 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmphasizing Unseen Words: New Vocabulary Acquisition for End-to-End Speech Recognition
Feb 21, 2023Due to the dynamic nature of human language, automatic speech recognition (ASR) systems need to continuously acquire new vocabulary. Out-Of-Vocabulary (OOV) words, such as trending words and new named entities, pose problems to modern ASR systems that require long training times to adapt their large numbers of parameters. Different from most previous research focusing on language model post-processing, we tackle this problem on an earlier processing level and eliminate the bias in acoustic modeling to recognize OOV words acoustically. We propose to generate OOV words using text-to-speech systems and to rescale losses to encourage neural networks to pay more attention to OOV words. Specifically, we enlarge the classification loss used for training neural networks' parameters of utterances containing OOV words (sentence-level), or rescale the gradient used for back-propagation for OOV words (word-level), when fine-tuning a previously trained model on synthetic audio. To overcome catastrophic forgetting, we also explore the combination of loss rescaling and model regularization, i.e. L2 regularization and elastic weight consolidation (EWC). Compared with previous methods that just fine-tune synthetic audio with EWC, the experimental results on the LibriSpeech benchmark reveal that our proposed loss rescaling approach can achieve significant improvement on the recall rate with only a slight decrease on word error rate. Moreover, word-level rescaling is more stable than utterance-level rescaling and leads to higher recall rates and precision on OOV word recognition. Furthermore, our proposed combined loss rescaling and weight consolidation methods can support continual learning of an ASR system.
Internally Rewarded Reinforcement Learning
Feb 01, 2023



We study a class of reinforcement learning problems where the reward signals for policy learning are generated by a discriminator that is dependent on and jointly optimized with the policy. This interdependence between the policy and the discriminator leads to an unstable learning process because reward signals from an immature discriminator are noisy and impede policy learning, and conversely, an untrained policy impedes discriminator learning. We call this learning setting $\textit{Internally Rewarded Reinforcement Learning}$ (IRRL) as the reward is not provided directly by the environment but $\textit{internally}$ by the discriminator. In this paper, we formally formulate IRRL and present a class of problems that belong to IRRL. We theoretically derive and empirically analyze the effect of the reward function in IRRL and based on these analyses propose the clipped linear reward function. Experimental results show that the proposed reward function can consistently stabilize the training process by reducing the impact of reward noise, which leads to faster convergence and higher performance compared with baselines in diverse tasks.
Learning Bidirectional Action-Language Translation with Limited Supervision and Incongruent Extra Input
Jan 09, 2023Human infant learning happens during exploration of the environment, by interaction with objects, and by listening to and repeating utterances casually, which is analogous to unsupervised learning. Only occasionally, a learning infant would receive a matching verbal description of an action it is committing, which is similar to supervised learning. Such a learning mechanism can be mimicked with deep learning. We model this weakly supervised learning paradigm using our Paired Gated Autoencoders (PGAE) model, which combines an action and a language autoencoder. After observing a performance drop when reducing the proportion of supervised training, we introduce the Paired Transformed Autoencoders (PTAE) model, using Transformer-based crossmodal attention. PTAE achieves significantly higher accuracy in language-to-action and action-to-language translations, particularly in realistic but difficult cases when only few supervised training samples are available. We also test whether the trained model behaves realistically with conflicting multimodal input. In accordance with the concept of incongruence in psychology, conflict deteriorates the model output. Conflicting action input has a more severe impact than conflicting language input, and more conflicting features lead to larger interference. PTAE can be trained on mostly unlabelled data where labeled data is scarce, and it behaves plausibly when tested with incongruent input.
Disentangling Prosody Representations with Unsupervised Speech Reconstruction
Dec 14, 2022



Human speech can be characterized by different components, including semantic content, speaker identity and prosodic information. Significant progress has been made in disentangling representations for semantic content and speaker identity in Automatic Speech Recognition (ASR) and speaker verification tasks respectively. However, it is still an open challenging research question to extract prosodic information because of the intrinsic association of different attributes, such as timbre and rhythm, and because of the need for unsupervised training schemes to achieve robust large-scale and speaker-independent ASR. The aim of this paper is to address the disentanglement of emotional prosody from speech based on unsupervised reconstruction. Specifically, we identify, design, implement and integrate three crucial components in our proposed speech reconstruction model Prosody2Vec: (1) a unit encoder that transforms speech signals into discrete units for semantic content, (2) a pretrained speaker verification model to generate speaker identity embeddings, and (3) a trainable prosody encoder to learn prosody representations. We first pretrain the Prosody2Vec representations on unlabelled emotional speech corpora, then fine-tune the model on specific datasets to perform Speech Emotion Recognition (SER) and Emotional Voice Conversion (EVC) tasks. Both objective and subjective evaluations on the EVC task suggest that Prosody2Vec effectively captures general prosodic features that can be smoothly transferred to other emotional speech. In addition, our SER experiments on the IEMOCAP dataset reveal that the prosody features learned by Prosody2Vec are complementary and beneficial for the performance of widely used speech pretraining models and surpass the state-of-the-art methods when combining Prosody2Vec with HuBERT representations. Some audio samples can be found on our demo website.
