 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset
Apr 26, 2020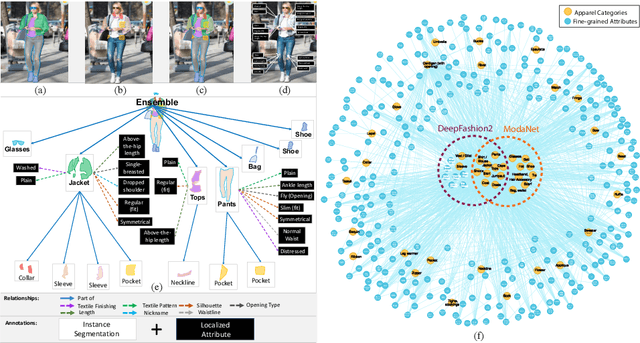


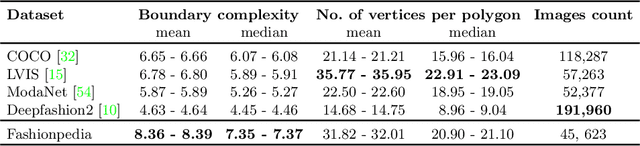
In this work we explore the task of instance segmentation with attribute localization, which unifies instance segmentation (detect and segment each object instance) and fine-grained visual attribute categorization (recognize one or multiple attributes). The proposed task requires both localizing an object and describing its properties. To illustrate the various aspects of this task, we focus on the domain of fashion and introduce Fashionpedia as a step toward mapping out the visual aspects of the fashion world. Fashionpedia consists of two parts: (1) an ontology built by fashion experts containing 27 main apparel categories, 19 apparel parts, 294 fine-grained attributes and their relationships; (2) a dataset with everyday and celebrity event fashion images annotated with segmentation masks and their associated per-mask fine-grained attributes, built upon the Fashionpedia ontology. In order to solve this challenging task, we propose a novel Attribute-Mask RCNN model to jointly perform instance segmentation and localized attribute recognition, and provide a novel evaluation metric for the task. We also demonstrate instance segmentation models pre-trained on Fashionpedia achieve better transfer learning performance on other fashion datasets than ImageNet pre-training. Fashionpedia is available at: https://fashionpedia.github.io/home/index.html.
Dialogue-Based Relation Extraction
Apr 17, 2020
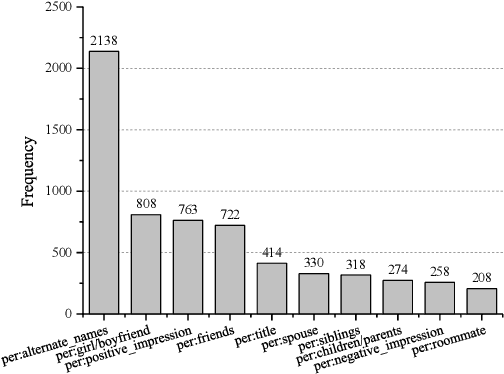
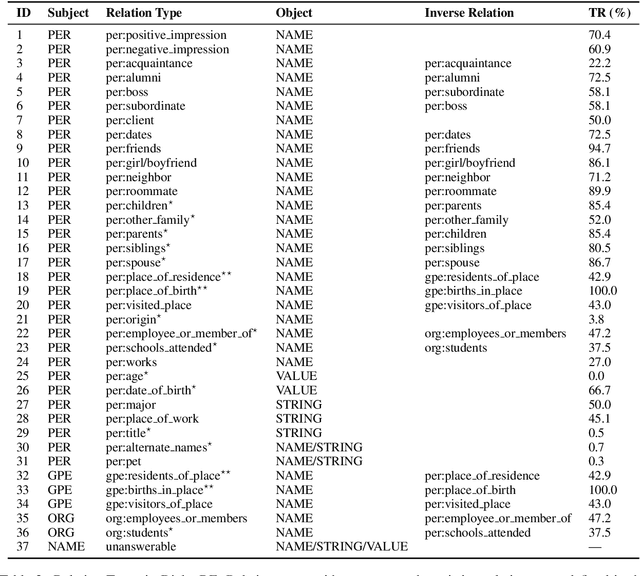
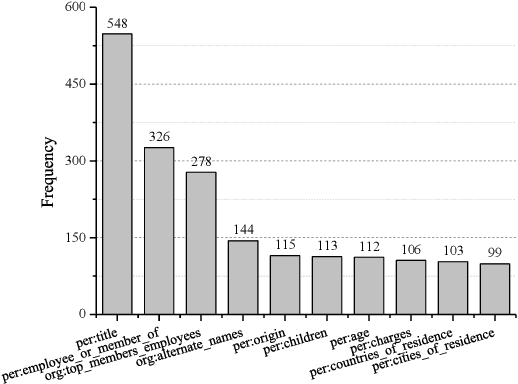
We present the first human-annotated dialogue-based relation extraction (RE) dataset DialogRE, aiming to support the prediction of relation(s) between two arguments that appear in a dialogue. We further offer DialogRE as a platform for studying cross-sentence RE as most facts span multiple sentences. We argue that speaker-related information plays a critical role in the proposed task, based on an analysis of similarities and differences between dialogue-based and traditional RE tasks. Considering the timeliness of communication in a dialogue, we design a new metric to evaluate the performance of RE methods in a conversational setting and investigate the performance of several representative RE methods on DialogRE. Experimental results demonstrate that a speaker-aware extension on the best-performing model leads to gains in both the standard and conversational evaluation settings. DialogRE is available at https://dataset.org/dialogre/.
