 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlender Object Detection: Diagnoses and Improvements
Nov 21, 2020


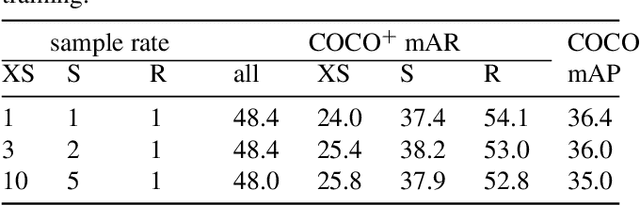
In this paper, we are concerned with the detection of a particular type of objects with extreme aspect ratios, namely slender objects. In real-world scenarios as well as widely-used datasets (such as COCO), slender objects are actually very common. However, this type of object has been largely overlooked by previous object detection algorithms. Upon our investigation, for a classical object detection method, a drastic drop of 18.9% mAP on COCO is observed, if solely evaluated on slender objects. Therefore, We systematically study the problem of slender object detection in this work. Accordingly, an analytical framework with carefully designed benchmark and evaluation protocols is established, in which different algorithms and modules can be inspected and compared. Our key findings include: 1) the essential role of anchors in label assignment; 2) the descriptive capability of the 2-point representation; 3) the crucial strategies for improving the detection of slender objects and regular objects. Our work identifies and extends the insights of existing methods that are previously underexploited. Furthermore, we propose a feature adaption strategy that achieves clear and consistent improvements over current representative object detection methods. In particular, a natural and effective extension of the center prior, which leads to a significant improvement on slender objects, is devised. We believe this work opens up new opportunities and calibrates ablation standards for future research in the field of object detection.
Differentiable Feature Aggregation Search for Knowledge Distillation
Aug 02, 2020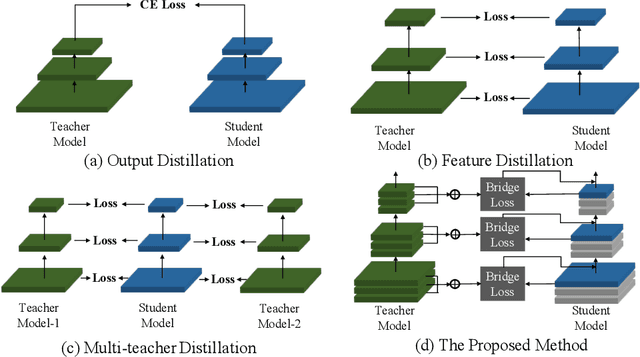
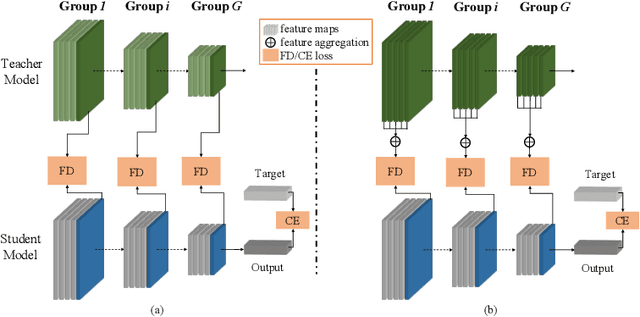

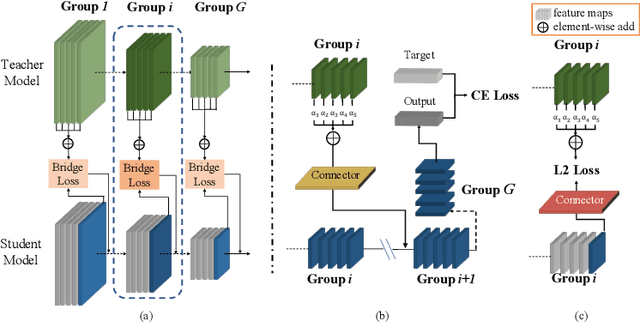
Knowledge distillation has become increasingly important in model compression. It boosts the performance of a miniaturized student network with the supervision of the output distribution and feature maps from a sophisticated teacher network. Some recent works introduce multi-teacher distillation to provide more supervision to the student network. However, the effectiveness of multi-teacher distillation methods are accompanied by costly computation resources. To tackle with both the efficiency and the effectiveness of knowledge distillation, we introduce the feature aggregation to imitate the multi-teacher distillation in the single-teacher distillation framework by extracting informative supervision from multiple teacher feature maps. Specifically, we introduce DFA, a two-stage Differentiable Feature Aggregation search method that motivated by DARTS in neural architecture search, to efficiently find the aggregations. In the first stage, DFA formulates the searching problem as a bi-level optimization and leverages a novel bridge loss, which consists of a student-to-teacher path and a teacher-to-student path, to find appropriate feature aggregations. The two paths act as two players against each other, trying to optimize the unified architecture parameters to the opposite directions while guaranteeing both expressivity and learnability of the feature aggregation simultaneously. In the second stage, DFA performs knowledge distillation with the derived feature aggregation. Experimental results show that DFA outperforms existing methods on CIFAR-100 and CINIC-10 datasets under various teacher-student settings, verifying the effectiveness and robustness of the design.
