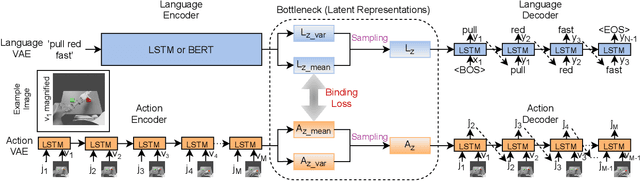
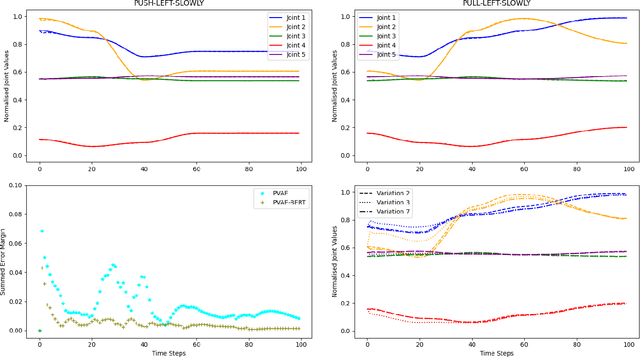
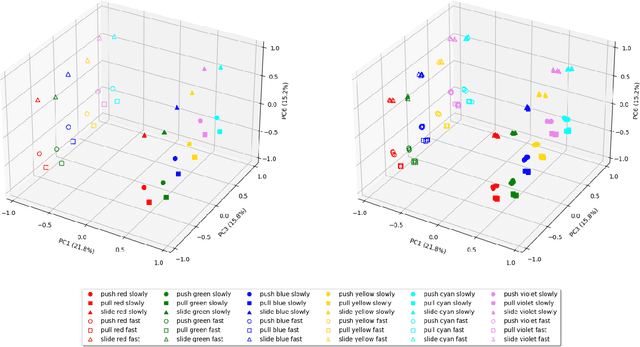
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.
LipSound2: Self-Supervised Pre-Training for Lip-to-Speech Reconstruction and Lip Reading
Dec 09, 2021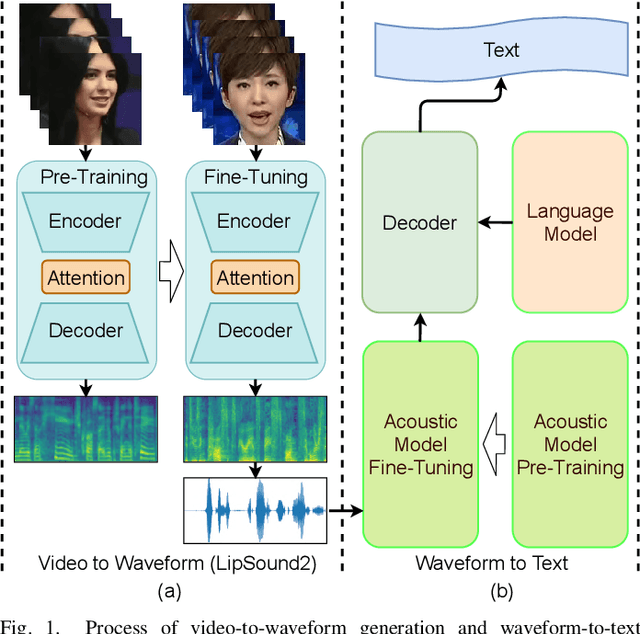
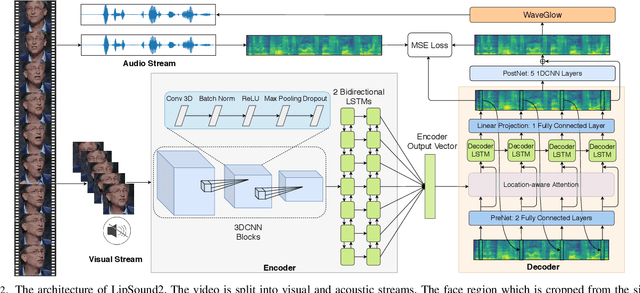
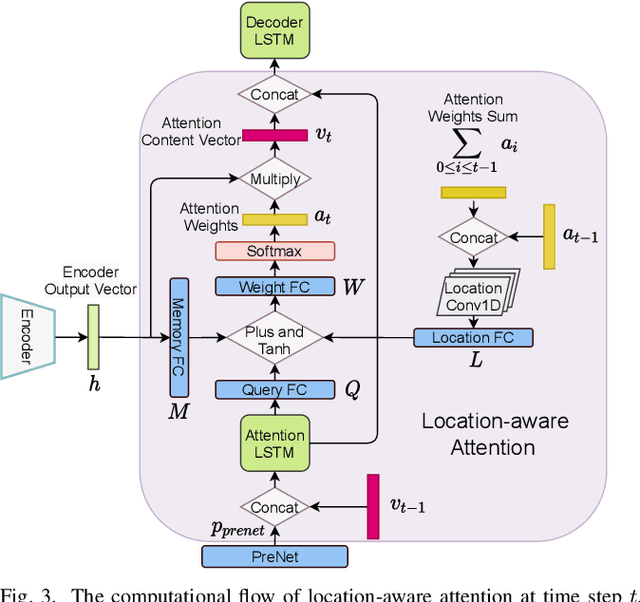

The aim of this work is to investigate the impact of crossmodal self-supervised pre-training for speech reconstruction (video-to-audio) by leveraging the natural co-occurrence of audio and visual streams in videos. We propose LipSound2 which consists of an encoder-decoder architecture and location-aware attention mechanism to map face image sequences to mel-scale spectrograms directly without requiring any human annotations. The proposed LipSound2 model is firstly pre-trained on $\sim$2400h multi-lingual (e.g. English and German) audio-visual data (VoxCeleb2). To verify the generalizability of the proposed method, we then fine-tune the pre-trained model on domain-specific datasets (GRID, TCD-TIMIT) for English speech reconstruction and achieve a significant improvement on speech quality and intelligibility compared to previous approaches in