The Role of Pragmatic and Discourse Context in Determining Argument Impact
Apr 06, 2020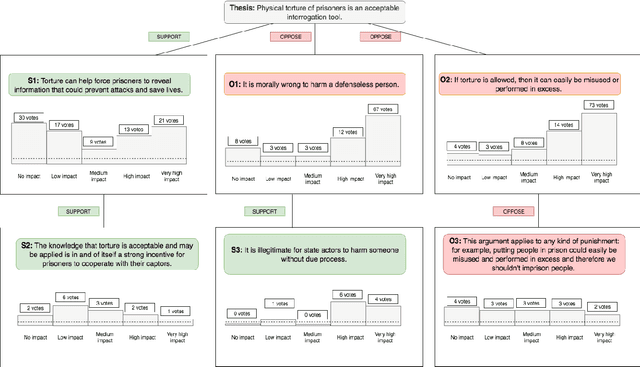

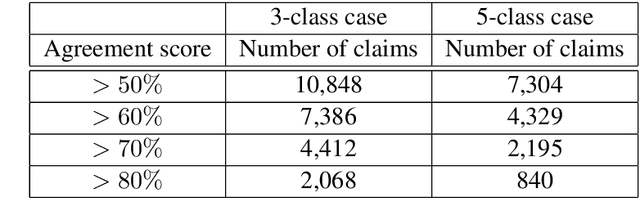
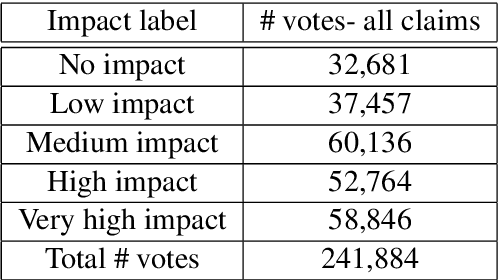
Research in the social sciences and psychology has shown that the persuasiveness of an argument depends not only the language employed, but also on attributes of the source/communicator, the audience, and the appropriateness and strength of the argument's claims given the pragmatic and discourse context of the argument. Among these characteristics of persuasive arguments, prior work in NLP does not explicitly investigate the effect of the pragmatic and discourse context when determining argument quality. This paper presents a new dataset to initiate the study of this aspect of argumentation: it consists of a diverse collection of arguments covering 741 controversial topics and comprising over 47,000 claims. We further propose predictive models that incorporate the pragmatic and discourse context of argumentative claims and show that they outperform models that rely only on claim-specific linguistic features for predicting the perceived impact of individual claims within a particular line of argument.