On Vocabulary Reliance in Scene Text Recognition
May 08, 2020
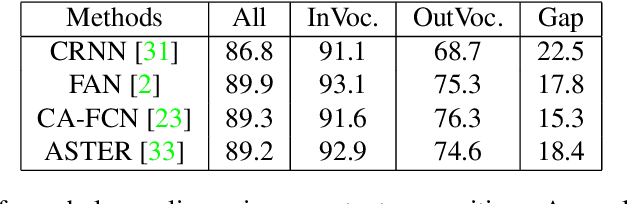
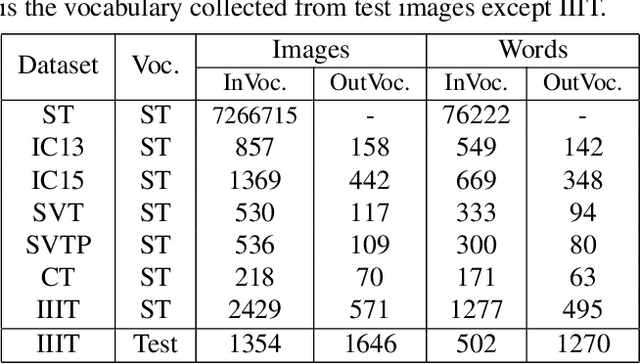

The pursuit of high performance on public benchmarks has been the driving force for research in scene text recognition, and notable progress has been achieved. However, a close investigation reveals a startling fact that the state-of-the-art methods perform well on images with words within vocabulary but generalize poorly to images with words outside vocabulary. We call this phenomenon "vocabulary reliance". In this paper, we establish an analytical framework to conduct an in-depth study on the problem of vocabulary reliance in scene text recognition. Key findings include: (1) Vocabulary reliance is ubiquitous, i.e., all existing algorithms more or less exhibit such characteristic; (2) Attention-based decoders prove weak in generalizing to words outside vocabulary and segmentation-based decoders perform well in utilizing visual features; (3) Context modeling is highly coupled with the prediction layers. These findings provide new insights and can benefit future research in scene text recognition. Furthermore, we propose a simple yet effective mutual learning strategy to allow models of two families (attention-based and segmentation-based) to learn collaboratively. This remedy alleviates the problem of vocabulary reliance and improves the overall scene text recognition performance.
