 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeja-vu: Double Feature Presentation in Deep Transformer Networks
Oct 23, 2019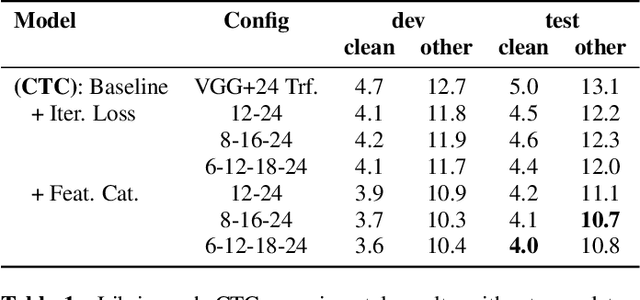
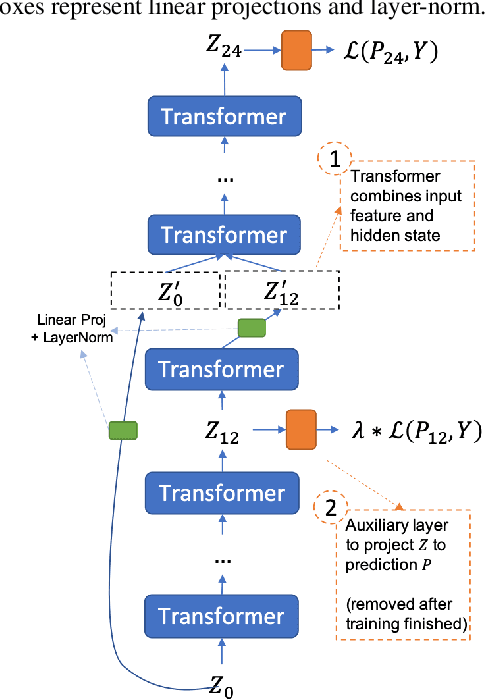
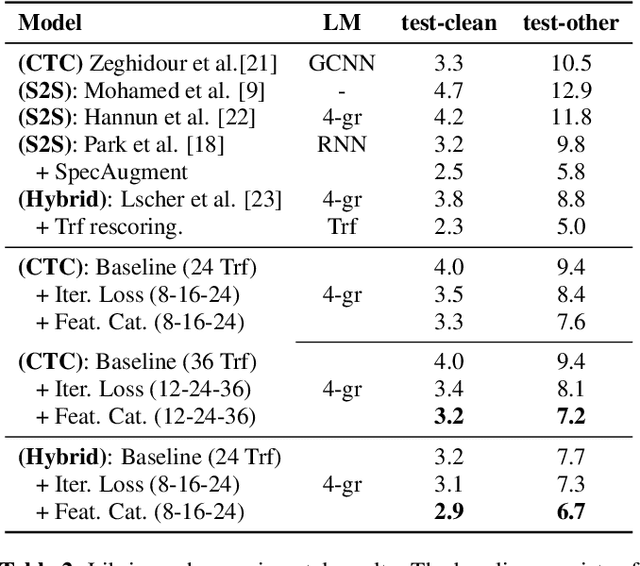
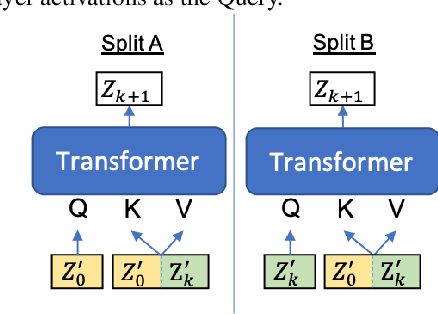
Deep acoustic models typically receive features in the first layer of the network, and process increasingly abstract representations in the subsequent layers. Here, we propose to feed the input features at multiple depths in the acoustic model. As our motivation is to allow acoustic models to re-examine their input features in light of partial hypotheses we introduce intermediate model heads and loss function. We study this architecture in the context of deep Transformer networks, and we use an attention mechanism over both the previous layer activations and the input features. To train this model's intermediate output hypothesis, we apply the objective function at each layer right before feature re-use. We find that the use of such intermediate losses significantly improves performance by itself, as well as enabling input feature re-use. We present results on both Librispeech, and a large scale video dataset, with relative improvements of 10 - 20% for Librispeech and 3.2 - 13% for videos.