Determining Relative Argument Specificity and Stance for Complex Argumentative Structures
Jun 26, 2019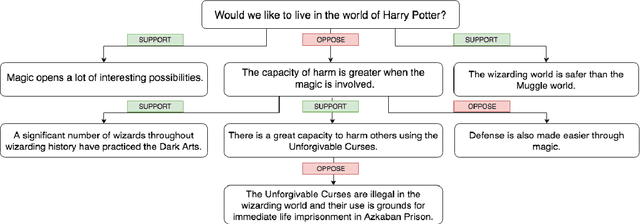

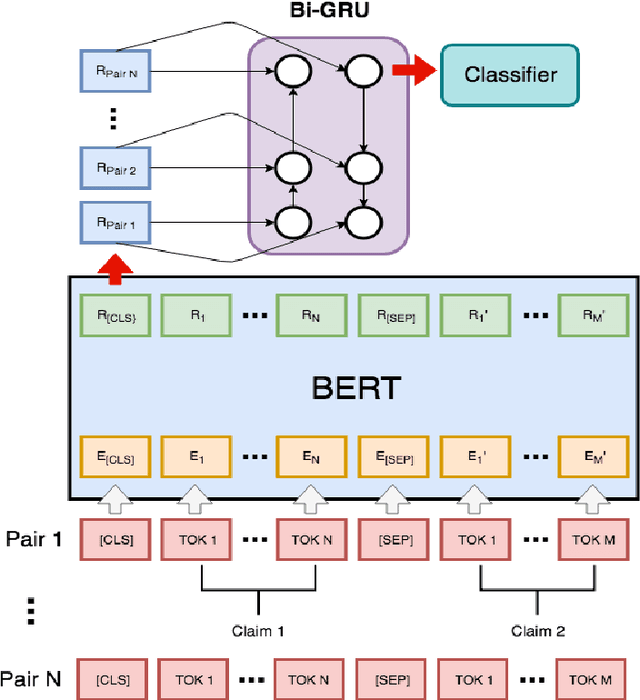
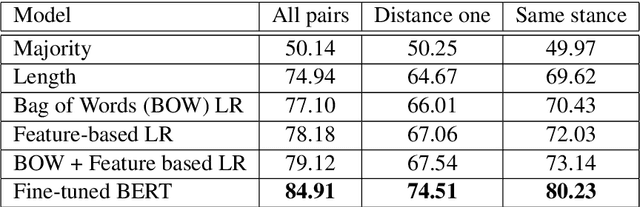
Systems for automatic argument generation and debate require the ability to (1) determine the stance of any claims employed in the argument and (2) assess the specificity of each claim relative to the argument context. Existing work on understanding claim specificity and stance, however, has been limited to the study of argumentative structures that are relatively shallow, most often consisting of a single claim that directly supports or opposes the argument thesis. In this paper, we tackle these tasks in the context of complex arguments on a diverse set of topics. In particular, our dataset consists of manually curated argument trees for 741 controversial topics covering 95,312 unique claims; lines of argument are generally of depth 2 to 6. We find that as the distance between a pair of claims increases along the argument path, determining the relative specificity of a pair of claims becomes easier and determining their relative stance becomes harder.
A Corpus for Modeling User and Language Effects in Argumentation on Online Debating
Jun 26, 2019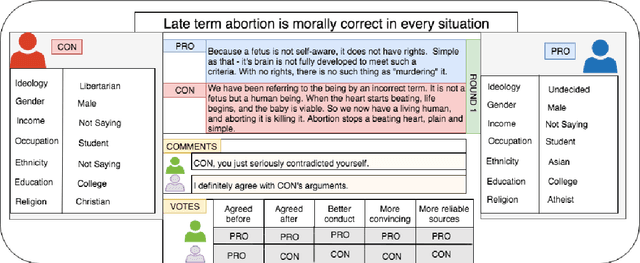
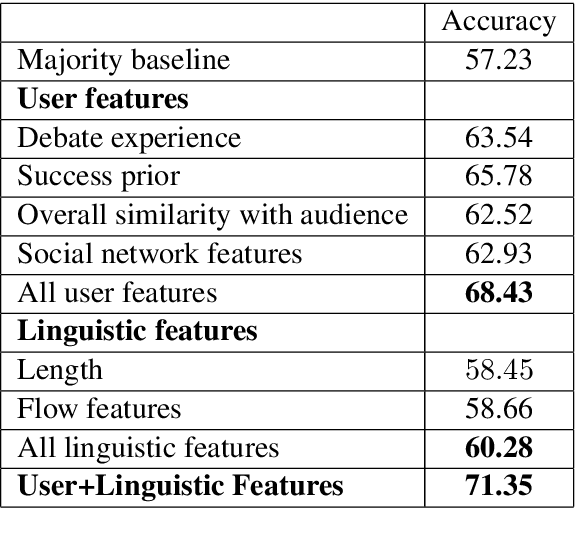
Existing argumentation datasets have succeeded in allowing researchers to develop computational methods for analyzing the content, structure and linguistic features of argumentative text. They have been much less successful in fostering studies of the effect of "user" traits -- characteristics and beliefs of the participants -- on the debate/argument outcome as this type of user information is generally not available. This paper presents a dataset of 78, 376 debates generated over a 10-year period along with surprisingly comprehensive participant profiles. We also complete an example study using the dataset to analyze the effect of selected user traits on the debate outcome in comparison to the linguistic features typically employed in studies of this kind.