* CVPR'20
UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World
Mar 24, 2020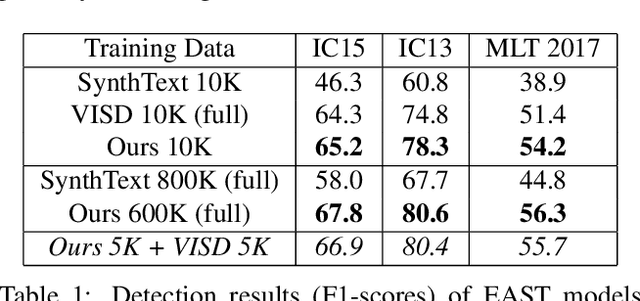
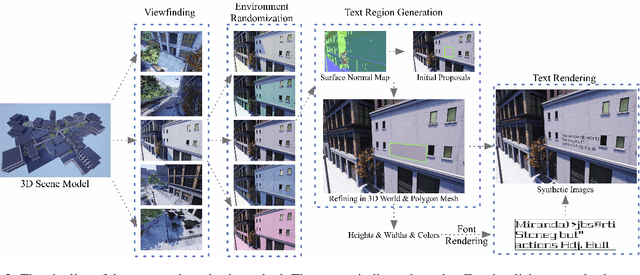
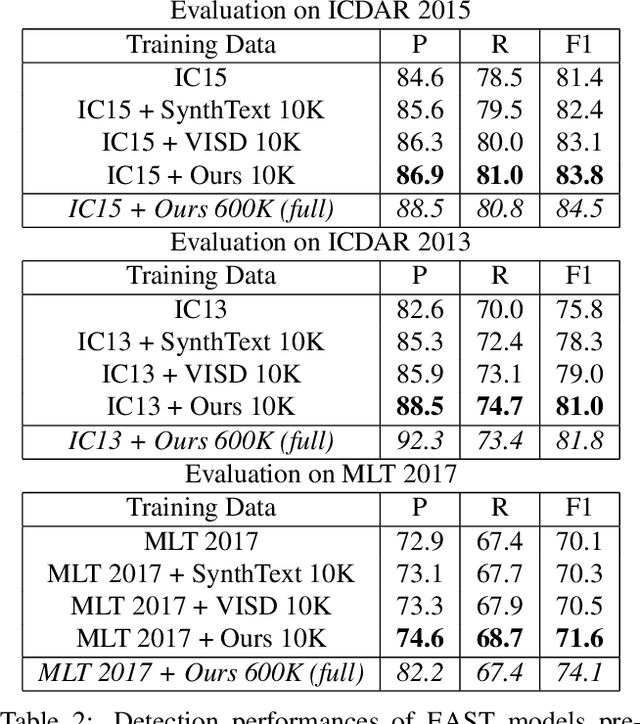

Synthetic data has been a critical tool for training scene text detection and recognition models. On the one hand, synthetic word images have proven to be a successful substitute for real images in training scene text recognizers. On the other hand, however, scene text detectors still heavily rely on a large amount of manually annotated real-world images, which are expensive. In this paper, we introduce UnrealText, an efficient image synthesis method that renders realistic images via a 3D graphics engine. 3D synthetic engine provides realistic appearance by rendering scene and text as a whole, and allows for better text region proposals with access to precise scene information, e.g. normal and even object meshes. The comprehensive experiments verify its effectiveness on both scene text detection and recognition. We also generate a multilingual version for future research into multilingual scene text detection and recognition. The code and the generated datasets are released at: https://github.com/Jyouhou/UnrealText/ .
A New Perspective for Flexible Feature Gathering in Scene Text Recognition Via Character Anchor Pooling
Feb 10, 2020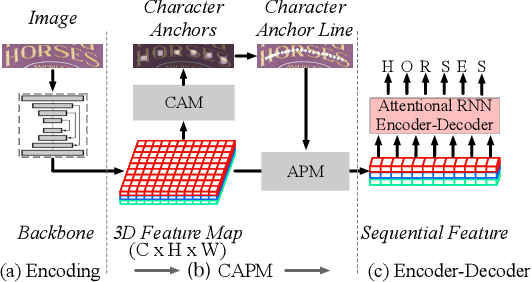
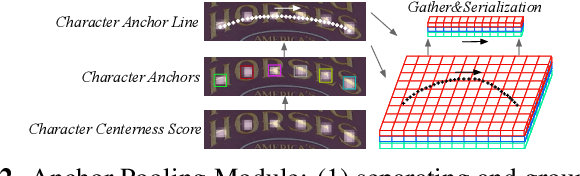

Irregular scene text recognition has attracted much attention from the research community, mainly due to the complexity of shapes of text in natural scene. However, recent methods either rely on shape-sensitive modules such as bounding box regression, or discard sequence learning. To tackle these issues, we propose a pair of coupling modules, termed as Character Anchoring Module (CAM) and Anchor Pooling Module (APM), to extract high-level semantics from two-dimensional space to form feature sequences. The proposed CAM localizes the text in a shape-insensitive way by design by anchoring characters individually. APM then interpolates and gathers features flexibly along the character anchors which enables sequence learning. The complementary modules realize a harmonic unification of spatial information and sequence learning. With the proposed modules, our recognition system surpasses previous state-of-the-art scores on irregular and perspective text datasets, including, ICDAR 2015, CUTE, and Total-Text, while paralleling state-of-the-art performance on regular text datasets.