Transformer-based Acoustic Modeling for Hybrid Speech Recognition
Oct 22, 2019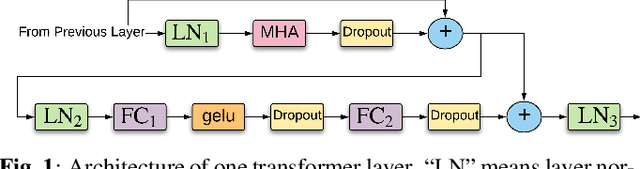
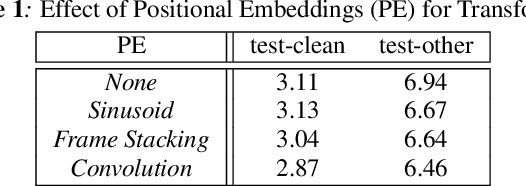
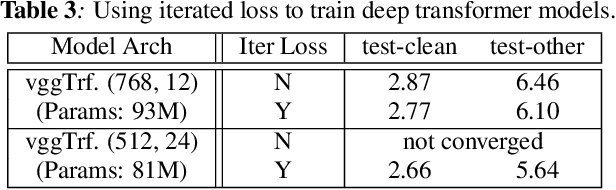
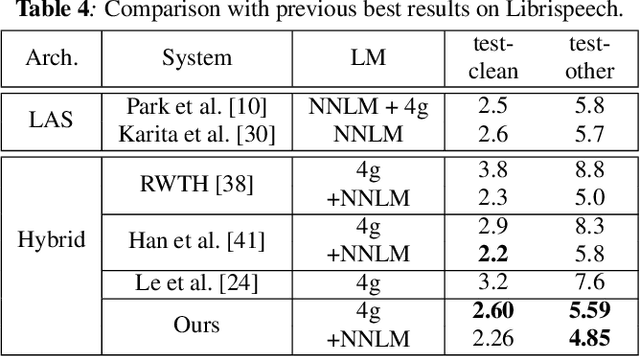
We propose and evaluate transformer-based acoustic models (AMs) for hybrid speech recognition. Several modeling choices are discussed in this work, including various positional embedding methods and an iterated loss to enable training deep transformers. We also present a preliminary study of using limited right context in transformer models, which makes it possible for streaming applications. We demonstrate that on the widely used Librispeech benchmark, our transformer-based AM outperforms the best published hybrid result by 19% to 26% relative when the standard n-gram language model (LM) is used. Combined with neural network LM for rescoring, our proposed approach achieves state-of-the-art results on Librispeech. Our findings are also confirmed on a much larger internal dataset.