speaker-dependent and -independent settings. In addition to English, we conduct Chinese speech reconstruction on the CMLR dataset to verify the impact on transferability. Lastly, we train the cascaded lip reading (video-to-text) system by fine-tuning the generated audios on a pre-trained speech recognition system and achieve state-of-the-art performance on both English and Chinese benchmark datasets.
Lifelong Learning from Event-based Data
Nov 11, 2021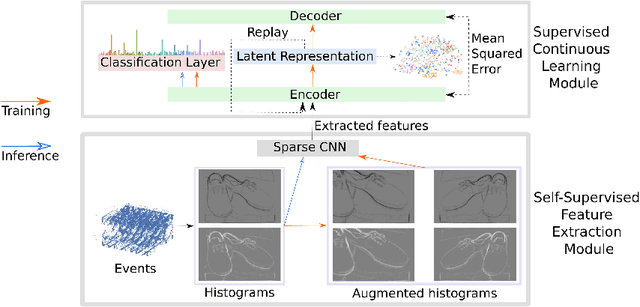

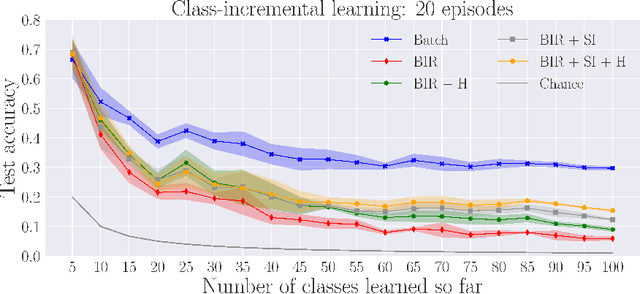
Lifelong learning is a long-standing aim for artificial agents that act in dynamic environments, in which an agent needs to accumulate knowledge incrementally without forgetting previously learned representations. We investigate methods for learning from data produced by event cameras and compare techniques to mitigate forgetting while learning incrementally. We propose a model that is composed of both, feature extraction and continuous learning. Furthermore, we introduce a habituation-based method to mitigate forgetting. Our experimental results show that the combination of different techniques can help to avoid catastrophic forgetting while learning incrementally from the features provided by the extraction module.