Exploring the Role of Prior Beliefs for Argument Persuasion
Jun 26, 2019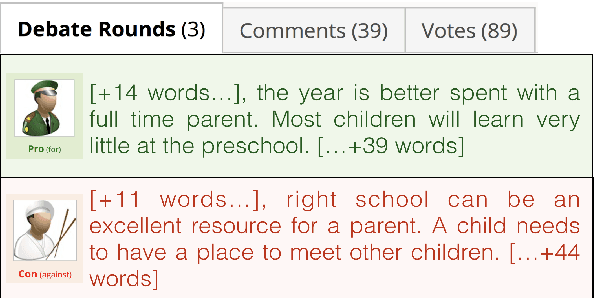


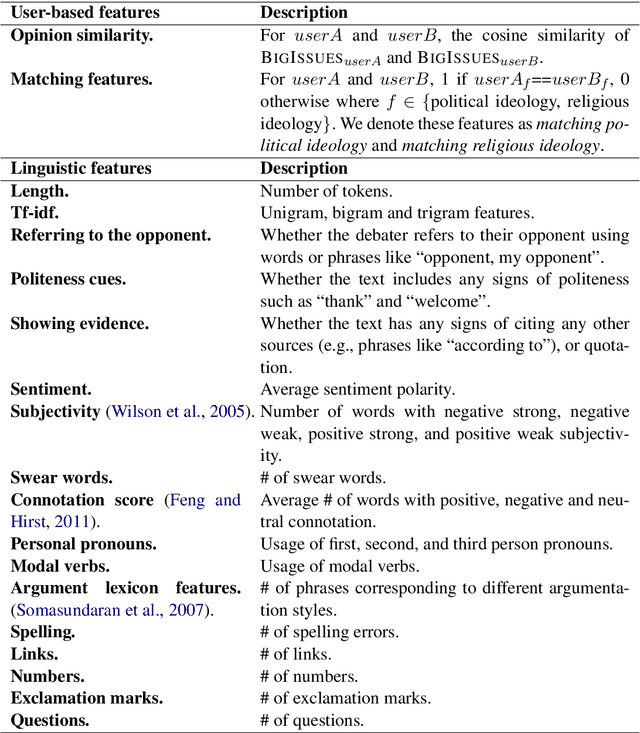
Public debate forums provide a common platform for exchanging opinions on a topic of interest. While recent studies in natural language processing (NLP) have provided empirical evidence that the language of the debaters and their patterns of interaction play a key role in changing the mind of a reader, research in psychology has shown that prior beliefs can affect our interpretation of an argument and could therefore constitute a competing alternative explanation for resistance to changing one's stance. To study the actual effect of language use vs. prior beliefs on persuasion, we provide a new dataset and propose a controlled setting that takes into consideration two reader level factors: political and religious ideology. We find that prior beliefs affected by these reader level factors play a more important role than language use effects and argue that it is important to account for them in NLP studies of persuasion.