TextScanner: Reading Characters in Order for Robust Scene Text Recognition
Jan 01, 2020
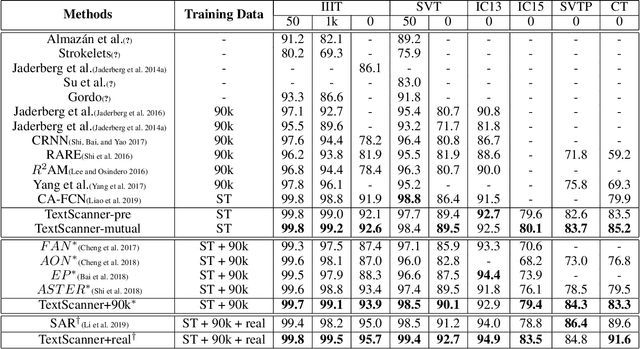
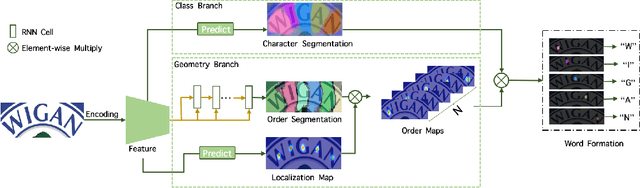
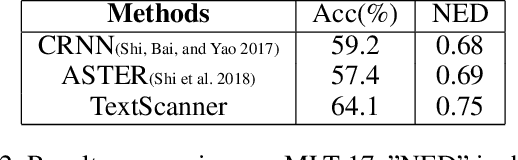
Driven by deep learning and the large volume of data, scene text recognition has evolved rapidly in recent years. Formerly, RNN-attention based methods have dominated this field, but suffer from the problem of \textit{attention drift} in certain situations. Lately, semantic segmentation based algorithms have proven effective at recognizing text of different forms (horizontal, oriented and curved). However, these methods may produce spurious characters or miss genuine characters, as they rely heavily on a thresholding procedure operated on segmentation maps. To tackle these challenges, we propose in this paper an alternative approach, called TextScanner, for scene text recognition. TextScanner bears three characteristics: (1) Basically, it belongs to the semantic segmentation family, as it generates pixel-wise, multi-channel segmentation maps for character class, position and order; (2) Meanwhile, akin to RNN-attention based methods, it also adopts RNN for context modeling; (3) Moreover, it performs paralleled prediction for character position and class, and ensures that characters are transcripted in correct order. The experiments on standard benchmark datasets demonstrate that TextScanner outperforms the state-of-the-art methods. Moreover, TextScanner shows its superiority in recognizing more difficult text such Chinese transcripts and aligning with target characters.
Real-time Scene Text Detection with Differentiable Binarization
Dec 03, 2019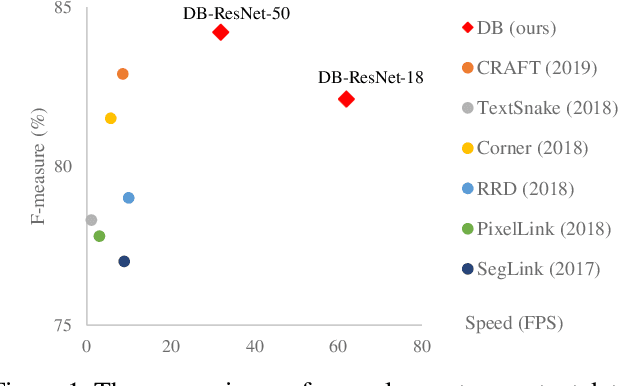
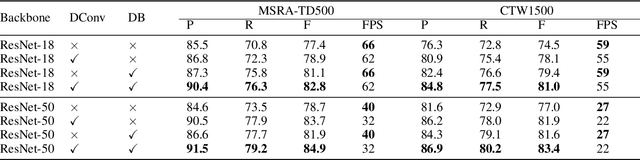
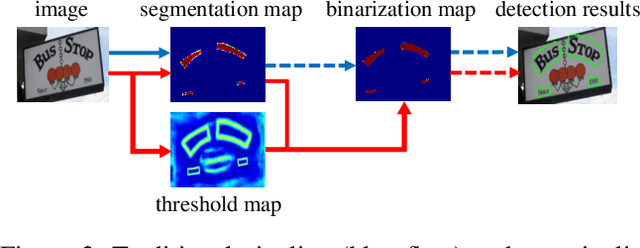
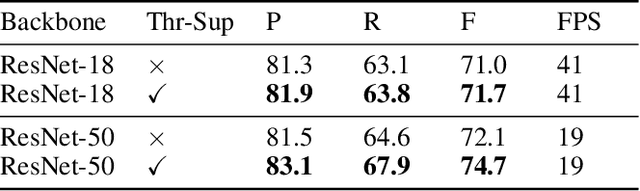
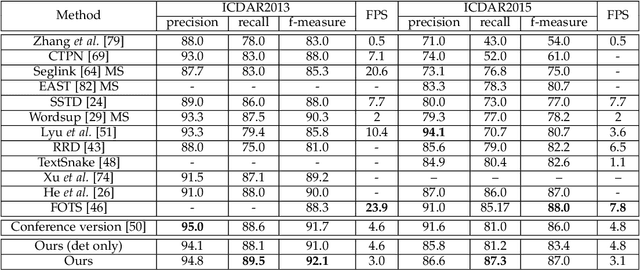
Recently, segmentation-based methods are quite popular in scene text detection, as the segmentation results can more accurately describe scene text of various shapes such as curve text. However, the post-processing of binarization is essential for segmentation-based detection, which converts probability maps produced by a segmentation method into bounding boxes/regions of text. In this paper, we propose a module named Differentiable Binarization (DB), which can perform the binarization process in a segmentation network. Optimized along with