FaVoA: Face-Voice Association Favours Ambiguous Speaker Detection
Sep 01, 2021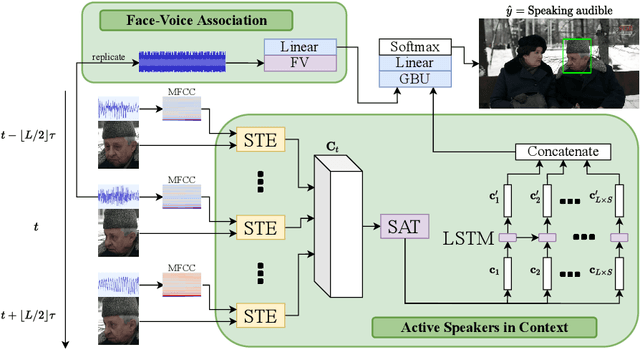

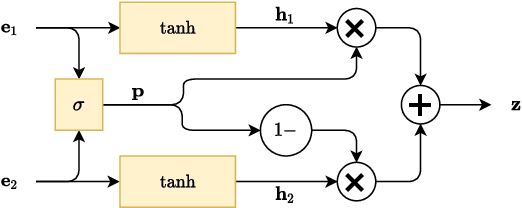
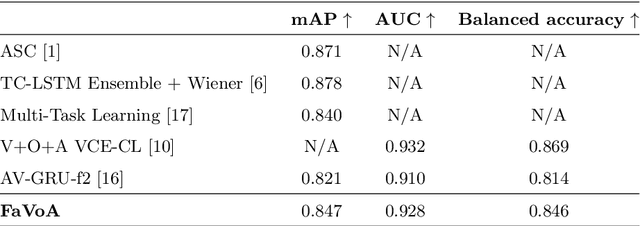
The strong relation between face and voice can aid active speaker detection systems when faces are visible, even in difficult settings, when the face of a speaker is not clear or when there are several people in the same scene. By being capable of estimating the frontal facial representation of a person from his/her speech, it becomes easier to determine whether he/she is a potential candidate for being classified as an active speaker, even in challenging cases in which no mouth movement is detected from any person in that same scene. By incorporating a face-voice association neural network into an existing state-of-the-art active speaker detection model, we introduce FaVoA (Face-Voice Association Ambiguous Speaker Detector), a neural network model that can correctly classify particularly ambiguous scenarios. FaVoA not only finds positive associations, but helps to rule out non-matching face-voice associations, where a face does not match a voice. Its use of a gated-bimodal-unit architecture for the fusion of those models offers a way to quantitatively determine how much each modality contributes to the classification.
Generalization in Multimodal Language Learning from Simulation
Aug 03, 2021


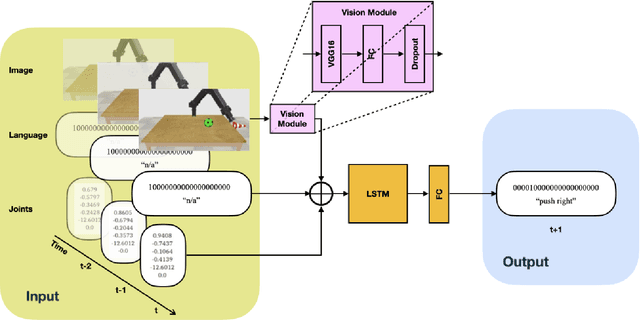
Neural networks can be powerful function approximators, which are able to model high-dimensional feature distributions from a subset of examples drawn from the target distribution. Naturally, they perform well at generalizing within the limits of their target function, but they often fail to generalize outside of the explicitly learned feature space. It is therefore an open research topic whether and how neural network-based architectures can be deployed for systematic reasoning. Many studies have shown evidence for poor generalization, but they often work with abstract data or are limited to single-channel input. Humans, however, learn and interact through a combination of multiple sensory modalities, and rarely rely on just one. To investigate compositional generalization in a multimodal setting, we generate an extensible dataset with multimodal input sequences from simulation. We investigate the influence of the underlying training data distribution on compostional generalization in a minimal LSTM-based network trained in a supervised, time continuous setting. We find compositional generalization to fail in simple setups while improving with the number of objects, actions, and particularly with a lot of color overlaps between objects. Furthermore, multimodality strongly improves compositional generalization in settings where a pure vision model struggles to generalize.