Be Consistent! Improving Procedural Text Comprehension using Label Consistency
Jun 21, 2019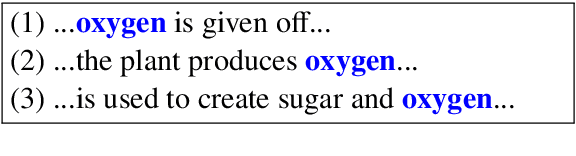
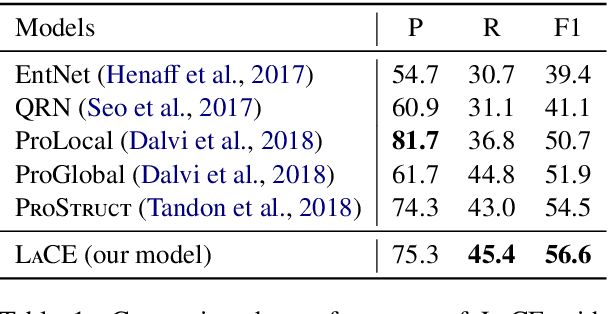
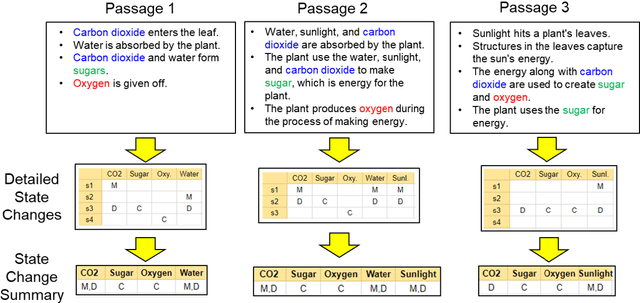
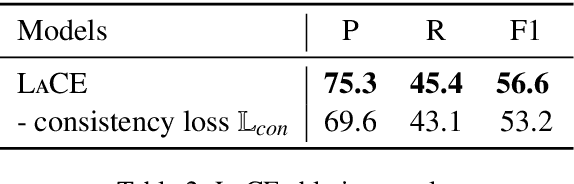
Our goal is procedural text comprehension, namely tracking how the properties of entities (e.g., their location) change with time given a procedural text (e.g., a paragraph about photosynthesis, a recipe). This task is challenging as the world is changing throughout the text, and despite recent advances, current systems still struggle with this task. Our approach is to leverage the fact that, for many procedural texts, multiple independent descriptions are readily available, and that predictions from them should be consistent (label consistency). We present a new learning framework that leverages label consistency during training, allowing consistency bias to be built into the model. Evaluation on a standard benchmark dataset for procedural text, ProPara (Dalvi et al., 2018), shows that our approach significantly improves prediction performance (F1) over prior state-of-the-art systems.
Keeping Notes: Conditional Natural Language Generation with a Scratchpad Mechanism
Jun 13, 2019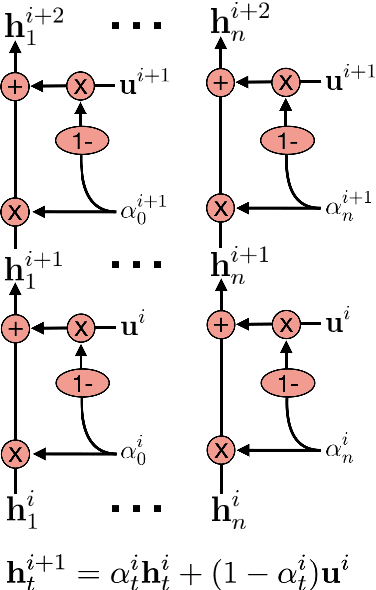
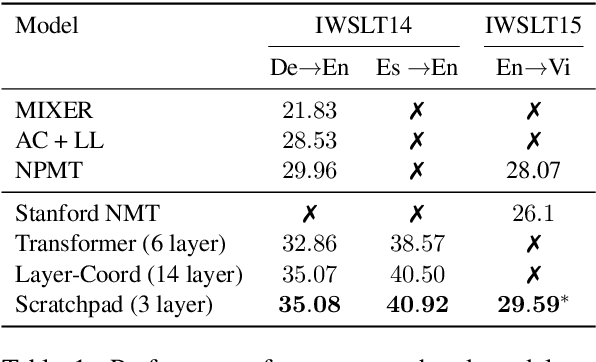
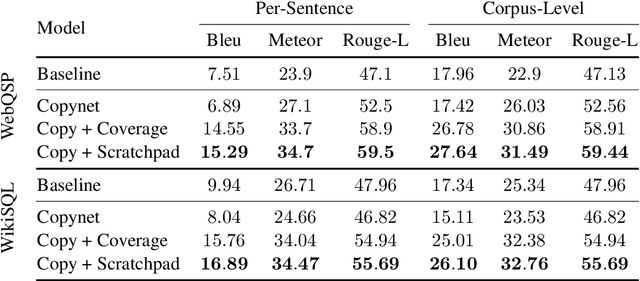
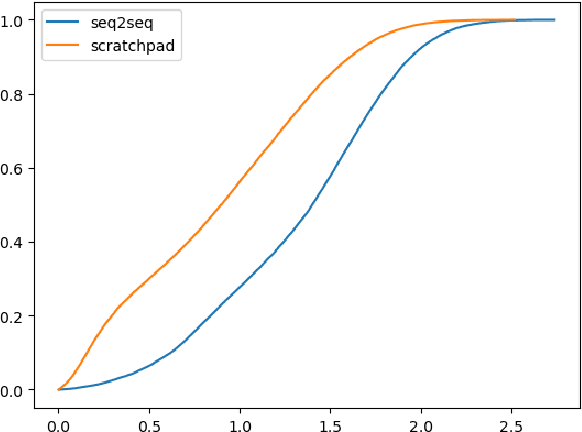
We introduce the Scratchpad Mechanism, a novel addition to the sequence-to-sequence (seq2seq) neural network architecture and demonstrate its effectiveness in improving the overall fluency of seq2seq models for natural language generation tasks. By enabling the decoder at each time step to write to all of the encoder output layers, Scratchpad can employ the encoder as a "scratchpad" memory to keep track of what has been generated so far and thereby guide future generation. We evaluate Scratchpad in the context of three well-studied natural language generation tasks --- Machine Translation, Question Generation, and Text Summarization --- and obtain state-of-the-art or comparable performance on standard datasets for each task. Qualitative assessments in the form of human judgements (question generation), attention visualization (MT), and sample output (summarization) provide further evidence of the ability of Scratchpad to generate fluent and expressive output.
Probing Prior Knowledge Needed in Challenging Chinese Machine Reading Comprehension
Apr 30, 2019


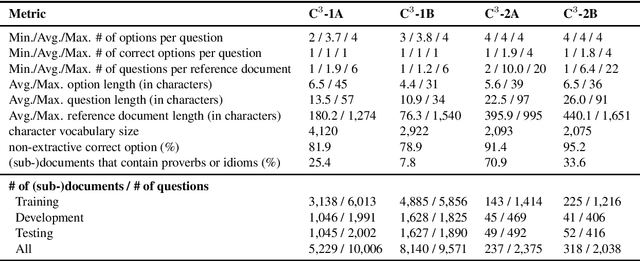