a DB module, a segmentation network can adaptively set the thresholds for binarization, which not only simplifies the post-processing but also enhances the performance of text detection. Based on a simple segmentation network, we validate the performance improvements of DB on five benchmark datasets, which consistently achieves state-of-the-art results, in terms of both detection accuracy and speed. In particular, with a light-weight backbone, the performance improvements by DB are significant so that we can look for an ideal tradeoff between detection accuracy and efficiency. Specifically, with a backbone of ResNet-18, our detector achieves an F-measure of 82.8, running at 62 FPS, on the MSRA-TD500 dataset. Code is available at: https://github.com/MhLiao/DB
Alchemy: Techniques for Rectification Based Irregular Scene Text Recognition
Aug 30, 2019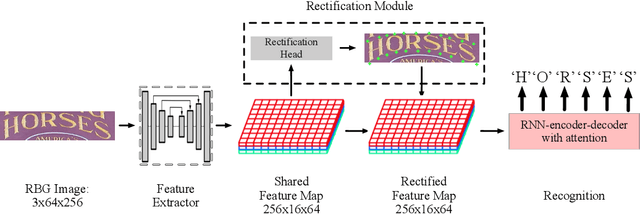
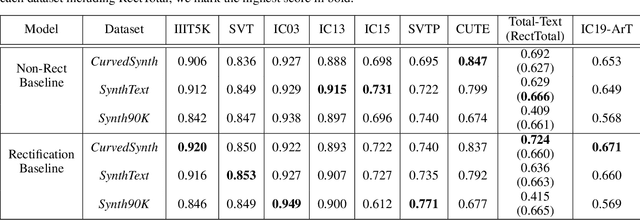

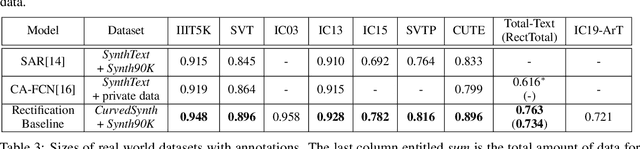
Reading text from natural images is challenging due to the great variety in text font, color, size, complex background and etc.. The perspective distortion and non-linear spatial arrangement of characters make it further difficult. While rectification based method is intuitively grounded and has pushed the envelope by far, its potential is far from being well exploited. In this paper, we present a bag of tricks that prove to significantly improve the performance of rectification based method. On curved text dataset, our method achieves an accuracy of 89.6% on CUTE-80 and 76.3% on Total-Text, an improvement over previous state-of-the-art by 6.3% and 14.7% respectively. Furthermore, our combination of tricks helps us win the ICDAR 2019 Arbitrary-Shaped Text Challenge (Latin script), achieving an accuracy of 74.3% on the held-out test set. We release our code as well as data samples for further exploration at https://github.com/Jyouhou/ICDAR2019-ArT-Recognition-Alchemy
Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
Aug 22, 2019
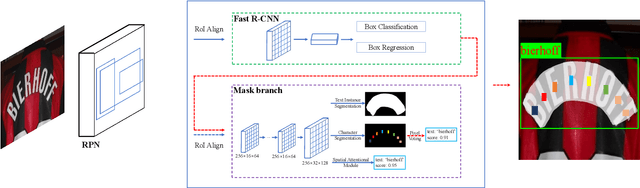
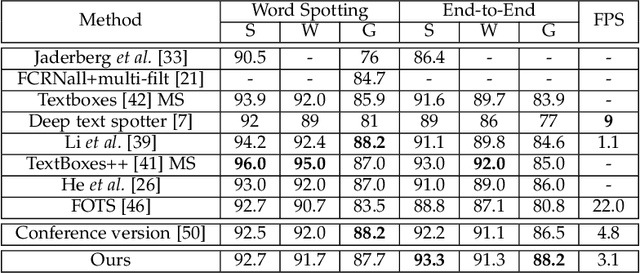