Robotic Occlusion Reasoning for Efficient Object Existence Prediction
Jul 28, 2021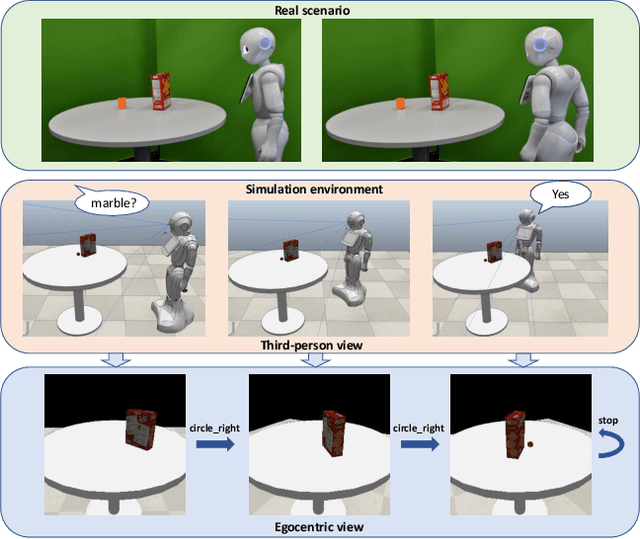
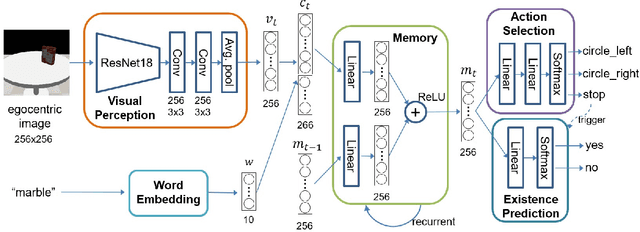
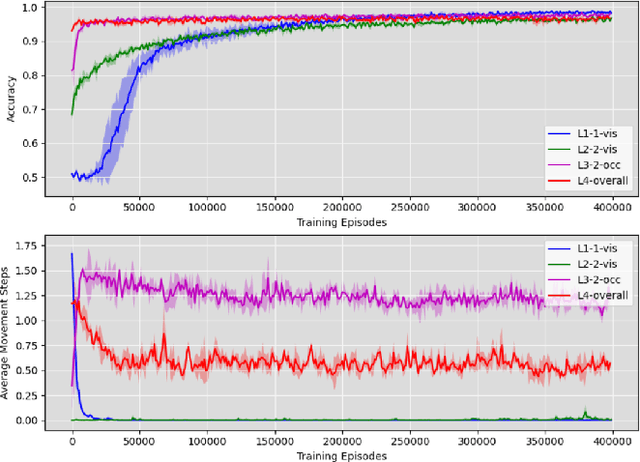
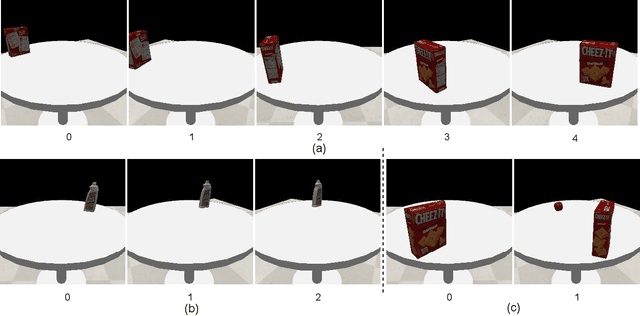
Reasoning about potential occlusions is essential for robots to efficiently predict whether an object exists in an environment. Though existing work shows that a robot with active perception can achieve various tasks, it is still unclear if occlusion reasoning can be achieved. To answer this question, we introduce the task of robotic object existence prediction: when being asked about an object, a robot needs to move as few steps as possible around a table with randomly placed objects to predict whether the queried object exists. To address this problem, we propose a novel recurrent neural network model that can be jointly trained with supervised and reinforcement learning methods using a curriculum training strategy. Experimental results show that 1) both active perception and occlusion reasoning are necessary to successfully achieve the task; 2) the proposed model demonstrates a good occlusion reasoning ability by achieving a similar prediction accuracy to an exhaustive exploration baseline while requiring only about $10\%$ of the baseline's number of movement steps on average; and 3) the model generalizes to novel object combinations with a moderate loss of accuracy.