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Dec 08, 2022The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.
Visually Grounded Commonsense Knowledge Acquisition
Nov 22, 2022



Large-scale commonsense knowledge bases empower a broad range of AI applications, where the automatic extraction of commonsense knowledge (CKE) is a fundamental and challenging problem. CKE from text is known for suffering from the inherent sparsity and reporting bias of commonsense in text. Visual perception, on the other hand, contains rich commonsense knowledge about real-world entities, e.g., (person, can_hold, bottle), which can serve as promising sources for acquiring grounded commonsense knowledge. In this work, we present CLEVER, which formulates CKE as a distantly supervised multi-instance learning problem, where models learn to summarize commonsense relations from a bag of images about an entity pair without any human annotation on image instances. To address the problem, CLEVER leverages vision-language pre-training models for deep understanding of each image in the bag, and selects informative instances from the bag to summarize commonsense entity relations via a novel contrastive attention mechanism. Comprehensive experimental results in held-out and human evaluation show that CLEVER can extract commonsense knowledge in promising quality, outperforming pre-trained language model-based methods by 3.9 AUC and 6.4 mAUC points. The predicted commonsense scores show strong correlation with human judgment with a 0.78 Spearman coefficient. Moreover, the extracted commonsense can also be grounded into images with reasonable interpretability. The data and codes can be obtained at https://github.com/thunlp/CLEVER.
Data Augmentation with Unsupervised Speaking Style Transfer for Speech Emotion Recognition
Nov 16, 2022



Currently, the performance of Speech Emotion Recognition (SER) systems is mainly constrained by the absence of large-scale labelled corpora. Data augmentation is regarded as a promising approach, which borrows methods from Automatic Speech Recognition (ASR), for instance, perturbation on speed and pitch, or generating emotional speech utilizing generative adversarial networks. In this paper, we propose EmoAug, a novel style transfer model to augment emotion expressions, in which a semantic encoder and a paralinguistic encoder represent verbal and non-verbal information respectively. Additionally, a decoder reconstructs speech signals by conditioning on the aforementioned two information flows in an unsupervised fashion. Once training is completed, EmoAug enriches expressions of emotional speech in different prosodic attributes, such as stress, rhythm and intensity, by feeding different styles into the paralinguistic encoder. In addition, we can also generate similar numbers of samples for each class to tackle the data imbalance issue. Experimental results on the IEMOCAP dataset demonstrate that EmoAug can successfully transfer different speaking styles while retaining the speaker identity and semantic content. Furthermore, we train a SER model with data augmented by EmoAug and show that it not only surpasses the state-of-the-art supervised and self-supervised methods but also overcomes overfitting problems caused by data imbalance. Some audio samples can be found on our demo website.