Multilingual ASR with Massive Data Augmentation
Sep 14, 2019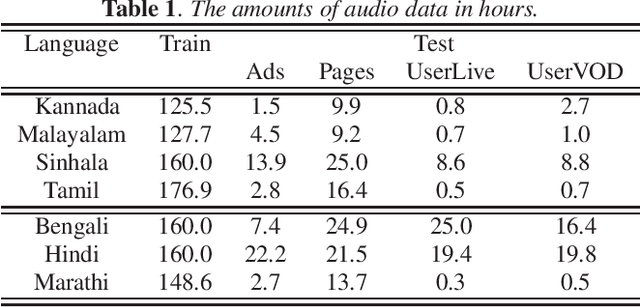
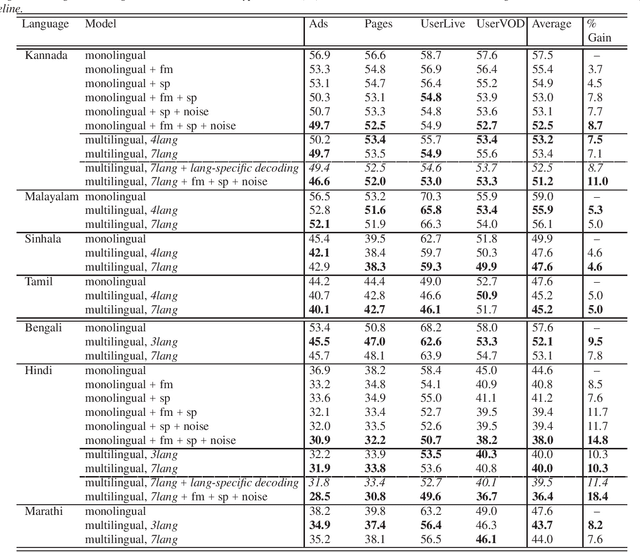
Towards developing high-performing ASR for low-resource languages, approaches to address the lack of resources are to make use of data from multiple languages, and to augment the training data by creating acoustic variations. In this work we present a single grapheme-based ASR model learned on 7 geographically proximal languages, using standard hybrid BLSTM-HMM acoustic models with lattice-free MMI objective. We build the single ASR grapheme set via taking the union over each language-specific grapheme set, and we find such multilingual ASR model can perform language-independent recognition on all 7 languages, and substantially outperform each monolingual ASR model. Secondly, we evaluate the efficacy of multiple data augmentation alternatives within language, as well as their complementarity with multilingual modeling. Overall, we show that the proposed multilingual ASR with various data augmentation can not only recognize any within training set languages, but also provide large ASR performance improvements.
Low Resource Multi-modal Data Augmentation for End-to-end ASR
Dec 10, 2018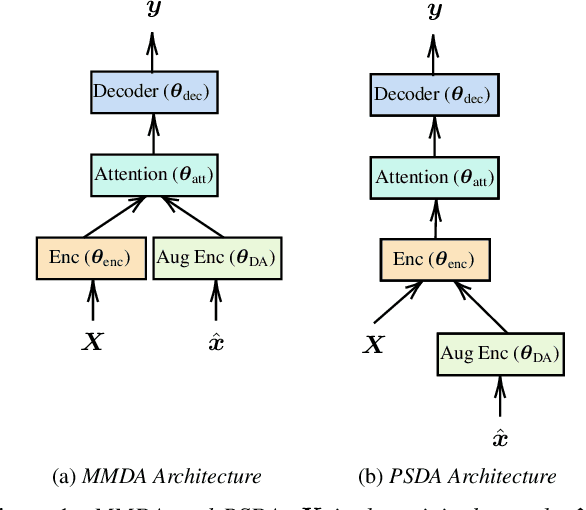
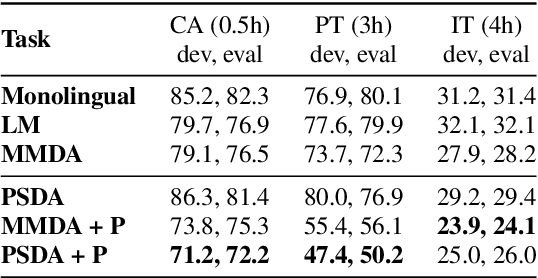

We explore training attention-based encoder-decoder ASR for low-resource languages and present techniques that result in a 50% relative improvement in character error rate compared to a standard baseline. The performance of encoder-decoder ASR systems depends on having sufficient target-side text to train the attention and decoder networks. The lack of such data in low-resource contexts results in severely degraded performance. In this paper we present a data augmentation scheme tailored for low-resource ASR in diverse languages. Across 3 test languages, our approach resulted in a 20% average relative improvement over a baseline text-based augmentation technique. We further compare the performance of our monolingual text-based data augmentation to speech-based data augmentation from nearby languages and find that this gives a further 20-30% relative reduction in character error rate.