Unifying text detection and text recognition in an end-to-end training fashion has become a new trend for reading text in the wild, as these two tasks are highly relevant and complementary. In this paper, we investigate the problem of scene text spotting, which aims at simultaneous text detection and recognition in natural images. An end-to-end trainable neural network named as Mask TextSpotter is presented. Different from the previous text spotters that follow the pipeline consisting of a proposal generation network and a sequence-to-sequence recognition network, Mask TextSpotter enjoys a simple and smooth end-to-end learning procedure, in which both detection and recognition can be achieved directly from two-dimensional space via semantic segmentation. Further, a spatial attention module is proposed to enhance the performance and universality. Benefiting from the proposed two-dimensional representation on both detection and recognition, it easily handles text instances of irregular shapes, for instance, curved text. We evaluate it on four English datasets and one multi-language dataset, achieving consistently superior performance over state-of-the-art methods in both detection and end-to-end text recognition tasks. Moreover, we further investigate the recognition module of our method separately, which significantly outperforms state-of-the-art methods on both regular and irregular text datasets for scene text recognition.
Symmetry-constrained Rectification Network for Scene Text Recognition
Aug 06, 2019
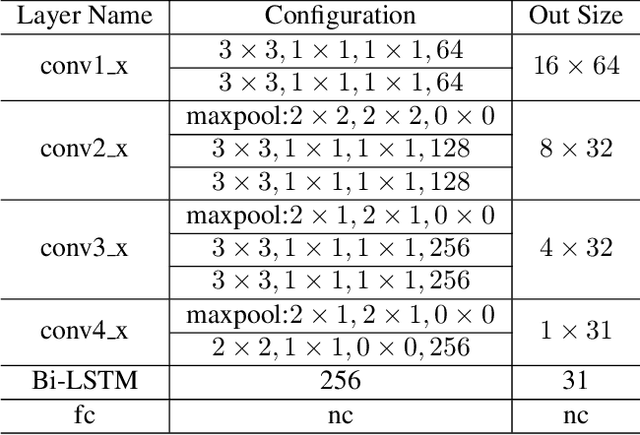

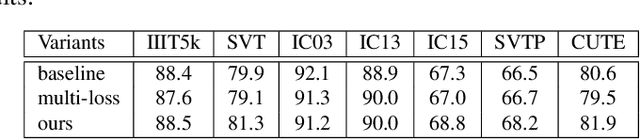
Reading text in the wild is a very challenging task due to the diversity of text instances and the complexity of natural scenes. Recently, the community has paid increasing attention to the problem of recognizing text instances with irregular shapes. One intuitive and effective way to handle this problem is to rectify irregular text to a canonical form before recognition. However, these methods might struggle when dealing with highly curved or distorted text instances. To tackle this issue, we propose in this paper a Symmetry-constrained Rectification Network (ScRN) based on local attributes of text instances, such as center line, scale and orientation. Such constraints with an accurate description of text shape enable ScRN to generate better rectification results than existing methods and thus lead to higher recognition accuracy. Our method achieves state-of-the-art performance on text with both regular and irregular shapes. Specifically, the system outperforms existing algorithms by a large margin on datasets that contain quite a proportion of irregular text instances, e.g., ICDAR 2015, SVT-Perspective and CUTE80.