Impact Makes a Sound and Sound Makes an Impact: Sound Guides Representations and Explorations
Aug 04, 2022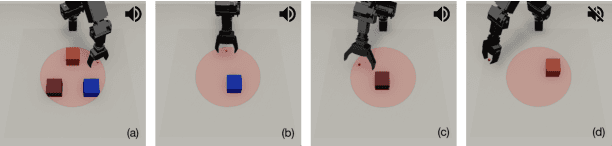
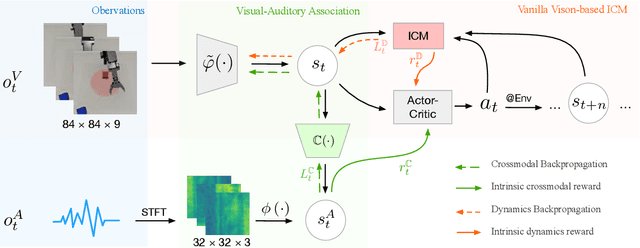
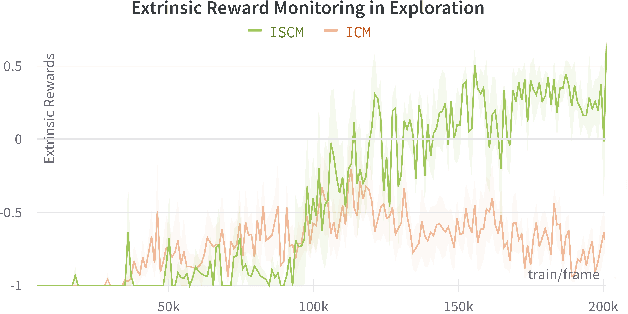
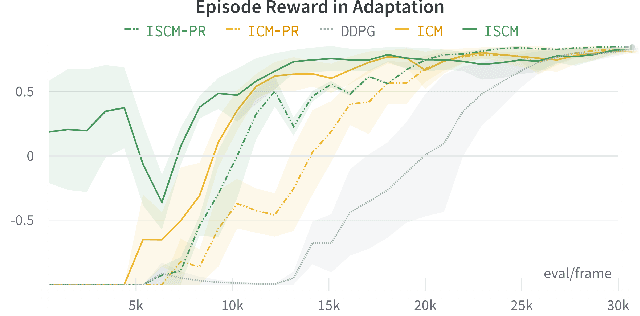
Sound is one of the most informative and abundant modalities in the real world while being robust to sense without contacts by small and cheap sensors that can be placed on mobile devices. Although deep learning is capable of extracting information from multiple sensory inputs, there has been little use of sound for the control and learning of robotic actions. For unsupervised reinforcement learning, an agent is expected to actively collect experiences and jointly learn representations and policies in a self-supervised way. We build realistic robotic manipulation scenarios with physics-based sound simulation and propose the Intrinsic Sound Curiosity Module (ISCM). The ISCM provides feedback to a reinforcement learner to learn robust representations and to reward a more efficient exploration behavior. We perform experiments with sound enabled during pre-training and disabled during adaptation, and show that representations learned by ISCM outperform the ones by vision-only baselines and pre-trained policies can accelerate the learning process when applied to downstream tasks.
Learning Flexible Translation between Robot Actions and Language Descriptions
Jul 15, 2022
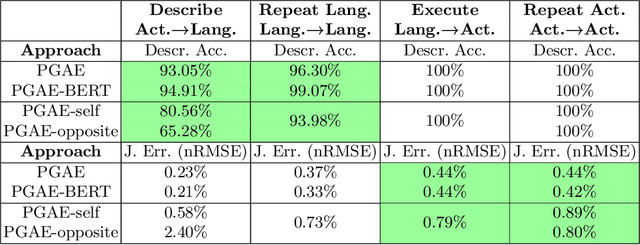

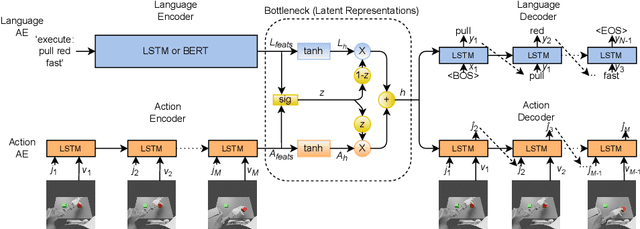
Handling various robot action-language translation tasks flexibly is an essential requirement for natural interaction between a robot and a human. Previous approaches require change in the configuration of the model architecture per task during inference, which undermines the premise of multi-task learning. In this work, we propose the paired gated autoencoders (PGAE) for flexible translation between robot actions and language descriptions in a tabletop object manipulation scenario. We train our model in an end-to-end fashion by pairing each action with appropriate descriptions that contain a signal informing about the translation direction. During inference, our model can flexibly translate from action to language and vice versa according to the given language signal. Moreover, with the option to use a pretrained language model as the language encoder, our model has the potential to recognise unseen natural language input. Another capability of our model is that it can recognise and imitate actions of another agent by utilising robot demonstrations. The experiment results highlight the flexible bidirectional translation capabilities of our approach alongside with the ability to generalise to the actions of the opposite-sitting agent.