With an ultimate goal of narrowing the gap between human and machine readers in text comprehension, we present the first collection of Challenging Chinese machine reading Comprehension datasets (C^3) collected from language and professional certification exams, which contains 13,924 documents and their associated 23,990 multiple-choice questions. Most of the questions in C^3 cannot be answered merely by surface-form matching against the given text. As a pilot study, we closely analyze the prior knowledge (i.e., linguistic, domain-specific, and general world knowledge) needed in these real-world reading comprehension tasks. We further explore how to leverage linguistic knowledge including a lexicon of idioms and proverbs, graphs of general world knowledge (e.g., ConceptNet), and domain-specific knowledge such as textbooks to aid machine readers, through fine-tuning a pre-trained language model. Experimental results demonstrate that linguistic and general world knowledge may help improve the performance of the baseline reader in both general and domain-specific tasks. C^3 will be available at http://dataset.org/c3/.
DREAM: A Challenge Dataset and Models for Dialogue-Based Reading Comprehension
Feb 01, 2019We present DREAM, the first dialogue-based multiple-choice reading comprehension dataset. Collected from English-as-a-foreign-language examinations designed by human experts to evaluate the comprehension level of Chinese learners of English, our dataset contains 10,197 multiple-choice questions for 6,444 dialogues. In contrast to existing reading comprehension datasets, DREAM is the first to focus on in-depth multi-turn multi-party dialogue understanding. DREAM is likely to present significant challenges for existing reading comprehension systems: 84% of answers are non-extractive, 85% of questions require reasoning beyond a single sentence, and 34% of questions also involve commonsense knowledge. We apply several popular neural reading comprehension models that primarily exploit surface information within the text and find them to, at best, just barely outperform a rule-based approach. We next investigate the effects of incorporating dialogue structure and different kinds of general world knowledge into both rule-based and (neural and non-neural) machine learning-based reading comprehension models. Experimental results on the DREAM dataset show the effectiveness of dialogue structure and general world knowledge. DREAM will be available at https://dataset.org/dream/.