Low-Resource Contextual Topic Identification on Speech
Sep 28, 2018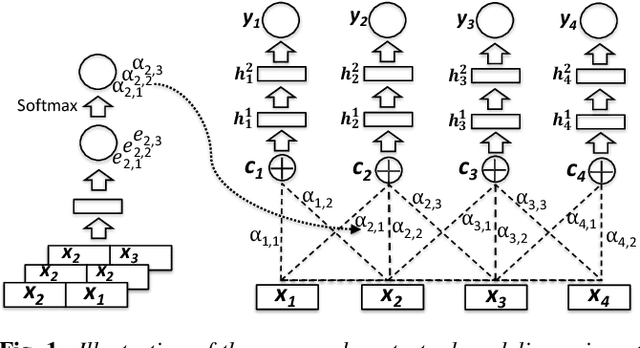

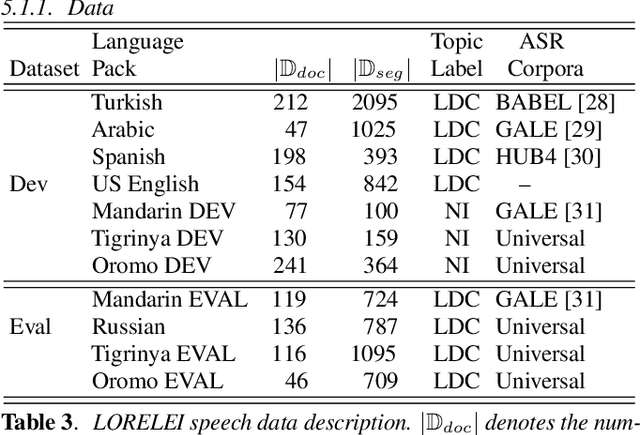
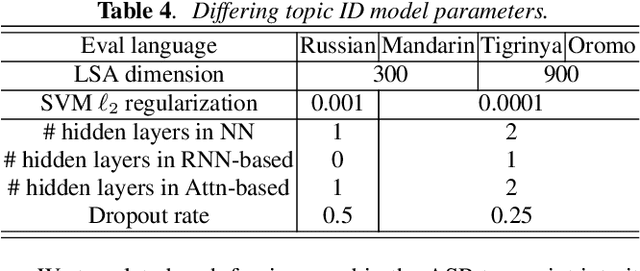
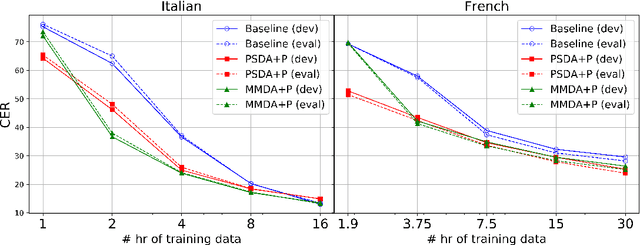
In topic identification (topic ID) on real-world unstructured audio, an audio instance of variable topic shifts is first broken into sequential segments, and each segment is independently classified. We first present a general purpose method for topic ID on spoken segments in low-resource languages, using a cascade of universal acoustic modeling, translation lexicons to English, and English-language topic classification. Next, instead of classifying each segment independently, we demonstrate that exploring the contextual dependencies across sequential segments can provide large improvements. In particular, we propose an attention-based contextual model which is able to leverage the contexts in a selective manner. We test both our contextual and non-contextual models on four LORELEI languages, and on all but one our attention-based contextual model significantly outperforms the context-independent models.