Knowing Earlier what Right Means to You: A Comprehensive VQA Dataset for Grounding Relative Directions via Multi-Task Learning
Jul 06, 2022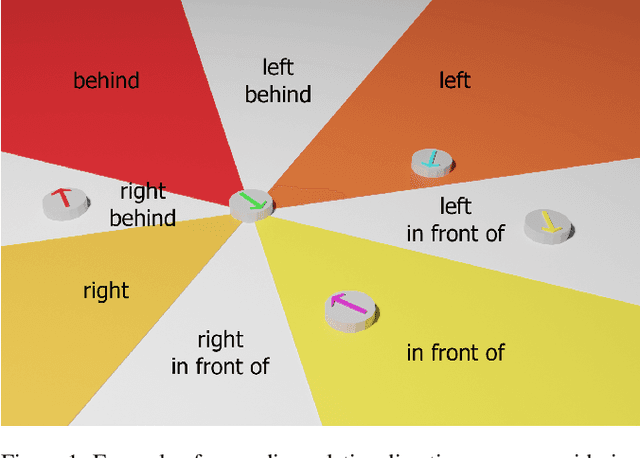
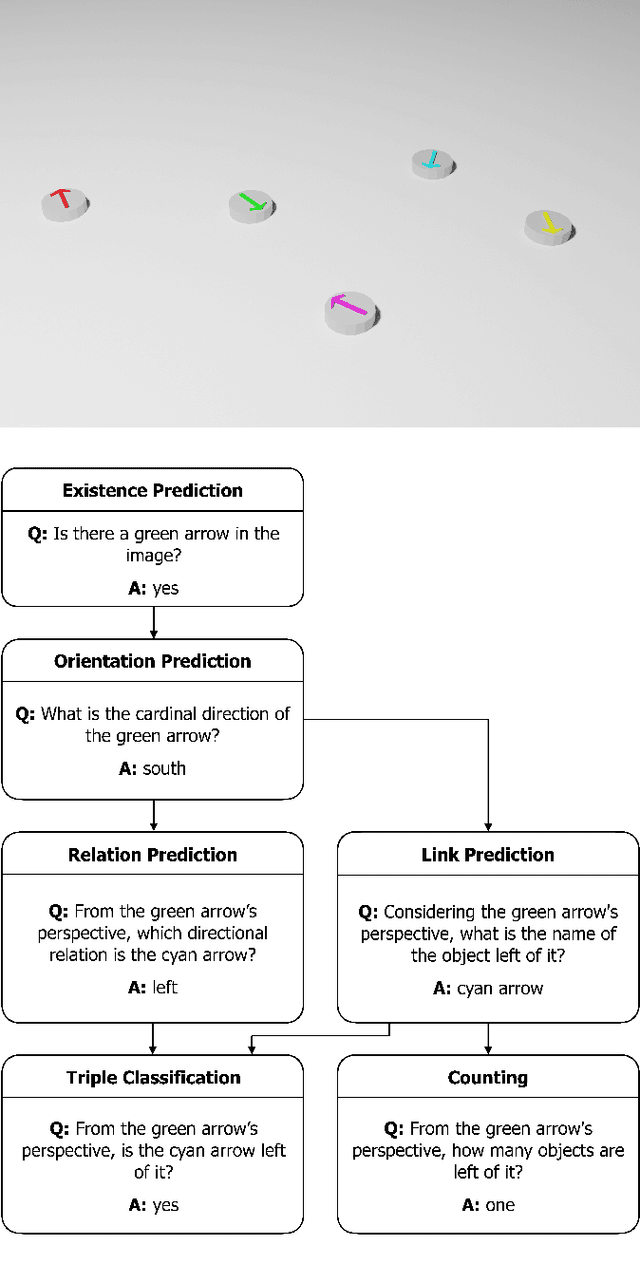

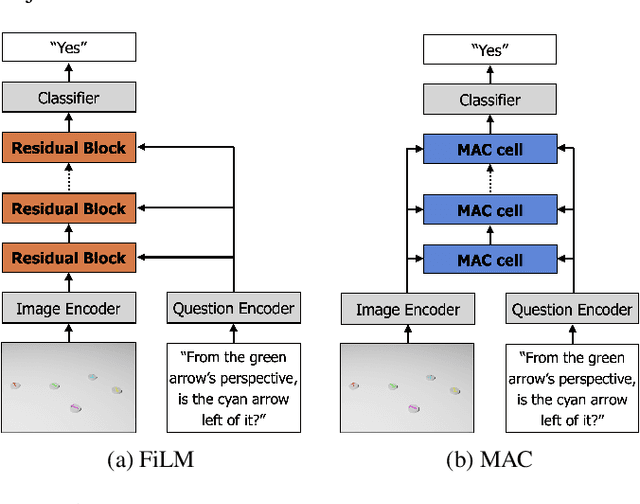
Spatial reasoning poses a particular challenge for intelligent agents and is at the same time a prerequisite for their successful interaction and communication in the physical world. One such reasoning task is to describe the position of a target object with respect to the intrinsic orientation of some reference object via relative directions. In this paper, we introduce GRiD-A-3D, a novel diagnostic visual question-answering (VQA) dataset based on abstract objects. Our dataset allows for a fine-grained analysis of end-to-end VQA models' capabilities to ground relative directions. At the same time, model training requires considerably fewer computational resources compared with existing datasets, yet yields a comparable or even higher performance. Along with the new dataset, we provide a thorough evaluation based on two widely known end-to-end VQA architectures trained on GRiD-A-3D. We demonstrate that within a few epochs, the subtasks required to reason over relative directions, such as recognizing and locating objects in a scene and estimating their intrinsic orientations, are learned in the order in which relative directions are intuitively processed.