Survey on reinforcement learning for language processing
Apr 12, 2021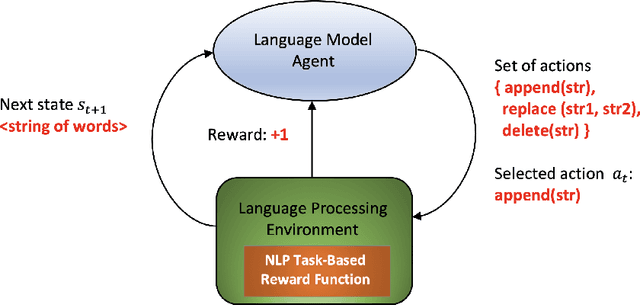
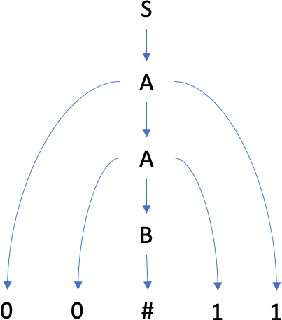

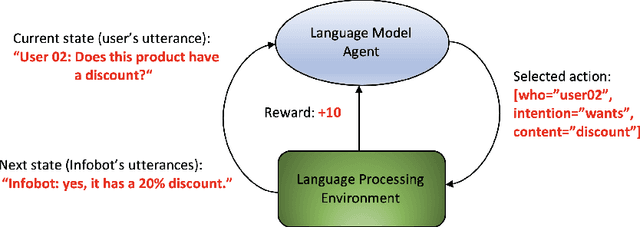
In recent years some researchers have explored the use of reinforcement learning (RL) algorithms as key components in the solution of various natural language processing tasks. For instance, some of these algorithms leveraging deep neural learning have found their way into conversational systems. This paper reviews the state of the art of RL methods for their possible use for different problems of natural language processing, focusing primarily on conversational systems, mainly due to their growing relevance. We provide detailed descriptions of the problems as well as discussions of why RL is well-suited to solve them. Also, we analyze the advantages and limitations of these methods. Finally, we elaborate on promising research directions in natural language processing that might benefit from reinforcement learning.
Visual Distant Supervision for Scene Graph Generation
Mar 29, 2021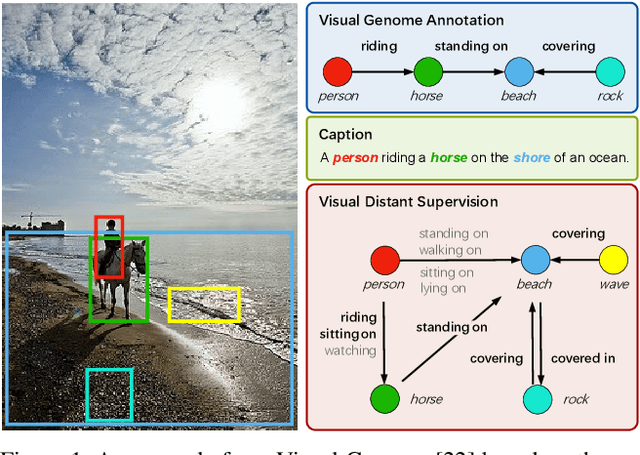
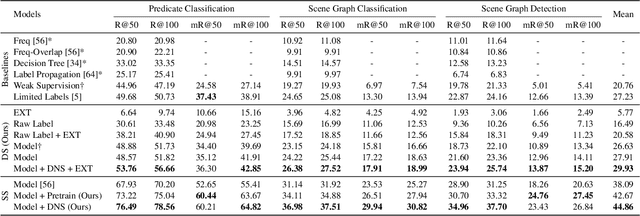
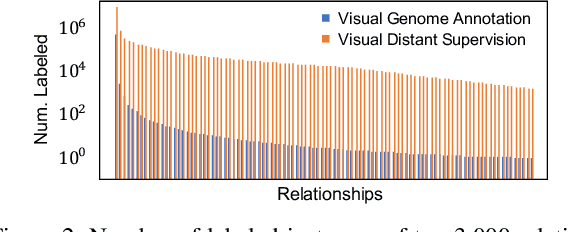
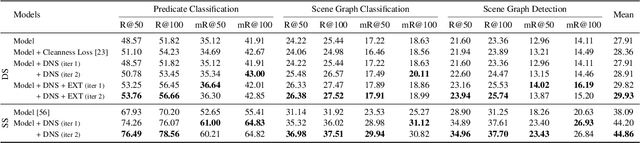
Scene graph generation aims to identify objects and their relations in images, providing structured image representations that can facilitate numerous applications in computer vision. However, scene graph models usually require supervised learning on large quantities of labeled data with intensive human annotation. In this work, we propose visual distant supervision, a novel paradigm of visual relation learning, which can train scene graph models without any human-labeled data. The intuition is that by aligning commonsense knowledge bases and images, we can automatically create large-scale labeled data to provide distant supervision for visual relation learning. To alleviate the noise in distantly labeled data, we further propose a framework that iteratively estimates the probabilistic relation labels and eliminates the noisy ones. Comprehensive experimental results show that our distantly supervised model outperforms strong weakly supervised and semi-supervised baselines. By further incorporating human-labeled data in a semi-supervised fashion, our model outperforms state-of-the-art fully supervised models by a large margin (e.g., 8.6 micro- and 7.6 macro-recall@50 improvements for predicate classification in Visual Genome evaluation). All the data and code will be available to facilitate future research.