Automatic Speech Recognition and Topic Identification for Almost-Zero-Resource Languages
Jun 18, 2018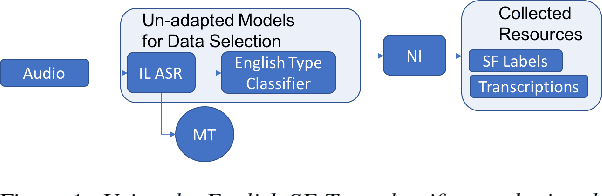
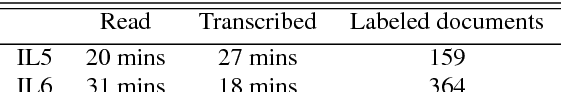
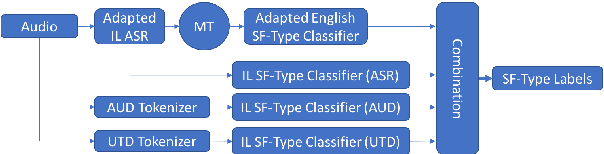
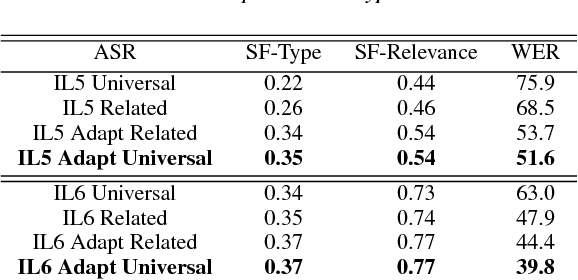
Automatic speech recognition (ASR) systems often need to be developed for extremely low-resource languages to serve end-uses such as audio content categorization and search. While universal phone recognition is natural to consider when no transcribed speech is available to train an ASR system in a language, adapting universal phone models using very small amounts (minutes rather than hours) of transcribed speech also needs to be studied, particularly with state-of-the-art DNN-based acoustic models. The DARPA LORELEI program provides a framework for such very-low-resource ASR studies, and provides an extrinsic metric for evaluating ASR performance in a humanitarian assistance, disaster relief setting. This paper presents our Kaldi-based systems for the program, which employ a universal phone modeling approach to ASR, and describes recipes for very rapid adaptation of this universal ASR system. The results we obtain significantly outperform results obtained by many competing approaches on the NIST LoReHLT 2017 Evaluation datasets.
Topic Identification for Speech without ASR
Jul 11, 2017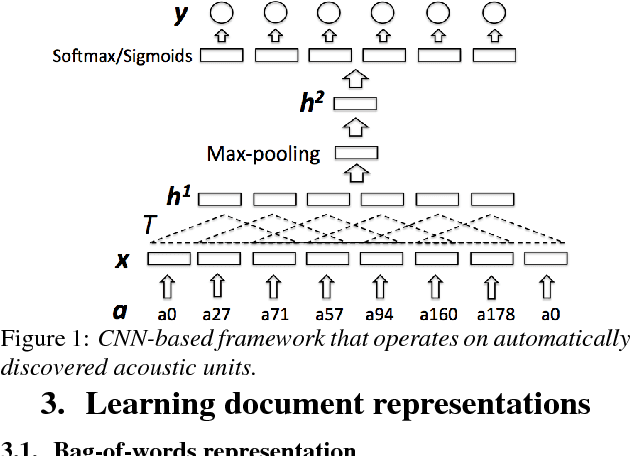
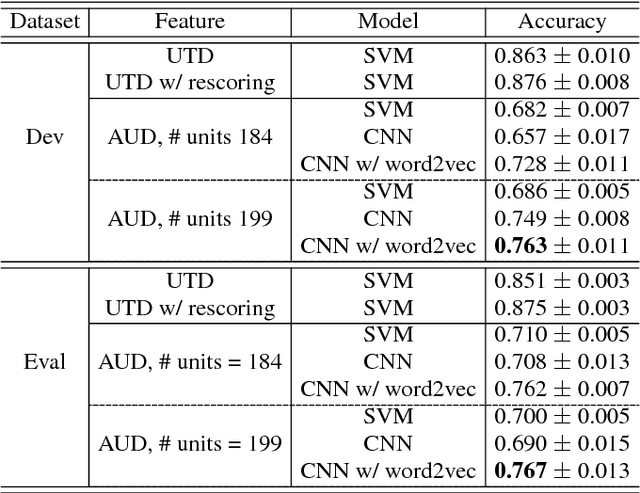
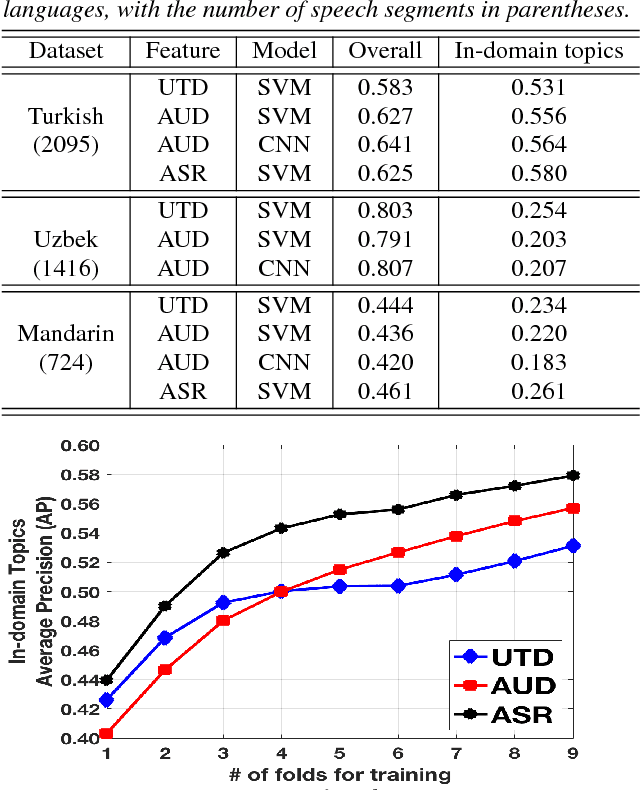
Modern topic identification (topic ID) systems for speech use automatic speech recognition (ASR) to produce speech transcripts, and perform supervised classification on such ASR outputs. However, under resource-limited conditions, the manually transcribed speech required to develop standard ASR systems can be severely limited or unavailable. In this paper, we investigate alternative unsupervised solutions to obtaining tokenizations of speech in terms of a vocabulary of automatically discovered word-like or phoneme-like units, without depending on the supervised training of ASR systems. Moreover, using automatic phoneme-like tokenizations, we demonstrate that a convolutional neural network based framework for learning spoken document representations provides competitive performance compared to a standard bag-of-words representation, as evidenced by comprehensive topic ID evaluations on both single-label and multi-label classification tasks.
An Empirical Evaluation of Zero Resource Acoustic Unit Discovery
Feb 05, 2017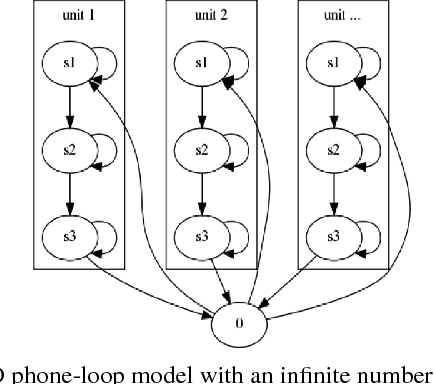
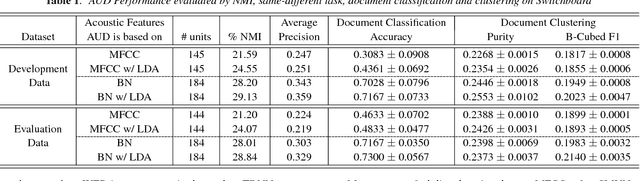
Acoustic unit discovery (AUD) is a process of automatically identifying a categorical acoustic unit inventory from speech and producing corresponding acoustic unit tokenizations. AUD provides an important avenue for unsupervised acoustic model training in a zero resource setting where expert-provided linguistic knowledge and transcribed speech are unavailable. Therefore, to further facilitate zero-resource AUD process, in this paper, we demonstrate acoustic feature representations can be significantly improved by (i) performing linear discriminant analysis (LDA) in an unsupervised self-trained fashion, and (ii) leveraging resources of other languages through building a multilingual bottleneck (BN) feature extractor to give effective cross-lingual generalization. Moreover, we perform comprehensive evaluations of AUD efficacy on multiple downstream speech applications, and their correlated performance suggests that AUD evaluations are feasible using different alternative language resources when only a subset of these evaluation resources can be available in typical zero resource applications.